多目标群体进化软件模块聚类方法与流程
[0001]
本发明属于软件系统重构技术领域,主要涉及软件系统重构中的软件模块聚类问题,本发明提供了多目标群体进化软件模块聚类方法,主要用于解决软件系统代码重构时优化系统代码的结构,消除系统代码冗余,提高系统代码的可理解性,减少软件系统维护成本。
背景技术:
[0002]
软件作为信息产业的核心,软件服务于各行各业,时刻影响着国家的科技和国民经济的发展,随着软件所属行业业务的变化,为之服务的软件功能与系统结构也会发生相应的变化。因此,需要软件维护人员根据业务的变化对软件系统的功能和结构进行相应的调整。随着对软件结构的不断更改,软件系统结构愈加复杂,同时软件的规模会逐渐扩大,会导致软件系统结构的逐渐恶化,最终软件系统难以维护甚至废弃。当软件系统的结构发生退化时,软件的可维护性会受到严重影响。如何使软件系统变得易于理解、维护和管理是一个亟待解决的问题。
[0003]
软件模块聚类是软件系统重构、恢复软件系统结构的有效手段,对软件模块进行聚类,能够很大程度提高软件系统的可理解性,降低软件的维护成本。目前常用的软件模块聚类方法主要是基于搜索的方法,传统方法没有考虑软件系统本身的特性或者只考虑某一单一规则,在解空间中盲目搜索,聚类效果一般,结果的多样性不足,不利于复杂软件系统进行软件模块聚类。
[0004]
本发明将软件模块聚类描述为多目标搜索问题,基于多目标进化优化方法进行聚类,结合软件模块聚类问题的特殊性,以软件模块质量和逆向边数为依据,采用双目标概率更新聚类方案,从根本上保证了产生的聚类结果具有合理性和聚类结果的有效性。
技术实现要素:
[0005]
本方法解决的问题:软件模块聚类问题是一个经典的组合优化问题,直接使用传统基于搜索的优化方法无法有效的针对软件模块聚类问题自身的特点进行设计,容易使得搜索的结果不全面,缺少多样性,无法为软件维护人员提供多种决策选择。本发明基于群体搜索的思路,使用双目标概率更新聚类方案,克服现有的大多数方法仅仅考虑软件模块质量这个单一目标而导致的聚类结果缺少多样性,提出多目标群体进化软件模块聚类方法,为大规模软件模块聚类问题提供了一种较为简单且有效的方法,得到模块聚类帕累托非支配解集,可根据实际情况由决策者选取符合特定情况的最优解。
[0006]
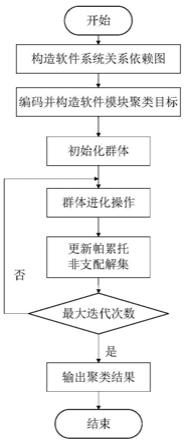
本发明的技术方案如图1所示包括以下的步骤:
[0007]
步骤1:面向对象语言编写的软件系统中,构造方法依赖图表示软件系统中方法之间的调用关系:顶点代表代码中的方法,边代表方法之间的调用关系;使用矩阵表示方法依赖图:若系统有n个方法,用集合f={f1,f2,
…
,f
j
,
…
,f
n
}表示,f
j
代表软件系统中的第j个方法,则软件系统方法依赖图用一个n
×
n的矩阵b来表示,若方法f
i
调用f
j
,则矩阵b的第i行第
j列的元素值为1,即b
ij
=1,若方法f
i
未调用方法f
j
,则b的第i行第j列的元素值为0,即b
ij
=0,矩阵b表示为:
[0008][0009]
其中i和j都为1到n之间的任意整数值;
[0010]
步骤2:编码;模块聚类是软件系统方法集合的一个划分,假设模块聚类数量为m,聚类结果可以用集合c={c1,c2,...c
k
,...c
m
}表示,k为1到m之间的任意一个整数值,c
k
表示软件系统经过模块聚类后的第k个聚类,在多目标群体进化软件模块聚类方法中,假设初始群体规模为n,群体中的第w个个体用p
w
表示,则群体可以用集合p={p1,p2,...,p
w
,...,p
n
}表示,w为1到n之间的任意一个整数值,该软件系统模块聚类方案可以用一个m
×
n的二维矩阵a编码,矩阵a的每一列代表一个方法,每一行代表一个模块聚类,则第w个个体在迭代到第t步时软件系统的模块聚类结果由中每一个元素的值决定,若方法f
j
属于c
k
聚类,则中的第k行第j列的元素值为1,即而第j列的其它元素值为0,则第w个个体在迭代到第t步时的模块聚类编码表示为:t为迭代步数,其中t为正整数;
[0011]
步骤3:构造软件模块聚类目标:软件模块质量mq和逆向边数fit_derection,软件模块质量mq:软件模块聚类后,第x个聚类和第y个聚类之间的耦合性用ε
x,y
表示:
[0012][0013]
第x个聚类的内聚性用μ
x
表示:
[0014][0015]
x,y分别表示第x个聚类和第y个聚类,其中x,y为1到m之间的任意一个整数值,f
x
和f
y
分别表示第x个聚类和第y个聚类中的方法个数,e
x,y
表示聚类x到聚类y的方法的引用次数,m
x
表示聚类x内部方法之间的引用次数,将内聚性和耦合性结合起来用软件模块质量,第w个个体的软件模块质量mq
w
为:
[0016][0017][0018]
模块聚类的逆向边数fit_derection:
[0019][0020][0021]
其中v
q
代表第q个模块聚类集合,v
q
补集表示集合v
q
和其补集合之间逆向边数,表示集合v
q
和其补集合之间逆向边数的最小值;b
ij
是方法依赖图矩阵b第i行和第j列的值;
[0022]
步骤4:群体初始化,设定最大迭代次数r,初始化帕累托非支配解集为空,对群体每个个体代表的聚类方案确定模块聚类中心:根据软件系统的方法依赖图,计算每个顶点的度d
c
,顶点v
c
作为聚类中心的概率值prob
c
:
[0023][0024]
每个顶点以prob
c
概率被选做聚类中心,每个个体代表的聚类选取m个不重复的中心,其他方法随机选择一个聚类加入,由此初始化个体,其中c为1到n之间的任意整数值,顶点v
c
代表第c个顶点,d是第c个顶点的度,n是软件系统的方法个数;
[0025]
步骤5:群体进化操作;对于个体w,首先计算其模块质量mq和逆向边数fit_derection这两个聚类目标值,然后计算个体w中方法f
j
属于聚类g的概率p
wjg
:
[0026][0027]
其中1≤g≤m,mq
jg
方法f
j
属于聚类g时聚类g的聚类质量,fit_derection
jg
表示方法f
j
属于聚类g时的聚类逆向边数;比较计算出的概率p
wjg
,选取最大概率p
wmax
=max(p
wj1
,p
wj2
,...,p
wjg
)对应的聚类作为方法f
j
最终的聚类结果,对个体w中每个方法按此方式计算概率,取其最大概率对应的聚类作为其聚类,对群体中的每个个体都采用步骤5的进化操作更新每个个体的模块聚类;
[0028]
步骤6:更新帕累托非支配解集;根据每个个体的聚类目标值:软件模块质量mq和逆向边数fit_derection,由个体间非支配关系更新帕累托非支配解集:如果当前个体被帕累托非支配解集中某个解支配,则当前个体不用加入帕累托非支配解集;如果当前个体支配了帕累托非支配解集中某个解,则删除帕累托非支配解集所有被支配的解,并把当前个体加入帕累托非支配解集;如果当前个体和帕累托非支配解集中所有解都不存在支配关系,则并把当前个体加入帕累托非支配解集;
[0029]
步骤7:重复迭代进行步骤5和步骤6,若达到最大迭代次数r,则结束整个步骤,帕累托非支配解集中的个体对应的聚类方案就是本软件模块聚类结果,输出聚类结果,否则重复执行步骤5到步骤6的操作,直到达到最大迭代次数。
[0030]
有益效果:
[0031]
当前,处理软件模块聚类问题的方法有很多,常见的应用于解决软件模块聚类问题的方法有基于图理论的方法、基于数据挖掘的聚类方法和基于搜索的群体智能方法,但在解决大规模复杂软件系统时,传统的基于搜索的方法大多考虑一个目标,提供的可选择方案少,聚类效果有待提升。
[0032]
软件模块聚类问题是一个组合优化问题,本发明提出了双目标概率群体进化方法,进化操作简单有效,为大规模复杂软件模块聚类问题提供了一种较为简单有效的多目标聚类方法,使得软件模块聚类的结果在达到高内聚,低耦合的软件开发准则的同时也能很好的符合逆向边数最小的原则,提高软件模块聚类的结果有效性性,改善了软件系统的可理解性和可维护性。
[0033]
对真实的软件系统ispell进行软件模块聚类,该ispell软件系统有24个方法,聚类个数设置为4,群体规模分别取10、20、50、80、100、150,迭代次数为100次,其中横坐标表示软件模块质量mq,纵坐标表示逆向边数,每个点表示一个帕累托非支配解,如图2所示,随着群体规模的增大,解集逐渐向坐标系右下方迁移,帕累托非支配解集在逐渐整体变优,说明了本方法的有效性。
附图说明
[0034]
附图1本发明的流程图
[0035]
附图2群体规模对ispell软件系统模块聚类的影响
[0036]
附图3某软件系统的方法依赖图
[0037]
附图4某软件系统的模块聚类结果图
具体实施方式
[0038]
以某个软件系统为例,如图3所示是此软件系统的方法依赖图,具体说明本发明公开的软件模块聚类方法的实施方式。
[0039]
步骤1:对如图2所示的方法调用关系用二维矩阵进行编码,此软件系统含有8个模块,这些方法表示为集合f={f1,f2,f3,f4,f5,f6,f7,f8},用8
×
8的二维矩阵表示如下:
[0040][0041]
步骤2:对群体进行初始化,初始化帕累托非支配解集为空,设定多目标群体进化软件模块聚类方法的参数:群体规模,即群体中的个体数量n=2,软件模块聚类的聚类数量m=3,最大迭代次数为100。
[0042]
计算方法依赖图各个顶点的度和每个顶点作为聚类中心的概率值:
[0043][0044][0045][0046][0047][0048][0049][0050][0051]
每个顶点以prob
c
概率被选做方案的聚类中心,假设选取f3,f5,f8三个方法作为模块聚类的中心,经过聚类后的软件系统可以用集合表示为c={c1,c2,c3},分别表示以f3,f5,
f8方法作为聚类中心的三个聚类,对此软件系统的模块聚类结果编码表示为一个3
×
8的二维矩阵a,第v个个体的初始化聚类编码表示为迭代到第t步时软件系统的模块聚类编码表示为其他方法随机选择一个聚类加入,由此初始化个体。假设p1个体的初始化编码矩阵为:
[0052][0053]
同理对个体p2进行初始化编码:
[0054][0055]
步骤3:计算每个个体的两个聚类目标值:软件模块质量mq和逆向边数fit_derection,以个体p1为例,首先计算p1三个聚类中的方法个数,f1=2,f2=1,f3=5;聚类c1中包含方法f3和方法f5,而聚类c2中包含方法f6,聚类c3中包含方法f1、f2、f4、f7和f8。
[0056]
计算聚类c
i
中方法的调用聚类c
j
中方法的次数:
[0057][0058][0059][0060][0061][0062][0063]
计算聚类c
i
内部方法之间的调用次数:
[0064][0065]
[0066][0067]
软件系统模块聚类后,计算第i个聚类c
i
和第j个聚类c
j
之间的耦合性ε
i,j
:
[0068]
ε
1,1
=0
[0069][0070][0071]
ε
2,2
=0
[0072][0073][0074]
ε
3,3
=0
[0075][0076][0077]
计算第i个聚类的内聚性μ
i
:
[0078][0079][0080][0081][0082][0083]
[0084][0085]
同理计算个体p2的软件模块质量
[0086]
计算逆向边数:
[0087][0088][0089]
将最优解(0.623,0.333)作为非支配个体加入到帕累托非支配解集合中,对帕累托非支配解集进行更新。
[0090]
步骤4根据个体p1和p2的两个聚类目标值:软件模块质量mq和逆向边数fit_derection更新聚类方案,个体p1的方法f
w
属计算于聚类g的概率p
1wg
:
[0091][0092]
比较计算出方法w分别属于3个聚类的概率p
1wg
,选取最大概率p
1wmax
,作为方法f
w
最终的聚类结果:
[0093]
p
1wmax
=max(p
1w1
,p
1w2
,p
1w3
)
[0094]
对个体p1和个体p2中每个方法求概率,更新两个个体所有方法的聚类结果,
[0095]
步骤5:更新帕累托非支配解集;根据每个个体的聚类目标值:软件模块质量和逆向边数,由个体间非支配关系更新帕累托非支配解集:如果当前个体被帕累托非支配解集中某个解支配,则当前个体不用加入帕累托非支配解集;如果当前个体支配了帕累托非支配解集中某个解,则删除帕累托非支配解集所有被支配的解,并把当前个体加入帕累托非支配解集;如果当前个体和帕累托非支配解集中所有解都不存在支配关系,则并把当前个体加入帕累托非支配解集。
[0096]
步骤6:重复迭代进行步骤4和步骤5,若达到最大迭代次数100,则结束整个步骤,帕累托非支配解集中的个体对应的聚类方案就是本软件模块聚类结果,输出聚类结果,否则重复执行步骤4到步骤5的操作。比较种群中所有个体的目标函数适应度值,把本次迭代的帕累托非支配个体加入到外部集中不断迭代,更新外部集,判断迭代次数是否达到最大迭代次数100,若达到最大迭代次数,则结束整个步骤,得到软件模块聚类结果,否则重复执行步骤4到步骤6的操作,聚类结果如图4所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1