一种基于模型量化的MDSSD人脸检测方法与流程
本发明涉及人脸检测的
技术领域:
,尤其涉及一种基于模型量化的mdssd人脸检测方法。
背景技术:
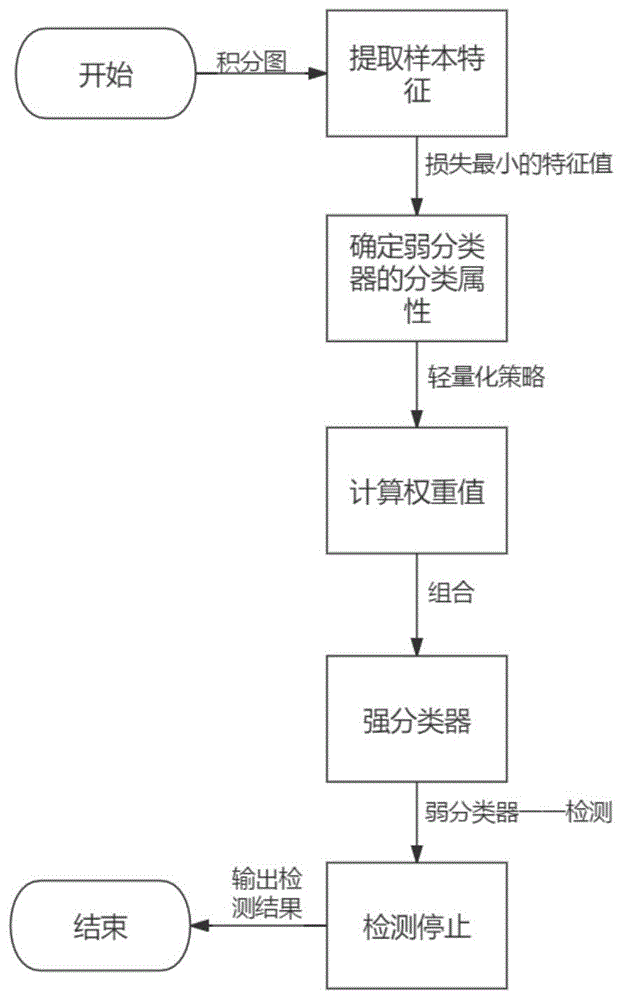
:随着深度学习的兴起,与人脸相关的智能分析技术成为人工智能领域研究的重点和热点,新的算法不断刷新着人脸相关任务的评分,目前人脸识别技术已经超越人类的最高水平,同时与人脸相关的工业应用也是最广泛的。例如与人脸检测相关的应用有智能安防、城市大脑、安全驾驶以及中国的天网系统等;与人脸识别的相关应用包括人脸支付、智能门禁、人脸考勤、各种智能终端设备的人脸验证等,人脸相关的技术与各种系统的安全息息相关。同时与人脸相关的技术也在不断的应用到生活的方方面面,比如走失儿童寻找、智慧教育等。进一步随着计算机计算能力的提高和5g网络的应用,数据储存的成本和数据传输的延时会越来越低,与人脸相关应用会部署到越来越多的智能终端上,真正实现智能社会而造福人类。人脸检测即智能终端在输入图像上判断是否有人脸存在,并找出人脸所在的位置。人脸检测技术的前提就是能准确的检测到人脸,而不受人脸图像背景的影响。因此人脸检测作为人脸相关任务的基础和核心技术,受到研究人员的广泛关注。基于ssd算法的人脸检测模型能快速准确的识别自然场景图像中的人脸,同时该算法具有较高的检测速度。但是ssd人脸检测算法对自然或非自然场景下小脸检测的召回率仍然有较大的提升空间,因此构建新的网络mdssd模型以及其量化模型mdssdlite,即mixdeconvolutionsingleshotmultiboxdetector用于人脸检测;mdssd算法对ssd算法在人脸检测方面的诸多缺点进行改进,包括模型结构、检测特征图、参数配置、损失函数等,并通过机器学习方法对模型进行配置以减少人为经验干预,大幅度提高了模型的检测效果。技术实现要素:本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。鉴于上述现有存在的问题,提出了本发明。因此,本发明提供了一种基于模型量化的mdssd人脸检测方法,能够解决针对小脸检测、模糊人脸召回率、检测速度较低的问题。为解决上述技术问题,本发明提供如下技术方案:包括,基于卷积神经网络计算输入图像的积分图并设置不同大小的特征模板提取所有样本的特征;读取所述所有样本的特征值,选取损失最小的所述特征值作为第一个弱分类器的分类属性;根据轻量化策略计算下一轮所述特征的权重值并计算所述弱分类器的权重;依次获得多个弱分类器并组合成强分类器;将候选框内预选位置输入所述强分类器内一一进行检测,直至所有的所述弱分类器确认所述预选位置为人脸时结束分类。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:所述卷积神经网络包括,卷积层、池化层和激活层;所述卷积层包括多个卷积核,利用所述卷积核在输入图像时进行固定步长滑动,扫描整个所述图像并进行离散卷积计算,通过激活函数将卷积运算的输出进行非线性映射,得到下一层网络的输入特征;所述池化层在卷积操作后对得到的特征图像进行分块,计算所述块内的最大值或平均值得到池化后的图像;所述激活层利用所述激活函数对上一层输出进行非线性映射从而将非线性引入到网络中,使得所述网络捕捉更加复杂的非线性模式。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:所述卷积层还包括,fx,y=-ix-1,y-1-2ix,y-1-ix+1,y-1+ix-1,y+1+2ix,y+1+ix+1,y+1卷积核k在各个方向上的滑动步长可以大于1,当步长为s(s>1)时,输出的特征图大小如下:其中,padding为扩充,m*n为输入图像尺寸,k为卷积核,i为输入图像子图,x、y为坐标值。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:所述池化层还包括,对所述卷积层的输出特征图进行池化操作压缩所述图像大小,减小过拟合;利用最大值池化和平均值池化代替整个候选区域。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:所述激活层还包括,f(x)=max(0,x)其中,梯度为1或者0,不会产生梯度消失或者梯度爆炸的问题,当输入为正时,损失函数梯度恒为1,极大地较少了模型训练时的计算量。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:所述轻量化策略包括,tensorflow通过线性变换将浮点型参数的小数部分转换成整型;计算转换的参数,利用线性变换将最终结果还原成所述浮点型;其中,r表示原始模型参数值,b表示量化的位数,q表示量化后模型的参数值,z表示量化后的0值。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:还包括,利用所述tensorflow对构建的mdssd模型进行量化压缩;在所述mdssd模型完成训练后,利用所述轻量化策略将所述mdssd模型参数由32位浮点型转换为8位整数型进行保存;最终得到mdssdlite轻量化模型。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:构建所述mdssd模型包括,mdssd算法利用k-means对groundtruth框进行聚类分析,以寻找最佳的先验框数量、大小和比例,并自定义iou距离作为度量距离进行聚类分析,diou(box,centroid)=1-iou(box,centroid)其中,聚类的损失是groundtruth与簇中心的iou距离,该距离越小则iou值越大;指定簇数k并随机初始化簇中心(wi,hi),i∈{1,2,…,k},其中wi,hi分别表示簇中心的长和宽;将所述簇中心与groundtruth中心置于坐标原点并计算每个groundtruth与簇的iou距离;将所述groundtruth分配为iou距离最小的簇,当所有的所述groundtruth框分配完毕后重新计算簇中心,不断更新直至簇中心不再改变;将所述簇中心的中位数作为最终的先验框大小和比例。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:计算所述积分图提取所述特征包括,所述特征模板划分为两个区域并分别计算所述两个区域内的像素值之和,且所述两个区域和的差值作为所述特征模板的所述特征值;所述积分图利用矩阵描述图像全局信息,所述积分图中的每一点的值等于所述点左上角上所有像素值之和,如下i(x,y)=f(x,y)+i(x-1,y)+i(x,y-1)-i(x-1,y-1)其中,i表示积分图像,f表示原始图像,x,y,x′,y′表示像素位置。作为本发明所述的基于模型量化的mdssd人脸检测方法的一种优选方案,其中:组合得到所述强分类器包括,在训练过程中不断调整数据分布以降低正确分类的样本权重;依次学习各个基分类器,直到所述弱分类器的数量达到预先制定的值停止学习;利用加权平均策略构建基于分类器的线性组合得到所述强分类器;给定训练样本x={(x1,y1),(x2,y2),…,(xn,yn)},xn为训练样本特征向量,yn为训练样本标签,其取值为+1或-1;赋予每个训练数据一个初始的权重值,所有样本权重均相等,d1=(ω11,ω12,…,ω1i,…,ω1n)对于基分类器gm(x),加权训练样本在分类器的错误率如下,其中,i(gm(xi)≠yi)为指示函数,其取值为0或者1,则当前分类器gm(x)的权重计算公式如下,更新所有训练样本的权重分布,则最终的所述强分类器如下,dm+1=(ωm+1,1,ωm+1,2,…,ωm+1,n)其中,zm为规范化因子,将ωm,i的值域规范值[0,1]之间,使得所有样本权重之和等于1,对m=1,2,…,n依次按照以上步骤训练每个弱分类器。本发明的有益效果:本发明通过对mdssd人脸检测模型进行量化压缩建立mdssdlite轻量级模型,相对于ssd而言,其对小脸和模糊人脸召回率更高,同时保持了较快的检测速度和检测精度。附图说明为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:图1为本发明一个实施例所述的基于模型量化的mdssd人脸检测方法的流程示意图;图2为本发明一个实施例所述的基于模型量化的mdssd人脸检测方法的卷积运算示意图;图3为本发明一个实施例所述的基于模型量化的mdssd人脸检测方法的包含padding卷积运算示意图;图4为本发明一个实施例所述的基于模型量化的mdssd人脸检测方法的池化示意图;图5为本发明一个实施例所述的基于模型量化的mdssd人脸检测方法的积分图示意图;图6为本发明一个实施例所述的基于模型量化的mdssd人脸检测方法的mdssd结构示意图;图7为本发明一个实施例所述的基于模型量化的mdssd人脸检测方法的widerface数据集示意图;图8为本发明一个实施例所述的基于模型量化的mdssd人脸检测方法的各模型p-r曲线对比示意图。具体实施方式为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明,显然所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明的保护的范围。在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本发明保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。同时在本发明的描述中,需要说明的是,术语中的“上、下、内和外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一、第二或第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。本发明中除非另有明确的规定和限定,术语“安装、相连、连接”应做广义理解,例如:可以是固定连接、可拆卸连接或一体式连接;同样可以是机械连接、电连接或直接连接,也可以通过中间媒介间接相连,也可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。实施例1参照图1~图6,为本发明的第一个实施例,提供了一种基于模型量化的mdssd人脸检测方法,包括:s1:基于卷积神经网络计算输入图像的积分图并设置不同大小的特征模板提取所有样本的特征。其中需要说明的是,卷积神经网络包括:卷积层、池化层和激活层;卷积层包括多个卷积核,利用卷积核在输入图像时进行固定步长滑动,扫描整个图像并进行离散卷积计算,通过激活函数将卷积运算的输出进行非线性映射,得到下一层网络的输入特征;池化层在卷积操作后对得到的特征图像进行分块,计算块内的最大值或平均值得到池化后的图像;激活层利用激活函数对上一层输出进行非线性映射从而将非线性引入到网络中,使得网络捕捉更加复杂的非线性模式。参照图2和图3,卷积层还包括:fx,y=-ix-1,y-1-2ix,y-1-ix+1,y-1+ix-1,y+1+2ix,y+1+ix+1,y+1卷积核k在各个方向上的滑动步长可以大于1,当步长为s(s>1)时,输出的特征图大小如下:其中,padding为扩充,m*n为输入图像尺寸,k为卷积核,i为输入图像子图,x、y为坐标值;参照图4,池化层还包括:对卷积层的输出特征图进行池化操作压缩图像大小,减小过拟合;利用最大值池化和平均值池化代替整个候选区域;激活层还包括,f(x)=max(0,x)其中,梯度为1或者0,不会产生梯度消失或者梯度爆炸的问题,当输入为正时,损失函数梯度恒为1,极大地较少了模型训练时的计算量。参照图5,计算积分图提取特征包括:特征模板划分为两个区域并分别计算两个区域内的像素值之和,且两个区域和的差值作为特征模板的特征值;积分图利用矩阵描述图像全局信息,积分图中的每一点的值等于点左上角上所有像素值之和,如下i(x,y)=f(x,y)+i(x-1,y)+i(x,y-1)-i(x-1,y-1)其中,i表示积分图像,f表示原始图像,x,y,x′,y′表示像素位置。s2:读取所有样本的特征值,选取损失最小的特征值作为第一个弱分类器的分类属性。s3:根据轻量化策略计算下一轮特征的权重值并计算弱分类器的权重。本步骤需要说明的是,轻量化策略包括:tensorflow通过线性变换将浮点型参数的小数部分转换成整型;计算转换的参数,利用线性变换将最终结果还原成浮点型;其中,r表示原始模型参数值,b表示量化的位数,q表示量化后模型的参数值,z表示量化后的0值;利用tensorflow对构建的mdssd模型进行量化压缩;在mdssd模型完成训练后,利用轻量化策略将mdssd模型参数由32位浮点型转换为8位整数型进行保存;最终得到mdssdlite轻量化模型。参照图6,构建mdssd模型包括:mdssd算法利用k-means对groundtruth框进行聚类分析,以寻找最佳的先验框数量、大小和比例,并自定义iou距离作为度量距离进行聚类分析,diou(box,centroid)=1-iou(box,centroid)其中,聚类的损失是groundtruth与簇中心的iou距离,该距离越小则iou值越大;指定簇数k并随机初始化簇中心(wi,hi),i∈{1,2,…,k},其中wi,hi分别表示簇中心的长和宽;将簇中心与groundtruth中心置于坐标原点并计算每个groundtruth与簇的iou距离;将groundtruth分配为iou距离最小的簇,当所有的groundtruth框分配完毕后重新计算簇中心,不断更新直至簇中心不再改变;将簇中心的中位数作为最终的先验框大小和比例。s4:依次获得多个弱分类器并组合成强分类器。其中还需要说明的是,组合得到强分类器包括:在训练过程中不断调整数据分布以降低正确分类的样本权重;依次学习各个基分类器,直到弱分类器的数量达到预先制定的值停止学习;利用加权平均策略构建基于分类器的线性组合得到强分类器;给定训练样本x={(x1,y1),(x2,y2),…,(xn,yn)},xn为训练样本特征向量,yn为训练样本标签,其取值为+1或-1;赋予每个训练数据一个初始的权重值,所有样本权重均相等,d1=(ω11,ω12,…,ω1i,…,ω1n)对于基分类器gm(x),加权训练样本在分类器的错误率如下,其中,i(gm(xi)≠yi)为指示函数,其取值为0或者1,则当前分类器gm(x)的权重计算公式如下,更新所有训练样本的权重分布,则最终的强分类器如下,dm+1=(ωm+1,1,ωm+1,2,…,ωm+1,n)其中,zm为规范化因子,将ωm,i的值域规范值[0,1]之间,使得所有样本权重之和等于1,对m=1,2,…,n依次按照以上步骤训练每个弱分类器。s5:将候选框内预选位置输入强分类器内一一进行检测,直至所有的弱分类器确认预选位置为人脸时结束分类。优选的是,本实施例构建新的网络mdssd模型及其量化模型mdssdlite,即mixdeconvolutionsingleshotmultiboxdetector用于人脸检测,且mdssd算法相对ssd算法在人脸检测方面的诸多缺点都进行了改进,包括模型结构、检测特征图、参数配置、模型轻量化,并通过深度神经网络学习方法对模型进行配置以减少人为经验干预,大幅度提高了模型的检测效果。实施例2参照图7,本实施例使用widerface(人脸检测基准)人脸数据集进行对比实验,该数据集包含由61个事件类别组成的32203个不同大小不同比例的图像和393703个不同肤色、尺度、姿势的人脸;同时该数据集含有训练数据和验证数据的人工标注groundtruth框(真实标注),但对于测试人脸图像该数据集并没有提供相应的groundtruth标注框。因此本实施例使用widerface训练数据对模型进行训练和超参数调节,使用验证数据对轻量化模型进行测试。由于使用的sdd算法、mdssd算法和mdssdlite的输入图像均为300×300像素大小,因此,在模型训练之前需要将图像强制转换为300×300大小,同时模型输入的人脸标注groundtruth框需要同步放缩;实验显示groundtruth框的长或宽小于11像素的人脸会导致模型训练时损失无法收敛而导致无效学习,因此,数据预处理阶段首先剔除这些微小的人脸样本,其次为了缩短模型训练时数据处理的时间还需要将数据集转换为voc格式,即一种特定格式的文本数据。ssd模型、mdssd模型和mdssdlite模型均使用python3.6基于tensorflow1.14框架实现,模型训练和测试机器配置如下表所示:表1:实验环境配置表。服务器delltower操作系统windows10gupnvidagtx1080ticupintercorei7-8700@3.20ghz内存32g显存8gssd网络训练使用迁移学习的方法,即在imagenet数据集上训练vgg16图像分类模型,使用该预训练模型的卷积层参数对ssd的前五个卷积块进行初始化,固定ssd网络的前三个卷积块,使用widerface的voc格式数据集对模型主干网络的深层和分类回归模块进行微调,以训练人脸检测模型;同理mdssd人脸检测模型使用预训练ssd人脸检测模型对主干网络的参数进行初始化,然后使用widerface的voc格式数据集对模型所有参数进行微调,并训练特征融合模块和分类回归模块;而本发明的mdssdlite模型的建立采用训练后量化方式,故直接使用mdssd参数进行量化,不使用训练数据进行再次训练。ssd和mdssd网络均使用adam进行优化,其学习率最小衰减为0.0001,以确保其损失逐渐接近与全局最小值。表2:训练超参数设置表。参数ssd网络mdssd网络主干网络初始化方法vgg16ssd批量大小(batchsize)3232优化方法adamadamadam_bate10.90.9adam_bate20.9990.999学习率0.0010.001学习率衰减率0.900.90迭代次数5000050000模型评估中有roc曲线和p-r曲线两种评估方法,但是对于目标检测任务由于要评估其精确率和召回率,因此选用p-r曲线评价更为直观,p-r曲线是模型在不同阈值下的召回率与精确率所连成的一条曲线,精确率和召回率是二分类任务中常用的评价指标,其可通过混淆矩阵计算得到。表3:混淆矩阵表。标注为人脸标注为背景检测为人脸tpfp检测为背景fntf若图像中标注人脸的groundtruth框与模型预测人脸边界框iou值大于0.5,则表示人脸检测正确,根据以上匹配规则,表中tp为模型正确检测的人脸总数,fn为模型漏检的人脸总数,fp为错将人脸分类为背景的总数,评估目标为人脸检测的精度,故人脸检测中混淆矩阵舍弃背景检测正确总数tn这一指标。根据以上指标可以计算得到精确率和召回率,如下:精确率表示在检测到的人脸中有多少比例为真实人脸,召回率表示在测试数据的标注人脸中有多少人脸被检测出来;在人脸检测中,p-r曲线即为在给定每个召回率时由对应的最大检测准确率所连成的曲线,通过p-r曲线可以对不同模型性能进行直观评估和对比。平均准确率即ap是widerface数据集的量化评估指标,其物理意义为模型p-r曲线与坐标轴围成区域的面积,如下:map=∫01p(r)dr其中,p为准确率,r为召回率,则ap表示准确率p在召回率r上的积分。但在实际计算中召回率和准确率是离散的,因此需要对ap求近似值,常用的计算方法包括pascalvoc2007和pascalvoc2012,其中voc2007采用maxintegral方法,即11point方法,即给定召回率recall=[0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0],计算这11个点的最大准确率并相加求平均来计算ap,如下:其中,maxp(r)表示在给定召回率r条件下的最大准确率p。voc2012采用integral方法,其直接对p-r曲线坐标轴围成的区域进行数值积分,即针对每一个准确率下降点计算其准确率与召回率变化值的乘积之和,根据interpolatedaverageprecision标准,ap用下式计算:其中,i表示当前检测出的人脸数,△ri表示当前置信度阈值变化导致准确率变化时召回率的变化量,本文使用式(5-5)评价方法计算ap值。本实施例对训练的ssd人脸检测模型、mdssd人脸检测模型、mdssdlite模型从检测速度、平均准确率、模型大小和实际检测效果等方面进行对比分析,来测试改进模型的有效性。表4:实验结果数据表。参照表4和图8,其实验效果均仅在相同配置的cpu上完成,无gup加速计算,同时实验测试基于widerface的验证集,通过实验对比可以发现ssd人脸检测模型其检测速度较快,可以达到28帧/秒,模型体积仅97m大小,但是其检测精度较低,尤其是其召回率较低;而基于ssd网络改进的mdssd网络由于其添加了额外的检测模块、检测层和先验框,使得其模型参数量以及模型体积更大,因此其检测速度略慢于ssd网络,达到25帧/秒,但是mdssd网络仍然可以达到人脸实时检测的要求,相对于ssd检测速度,mdssd网络检测速度的损失是可以忽略不计;同时mdssd网络检测精度和人脸置信度较高,其平均准确率达到0.813,极大地提高了小脸检测的召回率,相对于ssd模型其平均准确率提高了20.9%,有效证明了模型改进的有效性;基于mdssd网络的量化压缩模型mdssdlite模型其检测精度高,检测速度最快,可达到34帧/秒,模型体积最小仅为63m。因此ssd、mdssd、mdssdlite三个模型的检测效果相当,但是由于ssd网络低层特征图语义特征不丰富,因此无法检测到稍小的模糊人脸;同时对于正常人脸检测而言,ssd人脸检测模型的框回归相对不准确,无法完整定位到全部人脸区域,在中等复杂的场景下,ssd模型错检率较高,而mdssd和mdssdlite模型可以很好地检测到自然场景下的人脸,其错检率和漏检漏均较低;在复杂场景下,尤其是人脸密集图像中,ssd几乎无法检测到小脸和遮挡人脸;对于背景简单的复杂场景,mdssd模型和mdssdlite模型仍然可以检测到几乎全部的人脸,而对于背景复杂场景,其仅存在很少的漏检人脸,但是漏检的人脸往往分辨率很低且遮挡严重,人脸特征不明显。总体而言,mdssd人脸检测模型有较高的检测精度和检测速度,但模型参数较多,计算相对复杂,适用于高性能设备的实时人脸检测需求;而mdssdlite模型检测速度较快,检测精度较高,可以部署到大多数设备进行实时人脸检测;mdssd模型与ssd模型检测速度相当,但其检测精度优于ssd模型,mdssdlite的检测精度和检测速度均优于ssd模型,因此,mdssd模型和mdssdlite模型更适用于人脸检测工业应用。应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1