CPU应用于人工智能相关程序时的执行方法与流程
cpu应用于人工智能相关程序时的执行方法
技术领域
1.本发明涉及中央处理单元,尤其涉及中央处理单元在执行与人工智能相关程序时的执行方法。
背景技术:
2.近年来人工智能的技术蓬勃发展,各大企业纷纷投入人工智能的相关产品的研发动作。
3.一般来说,软件工程师经常使用谷歌公司(google)所开发的tensorflow来开发人工智能的相关程序。具体地,tensorflow是一种应用于机器学习的开源软件库,并且tensorflow提供了多种人工智能相关模型,有助于软件工程师直接用来进行人工智能的开发。
4.然而,于现有技术中一般并不会对所述人工智能相关模型用来进行运算的矩阵进行优化,因此这些模型在进行运算时所使用的计算参数较多。也因为这样,目前若要执行人工智能的相关运算,通常需要使用较高阶的硬件才能完成。例如,需要使用高阶的中央处理单元(central processing unit,cpu),或是需要使用特定的图像处理单元(graphics processing unit,gpu)。然而,上述硬件的使用实大幅提高了人工智能的开发、使用成本,并且也造成了硬件散热不易的问题。
5.另外,有鉴于目前gpu的强大计算能力,cpu在执行上并不会也不需要对各项程序进行最佳化排序。具体地,cpu通常仅会单纯地按照顺序来执行所接收的多个指令,因此常会发生cpu的一个执行线程(thread)无法算完一个程序,而需要交给下一个执行线程继续计算的现象。当于上述现象发生时,cpu即增加了执行swap的时间成本,导致整体速度变慢,而需要更换更高阶的cpu,或是必须额外设置gpu。于此情况下,无疑是阻挡了利用低阶的硬件,例如x86架构的工业电脑(inidustry personal computer,ipc)来开发、使用人工智能的可能性,实相当可惜。
技术实现要素:
6.本发明的主要目的,在于提供一种cpu应用于人工智能相关程序时的执行方法,系对人工智能模型在运算时采用的矩阵进行简化,同时最佳化cpu的执行时间,借此令低阶的硬件设备也可以被用于开发、使用人工智能。
7.为了达成上述的目的,本发明的执行方法运用于至少具有一加权值中央处理单元(weighted central processing unit,weighted cpu)的一电子设备,并且包括下列步骤:
8.a)于该电子设备上执行tensorflow;
9.b)依据程序码内容调用tensorflow中的至少一人工智能模型;
10.c)判断并取出该人工智能模型于运算中使用的一或多个稀疏矩阵(sparse matrix);
11.d)对该一或多个稀疏矩阵执行一矩阵简化程序;
12.e)对该人工智能模型所采用的一指令集进行一指令转换程序,以产生一转换后指令集;
13.f)该人工智能模型通过该转换后指令集对该加权值中央处理单元进行指令发布;及
14.g)该加权值中央处理单元接收指令后,依据该人工智能模型所指示的多个程序的权重值,将该多个程序平均分配由其下的多个执行线程(thread)来分别执行。
15.如上所述,其中该步骤a)是于程序码中通过import tensorflow的指令来执行tensorflow。
16.如上所述,其中该人工智能模型至少包括一imagenet模型及一inception模型。
17.如上所述,其中该矩阵简化程序包括将该一或多个稀疏矩阵分解成一或多个合并矩阵(consolidate matrix),其中该多个程序至少包括对该一或多个合并矩阵的运算。
18.如上所述,其中该加权值中央处理单元为intel架构的中央处理单元,该人工智能模型采用的该指令集为intel架构的指令集。
19.如上所述,其中该加权值中央处理单元的一加权cpu时间为该多个执行线程的一加权程序时间之和,各该执行线程的该加权程序时间分别是执行对应的该程序的一cpu时间与一执行频率(program frequency)的乘积,该cpu时间为该执行线程的一周期时间(cycle time)与一周期计数(cycle count)及一停顿周期(idle cycles)的和之乘积。
20.相较于现有技术,本发明先通过矩阵简化程序来压缩人工智能模型于运算中使用的稀疏矩阵,以令运算中的计算参数产生缩减。并且,本发明先借由转换后的指令对人工智能模型所指示的多个程序进行权重值的设定后,再下指令给加权值中央处理单元,借此加权值中央处理单元可以将这些程序平均分配给多个执行线程来执行,以最佳化cpu执行时间。借此,达到令低阶的硬件设备也可以被用来开发、使用人工智能的主要目的。
21.以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
附图说明
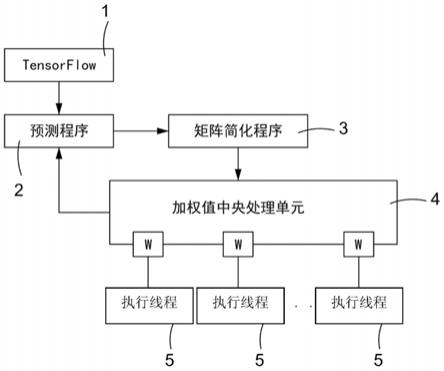
22.图1为本发明的第一具体实施例的系统架构图。
23.图2为本发明的第一具体实施例的执行方法流程图。
24.图3为本发明的第一具体实施例的矩阵简化示意图。
25.图4为本发明的第一具体实施例的加权值中央处理单元的示意图。
26.其中,附图标记:
[0027]1…
tensorflow;
[0028]2…
预测程序;
[0029]3…
矩阵简化程序;
[0030]
31
…
稀疏矩阵;
[0031]
32
…
合并矩阵;
[0032]4…
加权值中央处理单元;
[0033]
41
…
加权cpu时间;
[0034]
42
…
加权程序时间;
[0035]
43
…
执行频率;
[0036]
44
…
cpu时间;
[0037]
45
…
周期时间;
[0038]
46
…
周期计数;
[0039]
47
…
停顿周期;
[0040]5…
执行线程;
[0041]
s10~s24
…
执行步骤。
具体实施方式
[0042]
下面结合附图对本发明的结构原理和工作原理作具体的描述:
[0043]
兹就本发明的一较佳实施例,配合附图,详细说明如后。
[0044]
本发明揭露了一种cpu应用于人工智能相关程序时的执行方法(下面将于说明书中简称为执行方法),所述执行方法主要可被应用在使用加权值中央处理单元(weighted central processing unit,weighted cpu)的电子设备上。更具体地,本发明中所指的电子设备,主要是指采用了较低阶的cpu,并且没有将图像处理单元(graphics processing unit,gpu)视为必要配备的电子设备,例如个人电脑(personal computer,pc)、工业电脑(industrial pc,ipc)、工业服务器等,但并不以此为限。通过本发明的执行方法,可以协助使用者借由相对低阶的硬件设备来开发、使用人工智能。
[0045]
首请参阅图1,为本发明的第一具体实施例的系统架构图。如上所述,本发明的执行方法主要用于协助使用者使用低阶的硬件设备来开发、使用一般需要耗费大量运算资源的人工智能,并且本技术领域中的技术人员皆知,于人工智能的开发中,经常会使用谷歌公司(google)所开发的tensorflow来进行各项运算。
[0046]
tensorflow 1是一种应用于机器学习的开源软件库,并且tensorflow提供了多种主要被用来开发人工智能相关程序的模型(下面于说明书中称为人工智能模型)。软件工程师在撰写程序时,可以直接引用tensorflow提供的多个人工智能模型,以直接、快速地对数据进行分析与运算,进而实现如机器学习(machine learning)、预测(inference)等人工智能相关的程序。
[0047]
如图1所示,使用者于电子设备上撰写程序时,可以执行上述tensorflow1,借此调用tensorflow 1的一或多个人工智能模型,并借由这些人工智能模型来实现人工智能中的预测程序(inference process)2。于一实施例中,使用者主要可以于程序码中通过例如import tensorflow的指令来令电子设备执行tensorflow,以便调用tensorflow中的一或多个人工智能模型。于另一实施例中,所述人工智能模型可例如为imagenet模型、inception模型等与影像处理相关的模型,但不以此为限。
[0048]
本技术领域中的技术人员皆知,目前绝大多数的人工智能模型(例如上述的imagenet模型、inception模型)都是利用矩阵(matrix)来进行数据运算,并且借由指令集的使用,指示cpu执行(run)运算相关的程序。有鉴于目前cpu的规格不断提升,并且部分高阶硬件设备中还配置有专门用来处理影像的gpu,因此目前在进行人工智能的运算时,一般并不会对所述人工智能模型进行优化,并且也不会特别对cpu所要执行的程序进行分配与排序。因此,人工智能的运算较难在低阶的硬件设备(例如采用低阶的cpu,并且不具有gpu的工业电脑)上被实现。
[0049]
本发明的其中一项主要技术特征在于,当一支应用程序执行了tensorflow1,并且调用上述人工智能模型进行运算以期实现预测程序2时,先对这些人工智能模型在运算中所要使用的矩阵进行矩阵简化程序3,以缩减这些人工智能模型于运算中的计算参数的数量。
[0050]
除了缩减运算中的计算参数的数量之外,本发明还可预先查询这些人工智能模型所需采用的指令集,并且对指令集中的指令进行指令转换程序。借此,本发明中的加权值中央处理单元4在收到人工智能模型所发布的指令后,可以依据所述运算所包含的多个程序的权重值(w)来对这些程序进行排序,以将这些程序平均分配给其下的多个执行线程(thread)5来分别执行,进而实现所述应用程序所要实现的预测程序2。如此一来,本发明可以更好地反映人工智能所需的各个程序对于cpu的平均资源利用率,进而可以最佳化cpu的执行时间。
[0051]
本发明的执行方法结合了矩阵简化程序3以及加权值中央处理单元4的执行线程分配技术,大幅降低了人工智能运算所需占用的资源,使得一般低阶的硬件设备(例如x86架构的工业电脑)也可以执行人工智能下的训练、识别任务。借此,使用者可以有效地节省开发与使用人工智能时的成本,并且可提高电子设备在实现所述预测程序2时的运算速度。
[0052]
请同时参阅图2,为本发明的第一具体实施例的执行方法流程图。本发明的执行方法主要是应用在使用加权值中央处理单元4的电子设备上,于一实施例中,本发明的执行方法主要是运用在低阶的电子设备(例如采用x86架构的工业电脑),并且所述电子设备采用intel架构的加权值中央处理单元4,但不加以限定。
[0053]
如图2所示,所述电子设备在执行程序码时,系先依据程序码内容执行tensorflow 1(步骤s10),并且依据程序码内容调用tensorflow中的至少一个人工智能模型(步骤s12)。于一实施例中,所述程序码通过例如import tensorflow的指令来执行tensorflow 1,并且调用例如imagenet模型、inception模型等主要用来执行影像处理的人工智能模型,但不加以限定。
[0054]
所述imagenet模型、inception模型为人工智能相关程序经常使用的模型,为本技术领域中的技术人员的常用手段,于此不再赘述。
[0055]
本发明的执行方法主要以驱动程序(driver)或中介软件(middleware)的形式存在于tensorflow与所述加权值中央处理单元4之间,用以缩减tensorflow的人工智能模型于运算时的计算参数的数量,并且令加权值中央处理单元4可以通过多个执行线程5来平均处理这个运算内容,借此最佳化这个加权值中央处理单元4的执行时间。
[0056]
如图2所述,本发明的执行方法进一步判断并取得所述人工智能模型于运算中使用的一或多个稀疏矩阵(sparse matrix)(步骤s14),并且对一或多个稀疏矩阵执行矩阵简化程序3(步骤s16),借此缩减所述一或多个人工智能模型在运算中的计算参数的数量。
[0057]
请同时参阅图3,为本发明的第一具体实施例的矩阵简化示意图。如图3所示,稀疏矩阵31指的是内部的元素大部分为零的矩阵,一般在求解线性模型时经常会使用到大型的稀疏矩阵31,也因此,与人工智能相关的模型经常会利用稀疏矩阵31来进行运算。
[0058]
为了缩减计算参数的数量,所述矩阵简化程序3主要仅储存稀疏矩阵31中非零的元素,以压缩稀疏矩阵31。并且,所述矩阵简化程序3进一步将压缩后的稀疏矩阵31分解成一或多个合并矩阵(consolidate matrix)32,以完成简化矩阵的动作。本发明中,被调用的
人工智能模型在进行运算时,主要会利用如图3中所示的合并矩阵32来进行运算。
[0059]
上述稀疏矩阵31的压缩,以及合并矩阵32的产生,都是本技术领域中的公知技术,于此不再赘述。并且,上述将稀疏矩阵31分解为合并矩阵32的方式,仅为本发明的矩阵简化程序3的其中一种具体实施范例,本技术领域中亦存在其他可以对矩阵进行简化的类似程序,故于此不再赘述。
[0060]
回到图2。于步骤s16后,本发明的执行方法进一步对所述人工智能模型所采用的指令集进行查询与分析,并且对指令集中的指令进行指令转换程序,以产生转换后指令集(步骤s18)。于一实施例中,所述加权值中央处理单元4为intel架构的中央处理单元,而所述指令集则为intel架构的指令集,但并不以此为限。
[0061]
如前文所述,现有技术在进行人工智能的运算时并不会对cpu要执行的程序进行有效的排序与分配,意即,cpu仅会单纯地按照指令的接收顺序来依序执行多个指令,而不会对其下的多个执行线程进行最佳化的分配,以进行平衡负载(loading)。
[0062]
本发明中,所述指令转换程序系对人工智能模型所采用的指令集进行修改,使得人工智能模型在将指令发布至加权值中央处理单元4之前,可以先判断、设定所需执行的多个程序的权重值,进而能够对这些程序进行排序与分配。如此一来,当加权值中央处理单元4接收了人工智能模型所发布的指令后,即可依据权重值来将这些程序平均分配给其下的各个执行线程5,借此可以有效地利用加权值中央处理单元4的有限资源,进而提高这些程序的执行速度。
[0063]
步骤s18后,所述人工智能模型即可通过转换后指令集来对加权值中央处理单元4进行指令发布(步骤s20),而加权值中央处理单元4在接收指令后,即可依据人工智能模型所指示的多个程序的权重值,来将多个程序平均分配给其下的多个执行线程5来分别执行(步骤s22)。其中,所述多个程序中即包含了对矩阵简化程序3后的一或多个合并矩阵32的运算,但并不以此为限。
[0064]
值得一提的是,所述人工智能模型在进行运算时,系可执行调用资源库(call library)的动作,进而可以执行(run)cpu的指令集。本发明系对指令集(较佳为intel架构的指令集)中的指令进行修改,使得人工智能模型在下达指令给加权值中央处理单元4之前,可以先判断、设定所需执行的多个程序的权重值,进而可以将这些程序平均分配给加权值中央处理单元4下的多个执行线程5。
[0065]
所述调用资源库的动作为本技术领域中的常用技术手段,于此不再赘述。
[0066]
参阅图4,为本发明的第一具体实施例的加权值中央处理单元的示意图。如图4所示,一个加权值中央处理单元4在运作时,系基于本身的执行周期而包括多个加权cpu时间41,图4中系以第一加权cpu时间至第n加权cpu时间为例。其中,加权值中央处理单元4在每一个加权cpu时间41下皆可控制其下的多个执行线程5(图4中以第一执行线程至第n执行线程为例)同时运作,并且所述加权cpu时间41为所有执行线程5的各自的加权程序时间42的总和。具体地,所述加权程序时间42指的是单一个执行线程5执行一个程序的时间。
[0067]
更具体地,所述加权程序时间42为此执行线程5执行被分配的程序的执行频率(program frequency)与所占据的cpu时间44的乘积,而所述cpu时间44则为此执行线程5的周期时间(cycle time)45与此执行线程5的周期计数(cycle count)46和停顿周期(idle cycles)的和之乘积。
[0068]
由上述说明可看出,加权值中央处理单元4在每一个加权cpu时间41中都可以借由多个执行线程5来同步执行多个程序,因此,若各个执行线程5在每一个加权程序时间42中所能执行的程序都被有效分配,则加权值中央处理单元4整体的资源利用率就可以被大幅的提升。
[0069]
回到图2。于步骤s22后,本发明的执行方法(即,所述驱动程序或中介软件)判断程序码是否执行完成(步骤s24),并且于程序码尚未执行完成前,重复执行步骤s12至步骤s22,以令电子设备可以依据本发明的执行方法,通过加权值中央处理单元4来实现人工智能的相关程序(例如所述预测程序2)。
[0070]
本发明的执行方法结合了矩阵简化技术以及加权值中央处理单元的执行线程分配技术,先缩减运算中的计算参数的数量,再对加权值中央处理单元下的多个执行线程进行最佳化的程序管理,借此达到令低阶的硬件设备也可以被用来开发、使用人工智能的主要目的。相对于现有技术,本发明的执行方法有效降低了人工智能的开发、使用成本与门槛限制。
[0071]
当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1