一种基于城市公共交通资源联合调度方法与流程
[0001]
本发明涉及人工智能领域,尤其涉及一种具有人流预测方法以及交通资源联合调度的强化学习方法。
背景技术:
[0002]
近年来,现代城市的交通拥堵问题日益成为居民的心病。如百度交通报告所示,北京上下班高峰时段的通勤压力指数达到惊人的1.973,导致出行时间延长,车辆排队增多。以往的研究表明,通过合理的调度,例如重新调度自行车共享系统和优化公交运输系统,可以在不消耗多余资源的情况下显著提高交通效率。
[0003]
经本发明人研究发现,仍有两个缺点限制了调度系统的性能:(1)只考虑短时间内的单一调度,而忽略了首次交通调度后交通资源重分布现象;(2)当前调度系统只关注一类交通调度。城市公共交通的多模式特性在很大程度上还没有得到充分的利用。因此,如何基于实时的交通状况,联合多类交通系统进行联合调度优化,从而为市民提供一体化的更好的出行体验,以及缓解交通拥堵至关重要。
技术实现要素:
[0004]
本发明所要解决的技术问题是提供一种基于城市公共交通资源联合调度方法,其特征在于,包括:
[0005]
步骤1、依据已记录的不同时间地点下人群流动的数据和各类交通工具,承载的人流流动数据,预先构造出一个随时间变化的人群乘坐交通工具的交通流量图,对于公交车和共享单车的每个站点,记录其每个时间段的流入和流出量;
[0006]
步骤2、在构建的交通流量图中,为每个地点生成一个时序的流量变化序列,使用机器学习技术,并针对不同交通构建出人流预测模型,然后将该流量变化序列和相应的流量流动相关的数据输入到构建的人流预测模型中,从而预先训练得到一个具有预测人流去向能力的预测模型;最后将实时统计的流量变化序列输入到人流预测模型中,得到未来时刻不同地点的流量流动图;
[0007]
步骤3、获取当前各个地点的交通资源状态,将其和预测的未来时刻的流量流动图一同输入到基于强化学习的联合调度系统中,为每个地点构造相关的调度状态和全局的流量状态输入到强化学习调度系统中得到相应的交通工具的调度动作,不断优化调度动作直至最优。
[0008]
进一步的,步骤2中预先构建的人群乘坐交通流量的人流预测模型,包括:
[0009]
对获取的各个地点的各类交通工具的流量变化序列进行预处理;
[0010]
根据各类交通流量的特点选取对应的流量预测模型,流量变化稳定,即每日交通流量变化相对总流量小于第一预定阈值,这些稳定的交通类采用分层预测模型;
[0011]
对于流动变化具有时序性的交通类,采用具有时序敏感性的预测模型;
[0012]
同时考虑不同交通流量预测系统之间的协同关系,将不同系统的预测信息嵌入到
不同类预测系统中协同预测。
[0013]
进一步的,具体包括:
[0014]
对于公交车系统采用分层预测模型;
[0015]
对于共享单车的流量变化代入带有长短期记忆lstm的预测模型;
[0016]
在共享单车的调度系统中引入周围公交车调度的状态信息。
[0017]
进一步的,所述步骤3中基于强化学习的联合交通调度系统是预先构建的,包括步骤:
[0018]
对公交车系统进行强化学习调度建模,定义公交车的状态包括四部分:
[0019]
e)对于公交站点的观测,其中b1,b2分别表示上一班次公交车从两个方向经过此车站的时间间隔,和表示所预测未来交通流入量和流出量;t=1......l,t表示l表示未来时刻;
[0020]
f)对于同一班线其他公交车的状态信息(d
j
,e
j
,f
j
,v
j
)和当前公交车的状态信息(d1,e1,f1,v1);其中d
j
表示当前第j个公交车位置,e
j
,f
j
分别表示第j个公交车当前载客量和剩余可承载多少客量;v
j
表示第j个公交车当前的操作类型;
[0021]
g)系统的信息h,包括天气、温度、相邻两站之间的时间距离和地理距离;
[0022]
h)当前路线公交车车站在其他公交车路线的状态o。
[0023]
进一步的,还定义公交车系统的公交车动作、奖励和停止条件如下:
[0024]
动作:一辆公交车的动作有两个,向终点方向开,向起点方向开,在终点或者起点停;
[0025]
奖励:对于公交车强化学习,定义奖励机制如下:
[0026]
d)公交车每次从a到b行程,奖励为减少的等待时间,惩罚为到a的行驶时间,车行驶数目;
[0027]
e)公交车调转方向,转向操作惩罚为一个常数c,以及l*当前乘客数量,l为惩罚系数;
[0028]
f)公交车不开车,没有奖励和惩罚;
[0029]
停止条件:某一用户等了p个时间片段未等到公交车或者完成一个完整的周期。
[0030]
进一步的,对共享单车系统进行强化学习调度建模,定义共享单车的状态包括四部分:共享单车调度
[0031]
a)共享单车车站的状态其中b1,b2分别表示当前单车可用单车量和可停放单车量,和表示所预测未来单车流入量和流出量;考虑了站点间的单车流动信息,并使用l个矩阵g
t
表示未来l段时间中所预测站点间单车的流动网络;对其进行编码(encoder)得到g
t
∈r
d
代表未来t时刻的预测的交通流量低维状态表示,作为对未来t时刻站点的详细预测信息;于是得到l个g
t
向量;
[0032]
b)同一个聚类中其他调度车(d
j
,e
j
,f
j
,v
j
)和当前调度车的状态信息(d1,e1,f1,v1);其中d
j
表示当前第j个调度车位置,e
j
,f
j
分别表示第j个调度车当前已经搬运单车量和剩余可承载单车量;
[0033]
c)系统的状态h,包括天气、温度、调度车的数量信息;
[0034]
d)共享单车车站在其他(公交)交通系统中的状态o。
[0035]
进一步的,还定义共享单车系统共享单车的动作、奖励和停止条件如下:
[0036]
动作:定义为当前调度车将要在哪个共享单车站点卸载或者装载单车以及相应操作的数量;这里用一个(d1,v1)向量表示其位置以及详细的操作单车数目;
[0037]
奖励:整个周期的用户使用单车次数总和;
[0038]
停止条件:某一用户等了p个时间片段未等到公交车或者完成一个完整的周期。
[0039]
进一步的,对于深度强化学习算法ddpg其优化迭代过程如下,具体的输入为公交车调度和共享单车系统中所定义的状态集合,算法输出为调度的动作a
t
;
[0040]
1)初始化actor-critic网络的参数θ
q
和θ
μ
;
[0041]
2)actor根据动作策略选择一个具体的动作a
t
,并在执行该动作a
t
=μ(s
t
|θ
u
)+b
t
;
[0042]
动作a
t
是根据当前的策略函数μ和随机噪音b
t
联合产生;其中状态s
t
为算法的输入,具体的为公交车调度和共享单车系统中所定义的状态集合;
[0043]
3)仿真环境执行动作,并产生对于的奖励r
t
和新的状态s
t+1
,并将(s
t
,a
t
,r
t
,s
t+1
)这个状态转换过程保存起来称为r;从r从采用n个状态转换数据,作为策略网络和动作价值网络q网络的mini-batch数据;
[0044]
4)计算q网络的梯度,其loss定义如下:
[0045][0046]
并根据梯度更新参数θ
q
,y
i
为实际的预测值;
[0047]
5)计算策略网络的policy gradient,策略梯度算法如下:
[0048][0049]
并更新参数μ
′
和q
′
。
[0050]
进一步的,所述步骤3包括:
[0051]
对于输入的预测的各类交通流量图的表征,以及所需调度地点的各类交通资源状态表征信息,输入到所建立的强化学习模型中作为状态;
[0052]
本发明中的方法相较于以往的框架有如下优势:
[0053]
(1)状态的表示包含了未来详细预测信息的更加清晰,更利于策略收敛。以往框架中的关于交通需求的预测表示,无法避免该文中所提到的案例,而本发明的状态表示更加详细,能够更大程度避免局部贪心策略。
[0054]
(2)使用深度强化学习算法ddpg,首先它是一种actor-critic网络,同时兼顾了value-based和policy-base方法的优势,其次在actor网络内部使用lstm,能综合考虑状态历史信息。
[0055]
(3)考虑的不同交通系统之间的相互作用,这种作用可能是一种竞争关系也可能是协同关系。
附图说明
[0056]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0057]
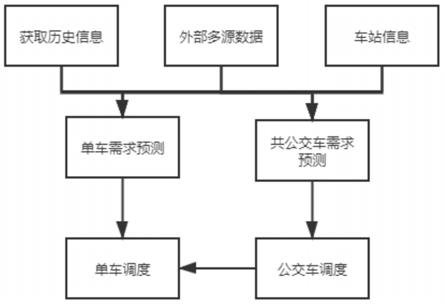
图1为调度系统的框架图;
[0058]
图2为共享单车和公交车调度算法中的强化学习状态的表示图。
具体实施方式
[0059]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0060]
根据本发明的一个实施例,提出一种基于城市公共交通资源联合调度方法,包括公交车系统客流量的预测,对共享单车流动情况进行预测,对公交车系统和共享单车系统进行联合优化调度,具体如下:
[0061]
1)公交车系统客流量的预测
[0062]
由于公交车站的日客流量时间序列呈现较强的规律性,为了减小计算量,对于每个站点都使用简单的线性模型模拟其过去一段时间的时间序列,例如一天内过去每半小时的客流量,若某段时间公交站还未营业取0即可,并对其未来较短的时间范围内(例如未来半小时)的客流量进行预测。对于第i个车站的时间序列其线性模型为:
[0063]
y
i
=αx
i
+β
[0064]
其中α和β为模型训练的参数,y
i
为预测的流量。对于整个公交系统的客流量预测依旧使用相同的方法,同样对其进行线性模型的建模。因为对各个车站的流量进行单独的预测不能保证其总和与公交系统的总流量保持一致,本发明使用分层时间序列预测方法中的求和矩阵将整个问题转化为一个需要优化的机器学习回归问题从而对各个车站的预测值进行调整,使得最后的预测结果更为准确并保证低层的(车站)聚合值与高层(公交系统)的值相等,即:
[0065][0066]
其中,y为公交系统预测的总客流量,n为车站的个数,∈为误差,需要注意的是,由于节假日和工作日公交系统的客流量时间序列差异较大,将节假日和工作目的数据分开进行单独的训练和预测。
[0067]
2)共享单车流动情况进行预测
[0068]
首先对于每个站点在未来一段时间内的车辆离开情况,使用长短期循环记忆神经网络lstm对其进行建模,共享单车站点的时间序列规律性不强,因此对于关注于短期内变
化复杂的时间序列,需要使用更为复杂的模型对其建模。
[0069]
对于一个时间序列s={x1,x2,...,x
t
},lstm随时间t=1,2...,t更新其中的状态向量c={c1,c2,...,c
t
}和隐向量h={h1,h2,...,h
t
}。其中的计算方式如下:
[0070]
i
t
=σ(w
xi
x
t
+w
hi
x
t-1
+b
i
)
[0071]
f
t
=σ(w
xf
x
t
+w
hf
x
t-1
+b
f
)
[0072]
c
t
=f
t
·
c
t-1
+i
t
·
τ(w
xc
x
t
+w
hc
h
t-1
+b
c
)
[0073]
o
t
=σ(w
xo
x
t
+w
ho
x
t-1
+b
o
)
[0074]
h
t
=o
t
·
τ(c
t
)
[0075]
其中i
t
,f
t
,o
t
分别是输入门、遗忘门和输出门,c
t
表示的是当前状态。σ(
·
),τ(
·
)分别是sigmoid(
·
)tanh(
·
)非线性激活函数。
·
是元素乘操作。w
*
和b
*
是模型的参数,最后一个时间步的输出经过全连接层得到预测值。
[0076]
考虑站点间的单车移动情况,由于共享单车没有固定的线路,因为单车离开站点a时,其同组内其他站点都有可能成为终点。对于该问题,本发明使用了频率代替概率的方法,即从过去相对较长的一段时间内(例如一周)共享单车的使用数据中计算站点a出发的单车到其他站点的概率,则预测站点a在未来一段时间内流动到b站点的单车数目时,只需用站点a的预测单车离开量和a->b站点的概率相乘即可。
[0077]
3)对公交车系统和共享单车系统进行强化学习调度建模
[0078]
[1].公交车调度
[0079]
1.状态
[0080]
对于公交车强化学习,定义状态如下如图2所示,包含四个部分:
[0081]
a)对于公交站点的观测,其中b1,b2分别表示上一班次公交车从两个方向经过此车站的时间间隔,和表示所预测未来交通流入量和流出量;l表示未来时刻;
[0082]
b)对于同一班线其他公交车的状态信息(d
j
,e
j
,f
j
,v
j
)和当前公交车的状态信息(d1,e1,f1,v1);其中d
j
表示当前第j个公交车位置,e
j
,f
j
分别表示第j个公交车当前载客量和剩余可承载多少客量;v
j
表示第j个公交车当前的操作类型;
[0083]
c)系统的信息h,如天气、温度、相邻两站之间的时间距离和地理距离等;
[0084]
d)当前路线公交车车站在其他公交车路线的状态o,比如可以是其他路线车站的中的(b1,b2);
[0085]
2.动作
[0086]
一辆公交车的动作有两个,向终点方向开,向起点方向开,在终点或者起点停。
[0087]
3.奖励
[0088]
对于公交车强化学习,定义奖励机制如下:
[0089]
a)公交车每次从a到b行程,奖励为减少的等待时间,(惩罚)到a的行驶时间,车行驶数目;
[0090]
b)公交车调转方向,转向操作惩罚为一个常数c,以及l*当前乘客数量,l为惩罚系数;
[0091]
c)公交车不开车,没有奖励和惩罚;
[0092]
4.停止条件
[0093]
某一用户等了p个时间片段未等到公交车或者完成一个完整的周期。
[0094]
[2].共享单车调度
[0095]
1.状态
[0096]
对于共享单车调度优化,这里的状态分为四个部分,如图2所示:
[0097]
a)共享单车车站的状态其中b1,b2分别表示当前单车可用单车量和可停放单车量,和表示所预测未来单车流入量和流出量;本发明考虑了更加细致的站点间的单车流动信息,并使用l个矩阵g
t
表示未来l段时间中所预测站点间单车的流动网络。直接这样用矩阵表示状态会导致最终的状态维度非常大,这里对其进行编码(encoder)得到g
t
∈r
d
代表未来t时刻的预测的交通流量低维状态表示,作为对未来t时刻站点的详细预测信息。于是可以得到l个g
t
向量,这样操作更加全面的描述单车交通网络,简化了状态的表示,更有利于策略的收敛和智能体的探索和利用。
[0098]
b)同一个聚类中其他调度车(d
j
,e
j
,f
j
,v
j
)和当前调度车的状态信息(d1,e1,f1,v1);其中d
j
表示当前第j个调度车位置,e
j
,f
j
分别表示第j个调度车当前已经搬运单车量和剩余可承载单车量;
[0099]
c)系统的状态h,包含如天气、温度、调度车的数量等信息;
[0100]
d)共享单车车站在其他(公交)交通系统中的状态o,比如可以是公交系统中的(b1,b2);
[0101]
2.动作
[0102]
一个动作定义为当前调度车将要在哪个共享单车站点卸载或者装载单车以及相应操作的数量。这里用一个(d1,v1)向量表示其位置以及详细的操作单车数目。
[0103]
3.奖励
[0104]
整个周期的用户使用单车次数总和。
[0105]
4.停止条件
[0106]
某一用户等了p个时间片段未等到公交车或者完成一个完整的周期。
[0107]
[3].深度强化学习算法
[0108]
对于深度强化学习算法ddpg(deep deterministic policy gradient)其优化迭代过程如下,具体的输入为[1]公交车调度和[2]中所定义的状态集合,算法输出为调度的动作a
t
;
[0109]
1.初始化actor-critic网络的参数θ
q
和θ
μ
;
[0110]
2.actor根据动作策略选择一个具体的动作a
t
,并在执行该动作a
t
=μ(s
t
|θ
u
)+b
t
;
[0111]
动作a
t
是根据当前的策略函数μ和随机噪音b
t
联合产生;其中状态s
t
为算法的输入,具体的为[1]公交车调度和[2]中所定义的状态集合;
[0112]
3.仿真环境执行动作,并产生对于的奖励r
t
和新的状态s
t+1
,并将(s
t
,a
t
,r
t
,s
t+1
)这个状态转换过程保存起来记为集合r。从集合r中采样出n个状态转移,作为策略网络和动作价值网络q网络的mini-batch数据;
[0113]
4.计算q网络的梯度,其损失定义如下:
[0114][0115]
并根据梯度更新参数θ
q
,y
i
为实际的预测值;
[0116]
5.计算策略网络的policy gradient,策略梯度算法如下:
[0117][0118]
并更新参数μ
′
和q
′
;
[0119]
[4].联合交通调度系统流程
[0120]
调度系统的框架图如图1所示,首先从外部获取到不同区域不同时刻的各类交通流量数据,一些可影响或反映交通状态的多源数据以及各站点的实时交通资源需求数据,将其输入到流量预测系统中,根据1)中公交车系统客流量预测系统的和2)中的单车流量预测系统中来预测未来时刻各站点的交通资源需求。最后再将获取的各站点实时状态数据和所预测的流量数据输入到强化学习框架中,根据3)中所描述来进行模型迭代优化,最后得到收敛的模型进行交通资源的联合调度。
[0121]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1