基于遗传算法与长短时神经网络的股票价格预测方法与流程
[0001]
本发明涉及深度学习领域,构建了基于遗传算法和长短时神经网络的股票价格预测方法,能够有效提高股票预测精度。
背景技术:
[0002]
随着社会经济的飞速发展,上市公司的数量越来越多,股票因而成为金融领域的热门话题之一,股票的变化趋势往往在一定程度上影响着诸多经济行为的走向,因此股票价格的预测也受到越来越多学者的关注。影响股票价格的因素众多,随着统计技术在金融领域的日趋成熟,金融学者们挖掘了大量的股票市场的影响因子,并将它们量化为具体的数据用于对股票变化趋势的研究。
[0003]
拥有海量的金融数据作为支撑,为机器学习算法的实现提供了可能,越来越多的研究人员开始使用机器学习非线性预测模型对股票价格进行预测。随机森林和支持吃向量机是两种在机器学习领域取得成熟发展的机器学习技术。随机森林属于集成学习具有运算速率快、抗干扰能力强、精确率高等特点,支持向量机基于结构风险最小化的方法能够在很大程度上降低了模型陷入局部最优的可能性,这两项机器学习技术均被广泛运用于金融时序预测领域。
[0004]
对于多变量金融时序预测,有效的特征选择十分重要,在选择关键特征的同时去除冗余特征,能够有效提高模型的泛化能力。传统的特征选择方法主要有过滤法、嵌入法和包装法。然而,股票预测的特征选择研究还没有得到学者们足够的重视。本专利提出的遗传算法能够有效的得对股票多因子数据进行特征选择,找出符合当前情景得优化多因子组合。
[0005]
金融数据在更新过程中,数据同时还具有两个特性。一是时效性。所谓时效性是指数据随着时间的推移而数据对预测目标的贡献会逐渐失效。二是差异性。通常来说,新数据比旧数据更能反映当前数据的特点及变化趋势,则新数据比旧数据对预测目标的贡献要大。差异性是指有效数据因新旧程度对预测检测系统的贡献不同。随机森林和支持向量机算法无法解决金融数据的时效性和差异性。为了解决金融数据的时效性和差异性,提出在特征选择之后使用长短时神经网络(lstm)对输入数据进行模型训练。
技术实现要素:
[0006]
本发明的目的在于提高股票价格的预测精度。将多因子模型引入到股票预测中,股票市场具有海量的描述股票价格行情变化的股票因子,这些因子均为较为常用的典型的股票因子,但是典型并不意味着能够适用于所有的情况,本发明提出了一种遗传算法在初期对大量因子进行特征选择,遴选出更为适合当前场景的因子并结合lstm深度学习网络模型挖掘因子与股票之间复杂的非线性关系从而进行股票价格预测工作。
[0007]
本发明包括初阶段和模型训练阶段,具体步骤如下:阶段i:初始阶段
初始数据集s0包含所有股票因子n0个特征,设置种群大小m和dna尺寸大小n,其中n0=n;设置交叉率r和突变率l;设置迭代次数为100;第1步:首先,为每条用于表示问题潜在解的染色体设计二进制编码。形如[1,0,0,1,0,1
……
],1代表选取该因子,0代表不选,染色体长度为n。随机生成m条染色体初始化种群;第2步:计算每条染色体适应度函数,采用决定系数作为该遗传算法的适应度函数,决定系数反应了y的波动有多少百分比能被x的波动所描述,即表示特征变量x对目标值y的解释程度;其中,决定系数用表示,y为标签值,为预测值,为平均值,的取值范围是,越大,则代表该染色体x对y的解释能力越强,被遗传到下一代的可能性也更大;第3步:根据染色体适应度以及交叉率和突变率对种群进行选择、交叉、变异工作,迭代100次后终止,统计最终种群中各因子重要度排名,取排名前四分之一因子作为优化因子组合,样本数为n1。
[0008]
阶段ii:模型训练阶段模型训练阶段数据集s
1 包含n1个特征,共m0个样本,将数据集按7:3比例分为训练集和测试集,其中,训练集数据规模为[m
1, n1],测试集数据规模为[m
2, n1];第4步:设计lstm网络时间步为k,将连续k个时间段的数据样本整合为单个数据样本,从而将训练集数据规模整合为[m
1, k,n1], 测试集数据规模为[m
2, k,n1];第5步:初始化lstm网络模型超参数,将网络设置为三层,输入层、隐藏层、输出层,隐藏层神经元数量为n,输出层神经元数量为1,批处理数量设为p,迭代次数设为100;第6步:在训练集上训练lstm神经网络,根据反向传播原理迭代更新lstm网络参数:其中,、、、分别为遗忘门、输入门、更新门和输出门的权值矩阵, 、、、分别为遗忘门、输入门、更新门和输出门的偏置, 最终计算得到当前时刻的输出与当前时刻更新的细胞状态;第7步:测试集上评估模型精度,求均方误差mse,
附图说明
[0009]
图1本发明的系统结构图。
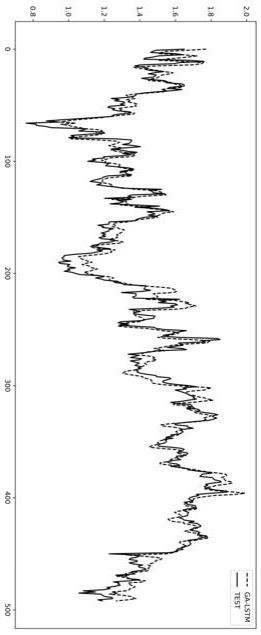
[0010]
图2ga-lstm模型预测结果对比图。
[0011]
图3ga-lstm与随机森林模型、支持向量机模型预测结果对比图。
[0012]
图4各模型均方误差mse对比图。
具体实施方式
[0013]
本发明的实施例是在以本发明技术方案为前提下进行实施的,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述实施例。
[0014]
详细步骤如下:步骤1:收集建设银行从2010年1月1日至2020年4月1日所有原始因子的历史数据并进行归一化和缺失值处理等数据预处理工作;步骤2:使用遗传算法对全部因子进行特征选择,获得优化因子组合;步骤3:设置lstm网络结构,确定超参数,随机初始化隐含层参数;步骤4:输入数据规范化,在训练集上训练lstm股票预测模型;步骤5:将测试集数据输入训练好的模型进行股票价格预测,并将预测结果与真实数据作绘图结果对比如图2;为了更好的说明算法的有效性,在如上所述的相同数据样本的基础上分别采用随机森林算法和支持向量机算法建立预测系统,并将之与本发明提出的ga-lstm算法建立的股票预测系统进行比较。各模型测试集股票预测结果对比如图3,均方差mse比较如图4。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1