基于深度学习的人流量检测方法与流程
[0001]
本发明涉及人工智能技术领域,具体涉及一种基于深度学习的人流量检测方法。
背景技术:
[0002]
随着科学技术的飞速发展和经济水平的不断提高,人们对生活的要求越来越高,从而推动了人工智能的快速发展,并逐步应用到各个领域。在公园、文化广场等场所,存在许多大人推婴儿车散步的现象。在诸如传染病疫情的特殊时期,为了加强对人们、特别是抵抗力较弱的婴幼儿的防护,可通过视频监控检测行人和婴儿车。将婴儿车计入人流量的检测范围,不仅能够为该场所提供有效人流量数据,也能及时疏散密集人群,预防踩踏事件及过度聚集等事件造成的公共安全事故。
[0003]
本发明基于深度学习的理论,常用的卷积神经网络模型有:alexnet,vgg,googlenet,inception-v3。该类大型模型只能在高性能平台上使用,不能移植到计算能力较差的移动终端或嵌入式芯片中。从网络架构角度压缩的模型有:squeezenet,mobilenet。模型压缩减少了计算量,使得在移动端部署卷积神经网络成为可能。
[0004]
目标检测技术因其广泛的应用而成为计算机视觉领域的一个重要分支,为视频监控、车辆辅助驾驶、智能机器人等领域提供了重要的技术支持。要实现人流量检测方法,首先要对视频中的行人进行检测。
[0005]
目前目标检测方法有两类:
[0006]
(1)基于统计学习的目标检测方法:如haar级联,hog+线性svm。
[0007]
(2)基于深度学习的目标检测方法:如faster r-cnn,yolo和ssd。如果需要检测小物体并且不追求快速,则倾向于使用faster r-cnn;如果不追求精度但需要较快的速度,则使用yolo;如果需要中间立场,则倾向于使用ssd。mobilenet作为卷积神经网络的基础网络部分的卷积层,使用深度可分离卷积的卷积方式,代替传统卷积方式,然后结合ssd检测器算法的原理,抽取基础网络中的输出特征图,获取不同尺度的特征映射,同时在不同的特征映射上面进行预测,不同的特征对检测有不同的作用。即mobilenet的作用是用特征提取网络为ssd提供不同尺度的特征图。
技术实现要素:
[0008]
基于上述问题,本发明提出了一种为资源受限设备设计的、基于深度学习的、快速有效的人流量检测系统。本发明在基于深度学习的基础上,使用轻量级深度学习网络,设计用于大型活动现场,如公园、文化广场的视频监控下的人流量检测方法,能够检测婴儿车,加强对大人及婴幼儿的防护。
[0009]
基于深度学习的人流量检测方法,所采用技术方案包括:
[0010]
s1:获取图像文件列表,并建立数据与标签之间的一一映射,由此构成数据集。
[0011]
s2:构建深度学习检测模型mobilenet-ssd。通过步骤s1构成的数据集训练深度学习检测模型。具体地,训练过程中,取整个数据集的90%作为trainval文件,即训练集与验
证集,再取trainval的90%作为训练集,训练集与验证集数据之间没有重复,训练集用于训练模型以及模型权重,验证集用于确定网络结构以及调整模型的超参数。训练完成后,保存训练后的深度学习检测模型及相关文件,其中相关文件为:参数文件solver_train.prototxt,包括的参数例如基本学习率base_lr:0.0005、每次迭代1000步之后产生一个当前的caffemodel和状态文件即snapshot:1000、训练方式solver_mode:gpu;网络文件,即定义网络的文件,包括网络输入层的输入数据类型、resize图片分辨率、定义网络学习率、卷积核个数、卷积核大小、卷积核步数、卷积核权值初始化方法。
[0012]
s3:使用python构建数据输入模块初始化视频检测数据文件,所述视频检测数据文件即输入视频流。
[0013]
s4:使用python构建行人检测模块。调用步骤s2训练好的深度学习检测模型,将步骤s3中数据输入模块初始化后的视频流,输入该行人检测模块,对行人进行检测。
[0014]
s5:使用python构建追踪模块。通过追踪模块,对步骤s4中检测到的行人进行追踪。
[0015]
s6:使用python构建结果输出模块,通过结果输出模块处理步骤s5追踪的数据,保存并输出,以显示人流量检测结果。
[0016]
进一步地,步骤s1中数据集采用网络爬虫的方式,爬取大量婴儿车数据集,并结合voc数据集的类别为“person”的数据,合并制作自己的数据集,并建立数据与标签之间的一一映射。
[0017]
进一步地,步骤s2中mobilenet-ssd网络总共有35层,深度学习检测模型mobilenet-ssd包含连续的标准卷积层、连续的深度可分离卷积层、检测模块、非极大值抑制算法。
[0018]
进一步地,步骤s3中直接用命令行调用视频检测数据文件,视频检测数据文件包括预存检测数据:.mp4、.avi格式的视频,和实时检测数据:摄像头获取的视频;将该检测数据输入到步骤s3中的数据输入模块。
[0019]
进一步地,步骤s3数据输入模块初始化视频检测数据文件后进行数据预处理,所述视频检测数据文件即输入视频流,判断数据预处理后的输入视频流是否达到视频结尾,若是,则处理数据并保存;若否,则在等待预设时间后进一步判断是否达到跳过帧,若达到跳过帧,则通过步骤s4中的行人检测模块启动检测器,对预处理后的输入视频流进行目标检测,识别出其中的行人;若没有达到跳过帧,则通过步骤s5中的追踪模块启动追踪器,对行人进行追踪,对行人进行追踪采用质心跟踪算法和dlib跟踪器实现;直到对数据预处理后的输入视频流完成检测跟踪。
[0020]
具体地,所述mobilenet-ssd主要使用了深度可分离卷积将标准卷积核进行分解计算,减少了计算量,引入了两个超参数:宽度乘数和分辨率乘数来减少参数量和计算量,这两个超参数分别减少输入输出的channels和feature map的大小。
[0021]
具体地,所述mobilenet-ssd模型的第一层input为卷积核大小为3*3的标准卷积层,输入特征图的分辨率为300*100*3,接着是13个深度可分离卷积层,conv0大小为150*150*32,conv1大小为150*150*64,conv2/3大小为75*75*128,conv4/5大小为38*38*256,co nv6/7/8/9/10/11大小为19*19*512,conv12/13大小为10*10*1024,接着是8个标准卷积层,conv14_1大小为10*10*256,conv14_2大小为5*5*512,conv15_1大小为5*5*128,co nv15_2
大小为3*3*256,conv16_1大小为3*3*128,conv16_2大小为2*2*256,conv17_1大小为2*2*64,conv17_2大小为1*1*128。其中,每一个深度可分离卷积层包含1层深度卷积层和1层点卷积层。模型总共抽取6层用作ssd检测网络框架,它们的大小和层数分别为19*19*512(conv11)、10*10*1024(conv13)、5*5*512(conv14_2)、3*3*256(conv15_2)、2*2*256(conv16_2)、1*1*128(conv17_2),原始图像经过卷积后得到数据,即特征映射图(featur e map),特征映射图包含了原始图像的信息,用多个卷积层后的特征映射图来定位和检测原始图像的物体。
[0022]
本发明基于深度学习神经网络,结合轻量级mobilenet-ssd框架,克服了模型过于庞大,面临着内存不足的缺点,具体地,基于深度学习对象检测方法的人流量检测系统具有以下优点:1)检测精度高:通过深度学习神经网络,对自己的数据集训练,可以检测特定类别,提高人流量检测准确度;2)实用性高:采用轻量级深度网络模型,在保持模型性能的前提下,能降低模型大小同时提升速度,克服了主流卷积神经网络模型计算资源消耗大的缺点,适用于如移动或者嵌入式设备,要求低延迟、响应速度快;3)适用于特殊场景,如婴儿车数量多、行人移动速度慢的公园、文化广场等场所。
附图说明
[0023]
图1为本发明的深度可分离卷积的基本结构。
[0024]
图2为本发明的mobilenet-ssd网络模型结构图。
[0025]
图3为本发明的深度学习网络模型检测测试图。
[0026]
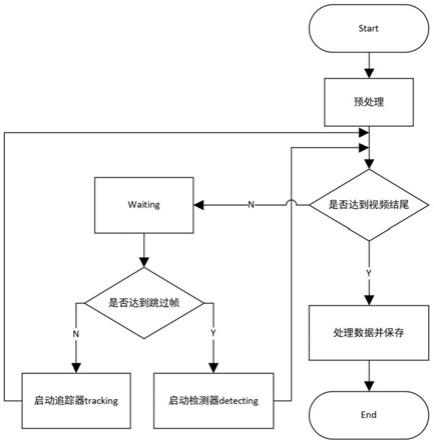
图4为本发明的人流量检测方法总体状态流程图。
[0027]
图5为本发明的目标检测流程图。
[0028]
图6为本发明的目标追踪流程图。
[0029]
图7为本发明的系统测试图。
具体实施方式
[0030]
下面结合附图对本发明的具体实施方式以及工作原理作进一步详细说明。
[0031]
如图1所示,为深度可分离卷积的基本结构。本发明使用的mobilenet-ssd网络模型,是为了适用于移动端而提出的一种轻量级深度网络模型。主要使用了深度可分离卷积将标准卷积核进行分解计算,减少了计算量。深度分离可卷积层是mobilenet-v1的基本组件,在真正应用中会加入batchnorm归一化操作,并使用relu激活函数。在mobilenet-v1中,深度可分离卷积成本通过引入的两个超参数:宽度乘数width multiplierα和分辨率乘数reso lution multiplierρ分别对输入输出通道数(channel)、图像分辨率(resolution)进行压缩,减少计算量,加速网络的计算。深度可分离卷积首先按照通道数进行按位相乘的计算,此时通道数不改变;然后将结果使用1*1的卷积核进行传统的卷积运算,此时通道数可以进行改变,其计算量为dk*dk*m*df*df+1*1*m*n*df*df(dk卷积核大小,m输入维度,df输入大小,n输出维度)。宽度乘数α主要用于减少channels,即输入层的channels个数m,变成αm,输出层的channels个数n变成了αn,所以引入宽度乘数后的总的计算量是:dk*dk*αm*df
·
df+αm*αn*df*df(dk卷积核大小,m输入维度,df输入大小,n输出维度,α宽度乘数);分辨率乘数ρ主要用于降低图片的分辨率,即作用在feature map上,所以引入分辨率乘数后
的总的计算量为:dk*dk*αm*ρdf*ρdf+αm*αn
·
ρdf*ρdf(dk卷积核大小,m输入维度,df输入大小,n输出维度,α宽度乘数,ρ分辨率乘数)。由于深度卷积中卷积核只操作单个通道,因此95%的计算量都集中在点卷积中的1x1卷积中。当dk=3时,深度可分离卷积比传统卷积少8到9倍的计算量。
[0032]
如图2所示,为本发明使用的mobilenet-ssd模型的整体结构,首先关于基础网络部分,mobilenet-ssd从conv0到conv13的配置与mobilenet v1(即上一段介绍的基本结构)模型是完全一致的,相当于只是去掉mobilenet v1最后的全局平均池化、全连接层和softmax层;
[0033]
再看ssd部分,conv13是骨干网络的最后一层,mobilenet-ssd在mobilenet的conv13后面添加了8个卷积层。
[0034]
因此,mobilenet-ssd模型的整体结构,第一层(conv0)为卷积核大小为3
×
3的标准卷积层。接着是连续的深度可分离卷积层(conv1-conv13),包含13层深度卷积层和13层点卷积层。深度可分离卷积层后面为卷积核大小为1
×
1标准卷积层(conv14-conv17)。ssd将b ounding box的输出空间离散成一系列具有不同纵横比的default box,并可以调整box以更好地匹配对象的形状。其次,将不同分辨率的feature map上的预测结果结合起来,解决了不同大小对象的问题。最后从六个不同尺度的特征图上提取特征来做检测,它们的大小分别为19*19*512、10*10*1024、5*5*512、3*3*256、2*2*256、1*1*128。mobilenet-ssd模型最后使用nms(non-maximum-suppression)非极大抑制算法,获取局部最大值。
[0035]
深度学习检测模型mobilenet-ssd训练的开发环境为ubuntu16.04+cuda8.0+cudnn6.0+opencv3.1+caffe,训练迭代35000次后,达到较好的效果,如图3,经测试,模型能够很好地检测图片中的人与婴儿车。
[0036]
如图4所示,为本发明实现的人流量检测方法的总体状态流程,其开发环境为pycharm+anaconda,涉及数据输入模块、行人检测模块、追踪模块和结果输出模块:
[0037]
s1:获取图像文件列表,并建立数据与标签之间的一一映射,由此构成数据集。
[0038]
s2:构建深度学习检测模型mobilenet-ssd。通过步骤s1构成的数据集训练深度学习检测模型。具体地,训练过程中,取整个数据集的90%作为trainval文件,即训练集与验证集,再取trainval的90%作为训练集,训练集与验证集数据之间没有重复,训练集用于训练模型以及模型权重,验证集用于确定网络结构以及调整模型的超参数。训练完成后,保存训练后的深度学习检测模型及相关文件,其中相关文件为:参数文件solver_train.prototxt,包括的参数例如基本学习率base_lr:0.0005、每次迭代1000步之后产生一个当前的caffemodel和状态文件即snapshot:1000、训练方式solver_mode:gpu;网络文件,即定义网络的文件,包括网络输入层的输入数据类型、resize图片分辨率、定义网络学习率、卷积核个数、卷积核大小、卷积核步数、卷积核权值初始化方法。
[0039]
s3:使用python构建数据输入模块初始化视频检测数据文件,所述视频检测数据文件即输入视频流。
[0040]
s4:使用python构建行人检测模块(行人检测模块调用深度学习检测模型进行检测)。调用步骤s2训练好的深度学习检测模型,将步骤s3中数据输入模块初始化后的输入视频流,输入该行人检测模块,对行人进行检测,即通过行人检测模块启动检测器,对初始化后的输入视频流进行目标检测。
[0041]
s5:使用python构建追踪模块。通过追踪模块,对步骤s4中检测到的行人进行追踪,即通过追踪模块启动追踪器,对行人进行追踪。
[0042]
s6:使用python构建结果输出模块,通过结果输出模块处理检测追踪的数据,保存并输出,以显示人流量检测结果。
[0043]
步骤s3的初始化包括以下过程:初始化视频流、初始化视频编写器、初始化框架尺寸、初始化存储列表。如果不使用已有视频文件,将使用摄像头,并处理摄像头视频流。状态初始化为“waiting”,在这种状态下,等待对行人的检测和跟踪。其余可能的状态包括“detec ting”和“tracking”,该过程分别的功能为调用检测模型检测行人,对行人进行跟踪。
[0044]
数据输入模块初始化视频检测数据文件后,所述视频检测数据文件即输入视频流,进行数据预处理,判断数据预处理后的输入视频流是否达到视频结尾,若是,则处理数据并保存;若否,则在等待预设时间后进一步判断是否达到跳过帧,若达到跳过帧,则通过步骤s4中的行人检测模块启动检测器,对预处理后的视频流进行目标检测,识别出其中的行人;若没有达到跳过帧,则通过步骤s5中的追踪模块启动追踪器,对行人进行追踪,对行人进行追踪采用质心跟踪算法和dlib跟踪器实现;直到对数据预处理后的输入视频流完成检测跟踪。
[0045]
数据预处理包括加载预训练模型、调整通道的大小、将帧从bgr到rgb转换。检测模型使用mobilenet-ssd模型。调整视频框架大小,为了使数据越少、处理速度越快,设置其最大宽度为500像素。
[0046]
判断是否达到跳过帧的目的是为了加快跟踪流程,避免在每帧上运行目标检测器进行检测,将根据实际情况跳过n帧(默认30),只有每n帧才使用ssd进行目标检测,除此之外将只是在每帧之间追踪移动的对象。
[0047]
如图5所示,为步骤s4对行人进行检测,即目标检测,包括以下过程:提取置信度(目标检测输出的是类别的置信度,目标检测分类器给出预测类别的概率,而分类器本身的结果是否可靠是根据置信度来评判)、过滤弱检测、提取标签、将对象传递输出给跟踪器。通过要求置信度最低限度来过滤掉弱检测。
[0048]
如图6所示,为步骤s5对行人进行追踪,即目标追踪,包括以下过程:获取坐标、获取质心、计算新旧质心欧式距离、判断追踪对象、处理追踪对象。
[0049]
a.通过行人检测模块输入的对象,获取边界框坐标。
[0050]
b.使用步骤a得到的边界框坐标来计算质心(即边界框的中心)。
[0051]
c.通过步骤b计算出的质心计算新质心和现有质心之间的欧几里得距离。
[0052]
d.如果新质心有与之关联的现有质心,则基于步骤c计算的欧几里得距离,追踪器选择关联各自欧几里得距离最小的质心,关联对象id后,将跟踪的对象质心更新到其新质心位置;如果新质心没有与之关联的现有质心,则注册新的对象id,并存储质心。
[0053]
e.将步骤d跟踪对象添加到计数列表。当对象离开视野,可以注销该物体(进出视频区域的对象计数,通过判断对象相对于基准线的移动方向来确定)。
[0054]
步骤s5同时使用dlib跟踪器,将对象边界框在前一帧中位置的先验信息,与从当前帧中获得的数据进行组合,以推断出对象的新位置在哪里。结合质心跟踪算法和dlib跟踪器可以在检测到的目标周围提供边界框并识别哪些边界框属于同一目标。
[0055]
步骤s6输出模块处理追踪数据包括以下过程:显示人流量信息、保存视频文件、释放指针、关闭窗口。该步骤绘制一条水平线,将其用于可视化行人的“穿越”,即,一旦行人越过该线,将增加各自(进或出)的计数器,通过质心跟踪算法会将对象id与对象位置相关联,计算出进出该画面的人流量。
[0056]
使用opencv进行基于深度学习网络模型mobilenet-ssd的目标检测,实现本发明的人流量检测方法,在计算机cpu型号i5-7200、内存大小8gb的环境下,本发明实现的人流量检测方法的测试结果如图7(a)、图7(b)、图7(c)、图7(d)所示,分别表明视频监控中检测到行人正在进入监控区域、监控区域中未出现行人、行人正在离开该区域、监控中检测到婴儿车。监控状态由status表示,分别为detecting检测、tracking追踪、waiting等待,并且整个过程在对行人进行计数,通过down(表示摄像头俯视角度时,目标对象向画面上方移动)和up(表示摄像头俯视角度时,目标对象向画面下方移动)的数值分别表示进入和离开该视频监控区域的人数。
[0057]
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合;本领域的技术人员根据本发明技术方案的技术特征所做出的任何非本质的添加、替换,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1