人体姿势辨识系统、人体姿势辨识方法以及非暂态计算机可读取储存媒体与流程
1.本案是有关于一种辨识系统及辨识方法,且特别是有关于一种人体姿势辨识系统以及人体姿势辨识方法。
背景技术:
2.人体姿势辨识方法广泛运用于公共场所,目的在于透过人体姿势的辨识来判别在场域之中人员的状态,以维护场域中人员的安全。例如在道路、交通环境、或是大众运输公共场所,当有人跌倒时,除了造成人员的受伤或生命危害而需要受到即时关注,跌倒还会导致场域的混乱而造成公共安全的危害。
3.为维护及掌握场域中人员的状态,公共场所会设置摄影机来监控现场。然而目前的影像处理技术会受摄影机拍摄到现场的场域复杂度、拍摄角度、光线变化等变数,造成不易在影像中正确地判别现场人员的状态。当场域复杂或人数众多造成人员交叠状况时,经常无法取得每个人员的完整影像,且目前影像辨识演算法多采用灰阶影像来运算,更无法判断人员的左右边或是远近,更难以辨识影像中的内容。这样的情况,会影响辨识模型的训练以及后续的影像辨识。
技术实现要素:
4.发明内容旨在提供本揭示内容的简化摘要,以使阅读者对本案内容具备基本的理解。此发明内容并非本揭示内容的完整概述,且其用意并非在指出本案实施例的重要/关键元件或界定本案的范围。
5.根据本案的一实施例,揭示一种人体姿势辨识系统,其包含来源影像装置、储存装置以及处理装置。来源影像装置用以接收多个待辨识影像。储存装置用以储存姿势辨识模型,其中姿势辨识模型是用以输入骨架影像后可输出人体姿势辨识结果。骨架影像包含有骨架,且骨架包含有多个关节及多个肢体。各肢体具有对应的肢体颜色,且各肢体颜色彼此不同。处理装置耦接于来源影像装置及储存装置。处理装置经配置以执行以下操作:从所述多个待辨识影像产生所述多个骨架影像;将所述多个骨架影像分别输入该姿势辨识模型,以输出对应的该人体姿势辨识结果;以及根据对应的该人体姿势辨识结果,判断是否发出一异常信息。
6.根据一实施例,该姿势辨识模型是采用多个训练影像进行一训练而产生,且该姿势辨识模型的训练是经由该处理装置,使用所述多个训练影像来获得多个训练骨架影像,使得每一所述多个训练骨架影像中的各该肢体具有对应的该肢体颜色,并标记每一所述多个训练骨架影像所对应的该人体姿势辨识结果,以及,根据具有对应该肢体颜色的所述多个训练骨架影像以及所对应的该人体姿势辨识结果,训练并产生该姿势辨识模型。
7.根据一实施例,所述多个训练骨架影像是经由该处理装置使用所述多个训练影像中对应每一所述多个训练骨架影像的一人体图片的一像素数目来计算一空间特征,根据各
该训练影像中的多个人体关键点坐标及该人体图片的该空间特征来获得所述多个训练骨架影像。
8.根据一实施例,一特定骨架的各该肢体的线条粗细,是依据该骨架影像所对应的该人体图片于该待辨识影像中的该像素数目的一比例而决定。
9.根据一实施例,当该骨架影像所对应的该人体图片于该待辨识影像中的一像素数目的一比例越高时,该骨架的各该肢体的线条越细,当该比例越低时,该骨架的各该肢体的线条越粗。
10.根据一实施例,该空间特征包含该骨架影像所对应的该人体图片的一景深信息,以透过该景深信息调整该人体图片的该骨架影像的各该肢体的线条的粗细。
11.根据一实施例,当该人体图片的景深信息指示人体的距离越远,该人体图片的该骨架影像的骨架线条越粗,以及当该人体图片的景深信息指示人体的距离越近,该人体图片的该骨架影像的骨架线条越细。
12.根据一实施例,该处理装置更经配置以从所述多个待辨识影像中取出至少一人体图片,从每一该人体图片中取得其对应的多个人体关键点坐标,使用所述多个人体关键点坐标之间的连线来获得每一所述多个人体所对应的骨架影像及其所述多个肢体。
13.根据一实施例,各该人体关键点坐标对应于该骨架影像的所述多个关节之一。
14.根据一实施例,该处理装置更经配置以等比例调整该骨架影像的尺寸,以使用经调整的该骨架影像来训练该姿势辨识模型。
15.根据另一实施例,揭示一种人体姿势辨识方法,包含以下步骤:接收多个待辨识影像;从所述多个待辨识影像产生多个骨架影像,其中该骨架影像包含有一骨架,且该骨架包含有多个关节及多个肢体,且各该肢体具有对应的一肢体颜色,且各该肢体颜色彼此不同;将所述多个骨架影像分别输入一姿势辨识模型,以输出对应的一人体姿势辨识结果;以及根据对应的该人体姿势辨识结果,判断是否发出一异常信息。
16.根据一实施例,还包含:采用多个训练影像进行一训练而产生该姿势辨识模型;使用所述多个训练影像来获得多个训练骨架影像,使得每一所述多个训练骨架影像中的各该肢体具有对应的该肢体颜色;标记每一所述多个训练骨架影像所对应的该人体姿势辨识结果;以及根据具有对应该肢体颜色的所述多个训练骨架影像以及所对应的该人体姿势辨识结果,训练并产生该姿势辨识模型。
17.根据一实施例,还包含:使用所述多个训练影像中对应每一所述多个训练骨架影像的一人体图片的一像素数目来计算一空间特征;以及根据各该训练影像中的多个人体关键点坐标及该人体图片的该空间特征来获得所述多个训练骨架影像。
18.根据一实施例,还包含:依据该骨架影像所对应的该人体图片于该待辨识影像中的该像素数目的一比例而决定一特定骨架的各该肢体的线条粗细。
19.根据一实施例,当该骨架影像所对应的该人体图片于该待辨识影像中的一像素数目的一比例越高时,该骨架的各该肢体的线条越细,当该比例越低时,该骨架的各该肢体的线条越粗。
20.根据一实施例,该空间特征包含该骨架影像所对应的该人体图片的一景深信息,该人体姿势辨识方法还包括透过该景深信息调整该人体图片的该骨架影像的各该肢体的线条的粗细。
21.根据一实施例,还包含:从该多个待辨识影像中取出至少一人体图片;从每一该人体图片中取得其对应的多个人体关键点坐标;以及使用所述多个人体关键点坐标之间的连线来获得每一所述多个人体所对应的骨架影像及其所述多个肢体。
22.根据一实施例,各该人体关键点坐标对应于该骨架影像的所述多个关节之一。
23.根据一实施例,还包含:等比例调整该骨架影像的尺寸,以使用经调整的该骨架影像来训练该姿势辨识模型。
24.根据另一实施例,揭示一种非暂态计算机可读取储存媒体,储存多个程序码,当所述多个程序码被载入至一处理器后,该处理器执行所述多个程序码以完成下列步骤:接收多个待辨识影像;从所述多个待辨识影像产生多个骨架影像;将所述多个骨架影像分别输入一姿势辨识模型,以输出对应的一人体姿势辨识结果,其中该骨架影像包含有一骨架,且该骨架包含有多个关节及多个肢体,且各该肢体具有对应的一肢体颜色,且各该肢体颜色彼此不同;以及根据对应的该人体姿势辨识结果,判断是否发出一异常信息。
附图说明
25.以下详细描述结合随附附图阅读时,将有利于较佳地理解本揭示文件的态样。应注意,根据说明上实务的需求,附图中各特征并不一定按比例绘制。实际上,出于论述清晰的目的,可能任意增加或减小各特征的尺寸。
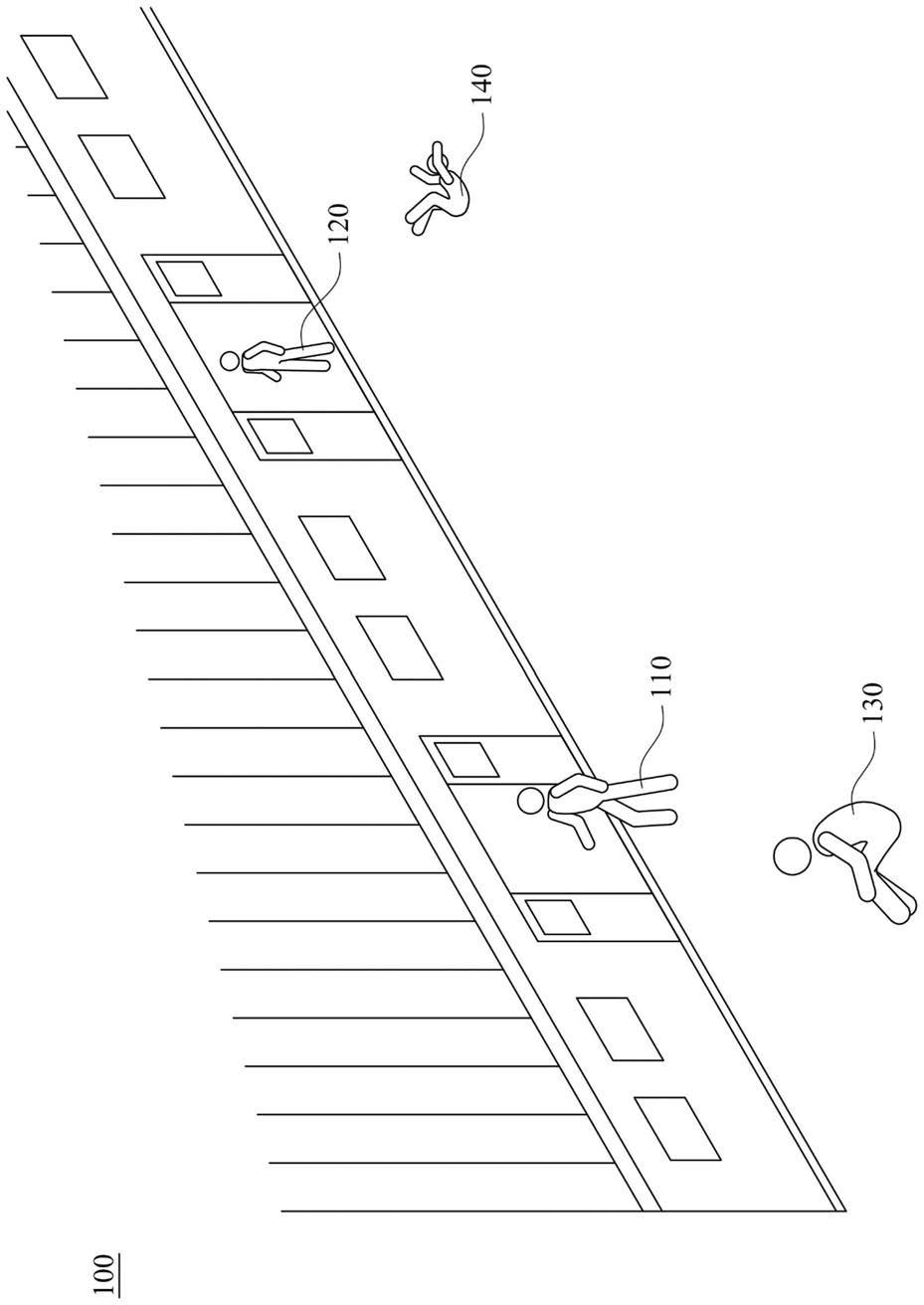
26.图1绘示根据本案一些实施例中在一场景拍摄的影片中的其中一待辨识影像的示意图。
27.图2绘示根据本案一些实施例中一种人体姿势辨识系统的示意图。
28.图3a至图3d绘示本案一些实施例中储存于姿势辨识模型的骨架影像的示意图。
29.图4绘示根据本案一些实施例中一种人体姿势辨识方法的流程图。
30.图5a至图5b绘示根据本案一些实施例中的调整骨架影像的示意图。
31.【符号说明】
32.100:待辨识影像
33.110~140:人体图片
34.200:人体姿势辨识系统
35.210:来源影像装置
36.220:处理装置
37.230:储存装置
38.310~340:骨架影像
39.311~314:关节
40.321~326:肢体
41.400:人体姿势辨识方法
42.s403~s420:步骤
43.510,520:骨架影像
具体实施方式
44.以下揭示内容提供许多不同实施例,以便实施本案的不同特征。下文描述元件及
排列的实施例以简化本案。当然,这些实施例仅为示例性且并不欲为限制性。举例而言,本案中使用“第一”、“第二”等用语描述元件,仅是用以区别以相同或相似的元件或操作,该用语并非用以限定本案的技术元件,亦非用以限定操作的次序或顺位。另外,本案可在各实施例中重复元件符号及/或字母,并且相同的技术用语可使用相同及/或相应的元件符号于各实施例。此重复是出于简明性及清晰的目的,且本身并不指示所论述的各实施例及/或配置之间的关系。
45.现今的保全监视系统相当发达,使用者可以取得在不同的场域中(例如捷运站、火车站、百货商场等)的监视摄影机的影片。现有的保全监视系统多是需仰赖中控人员随时地监视画面,透过监视画面来判断现场是否有意外事件发生。然而,这样的方法存在风险。若中控人员一时不注意或者显示屏幕有瑕疵或毁损等意外状况,将错失对现场状况的掌握。
46.参照图1,其绘示根据本案一些实施例中在一场域拍摄影片中的其中一待辨识影像100的示意图。待辨识影像100是在捷运月台的画面(scene)。为辨识影片中的人员是否有异常状态,使用者可以在这些影片(video)中取得一帧(frame)的影像(image)(或者称为图片(picture)),以此影像作为待辨识影像100,以判断此待辨识影像100中的人员是否有异常状态。于一些实施例中,待辨识影像100中包含人体图片,例如人体图片110、120、130及140。撷取人体图片的方法将说明如后。在捷运月台有多个乘客(如人体图片110及120)即将走进车厢。在捷运月台有乘客(如人体图片130)跌坐在地上。在捷运月台有乘客(如人体图片140)倒卧在地。
47.请参照图2,其绘示根据本案一些实施例中一种人体姿势辨识系统200的示意图。人体姿势辨识系统200可以透过辨识影像中的人体骨架,来实现自动侦测影像中的人体姿势。
48.如图2所示,人体姿势辨识系统200包含来源影像装置210、处理装置220以及储存装置230。来源影像装置210以及储存装置230耦接于处理装置220。
49.于一些实施例中,来源影像装置210会接收多个待辨识影像。待辨识影像可以是从即时串流或影片中所撷取出的任一影像。举例而言,若影片的影格率(frame per second,fps)是30fps,代表此影片每秒显示30帧。待辨识影像可以是影片中的任何一个静态的画面。于另一些实施例中,来源影像装置210也可以接收一即时串流(live stream),或者是预先储存的影片(video)后,从中撷取出多个待辨识影像。
50.于一些实施例中,储存装置230会储存一姿势辨识模型。姿势辨识模型于输入一骨架影像后,会输出一人体姿势辨识结果。举例而言,姿势辨识模型储存有多个骨架影像及对应的人体姿势。当待辨识影像被输入至姿势辨识模型后,若判断出待辨识影像中有骨架影像,则可进一步根据此骨架影像来辨识出人体的姿势,以输出人体的姿势结果。姿势辨识模型可以是卷积类神经网络(cnn)模型。卷积类神经网络可以是lenet、alexnet、vggnet、googlenet(inception)、resnet等模型,本案不限于此些模型。
51.于一些实施例中,处理装置220从这些待辨识影像产生姿势辨识模型所需要的骨架影像,骨架影像中包含一个以上的骨架。从影像中撷取出骨架影像的方法可以是人物肢体关键点侦测演算法。人物肢体关键点侦测演算法是透过侦测人体的关键点,例如关节,以通过这些关键点来描绘人体的骨胳或肢体信息。人物肢体关键点侦测演算法可以为但不限于openpose演算法、多人姿态估计演算法(regional multi-person pose estimation,
rmpe)、deepcut演算法、mask r-cnn演算法等,或者任何自行建构开发用来检测出人物肢体的演算法均可运用于本案。在执行人物肢体关键点侦测演算法而得到人体的关节位置之后,可根据关节位置的坐标连线,绘制出骨架影像。
52.值得一提的是,待辨识影像是从即时串流或影片中撷取出的画面或图片,一个待辨识影像中可能没有人体,或者有一个或以上的多个人体。经由处理装置220从一个待辨识影像产生骨架影像时,若待辨识影像中没有骨架影像,则不需要输入姿势辨识模型。待辨识影像亦可能会撷取到一个或多个骨架影像,而一个待辨识影像中的每一所述多个骨架影像都会逐一输入姿势辨识模型来进行辨识。
53.为进一步说明骨架影像于本案中的运作,请一并参照图1及图3a至图3d。图3a至图3d绘示本案一些实施例中储存于姿势辨识模型的骨架影像310至340的示意图。于一些实施例中,图3a的骨架影像310及图3b的骨架影像320是对应到站立的人体姿势。图3c的骨架影像330是对应到蹲坐的人体姿势。图3d的骨架影像340是对应到跌倒的人体姿势。值得一提的是,图3a至图3d绘示的骨架影像310至340仅为例示,姿势辨识模型中对应到每个人体姿势的骨架影像可以有多个,骨架影像的数量越多,越可以增加判断人体姿势的精确度。
54.于一些实施例中,每个骨架影像中的骨架包含多个关节及多个肢体。各肢体具有对应的肢体颜色,并且各肢体颜色彼此不同。举例而言,在计算出关节坐标之后,可以获得各关节坐标之间的连线(即肢体)的线条,来绘制骨架影像。
55.于一些实施例中,图3a的骨架影像310包括关节311、312、313及314。在关节311及312之间的肢体322为左上臂。在关节313及314之间的肢体325为右上臂。在关节311及关节313之间的肢体324为人体肩膀。在肢体324上方的肢体321为头部。在关节312至末端关节的肢体323为左下臂。在关节314至末端关节的肢体326为右下臂。以此类推,图3a仅标示部分肢体作为说明,而不限于此些肢体。
56.在一些实施例中,肢体321、322、323、324、325及326都具有对应的肢体颜色,并且每个肢体颜色都不同。举例而言,肢体321是红色,肢体322是浅绿色,肢体323是深绿色,肢体324是紫色,肢体325是黄色,以及肢体326是蓝绿色。由于各肢体颜色彼此不同,骨架便可以区分出人员的左半边或右半边,当骨架有比较复杂的交叠时,也比较容易进行判断,在辨识人体姿势的时候可以更精准。此外,由于人体距离摄影机的距离不同,所产生的骨架影像的精细和模糊样态也会有差异,为了能够将和摄影机距离不同的骨架分开进行比对,当该骨架影像所对应的该人体图片于该待辨识影像中的该像素数目的该比例越高时,该骨架的各该肢体的线条越细,当该比例越低时,该骨架的各该肢体的线条越粗。
57.于一些实施例中,处理装置220会从待辨识影像中取出人体图片,并人物肢体关键点侦测演算法,从人体图片中取得对应的多个人体关键点坐标。接着,处理装置220根据这些人体关键点坐标之间的连线,来获得人体所对应的骨架影像及其肢体。于一些实施例中,人体关键点坐标是对应于骨架影像的关节。
58.请复参照图1及图2,处理装置220用以从待辨识影像100中产生骨架影像。举例而言,处理装置220对图1的待辨识影像100执行人物肢体关键点侦测演算法,由于待辨识影像100有四个乘客,因此处理装置220可以产生分别对应到人体图片110至140的四个骨架影像(未绘示)。
59.于一些实施例中,处理装置220将产生的四个骨架影像分别输入至姿势辨识模型,
以输出人体姿势辨识结果。举例而言,处理装置220从人体图片110计算得到第一骨架影像(未绘示),并将第一骨架影像输入至姿势辨识模型。姿势辨识模型中预先储存有骨架影像(例如图3a至图3d的骨架影像310至340),逐一比对判断是否存在有相同或相似于第一骨架影像的骨架影像。本实施例中,可以在姿势辨识模型中得到相同或相似于第一骨架影像的骨架影像310,如图3a所示。由于骨架影像310对应至站立的人体姿势,因此,处理装置220输出的人体姿势辨识结果是站立姿势。
60.相似地,处理装置220从人体图片120计算得到第二骨架影像(未绘示),并将第二骨架影像输入至姿势辨识模型。本实施例中,可以在姿势辨识模型中得到相同或相似于第二骨架影像的骨架影像320,如图3b所示。由于骨架影像320对应至站立的人体姿势,因此,处理装置220输出的人体姿势辨识结果是站立姿势。
61.相似地,处理装置220从人体图片130计算得到第三骨架影像(未绘示),并将第三骨架影像输入至姿势辨识模型。本实施例中,可以在姿势辨识模型中得到相同或相似于第三骨架影像的骨架影像330,如图3c所示。由于骨架影像330对应至蹲坐的人体姿势,因此,处理装置220输出的人体姿势辨识结果是蹲坐姿势。
62.相似地,处理装置220从人体图片140计算得到第四骨架影像(未绘示),并将第四骨架影像输入至姿势辨识模型。本实施例中,可以在姿势辨识模型中得到相同或相似于第四骨架影像的骨架影像340,如图3d所示。由于骨架影像340对应至跌倒的人体姿势,因此,处理装置220输出的人体姿势辨识结果是跌倒姿势。
63.于一些实施例中,处理装置220会根据对应的人体姿势辨识结果来判断是否发出一异常信息。承上述实施例说明,处理装置220于图1的待辨识影像100中判断出有乘客的人体姿势是跌倒姿势,则判定是异常状态,因此发出一异常信息。值得一提的是,对于人体姿势是正常状态或异常状态,可随着场景运用的不同而有所改变。举例而言,在月台上若有乘客跌倒,则可能造成安全性的危害(例如跌入轨道),或者造成秩序的混乱(例如挡住通道)。这样的情况下,可以将跌倒姿势设定为异常姿势。
64.为进一步说明本案的人体姿势辨识方法,请一并参照图2及图4。
65.图4绘示根据本案一些实施例中一种人体姿势辨识方法400的流程图。人体姿势辨识方法400可由图2的人体姿势辨识系统200来执行。
66.于步骤s403,接收多个待辨识影像。于一些实施例中,人体姿势辨识系统200会接收多个待辨识影像,以对这些待辨识影像进行辨识。
67.于步骤s405,分别从这些待辨识影像产生对应的骨架影像。于一些实施例中,人体姿势辨识系统200对待辨识影像执行人物肢体关键点侦测演算法,计算出待辨识影像中的每一个人体所对应的骨架影像。
68.于一些实施例中,人体姿势辨识方法400会从待辨识影像中取出人体图片,并从人体图片中取得对应的多个人体关键点坐标。接着,根据这些人体关键点坐标之间的连线,来获得人体所对应的骨架影像及其肢体。所述的人体关键点坐标是对应于骨架影像的关节。
69.于步骤s410,对骨架影像中的每个肢体部位标记一颜色特征,使得每个肢体部位的颜色特征彼此不同。于一些实施例中,姿势辨识模型中预先储存的骨架影像的各肢体部位都有一对应的肢体颜色,例如头部会标记为红色。在后续对待辨识影像所产生的骨架影像中的肢体部位标记颜色特征时,会遵循同样的颜色特征的规则,也就是若辨识出头部,则
该肢体部位的颜色特征会被标记为红色。
70.于步骤s415,将从待辨识影像中获得的每一个骨架影像输入至姿势辨识模型。于一些实施例中,若从待辨识影像中计算出多个骨架影像,则每一个骨架影像都会被输入至姿势辨识模型,以判断每一个人体的姿势。
71.于一些实施例中,人体姿势辨识方法400会进一步对骨架影像的各肢体的线条粗细进行调整,例如会随着骨架影像对应的人体图片于待辨识影像的像素数目的比例,调整骨架影像中的骨架的线条粗细。举例而言,根据具有该骨架影像的人体图片的像素数目以及待辨识影像的像素数目,来计算两者的比例。于一些实施例中,若骨架影像对应的人体图片于待辨识影像的像素数目的比例越高(例如18%),代表人体距离摄影机越近,则骨架影像中的骨架线条越细。相反地,若骨架影像对应的人体图片于待辨识影像的像素数目的比例越低(例如3%),代表人体距离摄影机越远,则骨架影像中的线条越粗。于一些实施例中,由于人体距离摄影机的距离不同,所产生的骨架影像的精细和模糊样态也会有差异,若能够将距离不同的骨架分开比对,将可提高比对的精准度。距离摄影机越远的人体图像,其对应于的像素数目的比例越低,其原始骨架的线条会越模糊,因此会调整加宽其骨架的线条。而距离摄影机越近的人体图像,其对应于的像素数目的比例越高,其原始骨架的线条会越清晰,因此调整变细其骨架的线条,以能够清楚的呈现骨架的结构,以提升人体姿势的辨识度。
72.于步骤s420,输出人体辨识结果,以根据人体姿势辨识结果,判断是否发出异常信息。于一些实施例中,若人体姿势辨识结果符合一异常状态,例如跌倒姿势,则判定现场有异常状态。此时,人体姿势辨识方法400会发出一异常信息,以供相关人员检视。
73.姿势辨识模型的训练方法说明如下。
74.于一些实施例中,姿势辨识模型是采用多个训练影像进行训练所建立。请复参照图2,处理装置220可取得来源影像装置210中的多个训练影像。值得一提的是,任何多媒体串流的画面、影像画面等可撷取为静态画面的影像均可被运用来作为训练影像。
75.于一些实施例中,处理装置220使用这些训练影像透过人物肢体关键点侦测演算法来获得多个训练骨架影像,使得每一个训练骨架影像中的各肢体都具有对应的肢体颜色。
76.于一些实施例中,处理装置220会标记这些骨架影像所对应的人体姿势辨识结果。例如提供一操作界面,让标记的人员来选择一个训练骨架影像并记录其所对应的人体姿势,操作界面亦可显示原始的训练影像以供标记的人员来确认和记录所对应的人体姿势。这些具有肢体颜色以及被标记有对应的人体姿势辨识结果的骨架影像会被输入训练模型进行训练。举例而言,透过深度学习演算法来训练模型。处理装置220会根据具有对应肢体颜色的训练骨架影像以及所对应的人体姿势辨识结果,训练并产生姿势辨识模型。
77.于一些实施例中,处理装置220使用这些训练影像中每一个训练骨架影像的人体图片的像素数目,来计算出空间特征。处理装置220可以根据各训练影像中的多个人体关键点坐标及人体图片的空间特征,来获得这些训练骨架。举例而言,训练影像中可以有一或多个人体,而进一步从训练影像中得到对应于人体的人体图片。于一些实施例中,可透过人体图片的像素数目与训练影像的像素数目的比例,来推算出人体图片和摄影机之间距离的远近,而获得此空间特征。空间特征可以是人体图片的景深信息。于一些实施例中,处理装置
220透过景深信息来调整人体图片的骨架影像的骨架线条的粗细。
78.于一些实施例中,当人体图片的景深信息指示人体和摄影机之间的距离越远,则人体图片的骨架影像的骨架线条会被加粗。于另一些实施例中,当人体图片的景深信息指示人体的距离越近,则人体图片的骨架影像的骨架线条越细。
79.于一些实施例中,人体姿势辨识方法400会等比例调整骨架影像的尺寸,以使用经调整的骨架影像来训练姿势辨识模型。请参照图5a至图5b,其绘示根据本案一些实施例中骨架影像510及520的示意图。如图5a所示,从训练影像中获得骨架影像510。获得骨架影像的方法如上说明,于此不再赘述。骨架影像510的影像宽度w1(例如是100像素)及高度h1(例如是200像素)。为使输入至姿势辨识模型的骨架影像的尺寸一致,会对骨架影像510的尺寸进行标准化的调整,例如将所有的骨架影像调整为一样的尺寸,例如等比例缩小为48像素的宽度及48像素的高度。举例而言,骨架影像510先进行等比例缩小(100像素
×
200像素缩小为24像素
×
48像素),接着再对不足48像素的影像宽度填补至48像素。如图5b所示,调整后的骨架影像520的影像宽度w2(例如是48像素)及高度h2(例如是48像素)。由于所有的骨架影像具有相同的长宽比,并且具有相同的影像尺寸。透过影像标准化的方法,除了可确保人体姿势的正确性,还可提升深度学习影像训练及辨识的时候的精准度。
80.于一些实施例中提出一种非暂态计算机可读取储存媒体,可储存多个程序码。当这些程序码被载入至处理器或如图2的处理装置220后,处理装置220执行这些程序码以执行如图4的步骤。举例而言,处理装置220接收多个待辨识影像,从这些待辨识影像产生多个骨架影像,并将这些骨架影像分别输入至姿势辨识模型,以输出对应的人体姿势辨识结果。以及,根据对应的人体姿势辨识结果,判断是否发出异常信息。
81.综上所述,本案的人体姿势辨识系统及人体姿势辨识方法中,将透过提取人体图片的骨架影像来进行姿势的比对,并且由于骨架影像的各肢体具有不同的颜色特征,当肢体彼此之间或人体彼此之间交叠时,相较于传统使用灰阶来进行影像辨识的作法,本案对各肢体采用不同的颜色特征可提升处理装置进行视觉辨识的准确度。此外,由于人体较远的时候人体图片较小,这会降低处理装置进行视觉辨识的精准度,因此,本案结合了人体图片的深度信息,来对应地加粗距离较远的人体的骨架线条,以利于辨识人体各肢体及各肢体之间的关联性。并且,相较于训练影像或待辨识影像的尺寸,本案的骨架影像的尺寸较小,而可节省影像训练及姿态辨识的运算时间,提升训练及辨识的效率。据此,本案透过肢体的颜色特征及空间信息的方法可提供高效率及高精准度的影像训练及姿态辨识。
82.上述内容概述若干实施例的特征,使得熟悉此项技术者可更好地理解本案的态样。熟悉此项技术者应了解,在不脱离本案的精神和范围的情况下,可轻易使用上述内容作为设计或修改为其他变化的基础,以便实施本文所介绍的实施例的相同目的及/或实现相同优势。上述内容应当被理解为本案的举例,其保护范围应以权利要求书为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1