一种5T运维中安全防护识别单元的制作方法
一种5t运维中安全防护识别单元
技术领域
[0001]
本发明涉及铁路安全监控与运维领域,具体涉及一种5t运维中安全防护识别单元。
背景技术:
[0002]
随着铁路线路的增加、覆盖区域变广,沿铁路运行线路建设的用于安放5t设备的探测站越来越多。5t系统是我国铁路相关部门为适应现代铁路的发展而建立的车辆安全防范系统,5t探测站的正常运转直接关系到铁路日常运行的安全与效率,对铁路的安全运行具有重要意义。
[0003]
5t探测站日常运维作业过程中,工作人员需正确佩戴安全帽和穿着防护服。然而5t探测站中现有的视频监控系统虽然能实时显示站内工作人员工作情况,但对工作人员在作业工程中安全帽的佩戴和防护服的穿着无法做到实时识别,需要值守人员24小时监视和人工巡检。由于值守人员精力有限,容易疲劳走神,往往导致潜在威胁安全生产的事故发生。
技术实现要素:
[0004]
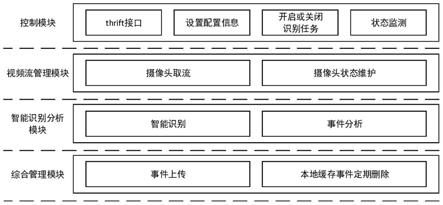
本发明公开了一种5t运维中安全防护识别单元,识别单元包括控制模块、视频流管理模块、智能识别分析模块及综合管理模块;5t检测上位机可通过所述控制模块的thrift接口设置配置信息、开启关闭识别作业任务,实现对系统运行状态进行监测;所述视频流管理模块根据控制模块下发的配置信息和命令,从摄像头中拉取视频流并进行摄像头状态维护;所述智能识别分析模块通过5t运维中安全防护识别方法对作业人员、安全帽、防护服进行智能识别,以及进行安全帽和防护服事件分析;综合管理模块负责向平台上传事件,以及本地缓存事件的定期删除。
[0005]
优选的,所述识别单元执行以下流程:
[0006]
(1)控制模块获取配置参数和识别任务启停命令,其中配置参数包括:识别时长、摄像头ip地址、摄像头用户名、摄像头密码、视频流对外端口号、每个事件存储图片张数和状态上报周期;
[0007]
(2)判断是否开启识别作业,若开启识别任务,则转到步骤(3),否则返回步骤(1);
[0008]
(3)获取环境光照强度数据;
[0009]
(4)视频流管理模块根据从控制模块获得的配置参数从对应编号摄像头中拉取视频流;
[0010]
(5)判断是否连续600秒未成功获取视频帧,若连续600秒未成功获取视频帧,则上报摄像头异常状态信息;否则转到步骤(6);
[0011]
(6)智能识别分析模块对视频帧中工作人员安全帽和防护服进行智能识别以及事件分析;
[0012]
(7)综合管理模块将生成的事件通过post请求上传;
[0013]
(8)综合管理模块将本地缓存的事件定期删除。
[0014]
优选的,该识别单元的整体流程中所述拉取视频流具体步骤为:
[0015]
(4-1)根据rstp标准流协议从配置参数确定的对应编号摄像头获取视频当前帧;
[0016]
(4-2)判断是否成功获取摄像头当前帧,若成功获取摄像头当前帧,则执行步骤(4-3),否则直接转到步骤(4-4);
[0017]
(4-3)输出摄像头当前帧数据到图片数据队列;
[0018]
(4-4)执行摄像头状态维护操作;
[0019]
(4-5)等待1秒后转到步骤(4-1)。
[0020]
优选的,拉取视频流流程中所述摄像头状态维护具体步骤为:
[0021]
(4-4-1)读取摄像头当前状态和摄像头异常状态次数;
[0022]
(4-4-2)判断摄像头当前状态是否正常,若摄像头当前状态正常,则执行步骤(4-4-3),否则执行步骤(4-4-4);
[0023]
(4-4-3)将摄像头异常状态次数置为0;
[0024]
(4-4-4)将摄像头异常次数加1;
[0025]
(4-4-5)判断若摄像头异常状态次数是否大于600,若摄像头异常状态次数大于600,则执行步骤(4-4-6);
[0026]
(4-4-6)将摄像头状态设为异常。
[0027]
优选的,该识别单元的整体流程中所述智能识别采用通过yolov4目标检测网络与改进的yolov3-tiny目标检测网络相级联方法并且基于匹配不同光照强度的多个网络识别模型来识别人员安全帽和防护服的穿戴,具体步骤为:
[0028]
(6a-1)从数据队列获取视频帧;
[0029]
(6a-2)判断获取视频帧是否成功,若获取视频帧成功,则执行步骤(6a-4),否则执行步骤(6a-3);
[0030]
(6a-3)等待直到数据队列有数据时转到步骤(6a-1);
[0031]
(6a-4)将视频帧输入yolov4目标检测网络进行人员检测;
[0032]
(6a-5)根据yolov4目标检测网络输出的检测到人员的可信度判断是否检测到人员,若没有检测到人员,则执行步骤(6a-1),否则执行步骤(6a-6);
[0033]
(6a-6)根据yolov4目标检测网络输出的人员目标框坐标参数对视频帧中检测到的人员目标框区域进行裁剪;
[0034]
(6a-7)判断环境光照强度是否小于0.0018lux,若小于0.0018lux,则执行步骤(6a-8),否则执行步骤(6a-9);
[0035]
(6a-8)将裁剪出的人员目标框区域图像输入适用于夜间识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0036]
(6a-9)判断环境光照强度是否小于0.0022lux,若小于0.0022lux,则执行步骤(6a-10),否则执行步骤(6a-11);
[0037]
(6a-10)将裁剪出的人员目标框区域图像分别输入适用于夜间识别和白天弱光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0038]
(6a-11)判断环境光照强度是否小于9lux,若小于9lux,则执行步骤(6a-12),否则
执行步骤(6a-13);
[0039]
(6a-12)将裁剪出的人员目标框区域图像输入适用于白天弱光照强度识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0040]
(6a-13)判断环境光照强度是否小于11lux,若小于11lux,则执行步骤(6a-14),否则执行步骤(6a-15);
[0041]
(6a-14)将裁剪出的人员目标框区域图像分别输入适用于白天弱光照强度和白天中光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0042]
(6a-15)判断环境光照强度是否小于90lux,若小于90lux,则执行步骤(6a-16),否则执行步骤(6a-17);
[0043]
(6a-16)将裁剪出的人员目标框区域图像输入适用于白天中光照强度识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0044]
(6a-17)判断环境光照强度是否小于110lux,若小于110lux,则执行步骤(6a-18),否则执行步骤(6-19);
[0045]
(6a-18)将裁剪出的人员目标框区域图像分别输入适用于白天中光照强度和白天强光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0046]
(6a-19)将裁剪出的人员目标框区域图像输入适用于白天强光照强度识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测;
[0047]
(6a-20)储存当前帧人员安全帽和防护服穿戴信息。
[0048]
优选的,所述采用通过yolov4目标检测网络与改进的yolov3-tiny目标检测网络相级联方法,首先采用yolov4目标检测网络进行人员检测,具体步骤为:
[0049]
(6a-4-1)从作业现场不同光照强度下监控摄像头拍摄的监控视频中抽取出包含作业人员的视频帧,建立作业人员图像数据集;
[0050]
(6a-4-2)使用labelimg工具对图像中的人员标记,得到对应的xml格式的数据集文件,并将xlm格式的数据集转换为适用于yolov4目标检测网络的txt格式的数据集;
[0051]
(6a-4-3)利用darknet深度学习框架搭建yolov4目标检测网络,具有以下步骤:
[0052]
1)采用cspdarknet53网络结构搭建yolov4目标检测网络的backbone部分,backbone部分的激活函数使用mish激活函数,其公式为:
[0053]
f(x)=x*tanh(log(1+e
x
))
[0054]
其中x为激活函数所在网络层的输入值,tanh()为双曲正切函数;mish激活函数函数曲线平滑,能够允许更好的信息深入神经网络,从而得到更好的准确性和泛化,采用dropblock方法,随机丢弃特征图的图像信息来缓解过拟合;
[0055]
2)采用spp模块和fpn+pan的结构搭建yolov4目标检测网络的neck部分;
[0056]
3)yolov4目标检测网络的目标框回归损失函数采用ciou_loss损失函数,使得预测框回归的速度和精度更高,其公式为
[0057][0058]
其中iou为目标检测预测框和真实框的交并比,distance_c为目标检测预测框和
真实框的最小外接矩形的对角线距离,distance_2为目标检测预测框和真实框中心点的欧氏距离,v是衡量目标检测预测框和真实框长宽比一致性的参数;
[0059]
4)yolov4目标检测网络采用diou_nms目标框筛选方法;
[0060]
(6a-4-4)采用coco图像数据集对yolov4目标检测网络进行物体分类训练,得到部分训练完成的yolov4网络模型;
[0061]
(6a-4-5)在步骤(6a-4-4)结果的基础上,采用制作的现场作业人员图像数据集对yolov4目标检测网络进行训练,得到能够用于现场人员检测的yolov4网络模型;
[0062]
(6a-4-6)将视频帧输入yolov4目标检测网络中,检测出人员的可信度及人员目标框的坐标参数。
[0063]
优选的,所述采用通过yolov4目标检测网络与改进的yolov3-tiny目标检测网络相级联方法,然后采用改进的yolov3-tiny目标检测网络并且基于匹配不同光照强度的多个网络模型权重进行人员安全帽和防护服检测,其特征在于具有以下步骤:
[0064]
(6a-8-1)从作业现场不同光照强度下监控摄像头拍摄的监控视频中抽取出包含人员安全帽和防护服的视频帧,分别建立白天弱光强人员安全帽和防护服图像数据集、白天中光强人员安全帽和防护服图像数据集、白天强光强人员安全帽和防护服图像数据集和夜间人员安全帽和防护服图像数据集,并利用mosaic数据增强的方式来扩充数据集;
[0065]
(6a-8-2)使用labelimg工具对图像中人员安全帽和防护服进行标记,得到对应的xml格式的数据集文件,并将xlm格式的数据集转换为适用于yolov3-tiny目标检测网络的txt格式的数据集;
[0066]
(6a-8-3)利用darknet深度学习框架搭建改进的yolov3-tiny目标检测网络,具有以下步骤:
[0067]
1)以yolov3-tiny目标检测网络为基本框架,进行网络模型修改剪枝操作;
[0068]
2)使用谷歌efficient-b0深度卷积神经网络替换yolov3-tiny原有的主干网络,去除efficient-b0深度卷积神经网络的132-135层,在131层后分别添加2个卷积层,1个shortcut层,1个卷积层,一个yolo层;
[0069]
3)在步骤2)得到的网络的基础上,在网络的133层后顺序连接1个route层,1个卷积层,1个降采样层,1个shortcut层,1个卷积层,2个shortcut层,1个卷积层,1个yolo层,得到改进的yolov3-tiny目标检测网络;
[0070]
(6a-8-4)利用k-means算法对安全帽和防护服数据集中的安全帽和防护服的真实框长宽参数进行聚类计算,用真实框聚类得到的长宽数据替代yolov3-tiny目标检测网络原有的先验框长宽数据,以提高目标框的检出率;
[0071]
(6a-8-5)采用制作的白天弱光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,得到能够适用于白天弱光照强度下人员安全帽和防护服检测的网络模型;
[0072]
(6a-8-6)采用制作的白天中光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,得到能够适用于白天中光照强度下人员安全帽和防护服检测的网络模型;
[0073]
(6a-8-7)采用制作的白天强光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,得到能够适用于白天强光照强度下人员安全帽和防护服检测
的网络模型;
[0074]
(6a-8-8)采用制作的夜间人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,得到能够用于夜间人员安全帽和防护服检测的网络模型;
[0075]
(6a-8-9)根据现场环境光照强度数据将裁剪过的人员目标区域输入适用于不同光照强度的改进的yolov3-tiny目标检测网络,得到现场人员穿戴安全帽和防护服的可信度及安全帽和防护服目标框的坐标参数。
[0076]
优选的,所述采用基于匹配不同光照强度的多个网络识别模型来识别人员安全帽和防护服的穿戴中,若安全防护识别单元所测照度值处于各光照强度识别模型应用区分值邻域范围时,采用基于相邻光照强度识别模型识别结果融合判断方法,首先分别采用与所测照度值最接近的低级别光照强度识别模型和最接近的高级别光照强度识别模型的识别结果,然后融合计算判断安全帽和防护服的穿戴情况,具体融合判断过程如下:
[0077]
(6a-10-1)记相邻两光照强度识别模型应用区分临界光强值为x
l
(夜间识别模型、白天,对应邻域下限光强值为x
ll
=0.9x
l
,邻域上限光强值为x
lh
=1.1x
l
,若当前光强值为x,则低级别光照强度模型识别的可信度权重记为高级别光照强度模型识别的可信度权重记为
[0078]
(6a-10-2)基于改进的yolov3-tiny低级别光照强度识别模型进行人员安全帽和防护服的识别,得到人员佩戴安全帽的可信度为h1,穿防护服的可信度为c1,则人员佩戴安全帽的加权可信度m1(a)=h1w
l
,未佩戴安全帽的加权可信度m1(b)=(1-h1)w
l
,安全帽佩戴状态未知的加权可信度m1(c)=1-w
l
,穿防护服的加权可信度m1(d)=c1w
l
,未穿防护服的加权可信度m1(e)=(1-c1)w
l
,防护服穿着状态未知的加权可信度m1(f)=1-w
l
;
[0079]
(6a-10-3)基于改进的yolov3-tiny高级别光照强度识别模型进行人员安全帽和防护服的识别,得到人员佩戴安全帽的可信度为h2,穿防护服的可信度为c2,则人员佩戴安全帽的加权可信度m2(a)=h2w
h
,未佩戴安全帽的加权可信度m2(b)=(1-h2)w
h
,安全帽佩戴状态未知的加权可信度m2(c)=1-w
h
,穿防护服的加权可信度m2(d)=c2w
h
,未穿防护服的加权可信度m2(e)=(1-c2)w
h
,防护服穿着状态未知的加权可信度m2(f)=1-w
h
;
[0080]
(6a-10-4)基于相邻两个光照强度识别模型的识别结果融合计算佩戴安全帽的可信度m(a),未佩戴安全帽的可信度m(b),穿防护服的可信度m(d),未穿防护服的可信度m(e),其中
[0081][0082][0083][0084][0085]
(6a-10-5)比较m(a)与m(b),若m(a)≥m(b),则融合判断为佩戴安全帽,若m(a)<m(b),则融合判断为未佩戴安全帽;
[0086]
(6a-10-6)比较m(d)与m(e),若m(d)≥m(e),则融合判断为穿防护服,若m(d)<m(e),则融合判断为未穿防护服。
[0087]
优选的,该识别单元的整体流程中所述事件分析具体步骤为:
[0088]
(6b-1)读取当前视频帧人员安全帽和防护服识别结果;
[0089]
(6b-2)判断当前视频帧摄像头ip是否属于事件任务字典中的某个事件,若视频帧摄像头ip属于事件任务字典中的某个事件,则执行步骤(6b-3);否则执行步骤(6b-4);
[0090]
(6b-3)将当前视频帧数据放入该事件对应的视频帧数据队列中;
[0091]
(6b-4)创建新的事件任务,将当前视频帧数据放入该事件对应的视频帧数据队列中;
[0092]
(6b-5)判断视频帧数据队列中的数据个数是否等于60,若视频帧数据队列中的数据个数是否不等于60,则转到步骤(6b-5);
[0093]
(6b-6)统计视频帧数据队列中,人员未穿防护服、配戴安全帽的个数;
[0094]
(6b-7)判断未穿防护服或未佩戴安全帽的个数是否大于视频帧数据队列数据总数的70%,若否,转到步骤(6b-9)
[0095]
(6b-8)执行事件上传操作;
[0096]
(6b-9)释放资源。
[0097]
其中事件上传具体步骤为:
[0098]
(6b-8-1)输入需要上传的图片和视频信息;
[0099]
(6b-8-2)上传事件;
[0100]
(6b-8-3)判断事件上传是否成功,若事件上传成功,则结束流程,否则转到步骤(6b-8-4);
[0101]
(6b-8-4)将需要上传的图片和视频信息保存至本地。
[0102]
优选的,该识别单元的整体流程中所述本地缓存事件定期删除具体步骤为:
[0103]
(8-1)判断本地是否有缓存事件,若没有缓存事件,则转到步骤(8-2),否则转到步骤(8-3);
[0104]
(8-2)等待固定时间之后转到步骤(8-1);
[0105]
(8-3)上传事件;
[0106]
(8-4)判断事件上传是否成功,若事件上传成功,则转到步骤(8-5),否则转到步骤(8-2);
[0107]
(8-5)删除本地缓存事件。
[0108]
有益效果
[0109]
1.安全防护识别单元实现了对铁路5t运维作业现场工作人员安全帽和防护服穿戴的实时自动识别及识别事件上传,并且5t检测上位机可以通过安全防护识别单元控制模块远程设置配置信息,开启关闭识别作业任务、对系统运行状态进行监测,实现了铁路5t运维智能化管理;
[0110]
2.安全防护识别单元的综合管理模块可以实现本地缓存事件的定期删除,大大节省本地储存空间,节约投资;
[0111]
3.安全防护识别单元的识别算法根据铁路5t运维应用场景,针对性的修改设计目标检测网络结构,通过yolov4目标检测网络与改进的yolov3-tiny目标检测网络相级联并
且基于匹配不同光照强度的多个网络模型权重来识别人员安全帽和防护服的穿戴,在保证识别速度的同时显著提高了不同环境背景下目标分类能力和检测精度;
[0112]
4.安全防护识别单元的识别算法针对安全防护识别单元所测照度值处于各光照强度识别模型应用区分值邻域范围时可能会出现模型误匹配情况,提出了相邻光照强度模型融合判断的方法,实现了不同光照强度模型平滑切换,保证了识别准确率。
附图说明
[0113]
图1为本发明的识别单元功能模块结构图
[0114]
图2为本发明的算法整体流程图
[0115]
图3为本发明的摄像头拉取视频流流程图
[0116]
图4为本发明的摄像头状态维护流程图
[0117]
图5为本发明的智能流程图
[0118]
图6为本发明的事件分析流程图
[0119]
图7为本发明的事件上传流程图
[0120]
图8为本发明的本地缓存事件定期删除流程图
具体实施方式
[0121]
防护识别单元功能模块结构图如图1所示,其中包括:
[0122]
1.控制模块
[0123]
5t检测上位机可以通过控制模块的thrift接口设置配置信息,开启关闭识别作业任务、对系统运行状态进行监测(实现了对系统的远程操作和状态实时监控)。
[0124]
2.视频流管理模块
[0125]
视频流管理模块根据控制模块下发的配置信息和命令,从摄像头中抓取视频流并进行摄像头状态维护。
[0126]
3.智能识别分析模块
[0127]
智能识别分析模块主要负责作业人员和安全帽、防护服的智能识别;安全帽和防护服事件分析(实现了对5t运维作业现场工作人员安全帽和防护服穿戴的实时自动识别和事件分析)。
[0128]
4.综合管理模块
[0129]
综合管理模块负责向平台上传事件,以及本地缓存事件的定期删除(可以大大节省本地储存空间节约投资)。
[0130]
二、防护识别方法流程
[0131]
1.结合图2,整体流程:
[0132]
(1)控制模块获取配置参数和识别任务启停命令,其中配置参数包括:识别时长、摄像头ip地址、摄像头用户名、摄像头密码、视频流对外端口号、每个事件存储图片张数和状态上报周期;
[0133]
(2)判断是否开启识别作业,若开启识别任务,则转到步骤(3);否则返回步骤(1);
[0134]
(3)获取环境光照强度数据;
[0135]
(4)视频流管理模块根据从控制模块获得的配置参数从对应编号摄像头中拉取视
频流;
[0136]
(5)判断是否连续600秒未成功获取视频帧,若连续600秒未成功获取视频帧,则上报摄像头异常状态信息;否则转到步骤(6);
[0137]
(6)智能识别分析模块对视频帧中工作人员安全帽和防护服进行智能识别以及事件分析;
[0138]
(7)综合管理模块将生成的事件通过post请求上传;
[0139]
(8)综合管理模块将本地缓存的事件定期删除。
[0140]
2.结合图3,摄像头拉取视频流具体步骤为:
[0141]
(4-1)根据rstp标准流协议从配置参数确定的对应编号摄像头获取视频当前帧;
[0142]
(4-2)判断是否成功获取摄像头当前帧,若成功获取摄像头当前帧,则执行步骤(4-3),否则直接转到步骤(4-4);
[0143]
(4-3)输出摄像头当前帧数据到图片数据队列;
[0144]
(4-4)执行摄像头状态维护操作;
[0145]
(4-5)等待1秒后转到步骤(4-1)。
[0146]
3.结合图4,摄像头状态维护具体步骤为:
[0147]
(4-4-1)读取摄像头当前状态和摄像头异常状态次数;
[0148]
(4-4-2)判断摄像头当前状态是否正常,若摄像头当前状态正常,则执行步骤(4-4-3);否则执行步骤(4-4-4);
[0149]
(4-4-3)将摄像头异常状态次数置为0;
[0150]
(4-4-4)将摄像头异常次数加1;
[0151]
(4-4-5)判断若摄像头异常状态次数是否大于600,若摄像头异常状态次数大于600,则执行步骤(4-4-6)
[0152]
(4-4-6)将摄像头状态设为异常。
[0153]
4.结合图5,智能识别的特征在于通过yolov4目标检测网络与改进的yolov3-tiny目标检测网络相级联并且基于匹配不同光照强度的多个网络模型权重来识别人员安全帽和防护服的穿戴(相比于基于单一网络模型权重直接检测佩戴安全帽和穿着防护服的人员目标的方式,能够显著提高在复杂背景图像中的识别准确率,具有很强的鲁棒性和适应性),具体步骤为:
[0154]
(6a-1)从数据队列获取视频帧;
[0155]
(6a-2)判断获取视频帧是否成功,若获取视频帧成功,则执行步骤(6a-4),否则执行步骤(6a-3);
[0156]
(6a-3)等待直到数据队列有数据时转到步骤(6a-1);
[0157]
(6a-4)将视频帧输入yolov4目标检测网络进行人员检测;
[0158]
(6a-5)根据yolov4目标检测网络输出的检测到人员的可信度判断是否检测到人员,若没有检测到人员,则执行步骤(6a-1),否则执行步骤(6a-6);
[0159]
(6a-6)根据yolov4目标检测网络输出的人员目标框坐标参数对视频帧中检测到的人员目标框区域进行裁剪;
[0160]
(6a-7)判断环境光照强度是否小于0.0018lux,若小于0.0018lux,则执行步骤(6a-8),否则执行步骤(6a-9);
[0161]
(6a-8)将裁剪出的人员目标框区域图像输入适用于夜间识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0162]
(6a-9)判断环境光照强度是否小于0.0022lux,若小于0.0022lux,则执行步骤(6a-10),否则执行步骤(6a-11);
[0163]
(6a-10)将裁剪出的人员目标框区域图像分别输入适用于夜间识别和白天弱光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0164]
(6a-11)判断环境光照强度是否小于9lux,若小于9lux,则执行步骤(6a-12),否则执行步骤(6a-13);
[0165]
(6a-12)将裁剪出的人员目标框区域图像输入适用于白天弱光照强度识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0166]
(6a-13)判断环境光照强度是否小于11lux,若小于11lux,则执行步骤(6a-14),否则执行步骤(6a-15);
[0167]
(6a-14)将裁剪出的人员目标框区域图像分别输入适用于白天弱光照强度和白天中光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0168]
(6a-15)判断环境光照强度是否小于90lux,若小于90lux,则执行步骤(6a-16),否则执行步骤(6a-17);
[0169]
(6a-16)将裁剪出的人员目标框区域图像输入适用于白天中光照强度识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0170]
(6a-17)判断环境光照强度是否小于110lux,若小于110lux,则执行步骤(6a-18),否则执行步骤(6a-19);
[0171]
(6a-18)将裁剪出的人员目标框区域图像分别输入适用于白天中光照强度和白天强光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0172]
(6a-19)将裁剪出的人员目标框区域图像输入适用于白天强光照强度识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测;
[0173]
(6a-20)储存当前帧人员安全帽和防护服穿戴信息。
[0174]
4.1yolov4目标检测网络进行人员检测(yolov4与yolov3相比检测速度更快,识别精度更高),其特征在于具有以下步骤:
[0175]
(6a-4-1)从作业现场不同光照强度下监控摄像头拍摄的监控视频中抽取出包含作业人员的视频帧,建立作业人员图像数据集;
[0176]
(6a-4-2)使用labelimg工具对图像中的人员标记,得到对应的xml格式的数据集文件,并将xlm格式的数据集转换为适用于yolov4目标检测网络的txt格式的数据集;
[0177]
(6a-4-3)利用darknet深度学习框架搭建yolov4目标检测网络,具有以下步骤:
[0178]
1)采用cspdarknet53网络结构搭建yolov4目标检测网络的backbone部分,backbone部分的激活函数使用mish激活函数,其公式为:
[0179]
f(x)=x*tanh(log(1+e
x
))
[0180]
其中x为激活函数所在网络层的输入值,mish激活函数函数曲线平滑,能够允许更
好的信息深入神经网络,从而得到更好的准确性和泛化,采用dropblock方法,随机丢弃特征图的图像信息来缓解过拟合;
[0181]
2)采用spp模块和fpn+pan的结构搭建yolov4目标检测网络的neck部分;
[0182]
3)yolov4目标检测网络的目标框回归损失函数采用ciou_loss损失函数,使得预测框回归的速度和精度更高,其公式为
[0183][0184]
其中iou为目标检测预测框和真实框的交并比,distance_c为目标检测预测框和真实框的最小外接矩形的对角线距离,distance_2为目标检测预测框和真实框中心点的欧氏距离,v是衡量目标检测预测框和真实框长宽比一致性的参数;
[0185]
4)yolov4目标检测网络采用diou_nms目标框筛选方法(在重叠目标的检测中,diou_nms的效果优于传统的nms)。
[0186]
(6a-4-4)采用coco图像数据集(coco数据集包含20万张从复杂的日常场景中截取的图像,具有80个目标类别和超过50万个目标标注,是目前最广泛公开的目标检测数据集)对yolov4目标检测网络进行物体分类训练,得到部分训练完成的yolov4网络模型;
[0187]
(6a-4-5)在步骤(6a-4-4)结果的基础上,采用制作的现场作业人员图像数据集对yolov4目标检测网络进行训练,得到能够用于现场人员检测的yolov4网络模型;
[0188]
(6a-4-6)将视频帧输入yolov4目标检测网络中,得到视频帧中检测出人员的可信度及人员目标框的坐标参数。
[0189]
4.2改进的yolov3-tiny目标检测网络并且基于匹配不同光照强度的多个网络模型权重进行人员安全帽和防护服检测(通过修改主干网络,增加了原有网络的深度,对于不同光照强度下的识别分别采用不同网络模型权重,在保证识别速度的同时大大提升了不同环境背景下目标分类能力和检测精度),其特征在于具有以下步骤:
[0190]
(6a-8-1)从作业现场不同光照强度下监控摄像头拍摄的监控视频中抽取出包含人员安全帽和防护服的视频帧,分别建立白天弱光强人员安全帽和防护服图像数据集、白天中光强人员安全帽和防护服图像数据集、白天强光强人员安全帽和防护服图像数据集和夜间人员安全帽和防护服图像数据集,并利用mosaic数据增强的方式(将4张图片通过随机缩放、随机裁剪、随机排布的方式拼接为1张图片)来扩充数据集;
[0191]
(6a-8-2)使用labelimg工具对图像中人员安全帽和防护服进行标记,得到对应的xml格式的数据集文件,并将xlm格式的数据集转换为适用于yolov3-tiny目标检测网络的txt格式的数据集;
[0192]
(6a-8-3)利用darknet深度学习框架搭建改进的yolov3-tiny目标检测网络,具有以下步骤:
[0193]
1)以yolov3-tiny目标检测网络为基本框架,进行网络模型修改剪枝操作;
[0194]
2)使用谷歌efficient-b0深度卷积神经网络替换yolov3-tiny原有的主干网络,去除efficient-b0深度卷积神经网络的132-135层,在131层后分别添加2个卷积层,1个shortcut层,1个卷积层,一个yolo层;
[0195]
3)在步骤2)得到的网络的基础上,在网络的133层后顺序连接1个route层,1个卷积层,1个降采样层,1个shortcut层,1个卷积层,2个shortcut层,1个卷积层,1个yolo层,得
到改进的yolov3-tiny目标检测网络;
[0196]
(6a-8-4)利用k-means算法(对于给定的数据集,按照数值之间的距离大小将数据集划分为k个簇,使簇内数值之间距离尽量小,簇间距离尽量大)对安全帽和防护服数据集中的安全帽和防护服的真实框长宽参数进行聚类计算,用真实框聚类得到的长宽数据替代yolov3-tiny目标检测网络原有的先验框长宽数据,以提高目标框的检出率;
[0197]
(6a-8-5)采用制作的白天弱光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,得到能够适用于白天弱光照强度下人员安全帽和防护服检测的网络模型;
[0198]
(6a-8-6)采用制作的白天中光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,得到能够适用于白天中光照强度下人员安全帽和防护服检测的网络模型;
[0199]
(6a-8-7)采用制作的白天强光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,得到能够适用于白天强光照强度下人员安全帽和防护服检测的网络模型;
[0200]
(6a-8-8)采用制作的夜间人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,得到能够用于夜间人员安全帽和防护服检测的网络模型;
[0201]
(6a-8-9)根据现场环境光照强度数据将裁剪过的人员目标区域输入适用于不同光照强度的改进的yolov3-tiny目标检测网络,得到现场人员穿戴安全帽和防护服的可信度及安全帽和防护服目标框的坐标参数。
[0202]
5.(保证模型平滑切换的)相邻防护状态融合判断
[0203]
由于照度传感器可能存在误差及实际环境中各个位置的照度值可能存在差异,当安全防护识别单元所测照度值处于各光照强度识别模型应用区分值邻域范围时可能会出现模型误匹配情况。为保证识别准确率,可首先分别采用与所测照度值最接近的低级别光照强度识别模型和最接近的高级别光照强度识别模型的识别结果,然后融合计算判断安全帽和防护服的穿戴情况,具体融合判断过程如下:
[0204]
(6a-10-1)记相邻两光照强度识别模型应用区分临界光强值为x
l
(夜间识别模型、白天弱光强识别模型、白天中光强识别模型、白天强光强识别模型应用区分临界光强值x
l
分别为0.002lx、10lx、100lx),对应邻域下限光强值为x
ll
=0.9x
l
,邻域上限光强值为x
lh
=1.1x
l
,若光强值为x,则低级别光照强度模型识别的可信度权重记为高级别光照强度模型识别的可信度权重记为
[0205]
(6a-10-2)基于改进的yolov3-tiny低级别光照强度识别模型进行人员安全帽和防护服的识别,得到人员佩戴安全帽的可信度为h1,穿防护服的可信度为c1,则人员佩戴安全帽的加权可信度m1(a)=h1w
l
,未佩戴安全帽的加权可信度m1(b)=(1-h1)w
l
,安全帽佩戴状态未知的加权可信度m1(c)=1-w
l
,穿防护服的加权可信度m1(d)=c1w
l
,未穿防护服的加权可信度m1(e)=(1-c1)w
l
,防护服穿着状态未知的加权可信度m1(f)=1-w
l
;
[0206]
(6a-10-3)基于改进的yolov3-tiny高级别光照强度识别模型进行人员安全帽和防护服的识别,得到人员佩戴安全帽的可信度为h2,穿防护服的可信度为c2,则人员佩戴安
全帽的加权可信度m2(a)=h2w
h
,未佩戴安全帽的加权可信度m2(b)=(1-h2)w
h
,安全帽佩戴状态未知的加权可信度m2(c)=1-w
h
,穿防护服的加权可信度m2(d)=c2w
h
,未穿防护服的加权可信度m2(e)=(1-c2)w
h
,防护服穿着状态未知的加权可信度m2(f)=1-w
h
;
[0207]
(6a-10-4)基于相邻两个光照强度识别模型的识别结果融合计算佩戴安全帽的可信度m(a),未佩戴安全帽的可信度m(b),穿防护服的可信度m(d),未穿防护服的可信度m(e),其中
[0208][0209][0210][0211][0212]
(6a-10-5)比较m(a)与m(b),若m(a)≥m(b),则融合判断为佩戴安全帽,若m(a)<m(b),则融合判断为未佩戴安全帽;
[0213]
(6a-10-6)比较m(d)与m(e),若m(d)≥m(e),则融合判断为穿防护服,若m(d)<m(e),则融合判断为未穿防护服;
[0214]
6.结合图6,事件分析具有以下步骤:
[0215]
(6b-1)读取当前视频帧人员安全帽和防护服识别结果;
[0216]
(6b-2)判断当前视频帧摄像头ip是否属于事件任务字典中的某个事件,若视频帧摄像头ip属于事件任务字典中的某个事件,则执行步骤(6b-3);否则执行步骤(6b-4);
[0217]
(6b-3)将当前视频帧数据放入该事件对应的视频帧数据队列中;
[0218]
(6b-4)创建新的事件任务,将当前视频帧数据放入该事件对应的视频帧数据队列中;
[0219]
(6b-5)判断视频帧数据队列中的数据个数是否等于60,若视频帧数据队列中的数据个数是否不等于60,则转到步骤(6b-5);
[0220]
(6b-6)统计视频帧数据队列中,人员未穿防护服、配戴安全帽的个数;
[0221]
(6b-7)判断未穿防护服或未佩戴安全帽的个数是否大于视频帧数据队列数据总数的70%,若否,转到步骤(6b-9)
[0222]
(6b-8)执行事件上传操作;
[0223]
(6b-9)释放资源。
[0224]
6.1结合图7,事件上传具有以下步骤:
[0225]
(6b-8-1)输入需要上传的图片和视频信息;
[0226]
(6b-8-2)上传事件;
[0227]
(6b-8-3)判断事件上传是否成功,若事件上传成功,则结束流程,否则转到步骤(6b-8-4);
[0228]
(6b-8-4)将需要上传的图片和视频信息保存至本地。
[0229]
7.结合图8,本地缓存事件定期删除具有以下步骤:
[0230]
(8-1)判断本地是否有缓存事件,若没有缓存事件,则转到步骤(8-2),否则转到步
骤(8-3);
[0231]
(8-2)等待固定时间之后转到步骤(8-1);
[0232]
(8-3)上传事件;
[0233]
(8-4)判断事件上传是否成功,若事件上传成功,则转到步骤(8-5),否则转到步骤(8-2);
[0234]
(8-5)删除本地缓存事件。
[0235]
级联识别算法进行实例说明:
[0236]
1.yolov4目标检测网络与改进的yolov3-tiny目标检测网络相级联并且基于匹配不同光照强度的多个网络模型权重来识别人员安全帽和防护服,具有以下步骤:
[0237]
(6a-1)从数据队列获取视频帧;
[0238]
(6a-2)判断获取视频帧是否成功,若获取视频帧成功,则执行步骤(6a-4),否则执行步骤(6a-3);
[0239]
(6a-3)等待直到数据队列有数据时转到步骤(6a-1);
[0240]
(6a-4)将视频帧输入yolov4目标检测网络进行人员检测;
[0241]
(6a-5)根据yolov4目标检测网络输出的检测到人员的可信度判断是否检测到人员,若没有检测到人员,则执行步骤(6a-1),否则执行步骤(6a-6);
[0242]
(6a-6)根据yolov4目标检测网络输出的人员目标框坐标参数对视频帧中检测到的人员目标框区域进行裁剪;
[0243]
(6a-7)判断环境光照强度是否小于0.0018lux,若小于0.0018lux,则执行步骤(6a-8),否则执行步骤(6a-9);
[0244]
(6a-8)将裁剪出的人员目标框区域图像输入适用于夜间识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0245]
(6a-9)判断环境光照强度是否小于0.0022lux,若小于0.0022lux,则执行步骤(6a-10),否则执行步骤(6a-11);
[0246]
(6a-10)将裁剪出的人员目标框区域图像分别输入适用于夜间识别和白天弱光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0247]
(6a-11)判断环境光照强度是否小于9lux,若小于9lux,则执行步骤(6a-12),否则执行步骤(6a-13);
[0248]
(6a-12)将裁剪出的人员目标框区域图像输入适用于白天弱光照强度识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0249]
(6a-13)判断环境光照强度是否小于11lux,若小于11lux,则执行步骤(6a-14),否则执行步骤(6a-15);
[0250]
(6a-14)将裁剪出的人员目标框区域图像分别输入适用于白天弱光照强度和白天中光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0251]
(6a-15)判断环境光照强度是否小于90lux,若小于90lux,则执行步骤(6a-16),否则执行步骤(6a-17);
[0252]
(6a-16)将裁剪出的人员目标框区域图像输入适用于白天中光照强度识别的改进
的yolov3-tiny目标检测网络进行人员安全帽和防护服检测,然后执行步骤(6a-20);
[0253]
(6a-17)判断环境光照强度是否小于110lux,若小于110lux,则执行步骤(6a-18),否则执行步骤(6a-19);
[0254]
(6a-18)将裁剪出的人员目标框区域图像分别输入适用于白天中光照强度和白天强光照强度识别的改进的yolov3-tiny目标检测网络分别进行人员安全帽和防护服检测并基于相邻两个模型的识别结果进行相邻防护状态融合判断,然后执行步骤(6a-20);
[0255]
(6a-19)将裁剪出的人员目标框区域图像输入适用于白天强光照强度识别的改进的yolov3-tiny目标检测网络进行人员安全帽和防护服检测;
[0256]
(6a-20)储存当前帧人员安全帽和防护服穿戴信息。
[0257]
1.1yolov4目标检测网络进行人员检测,具体包括以下步骤:
[0258]
(6a-4-1)从白天光照强度为0.002-10lux作业现场的监控摄像头拍摄的视频中抽取出1万张包含作业人员的彩色视频帧,从白天光照强度为10-100lux作业现场的监控摄像头拍摄的视频中抽取出1万张包含作业人员的彩色视频帧,从白天光照强度大于100lux作业现场的监控摄像头拍摄的视频中抽取出2万张包含作业人员的彩色视频帧,从夜间作业现场监控摄像头拍摄的视频中抽取出1万张包含作业人员的红外灰度视频帧,建立作业人员图像数据集,并按照9:1的比例将数据集划分为训练集和验证集;
[0259]
(6a-4-2)建立train.txt文件,包含训练集中所有图片的储存路径;建立val.txt文件,包含验证集所有图片的储存路径;使用labelimg工具对数据集图像中的人员标记,将人员区域标记为person,得到对应的xml格式的数据集文件,利用python脚本程序将xlm格式的数据集转换为适用于yolov4目标检测网络的txt格式的数据集;
[0260]
(6a-4-3)利用darknet深度学习框架搭建yolov4目标检测网络,具有以下步骤:
[0261]
1)采用cspdarknet53网络结构搭建yolov4目标检测网络的backbone部分,backbone部分的激活函数使用mish激活函数,其公式为:
[0262]
f(x)=x*tanh(log(1+e
x
))
[0263]
其中x为激活函数所在网络层的输入值,tanh()为双曲正切函数,mish激活函数函数曲线平滑,能够允许更好的信息深入神经网络,从而得到更好的准确性和泛化,采用dropblock方法,随机丢弃特征图的图像信息来缓解过拟合;
[0264]
2)采用spp模块和fpn+pan的结构搭建yolov4目标检测网络的neck部分;
[0265]
3)yolov4目标检测网络的目标框回归损失函数采用ciou_loss损失函数,使得预测框回归的速度和精度更高,其公式为
[0266][0267]
其中iou为目标检测预测框和真实框的交并比,distance_c为目标检测预测框和真实框的最小外接矩形的对角线距离,distance_2为目标检测预测框和真实框中心点的欧氏距离,v是衡量目标检测预测框和真实框长宽比一致性的参数;
[0268]
4)yolov4目标检测网络采用diou_nms目标框筛选方法(在重叠目标的检测中,diou_nms的效果优于传统的nms)。
[0269]
(6a-4-4)建立yolov4.names文件,此文件每一行就是一个要识别对象的类别名,将第一行设为person;
[0270]
建立yolov4.data文件,此文件用于储存识别类别种类数、训练集文件地址、验证集文件地址和名称文件地址等信息,将yolov4.data文件中的类别数设为1、训练集文件地址设为“train.txt”文件所在地址,验证集文件地址设为“val.txt”文件所在地址,名称文件地址设为“yolov4.names”文件所在地址。
[0271]
采用coco图像数据集(coco数据集包含20万张从复杂的日常场景中截取的图像,具有80个目标类别和超过50万个目标标注,是目前最广泛公开的目标检测数据集)对yolov4目标检测网络进行物体分类训练,每次迭代训练64张图片,迭代500000次,得到部分训练完成的yolov4网络模型;
[0272]
(6a-4-5)在步骤(6a-4-4)结果的基础上,采用制作的现场作业人员图像数据集对yolov4目标检测网络进行训练,每次迭代训练64张图片,迭代200000次得到能够用于现场人员检测的yolov4网络模型;
[0273]
(6a-4-6)将视频帧输入yolov4目标检测网络中,得到视频帧中检测出人员的可信度及人员目标框的坐标参数。
[0274]
1.2改进的yolov3-tiny目标检测网络并且基于匹配不同光照强度的多个网络模型权重进行人员安全帽和防护服检测,具体包括以下步骤:
[0275]
(6a-8-1)从白天光照强度为0.002lux-10lux的作业现场的监控摄像头拍摄的视频中抽取出1万张包含安全帽和防护服的彩色视频帧,从白天光照强度为10lux-100lux的作业现场的监控摄像头拍摄的视频中抽取出1万张包含安全帽和防护服的彩色视频帧,从白天光照强度大于100lux的作业现场的监控摄像头拍摄的视频中抽取出2万张包含安全帽和防护服的彩色视频帧,从夜间作业现场监控摄像头拍摄的视频中抽取出1万张包含安全帽和防护服的红外灰度视频帧,分别建立白天弱光强人员安全帽和防护服图像数据集、白天中光强人员安全帽和防护服图像数据集、白天强光强人员安全帽和防护服图像数据集和夜间安全帽和防护服图像数据集,并利用mosaic数据增强的方式,将4张图片通过随机缩放、随机裁剪、随机排布的方式拼接为1张新的图片来扩充上述四个数据集,以增强对小目标的识别能力,并将四个数据集按照9:1的比例都划分为训练集和验证集;
[0276]
建立train0.txt文件,包含白天弱光强人员安全帽和防护服图像训练集中所有图片的储存路径;建立val0.txt文件,包含白天弱光强人员安全帽和防护服图像验证集所有图片的储存路径;
[0277]
建立train1.txt文件,包含白天中光强人员安全帽和防护服图像训练集中所有图片的储存路径;建立val1.txt文件,包含白天中光强人员安全帽和防护服图像验证集所有图片的储存路径;
[0278]
建立train2.txt文件,包含白天强光强人员安全帽和防护服图像训练集中所有图片的储存路径;建立val2.txt文件,包含白天强光强人员安全帽和防护服图像验证集所有图片的储存路径;
[0279]
建立train3.txt文件,包含夜间人员安全帽和防护服图像训练集中所有图片的储存路径;建立val3.txt文件,包含夜间人员安全帽和防护服图像验证集所有图片的储存路径;
[0280]
(6a-8-2)使用labelimg工具对数据集图像中人员安全帽和防护服进行标记,佩戴安全帽的头部区域标记为hat,未佩戴帽子的头部区域标记为head,防护服区域标记为
clothe,得到对应的xml格式的数据集文件,并将xlm格式的数据集利用python脚本文件转换为适用于yolov3-tiny目标检测网络的txt格式的数据集;
[0281]
(6a-8-3)利用darknet深度学习框架搭建改进的yolov3-tiny目标检测网络,具有以下步骤:
[0282]
1)以yolov3-tiny目标检测网络为基本框架,进行网络模型修改剪枝操作;
[0283]
2)使用谷歌efficient-b0深度卷积神经网络替换yolov3-tiny原有的主干网络,去除efficient-b0深度卷积神经网络的132-135层,在131层后分别添加2个卷积层,1个shortcut层,1个卷积层,一个yolo层;
[0284]
3)在步骤2)得到的网络的基础上,在网络的133层后顺序连接1个route层,1个卷积层,1个降采样层,1个shortcut层,1个卷积层,2个shortcut层,1个卷积层,1个yolo层,得到改进的yolov3-tiny目标检测网络;
[0285]
建立yolov3-tiny.names文件,此文件每一行就是一个要识别对象的类别名,将第一行设为hat,第二行设为head,第三行设为clothe;
[0286]
建立yolov3-tiny.data文件,此文件用于储存识别类别种类数、训练集文件地址、验证集文件地址和名称文件地址等信息,将yolov3-tiny.data文件的classes设为3,训练集文件地址设为“train.txt”文件所在地址,验证集文件地址设为“val.txt”文件所在地址,名称文件地址设为“yolov3-tiny.names”文件所在地址。
[0287]
(6a-8-4)利用k-means算法(对于给定的数据集,按照数值之间的距离大小将数据集划分为k个簇,使簇内数值之间距离尽量小,簇间距离尽量大)对安全帽和防护服数据集中的安全帽和防护服的真实框长宽参数进行聚类计算,用真实框聚类得到的长宽数据替代yolov3-tiny目标检测网络原有的先验框长宽数据,以提高目标框的检出率;
[0288]
(6a-8-5)采用制作的白天弱光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,每次迭代训练64张图片,迭代50000次得到能够用于白天弱光强环境的人员安全帽和防护服检测的网络模型;
[0289]
(6a-8-6)采用制作的白天中光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,每次迭代训练64张图片,迭代50000次得到能够用于白天中光强环境的安全帽和防护服检测的网络模型;
[0290]
(6a-8-7)采用制作的白天强光强人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,每次迭代训练64张图片,迭代100000次得到能够用于白天强光强环境的安全帽和防护服检测的网络模型;
[0291]
(6a-8-8)采用制作的夜间人员安全帽和防护服数据集对改进的yolov3-tiny目标检测网络进行训练,每次迭代训练64张图片,迭代50000次得到能够用于夜间人员安全帽和防护服检测的网络模型;
[0292]
(6a-8-9)根据现场环境光照强度数据将裁剪过的人员目标区域输入适用于不同光照强度的改进的yolov3-tiny目标检测网络,得到现场人员穿戴安全帽和防护服的可信度及安全帽和防护服目标框的坐标参数。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1