一种基于知识图卷积网络的模型混合推荐方法与流程
[0001]
本发明涉及机器学习领域,尤其是一种基于知识图卷积网络的模型混合推 荐方法。
背景技术:
[0002]
随着互联网技术的迅猛发展,人们可以足不出户便轻松获得诸如新闻[1]、 影视[2]和商品[3]等大量的网上资讯。如何从如此海量的信息中剔除用户不需 要的信息而获取用户所需的有用信息,如何有效提升用户体验成为了人们关注 的焦点。为了缓解信息过载,推荐系统应运而生。
[0003]
推荐系统作为一种筛选信息的工具,可以有效解决信息过载问题,通过个 性化的方式提供满足用户需求的内容。在早期的推荐系统中,协同过滤推荐算 法是应用广泛的技术。基于协同过滤的算法[4-6]通过挖掘用户的历史数据来发 现用户的偏好。但是基于协同过滤的算法通常存在用户-物品交互的稀疏性[7] 和冷启动问题[8]。为解决稀疏性和冷启动问题,一些研究者利用用户和物品的 属性来弥补冷启动和稀疏性问题以提高推荐性能[9-11]。近年来一些研究[12-16] 不再使用单纯的属性,而是认为属性间是有关系的,这种关系构成了知识图谱。 将知识图谱作为附加信息引入到推荐系统以实现物品的个性化混合推荐方法 在一定程度上可以缓解冷启动、稀疏矩阵的问题。进一步,文献[17]将知识图 谱和图卷积结合,提出了用于推荐系统的知识图卷积网络(kgcn),这是一 种捕捉知识图谱中语义信息和高阶结构信息的推荐模型。kgcn的核心思想是 在计算给定实体的知识图表示的过程中有偏好地聚合和合并实体的邻居信息。 但是kgcn只捕获了项目间的相关性用于推荐预测,而忽视了用户间的相关 性以及用户的历史交互记录。
[0004]
近年来,因混合推荐算法结合多种推荐方法,能实现算法间的取长补短, 提高推荐系统的性能,而成为了研究热点[18-20]。其中,将深度学习融入推荐 领域作为一个新方向得到了产业界和学术界的青睐。推荐方法中融合深度学习 技术,可以有效解决传统推荐系统中冷启动、稀疏矩阵等问题,提高推荐系统 的性能和推荐精度。研究中,kgcn和kg两种方法各自具有一定优势。
[0005]
kgcn是推荐系统研究的一种新视角,主要受gcn非光谱法思想的启发。 非光谱方法直接在原始图上操作,并为节点组定义卷积。为了处理大小各异的 邻域并保持卷积神经网络(convolutional neural networks,cnn)的权重共享特 性,研究人员建议针对每个节点度学习权重矩阵[21],从图中提取局部相连的 区域[22],或采样一组固定大小的邻域作为支持大小[23]。kgcn的主要思想 是在计算知识图谱中给定实体的表示时,将带有偏差的邻域信息进行聚合和合 并。将kg引入推荐系统具有以下优点:一是可以利用图中节点之间丰富的语 义关系挖掘其潜在的关联以提高结果的准确性;二是可以增加项目的多样性; 三是可以利用用户的历史交互数据增加系统的可解释性。尽管具有上述优点, 但由于其高维度和异质性,在推荐系统中中使用kg仍具有挑战性。一种方法 是通过知识图嵌入方法对kg进行预处理[24]。另一种方法是设计图算法以利 用kg结构。基于图结构的方法并不局限
于实体间具体的连接路径,而是将知 识图谱看做以特定用户/项目为中心的巨大关系网。采用以用户/项目为中心向 外扩散的方式,来提取对应实体的特征应用到推荐当中。如何将知识图谱中的 辅助信息有效的提取出来并应用到推荐系统的场景中是最核心的问题。针对这 个问题,一些科研工作者进行了尝试:文献[13]提出了用户兴趣扩散的思想, 以用户历史交互的各个项目实体为中心进行扩散来提取用户的兴趣特征。文献[25]尝试利用知识图谱的结构特征,将本体融进协同过滤算法。文献[15]尝试 将知识图谱表示学习算法与基于隐性反馈的协同过滤相结合,把原始数据转化 为偏好序列进行参数学习,加强了协同过滤推荐算法的性能。文献[26]将表示 学习的思想应用于知识图谱领域,提出了一种知识图谱表示学习算法transe。 文献[17]将gcn与知识图谱相结合来提取推荐项目的嵌入特征应用到推荐系 统中。但上述方法多是根据项目的相似性进行推荐,而忽略了用户的相似性。
[0006]
综上所述,kgcn主要用于捕获物品之间的相关性,未考虑捕获用户间的 相关性以及传统的协同过滤推荐系统存在的稀疏性和冷启动问题,从而导致推 荐结果不够准确。
[0007]
本发明涉及到的参考文献:
[0008]
1.ge,s.,et al.graph enhanced representation learning for news recommendation.in www'20:the web conference 2020.2020.
[0009]
2.iliopoulou,k.,et al.,improving movie recommendation systems filtering by exploiting user-based reviews and movie synopses,in artificial intelligence applications and innovations.aiai 2020ifip wg 12.5international workshops. 2020.p.187-199.
[0010]
3.guorui zhou,x.z.,chenru song,ying fan,han zhu,xiao ma,yanghui yan,junqi jin,han li,and kun gai,deep interest network for click-through rate prediction.2018.
[0011]
4.chen,r.,et al.,a survey of collaborative filtering-based recommender systems:from traditional methods to hybrid methods based on social networks. ieee access,2018.6:p.64301-64320.
[0012]
5.li,w.,et al.,a collaborative filtering recommendation method based on discrete quantum-inspired shuffled frog leaping algorithms in social networks
☆
. 2018.88(nov.):p.262-270.
[0013]
6.jiang,m.,et al.,a collaborative filtering recommendation algorithm based on information theory and bi-clustering.neural computing and applications,2019. 31(12):p.8279-8287.
[0014]
7.<mitigating the effect of data sparsity_a case study on collaborativefiltering recommender system.pdf>.
[0015]
8.alhijawi,b.,et al.improving collaborative filtering recommender systems using semantic information.in 2018 9th international conference on information and communication systems(icics).2018.
[0016]
9.shine:signed heterogeneous information network embedding for sentiment link prediction.
neural networks for graphs.2016.
[0030]
23.will hamilton,z.y.,and jure leskovec,inductive representation learning on large graphs.in advances in neural information processing systems,2017:p. 1024
–
1034.
[0031]
24.wang,q.,et al.,knowledge graph embedding:a survey of approaches and applications.2017.29(12):p.2724-2743.
[0032]
25.zhang,z.,l.gong,and j.xie,ontology-based collaborative filtering recommendation algorithm.2013.
[0033]
26.antoine bordes,n.u.,alberto garcia-duran,jason weston,and oksana yakhnenko,translating embeddings for modeling multi-relational data.2013.
[0034]
27.koren,y.,factorization meets the neighborhood:a multifaceted collaborative filtering model,in proceedings of the 14th acm sigkdd international conference on knowledge discovery and data mining.2008, association for computing machinery:las vegas,nevada,usa.p.426
–
434.
[0035]
28.rendle,s.,factorization machines with libfm.2012.3(3%j acm trans. intell.syst.technol.):p.article 57.
技术实现要素:
[0036]
本发明的发明目的在于:针对上述存在的问题,提供一种基于知识图卷积 网络的模型混合推荐方法,在将知识图谱引入推荐系统的同时加入了基于用户 的协同过滤以捕获用户间的相关性,避免kgcn及传统的协同过滤推荐系统 存在的稀疏性和冷启动问题,提高推荐的准确率。
[0037]
本发明采用的技术方案如下:
[0038]
一种基于知识图卷积网络的模型混合推荐方法,包括:a.计算用户实体 集u与项目实体关系集r之间的第一评价,根据输入的用户实体u,以及每个用 户实体和项目实体在知识图谱中的邻居集合n(i),计算用户实体u与其邻域中 各个项目实体关系r的第一评价,将用户实体u与其邻域中各个项目实体关系r 的第一评价进行聚合,其中,项目实体关系集r由每两两项目实体间的关系r构 成;b.根据步骤a的聚合结果,以及输入的待选项目实体i,对待选项目实 体i的拓扑邻近结构进行聚合;c.根据步骤c的聚合结果,计算用户实体u对 待选项目实体i的第一感兴趣概率;d.基于已训练好的协同过滤模型,计算用 户实体u与项目实体集i之间的第二评价集合;e.基于步骤d中计算的第二评 价集合,计算用户实体u与待选项目实体i之间的第二感兴趣概率;f.将用户 实体u对项目实体i的第一感兴趣概率和第二感兴趣概率进行融合,得到最终预 测结果。
[0039]
进一步的,所述用户实体集u与项目实体关系集r之间的第一评价的计算 方法为:其中,s
u,r
为第一评价值,f(*)表示全连接层,u和 r分别表示用户u实体u的集合和项目实体关系r的集合,表示元素间的內积。
[0040]
进一步的,所述步骤b包括:以待选项目实体i的邻居的线性组合来 表示待
选项目实体i的拓扑邻近结构:其中是标 准化后的用户实体u与其邻域中各个项目实体关系r间的第一评价: e是实体e的表示;将每个用户实体和项目实体在知 识图谱中的邻居集合的个数设定为固定大小且 k为邻居集合的个数;将待选项目实体i的拓扑邻近结构进行 迭代聚合操作,直至收敛至第0层:其中w表 示可学习的权重,b表示可学习的偏置,σ表示relu激活函数。
[0041]
进一步的,所述k等于4或8。
[0042]
进一步的,所述步骤c中,计算用户实体u对待选项目实体i的第一感兴趣 概率的方法为:其中表示sigmoid激活函数,u是用户 实体u的表示,是聚合特征。
[0043]
进一步的,所述步骤d中,计算指定用户实体u1与项目实体集i之间的第二 评价集合的方法为:对于项目实体集i中的各项目实体i,分别计算:s=η(c(u,i)), 其中,c(u,i)表示利用协同过滤模型计算的用户实体u对项目实体i的第二评价, η(*)表示归一化函数,第二评价值s的取值范围为[0,1]。
[0044]
进一步的,所述步骤e中计算用户实体u与待选项目实体i之间的第二感兴 趣概率的方法为:
[0045]
进一步的,所述步骤f中,将用户实体u对待选项目实体i的第一感兴趣概 率和第二感兴趣概率进行融合的方法为,将所述第一感兴趣概率和第二感兴趣 概率进行平均处理。
[0046]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0047]
本发明的基于知识图谱的图卷积混合模型推荐方法,将用户实体的邻域信 息迭代的融入到协同过滤中并利用知识图谱的高阶连通性来辅助推荐,对于邻 域信息的迭代聚合操作,充分利用了知识图谱的结构信息来提取用户兴趣特征, 并引入注意力机制为不同的聚合信息分配权重。在引入知识图谱的过程中,既 捕获了物品的相关性也捕获了用户的相关性,将二者进行融合提出了基于知识 图谱的图卷积混合模型推荐方法,从而提高推荐的准确度。
附图说明
[0048]
本发明将通过例子并参照附图的方式说明,其中:
[0049]
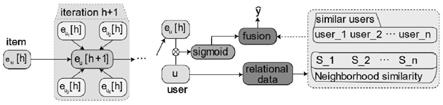
图1是知识图谱中邻域信息聚合示意图。
[0050]
图2是计算最终预测结果的计算流程图。
[0051]
图3是kgcn-cf在不同邻居采样个数k下的auc结果。
[0052]
图4是kgcn-cf在不同接收野深度h下的auc结果。
[0053]
图5是kgcn-cf在不同特征维度d下的auc结果。
具体实施方式
[0054]
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互 相排斥的特征和/或步骤以外,均可以以任何方式组合。
[0055]
本说明书(包括任何附加权利要求、摘要)中公开的任一特征,除非特别 叙述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非特别叙 述,每个特征只是一系列等效或类似特征中的一个例子而已。
[0056]
名词定义:
[0057]
a)用户集u={u1,u2,...,u
m
}其中m表示用户的个数。
[0058]
b)项目集i={i1,i2,...,i
n
},其中n表示项目的个数。
[0059]
c)用户-项目交互矩阵该交互矩阵根据用户的隐 式反馈定义而成,其中y
u,i
=1表示用户对项目有过点击、购买或浏览等行为。 相应地,y
u,i
=0表示用户对项目没有历史交互行为。
[0060]
知识图谱三元组为g=(h,r,t),其中表示一个知识三元组的 头部、关系、尾部,和分别是知识图中实体和关系的集合。例如,对电影《阿 甘正传》,知识图谱存在三元组(forrest gump,film.film.star,tom hanks)表 示tom hanks是影片《forrest gump》的主演。(实体、关系、实体)在本发明 涉及的推荐场景中,用户与项目都对应于知识图谱中的一个实体。
[0061]
实施例一
[0062]
一种基于知识图卷积网络的模型混合推荐方法,包括:
[0063]
输入数据包括:用户实体u,待选项目实体i,以及每个用户实体和项目实 体在知识图谱中的邻居集合n(i)。方法包括:
[0064]
a.计算用户实体u与其邻域中各个项目实体关系r之间的第一评价,将用 户实体u与其邻域中各个项目实体关系r的第一评价进行聚合:
[0065]
用户实体集u与项目实体关系集r之间的第一评价表示为:
[0066]
其中s
u,r
为第一评价值,表示各项目实体关系r对于相关用户 实体u的重要程度,f(*)表示全连接层(优选输出维度为8),u和r分别表示用 户实体u的集合和项目实体关系r的集合,表示元素间的內积,表示u和r的 维度,项目实体i
a
和i
b
的关系表示为例如类型、作者等属性信息 方面的关系,两两项目实体间的关系组成项目实体关系集r。根据输入的用户 实体u以及每个用户实体和项目实体在知识图谱中的邻居集合n(i),从上式中 即可计算出用户实体u与其邻域中各个项目实体关系r的第一评价。
[0067]
对于同一个用户实体u来说,存在着多个项目实体关系r,这些项目实体关 系对于用户实体来说又必将存在着不同程度的影响,因此,聚合的步骤很有必 要。
[0068]
b.根据步骤a的聚合结果,以及输入的待选项目实体i,对待选项目实体i的 拓扑
邻近结构进行聚合。
[0069]
以项目实体i的邻居的线性组合i
n(i),u
来表示项目实体i的拓扑邻近结构:
[0070][0071]
其中是标准化后的用户实体u与项目实体关系r的第一评价:
[0072][0073]
e是实体e的表示。
[0074]
在知识图谱中,邻居集合的个数存在着很大的差异,所以我们将每个 实体的邻居集合的个数设定为固定大小,不使用完整的邻居集合。设k为 邻居集合的个数,取并且其中k是一个可修改 的常数,表示了知识图谱中每一层中取的邻居个数。
[0075]
最终将项目实体i的邻居表示(拓扑邻近结构)i
n(i),u
进行聚合:
[0076]
j=σ(w
·
(i+i
n
′
(i),u
)+b)
[0077]
其中w表示可学习的权重,b表示可学习的偏置,σ表示relu激活函数。 模型迭代的聚合过程由用户u在知识图谱中发散出的邻域迭代地聚合到中心实 体e上,如图1所示,假设最中心的实体为中心实体e,我们在提取用户特征的 时候考虑到知识图谱中n-hop(n∈n
*
)范围内的实体,中心实体e在1-hop范围内 的邻居由与e直接相连的实体(有交互记录的项目)组成,相应地,2-hop范围 内的邻居由1-hop范围中实体e的直连实体的邻居组成。以此类推,模型提取 的邻居包括n层,则模型的聚合操作总共迭代n次,第i次迭代是对n-i+1层 内的所有实体进行聚合邻域信息。当模型收敛至第0层,完成聚合操作。
[0078]
c.计算用户实体u对待选项目实体i的第一感兴趣概率。
[0079][0080]
其中表示sigmoid激活函数,u是某指定用户实体u的表示,是聚合特征。
[0081]
上述过程主要针对项目实体间的关系进行信息聚合,本发明还包括用户实 体件相似性的分析过程。
[0082]
d.基于已训练好的协同过滤(user-cf)模型,计算输入的用户实体u与 项目实体集i之间的第二评价集合。对于各项目实体,分别采用下式计算:
[0083]
s=η(c(u,i))
[0084]
其中c(u,i)表示利用协同过滤模型计算的用户实体u对项目实体i的第二评 价,η(*)表示归一化函数,s的取值范围为[0,1]。
[0085]
e.基于步骤d中计算的第二评价集合,计算用户实体u1与项目实体i1之间 的第二感兴趣概率计算方法为:
[0086][0087]
根据相同原理,计算用户实体u与待选项目实体i之间的第二感兴趣概率的 方法
为:
[0088][0089]
f.将用户实体u对待选项目实体i的第一感兴趣概率和第二感兴趣概率进行 融合,得到最终预测结果。
[0090][0091]
其中a(*)是求平均函数,为最终的预测结果。
[0092]
将上述模型预测结果与l2正则化相结合,设计了如下完全损失函数:
[0093][0094]
其中c(*)是交叉熵损失函数,表示求函数f的l2正则化,λ为可学习参 数,y
u,i
表示用户实体与项目实体间的交互关系,y
u,i
=1表示用户对项目有过点 击、购买或浏览等行为。相应地,y
u,i
=0表示用户对项目没有历史交互行为。
[0095]
实施例二
[0096]
本实施例公开了一种基于知识图谱的图卷积混合模型推荐方法,其基本思 路是:通过在推荐过程中引入知识图谱,并利用用户的历史交互数据将物品的 信息与其邻居进行有偏好地聚合,同时在计算用户-关系分值时加入注意力机 制计算用户交互过的物品和候选物品之间的相似性,接下来再融入基于用户的 协同过滤,进行准确的推荐,提高推荐的准确率。
[0097]
在一个典型的推荐场景中,我们将知识图感知推荐问题描述如下:
[0098]
a)用户集u={u1,u2,...,u
m
}其中m表示用户的个数。
[0099]
b)项目集i={i1,i2,...,i
n
},其中n表示项目的个数。
[0100]
c)用户-项目交互矩阵该交互矩阵根据用户的隐式反馈 定义而成,其中y
u,i
=1表示用户对项目有过点击、购买或浏览等行为。相应地, y
u,i
=0表示用户对项目没有历史交互行为。
[0101]
d)知识图谱三元组为g=(h,r,t),其中表示一个知识三元组的 头部,关系和尾部,和分别是知识图中实体和关系的集合。例如,对电影《阿 甘正传》,知识图谱存在三元组(forrest gump,film.film.star,tom hanks)表 示tom hanks是影片《forrest gump》的主演。(实体、关系、实体)在本文涉 及的推荐场景中,用户与项目都对应于知识图谱中的一个实体。
[0102]
本实施例的目的是在给定用户u,拟推荐项目i以及对应知识图谱g的条件 下,根据用户交互矩阵y和知识图谱g预测用户u对之前从没有接触过的物品i 是否感兴趣。具体来说,我们的目标分为两部分,其中一部分是学习预测函数
[0103][0104]
其中表示用户u对项目i感兴趣的概率,f表示kgcn函数,w表示模 型函数f的可训练参数。
[0105]
另一部分为:
[0106][0107]
其中g表示基于用户的协同过滤函数。
[0108]
我们根据和这两个概率的融合结果判定用户是否会对该项目进
[0109]
为此,本实施例设计了kgcn-cf模型。kgcn-cf用来发现知识图谱中用 户的潜在兴趣以及提取实体之间的隐藏关系特征。模型有三部分输入:用户实 体u,待选项目实体i,以及每个用户和项目实体在知识图谱中的邻居集合n(i), 其中用户的邻居由用户历史交互记录中的项目实体组成。我们将两个项目实体 i
a
和i
b
的关系表示为
[0110]
现实中,大量用户的兴趣侧重点都不同,比如,有的用户对于同一个歌手 演唱的歌曲感兴趣,而有的用户可能更注重歌曲的曲风。在推荐系统中计算关 系r对于用户u的重要程度是十分重要的。首先,我们将用户和关系之间的得分 表示为:
[0111][0112]
其中s
u,r
表示关系r对于用户u的重要程度,f(*)表示全连接层(输出维度为 8),u和r分别表示用户u和关系r,表示元素间的內积,表示u和r的维度, 当u和r的输入维度增大时会增加模型的计算负担,并且有可能会引入 多余的噪声,所以我们在(3)式中加入了f(*)。一方面,加入f(*)可以降低模 型的学习参数,当u和r的输入维度很大时,也能将模型的参数控制在较少的 范围。另一方面,有效地减少了长维度向量中引入的噪声。对于同一个用户u来 说,存在着多个关系r,这些关系对于用户来说又必将存在着不同程度的影响。 因此,我们就需要将用户u与其邻域中各个关系r的得分进行聚合。
[0113]
另外,我们使用项目i的邻居的线性组合i
n(i),u
来表示项目i的拓扑邻近结构:
[0114][0115]
其中是标准化后的用户和关系之间的得分:
[0116][0117]
e是实体e的表示。
[0118]
在知识图谱中,邻居集合的个数存在着很大的差异,所以我们将每个 实体的邻居集合的个数设定为固定大小,不使用完整的邻居集合。设k为 邻居集合的个数,取并且其中k是一个可修改 的常数,表示了知识图谱中每一层中取的邻居个数。以两层接受域(h=2)的 图1为例,中心实体为给定的实体,k设置为3,灰色实体为邻居集合。接着, 我们需要将实体表示i和邻居表示进行聚合:
[0119]
j=σ(w
·
(i+i
n
′
(i),u
)+b)
ꢀꢀꢀ
(6)
[0120]
其中w表示可学习的权重,b表示可学习的偏置,σ表示relu激活函数。 模型迭代的聚合过程由用户u在知识图谱中发散出的邻域迭代地聚合到中心实 体e上。如图1所示,假设位于中心的实体为中心实体e,我们在提取用户特征 的时候考虑到知识图谱中n-hop(n
∈n
*
)范围内的实体,中心实体e在1-hop范围 内的邻居由与e直接相连的实体(有交互记录的项目)组成,相应地,2-hop 范围内的邻居由1-hop范围中实体e的直连实体的邻居组成。以此类推,模型 提取的邻居包括n层,则模型的聚合操作总共迭代n次,第i次迭代是对n-i+1 层内的所有实体进行聚合邻域信息。当模型收敛至第0层,完成聚合操作,用 户u对项目i感兴趣的概率为:
[0121][0122]
其中表示sigmoid激活函数,u是某指定用户的表示,是聚合特征。
[0123]
以上聚合信息的过程都是针对项目间的关系进行信息聚合,忽略了用户间 的相似性。并且考虑到以下问题:当邻居聚合的个数偏少时,会造成聚合的关 系信息不足和获取的用户兴趣偏好不准;当邻居聚合的个数过多时,会造成聚 合的信息过多,难以对用户进行更加准确和优质的推荐;推荐结果完全依赖于 项目间的邻居关系。为了弥补上述缺陷,我们借鉴了基于用户的协同过滤 (user-cf)算法,并将其与kgcn进行融合。由于篇幅限制,因此本文不对 user-cf进行详细的公式推导,假设已经训练好的user-cf模型为c,用户u对 项目i的评分为c(u,i)。在实际的计算过程中,user-cf往往预测的是用户u对项 目i的评分,这就需要将评分结果转换成感兴趣的概率。例如,设候选项目集 i={i1,i2,
…
,i
m
},我们需要计算指定用户u1对候选项目i1(i1∈i)感兴趣的概率,用户对 候选项目集i中的项目初始感兴趣的概率那么将得到用户u1与项目 集合i之间的评分集合:
[0124]
s=η(c(u1,i))
ꢀꢀꢀ
(8)
[0125]
其中η(*)表示归一化函数,s的取值范围为[0,1]。因此,用户u1与项目i1之间 的感兴趣概率为:
[0126][0127]
最终,我们将kgcn的计算结果与user-cf的计算结果进行融合:
[0128][0129]
其中a(*)是求平均函数,为最终的预测结果。如图2示出了预测流程的 计算过程。
[0130]
我们将kgcn-cf模型与l2正则化相结合,设计了如下完全损失函数:
[0131][0132]
其中c(*)是交叉熵损失函数,表示求函数f的l2正则化,λ为可学习参 数。
[0133]
上述过程可预测出特定用户实体对待选项目实体进行选择的概率。本实施 例还对上述模型预测的结果进行了验证。
[0134]
为了验证本文所提出算法的有效性,我们进行了如下实验。在本节中,我 们首先简要介绍了dianping-food、book-crossing和last.fm三个数据集,然 后使用这三个数据集来验证kgcn-cf的优越性,并与svd﹑libfm等模型进 行了对比,实验设置如下。
[0135]
1数据集和实验环境
[0136]
本节主要针对上述提出的基于知识图谱的图卷积混合模型推荐方法的有效 性在
dianping-food、book-crossing、last.fm三个数据集上进行实验与分析。 数据集详细情况如下:
[0137]
表1数据集详情
[0138][0139]
其中dianping-food由dianping.com提供,它包含了大约200万用户和1000 家餐厅之间超过1000万次的互动(包括点击、购买和添加收藏夹)。对应的 kg包含28115个实体、160519个边和7个关系类型。book-crossing包含了从 图书漂流网站社区中爬取的100多万条从1分到10分不等的评分记录,对应 知识图谱中25787个实体和18种关系。last.fm收集了在线音乐系统中两千多 名用户的收听记录,对应知识图谱中9366个实体和15518种关系。本发明提 出的模型主要由两部分组成:基于知识图谱的图卷积模型kgcn和user-based 的协同过滤模型,对于模型的第一部分kgcn,隐式反馈能够提高该组件的预 测准确率,因此对于上述两种显式反馈的数据集,我们将其转换为隐式反馈, 正采样设置为1,负采样设置为0。对于模型的第二部分,需要使用到评分记 录来计算相似性,因此不需要将显式反馈转换为隐式反馈。
[0140]
表2.实验环境
[0141][0142]
表2给出了本实验实验环境的详细信息。我们主要使用tensorflow训练模 型。
[0143]
2参数设置
[0144]
在实验中,我们主要通过调整邻居采样个数、特征维度和接受野的深度来 分析这些参数对模型的影响程度和变化趋势。
[0145]
表3.模型参数配置
[0146][0147]
表3给出了在实验中两个数据集的基本统计信息和kgcn-cf超参数的设 置(k:邻居采样个数,d:特征维度;h:接受野的深度;λ:l2正则项 系数)。同时,我们在后续的实验参数调整部分分别对它们进行了调整: k∈{2,4,8,16,32,64},d∈{4,8,16,32,64},h∈{1,2,3,4}。
[0148]
3基线
[0149]
为了验证kgcn-cf是否优于现有方法,我们将kgcn-cf与以下7个已 有的模型进行了比较:
[0150]
svd[27]:推荐系统中一个经典的基于协同过滤的隐含因素模型。
[0151]
libfm[28]:一种基于特征的分解模型,
[0152]
libfm+transe:结合libfm和transe两种方法,把transe[26]学习到的实 体表示拼接到每个用户-物品对,再作为libfm的输入。
[0153]
per[11]:使用kg中的“物品-属性-物品”作为per的特征(例如,
ꢀ“
movie-director-movie”)。但per不能被应用到新闻推荐,因为在新闻实体中 很难预定义元路径(meta-path)。
[0154]
cke[15]:联合学习协同过滤的隐式向量以及物品的基于知识库的语义表达。
[0155]
ripplenet[13]:在知识图谱上模拟用户传播偏好的推荐模型。
[0156]
kgcn[17]:是一种捕捉kg中语义信息和高阶结构信息的推荐模型。
[0157]
4结果对比与分析
[0158]
首先,我们在book-crossing数据集和last.fm两个数据集上比较了本发明 提出的方法kgcn-cf和上述七种已有模型的预测准确度与f1值,实验结果 如表4所示。
[0159]
表4.kgcn-cf与基线的对比
[0160][0161][0162]
从表4可以看出,本发明提出的kgcn-cf在dianping-food、book-crossing 数据集和last.fm数据集上显示的性能均优于其他7个模型,auc和f1在 dianping-food数据集上
分别提高了3.4%~13.4%和3.4%~12.1%,在 book-crossing数据集上分别提高了2.7%~18.7%和1.0%~19.1%,在last.fm数 据集上分别提高了6.9%~25.8%和7.1%~23%。通过表4可以发现kgcn-cf在 book-crossing和last.fm数据上auc和f1值的提高要高于dianping-food。 这表明kgcn-cf可以很好地解决稀疏场景,因为book-crossing和last.fm 比dianping-food稀疏。kgcn-cf在考虑了物品kg中的语义信息和高阶结构 信息的前提下,也考虑了用户之间的相关性,较kgcn有了明显提高,这表 明考虑用户之间的相关性更有利于推荐。实验表明该方法在多种数据集上均具 有很好的建模能力。
[0163]
表4中的最后四行总结了kgcn-cf变体的性能。前三个(sum,concat, neighbor)对应于不同聚合器,sum聚合器将两个表示向量相加,concat聚合器 将两个表示向量连接在一起,neighbor聚合器直接将实体的邻居表示作为输出 表示。而最后一个变体kgcn-avg是kgcn-sum的简化情况,其中邻域表示 直接取平均而没有用户关系得分。因此,kgcn-cf-sum用于检查“注意机制
”ꢀ
的有效性。
[0164]
图3给出了kgcn-cf在不同邻居采样个数k下的auc结果。从图3中我 们发现,当k=4或8时,kgcn-cf可获得最佳性能。此行为表明,太小的k没有足够的容量来合并邻域信息,而考虑到太大的k邻居关系,则无用的邻 居关系将被引入,从而降低最终的预测性能。对于不同的数据集,我们需要考 虑的邻居关系个数也不同,例如,有些人对音乐的收听可能只考虑演唱者和歌 曲热度,然而对于书籍的阅读却要考虑更多的因素。
[0165]
图4给出了kgcn-cf在不同接收野深度h下的auc结果。当接收野深度 h取值大于1时,在dianping-food、book-crossing和last.fm数据集上的auc 都有所提升,但随着h的增加,auc没有继续提升且维持在一个水平上。这 说明了接收野深度h对于kgcn-cf的预测性能的影响很小,我们不需要对接 收野深度进行繁复的调参就能得到很好的结果。但是接受野也不能过小,这样 会造成模型在计算实体关系时信息的丢失。
[0166]
一般的推荐模型需要比较长的特征维度才能对数据进行优质的建模,但是 当特征维度过大时反而会造成计算困难和时间成本高的问题。kgcn-cf通过 加入attention机制(公式3)后成功地解决了该问题。从图5中可以看出,在 book-crossing数据集下和last.fm数据集下,特征维度的增加对模型的结果没 有太大的影响。
[0167]
图3到图5中的结果显示,在一定程度上,邻居采样个数、接收野深度和 特征维度对于kgcn-cf的影响不是特别大。由此可以说明,kgcn-cf既可 以捕获项之间和用户之间的相关性,也可以在一定程度上解决稀疏性和冷启动 的问题,在未调参的情况下也能保持优秀的预测能力。
[0168]
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中 披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何 新的组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1