一种基于样本重加权的遥感图像多类目标检测方法与流程
[0001]
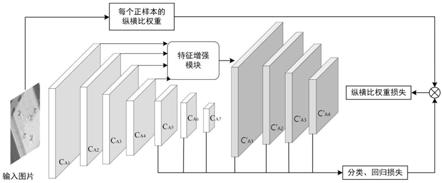
本发明属遥感图像处理技术领域,具体涉及一种基于样本重加权的遥感图像多类目标检测方法,可以用于提升遥感图像数据集中纵横比差异较大的目标类别的检测效果。
背景技术:
[0002]
遥感图像目标检测,是遥感大数据信息应用领域中的一项关键技术,高分辨率遥感图像数据和地理信息系统紧密结合,在未来的城市道路规划、工程项目评估以及可再生资源的监测评估等方面将有广阔的发展前景。随着大数据时代的到来以及计算机硬件性能的大幅提高,基于深度学习技术的目标检测算法突破了以往基于手工特征的目标检测技术瓶颈,成为现阶段光学图像目标检测任务的主流方法,并且受到了领域内学者和专家们的广泛关注。
[0003]
基于深度学习的主流目标检测方法按照anchor(锚框)的产生方式主要分为两大类,一类是以anchor-based为核心的通用目标检测算法,最具有代表性的工作是由kaiming he等人在《conference and workshop on neural information processing systems2015》上发表的“faster r-cnn:towards real-time object detection with region proposal networks”,该方法首先根据任务需求在原始图片上生成一系列密集排列的anchor,这些anchor的尺寸、长宽比和数量都是超参数;接着训练区域建议网络(region proposal network,rpn)来确定anchor内目标是前景或是背景,同时对原始anchor坐标进行初步的回归;最后进行多分类和精细回归任务,该类方法的优点是检测精度比较高,缺点是anchor的设定往往依赖于数据集中目标尺度的分布,这种方法无法自适应的拟合待训练数据集的尺度分布。另一类是以anchor-free为核心的通用目标检测算法,比较典型的方法是由ross girshick等人在《ieee conference on computer vision and pattern recognition 2016》上发表的“you only look once:unified,real-time object detection”,该检测模型将输入图像分成s
×
s个网格单元,如果一个目标样本的中心点在某个网格中,则由该网格负责检测这个目标样本,每个网格单元预测b个边界框和每个边界框的confidence(置信度),其中b是根据任务需求设定的超参数,confidence反映了网络模型对该边界框是否含有目标样本的信心,以及边界框位置预测的准确程度,这类方法的优点是运行速度快,可以用于实时系统,缺点是检测精度低,回归范围变化大。
[0004]
然而,基于深度学习技术的光学遥感图像目标检测算法与自然场景图像下的目标检测任务之间仍存在一定程度上的差异,光学遥感图像成像具有作用距离远、覆盖范围广的特点,因此遥感图像数据集中的目标样本会存在一些极端情况,对于那些可用像素信息少的小目标,在通过卷积神经网络不断地下采样之后,其位置信息丢失严重;部分目标类别的纵横比大,使得网络回归变化范围不可控;有些类别的目标在外观上具有高度的相似性,容易出现误检的情况,这些都是光学遥感图像目标检测任务中亟待解决的难点问题。
技术实现要素:
[0005]
针对基于深度学习技术的光学遥感图像目标检测任务中显著性特征提取和目标样本纵横比差异大的问题,本发明提出了一种基于样本重加权的遥感图像多类目标检测方法。首先,进行图像数据预处理操作,对原始图像数据进行数据增广处理,再对处理后的图像进行尺度缩放;然后,构建目标检测网络,包括特征提取模块、特征增强模块和检测头部模块,为了实现特征的显著性表达,针对部分特征层级进行特征增强操作;接着,进行网络端到端的训练过程,针对纵横比差异大的目标样本,采用样本重加权的策略来引导训练网络更多的对这类目标样本进行关注,以此来优化训练模型;最后,实现目标检测过程,将待检测遥感图像输入到训练好的目标检测网络中,得到每个先验框的类别预测值和其坐标偏移量,再使用非极大值抑制(non maximum suppression,nms)来过滤掉针对同一目标的重叠率较高的检测结果。
[0006]
一种基于样本重加权的遥感图像多类目标检测方法,其特征在于步骤如下:
[0007]
步骤1,图像数据预处理:首先,对原始遥感图像数据集中的图像进行数据增广处理,然后,对处理后的图像进行尺度缩放,使所有输入图像具有相同的尺寸;
[0008]
步骤2,构建目标检测网络,包括特征提取模块、特征增强模块和检测头部模块,其中,特征提取模块采用修改后的vgg16网络,即将vgg16的全连接层fc6替换为卷积核为3
×
3、卷积步长为1、卷积增补为6、空洞卷积率为6的卷积层,将全连接层fc7替换为卷积核为1
×
1、卷积步长为1的卷积层,输入图像经过特征提取模块得到长宽尺寸依次递减的多尺度特征图{c
a1
,c
a2
,c
a3
,c
a4
,c
a5
,c
a6
,c
a7
};特征增强模块对{c
a1
,c
a2
,c
a3
,c
a4
}这4组特征图进行处理,针对特征图{c
a1
}分别采用3
×
3和5
×
5的卷积核进行卷积操作得到{c
a13
,c
a15
},并将原特征图{c
a1
}与卷积后的特征图{c
a13
,c
a15
}的对应元素相加,得到融合后的特征图{c'
a1
},针对特征图{c
a2
}采用与上述相同的操作得到融合后的特征图{c'
a2
};同时,针对特征图{c
a3
}分别采用1
×
1和3
×
3的卷积核进行卷积操作得到{c
a31
,c
a33
},并将原特征图{c
a3
}与卷积后的特征图{c
a31
,c
a33
}的对应元素相加,得到融合后的特征图{c'
a3
},针对特征图{c
a4
}采用与上述相同的操作得到融合后的特征图{c'
a4
};经过特征增强模块获得新的特征图组{c'
a1
,c'
a2
,c'
a3
,c'
a4
},最终多尺度特征图表示为{c'
a1
,c'
a2
,c'
a3
,c'
a4
,c
a5
,c
a6
,c
a7
},它们的长宽尺度依次递减;
[0009]
检测头部模块包括分类分支和回归分支,分类分支为卷积核为3x3、卷积步长为1、卷积增补为1的网络,将多尺度特征图输入到分类分支,输出为该特征图中每个先验框的类别预测值;回归分支为卷积核为3x3、卷积步长为1、卷积增补为1的网络,将多尺度特征图输入到回归分支,输出为该特征图中每个先验框的坐标偏移量;
[0010]
针对特征图上每个像素点,添加不同尺度和长宽比的先验框,具体如下:
[0011]
对于特征图c'
a1
,其先验框尺度设置为input_size
×
4/100,input_size表示输入图像的尺寸;对于其他特征图,其先验框尺度按以下公式计算得到:
[0012][0013]
其中,m指除c'
a1
外特征图的个数,这里m=6,s
k
表示第k个特征图中的先验框的尺度,k=2、3、4、5、6、7依次表示特征图c'
a2
、c'
a3
、c'
a4
、c
a5
、c
a6
、c
a7
,s
min
表示比例的最小值,本发明中为s
min
=0.1,s
max
表示比例的最大值,本发明中为s
max
=0.9;
[0014]
针对特征图{c'
a1
,c'
a2
,c
a7
}的每个像素点,分别设置4个先验框,其中3个框的长宽比依次设定为1:1、2:1、1:2,另外,在每一组特征图上设置一组尺度信息为且长宽比为1:1的先验框,k=1、2、7,其中,s8=input_szie
×
106/100;针对特征图{c'
a3
,c'
a4
,c
a5
,c
a6
}的每个像素点,分别设置6个先验框,其中5个框的长宽比依次设定为1:1、2:1、1:2、1:3、3:1,另外,在每一组特征图上额外设置一组尺度信息为且长宽比为1:1的先验框,k=3、4、5、6;
[0015]
将所有先验框按照像素点位置映射到输入图像上;
[0016]
步骤3,对网络进行端到端的训练:将步骤1预处理后的图片输入到步骤2构建的目标检测网络进行训练,当达到设定的训练总次数时,停止训练,得到训练好的目标检测网络;其中,网络训练参数分别设定为:训练总次数设置为24个epoch,初始学习率为2.5e-4
,一个批次处理的图片数为8,学习率在epoch为16-22时开始下降,下降速率为0.1,到第23个epoch时,学习率降低为2.5e-6
;网络的损失函数设定为:
[0017][0018]
l
cls
=f.cross_entropy(cls
score
,labels)*scale_weight
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0019]
l
reg
=smooth_l1_loss(bbox
pred
,bbox
targets
)*scale_weight
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0020]
其中,l
total
表示总的网络损失,l
cls
表示分类损失,l
reg
表示回归损失,n
cls
表示参与分类损失计算的样本总数,n
reg
表示参与回归损失计算的样本总数,p
i*
表示先验框的归属,根据先验框与ground truth框进行匹配的原则确定,若先验框被匹配为正样本,则若先验框被匹配为负样本,则f.cross_entropy(
·
)表示交叉熵损失,cls
score
表示分类分支针对先验框的类别预测值,labels表示先验框与ground truth框匹配的标签真值信息,其取值范围为[1,...,k],k表示类别总数,labels=0表示为负样本;smooth_l1_loss(
·
)用于计算回归损失,bbox
pred
表示回归分支对先验框预测的坐标偏移量,bbox
targets
表示先验框的坐标偏移真值,scale_weight表示匹配为正样本的先验框所属真值信息的纵横比经过归一化之后的结果;
[0021]
所述的交叉熵损失f.cross_entropy(
·
)的计算表达式如下:
[0022]
f.cross_entropy=-[labels*log(cls
score
)+(1-labels)*log(1-cls
score
)]
ꢀꢀꢀꢀꢀ
(5)
[0023]
在进行上述计算时,labels的信息由[0,k]转换为一个one-hot向量;
[0024]
所述的回归损失函数smooth_l1_loss(
·
)的计算表达式如下:
[0025][0026]
所述的scale_weight的计算公式如下:
[0027]
scale_weight=exp
(-scale
′
)
+1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0028]
其中,scale
′
表示匹配为正样本的先验框的纵横比系数,按照以下公式计算:
[0029][0030]
其中,scale表示匹配为正样本的先验框的宽度与高度之比;
[0031]
步骤4,目标检测:将待检测遥感图像输入到步骤3训练好的目标检测网络中,得到每个先验框的类别预测值和其坐标偏移量,然后利用归一化指数函数softmax将类别预测值转换为最终的类别概率得分,具体计算公式如下:
[0032][0033]
其中,σ(z)
j
代表先验框内目标被预测为类别j的概率得分,其范围为(0,1);j代表类别所对应的序号,j=0,1,
…
,k,j=0表示为背景;z
j
和z
k
代表目标检测网络输出的先验框的类别预测值;
[0034]
概率得分最大值所对应的类别即为该先验框最终的分类结果;
[0035]
按照下式计算先验框经过坐标偏移之后得到的检测框位置信息:
[0036][0037]
其中,{b
lx
,b
ly
,b
rx
,b
ry
}表示检测框的位置信息,b
lx
表示检测框左上角x方向的坐标,b
ly
表示检测框左上角y方向的坐标,b
rx
表示检测框右下角x方向的坐标,b
ry
表示检测框右下角y方向的坐标;{t
x
,t
y
,t
w
,t
h
}表示回归分支网络预测得到的坐标偏移量,t
x
表示在x方向上的偏移量,t
y
表示在y方向上的偏移量,t
w
表示宽度尺度因子,t
h
表示高度尺度因子;{p
x
,p
y
,p
w
,p
h
}表示先验框的坐标信息,p
x
表示先验框左上角x方向的坐标,p
y
表示先验框左上角y方向的坐标,p
w
表示先验框的宽度,p
h
表示先验框的高度;
[0038]
最后,按以下过程进行目标检测:首先,删除属于背景类的检测框;然后,删除概率得分小于0.02的检测框,如果此时剩余检测框个数大于200,则仅保留概率得分最高的前200个检测框;最后,利用非极大值抑制来过滤针对同一目标的重叠率较高的检测框,剩余检测框即为最终的目标检测结果,具体为:以概率得分最高的检测框为基准框,分别计算其他检测框与基准框的重叠率iou,并将重叠率iou大于0.45的检测框的得分置为0;然后以概率得分次高的检测框为基准框,重复上述操作,直至遍历所有检测框完成上述操作后,剩余得分大于零的检测框,即为最终的目标检测结果。
[0039]
本发明的有益效果是:由于设计了新的目标检测网络,使用训练好的网络模型可以自动地从光学遥感图像中对目标进行定位和分类,具有较高的检测精度和较快的推理速度;由于目标检测网络中包括特征增强模块,该模块可以实现特征的显著性表达,使得检测精度在数据集的不同类别上有提升;由于在网络端到端的训练过程中,采用样本重加权策略来引导训练网络更加关注纵横比差异较大的目标样本,以此来优化训练模型,使得纵横比差异较大目标样本类别的检测精度得到显著提升。
附图说明
[0040]
图1本发明方法的流程框图;
[0041]
图2本发明实施例的训练图像;
[0042]
图3本发明目标检测网络的特征增强模块示意图;
[0043]
图4本发明的样本重加权示意图;
[0044]
图5采用本发明方法进行目标检测的结果图像。
具体实施方式
[0045]
下面结合附图和实施例对本发明进一步说明,本发明包括但不仅限于下述实施例。
[0046]
如图1所示,本发明提供了一种基于样本重加权的遥感图像多类目标检测方法,构建了新的目标检测网络。为更好地说明本发明,本实施例在硬件环境:intel(r)core(tm)i3-8100 cpu计算机、8.0gb内存,显卡型号:titan x(pascal),可使用内存为12gb,软件环境:pycharm2016和ubuntu 16.04.5lts下进行实验。实验使用公开光学遥感数据库dior,该数据集中有23463幅图像,总共为20个类别标注了192472个水平框实例,每幅图像的像素为800
×
800。为了验证本发明方法的合理性以及有效性,从数据集中选择11725幅图像作为训练集,选择其余的11738幅图像作为测试集,本发明的部分训练图像如图2所示。
[0047]
本发明的具体实施过程如下:
[0048]
1、数据预处理:使用数据增广方法增加待训练样本的多样性,再使用重缩放实现输入图片尺度的合理性。其中,数据增广方法采用文献“liu wei,anguelov dragomir,erhan dumitru,szegedy christian,reed scott,fucheng yang,berg alexander c.ssd:single shot multibox detector.eccv,2016”中的方法,具体包括以下过程:
[0049]
(1)图像度量失真:对原始图片进行色彩亮度、对比度、饱和度等方面的改变,这些改变针对图片中每个像素点进行。首先,给定亮度值δbrightness,其初始值为32,δ=random.uniform(-δbrightness,δbrightness)表示为一个随机亮度值,在原始图片每一个像素值处加δ;其次,给定色彩对比度上下限contrast
upper
、contrast
lower
,本实施中依次设定为1.5、0.5,α=random.uniform(contrast
lower
,contrast
upper
)表示为一个随机色彩对比度值,在原始图片每一个像素值处乘α;接着把图片的颜色空间从bgr转换到hsv,给定色彩饱和度的上下限saturation
upper
、saturation
lower
,本实施中依次设定为1.5、0.5,针对图片的s空间,利用β=random.uniform(saturation
lower
,saturation
upper
)生成一个随机色彩饱和度,在该图片空间的每一个像素点处乘β;再给定色度值δhue,其初始值为18,针对图片的h空间,利用δh=random.uniform(-δhue,δhue)产生一个随机色度值,在该图片空间的每一个像素点处加δh;最后,再把图片的颜色空间从hsv转换到bgr,同时可以打乱图片的通道信息,得到图片新的表征;
[0050]
(2)随机裁剪:设置5组最小的覆盖率,分别为0.1、0.3、0.5、0.7、0.9,最小的随机裁剪比例表示为:γ=0.3,其中覆盖率是指新生成的图像块(patch)中的目标框与原始图片中ground truth框之间的iou(intersection over union),随机裁剪的比例是根据原始输入图片的宽高信息来定义的;
[0051]
(3)图片扩张:图片的尺度扩张首先定义了扩张比率的上下限ratio
max
、ratio
min
,
本实施中依次设定为4、1,利用ratio=random.uniform(ratio
min
,ratio
max
)得到一个随机的扩张比率,用该ratio对原始图片进行尺度方面的扩张,使用待训练数据集中的rgb均值来填充扩张过后的图片空间,根据ratio得到新的坐标index,在新扩张图片的index处作为原始图片的覆盖点,其余部分的像素值仍然保持rgb均值;
[0052]
图片尺度的重新缩放:训练网络的输入图片尺寸要求是512
×
512,因此采用pil(python imaging library)库中的image.resize(w,h)函数对原始图片进行尺度缩小操作,使得所有输入到卷积神经网络里的图片具有相同的尺寸,均为512
×
512。
[0053]
2、构建目标检测网络:包括特征提取模块、特征增强模块和检测头部模块。
[0054]
其中,特征提取模块采用修改后的vgg16网络,即将vgg16的全连接层fc6替换为卷积核为3
×
3、卷积步长为1、卷积增补为6、空洞卷积率为6的卷积层,将全连接层fc7替换为卷积核为1
×
1、卷积步长为1的卷积层,输入图像经过特征提取模块得到长宽尺度依次递减的多尺度的特征图{c
a1
,c
a2
,c
a3
,c
a4
,c
a5
,c
a6
,c
a7
},其长宽尺度信息表示为{64
×
64,32
×
32,16
×
16,8
×
8,4
×
4,2
×
2,1
×
1},该组特征图通道数表示为{512,1024,512,256,256,256,256}。
[0055]
由特征提取模块得到的特征图的长宽尺度依次递减,特征增强模块对{c
a1
,c
a2
,c
a3
,c
a4
}这4组特征图进行处理,其网络结构设计如图3所示。针对特征图{c
a1
}分别采用3
×
3和5
×
5的卷积核进行卷积操作得到{c
a13
,c
a15
},并将原特征图{c
a1
}与卷积后的特征图{c
a13
,c
a15
}的对应元素相加,得到融合后的特征图{c'
a1
},针对特征图{c
a2
},采用与上述相同的操作得到融合后的特征图{c'
a2
};同时,针对特征图{c
a3
}分别采用1
×
1和3
×
3的卷积核进行卷积操作得到{c
a31
,c
a33
},并将原特征图{c
a3
}与卷积后的特征图{c
a31
,c
a33
}的对应元素相加,得到融合后的特征图{c'
a3
},针对特征图{c
a4
},采用与上述相同的操作得到融合后的特征图{c'
a4
};经过特征增强模块获得了新的特征图组{c'
a1
,c'
a2
,c'
a3
,c'
a4
},最终多尺度特征图表示为{c'
a1
,c'
a2
,c'
a3
,c'
a4
,c
a5
,c
a6
,c
a7
}。
[0056]
将得到的多尺度特征图{c'
a1
,c'
a2
,c'
a3
,c'
a4
,c
a5
,c
a6
,c
a7
}送入检测头部模块,检测头部模块包括分类分支和回归分支。
[0057]
在特征图{c'
a1
,c'
a2
,c
a7
}的每个像素点上分别设置4个先验框,在特征图{c'
a3
,c'
a4
,c
a5
,c
a6
}的每个像素点上分别设置6个先验框。先验框的尺度设定遵守一个线性递增规则,随着特征图长宽尺度的减小,先验框尺度按照以下公式线性增加。对于第一个特征图{c'
a1
},其先验框的实际尺度表示为input_size
×
4/100,input_size表示输入图片的尺寸,本实施例中为512。其他6个特征图中先验框的尺度按以下公式进行计算:
[0058][0059]
其中,m指除c'
a1
外特征图的个数,这里m=6,s
k
表示第k个特征图中的先验框的实际尺度,k=2、3、4、5、6、7依次表示特征图c'
a2
、c'
a3
、c'
a4
、c
a5
、c
a6
、c
a7
,s
min
=0.1表示比例的最小值,s
max
=0.9表示比例的最大值。按照上述公式计算先验框的尺度,本实施例中多尺度特征图{c'
a2
,c'
a3
,c'
a4
,c
a5
,c
a6
,c
a7
}上的先验框实际尺度依次为:51、133、215、296、378、460,加上{c'
a1
}的先验框实际尺度信息,最终各个特征图的先验框实际尺度s
k
,k∈[1,7]依次为:20、51、133、215、296、378、460。针对特征图{c'
a1
,c'
a2
,c
a7
}上的每个像素点,分别设置4个先验框,将其映射到步骤1处理过的图片上,其中3个先验框遵循以下设计规则,在各个
特征图上设置先验框的尺度信息依表示为s
k
,k=1,2,7,针对每一个尺度信息,其长宽比依次设定为1:1、2:1、1:2,另外,在每一组特征图上设置一组尺度信息为k=1,2,7且长宽比为1:1的先验框,其中s8=input_szie
×
106/100,本实施例中在这3组特征图上设置的第4个先验框的尺度信息分别为32、82、499;针对特征图{c'
a3
,c'
a4
,c
a5
,c
a6
}上的每个像素点,分别设置6个先验框,将其映射到步骤1处理过的图片上,其中5个先验框遵循以下设计规则,各个特征图上设置先验框的尺度信息表示为s
k
,k=3,4,5,6,针对每一个尺度信息,其长宽比依次设定为1:1、2:1、1:2、1:3、3:1,另外,在每一组特征图上设置一组尺度信息为k=3,4,5,6且长宽比为1:1的先验框,本实施例中在这4组特征图上设置的第6个先验框的的尺度信息依次为169、252、334、416。
[0060]
分类分支是卷积核为3x3、卷积步长为1、卷积增补为1的网络,将多尺度特征图输入到分类分支,每一组都分别经过分类分支网络,彼此之间相互独立,输出为该特征图中每个先验框的类别预测值。回归分支是卷积核为3x3、卷积步长为1、卷积增补为1的网络,将多尺度特征图输入到回归分支,每一组都分别经过回归分支网络,彼此之间相互独立,输出为该特征图中每个先验框的坐标偏移量{t
x
,t
y
,t
w
,t
h
},t
x
表示x方向的偏移量,t
y
表示y方向的偏移量,t
w
表示宽度尺度因子,t
h
表示高度尺度因子。分类分支和回归分支同时进行预测,即图像中的一个先验框通过检测头部的卷积运算,最终会得到25个预测值,其中21个预测值(训练数据集中目标类别数20,加入背景类,共21个类别)通过分类分支获得,4个预测值(坐标偏移量)通过回归分支获得。
[0061]
设先验框的坐标信息为{p
x
,p
y
,p
w
,p
h
},其中,p
x
表示先验框左上角x方向的坐标,p
y
表示先验框左上角y方向的坐标,p
w
表示先验框的宽度信息,p
h
表示先验框的高度信息;与该先验框匹配的ground truth框的坐标信息表示为{g
x
,g
y
,g
w
,g
h
},其中g
x
表示ground truth框左上角x方向的坐标,g
y
表示ground truth框左上角y方向的坐标,g
w
表示ground truth框得宽度信息,g
h
表示ground truth框的高度信息。先验框与ground truth框进行匹配的原则是:(1)对每一个ground truth框匹配一个与其iou最大的先验框;(2)对于每一个先验框,找到其与给定图片中所有ground truth框之间iou的最大值,将其与该ground truth框进行匹配。当同一个先验框与多个(大于等于2个)ground truth框的iou一样且最大时,每个先验框只能匹配一个类别标签,此时该先验框的类别信息会被后面出现的ground truth框的类别标签所覆盖。
[0062]
回归分支预测每个先验框的坐标偏移量{t
x
,t
y
,t
w
,t
h
},其坐标偏移真值表示为:
[0063][0064]
其中,表示x方向的坐标偏移真值,表示y方向的坐标偏移真值,表示宽度尺
度因子,表示高度尺度因子。
[0065]
3、对网络进行端到端的训练:将步骤1预处理后的图像输入到所构建的目标检测网络进行训练,当达到设定的训练总次数时,停止训练,得到训练好的目标检测网络;其中,网络训练参数分别设定为:训练总次数设置为24个epoch,初始学习率为2.5e-4
,一个批次处理的图片数为8,学习率在epoch为16-22时开始下降,下降速率为0.1,到第23个epoch时,学习率降低为2.5e-6
;网络的损失函数设定为:
[0066][0067]
l
cls
=f.cross_entropy(cls
score
,labels)*scale_weight
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0068]
l
reg
=smooth_l1_loss(bbox
pred
,bbox
targets
)*scale_weight
ꢀꢀꢀꢀꢀꢀꢀ
(15)
[0069]
其中,l
total
表示总的网络损失,l
cls
表示分类损失,l
reg
表示回归损失,n
cls
表示参与分类损失计算的样本总数,n
reg
表示参与回归损失计算的样本总数,表示先验框的归属,根据先验框与ground truth框进行匹配的原则确定,若iou>=0.5时,先验框被匹配为正样本,则iou<0.5时,先验框被匹配为负样本,
[0070]
f.cross_entropy(
·
)表示交叉熵损失,计算表达式如下:
[0071]
f.cross_entropy=-[labels*log(cls
score
)+(1-labels)*log(1-cls
score
)]
ꢀꢀꢀꢀ
(16)
[0072]
其中,cls
score
表示分类分支针对先验框的类别预测值,labels表示先验框与ground truth框匹配的标签真值信息,其取值范围为[1,...,k],k表示类别总数,本实施中为20,labels=0表示为负样本。在进行上述计算时,labels的信息由[0,k]转换为一个one-hot向量。
[0073]
smooth_l1_loss(
·
)用于计算回归损失,计算表达式如下:
[0074][0075]
其中,bbox
pred
表示回归分支对先验框预测得到的坐标偏移量,bbox
targets
表示先验框的坐标偏移真值,scale_weight表示匹配为正样本的先验框所属真值信息的纵横比经过归一化之后的结果,计算公式如下:
[0076]
scale_weight=exp
(-scale
′
)
+1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0077]
其中,scale
′
表示匹配为正样本的先验框的纵横比系数,按照以下公式计算:
[0078][0079]
其中,scale表示匹配为正样本的先验框的宽度与高度之比。通过上述归一化方法对每个正样本的scale_weight进行限制,损失函数的变化在一个可控的范围内,使模型最终实现收敛。在计算样本的分类损失和回归损失时,加入该样本所匹配到的groundtruth框的纵横比信息,通过这种样本重加权的方法,让网络侧重于训练纵横比差异较大的目标类别,用于提升这类目标的检测效果。样本重加权模块如图4所示。
[0080]
4、目标检测:将待检测遥感图像输入到以上训练好的目标检测网络中,得到每个
先验框的类别预测值和其坐标偏移量,然后,利用归一化指数函数softmax将类别预测值转换为最终的类别概率得分,具体计算公式如下:
[0081][0082]
其中,σ(z)
j
代表先验框内目标被预测为类别j的概率得分,其范围为(0,1);j代表类别所对应的序号,j=0,1,
…
,20,j=0表示为背景;z
j
和z
k
代表目标检测网络输出的检测框的类别预测值;
[0083]
概率得分最大值所对应的类别即为该先验框最终的分类结果;
[0084]
按照下式计算先验框经过坐标偏移之后得到的检测框位置信息:
[0085][0086]
其中,{b
lx
,b
ly
,b
rx
,b
ry
}表示检测框的位置信息,b
lx
表示检测框左上角x方向的坐标,b
ly
表示检测框左上角y方向的坐标,b
rx
表示检测框右下角x方向的坐标,b
ry
表示检测框右下角y方向的坐标;
[0087]
最后,按以下过程进行目标检测:首先,删除属于背景类的检测框;然后,删除概率得分小于0.02的检测框,如果此时剩余检测框个数大于200,则仅保留概率得分最高的前200个检测框;最后,利用非极大值抑制来过滤针对同一目标的重叠率较高的检测框,剩余检测框即为最终的目标检测结果,具体为:以概率得分最高的检测框为基准框,分别计算其他检测框与基准框的重叠率iou,并将重叠率iou大于0.45的检测框的得分置为0;然后,以概率得分次高的检测框为基准框,重复上述操作,直至遍历所有检测框完成上述操作后,剩余得分大于零的检测框,即为最终的目标检测结果。采用本发明方法进行目标检测的部分结果图像如图5所示。
[0088]
选用map(mean average precision)对本发明方法的有效性进行评估,其定义如下:
[0089][0090]
其中,n代表待训练数据集中所包含的类别总数,本实例中n=20,i代表其中一种目标类别,ap
i
代表该类目标的平均精度值;同时,将本发明所得的检测结果与基于ssd512的目标检测算法进行了对比,对比结果如表1所示,map这一评价指标证明了本发明方法的有效性。
[0091]
表1
[0092]
方法map基于ssd512的目标检测算法68.7%本发明方法71.7%
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1