语音无法理解说法数据的分流处理方法、系统及存储介质与流程
[0001]
本发明属于语音交互技术领域,具体涉及一种语音无法理解说法数据的分流处理方法、系统及存储介质。
背景技术:
[0002]
当前语音交互产品已经广泛普及,用户意图理解的正确与否直接影语音执行结果及产品体验。由于汉语语法的高灵活性,句式的高复杂性以及各地方说话习惯不一等因素导致用户同一意图有多种不同说法,特别是非常规说法、地方说法不能正确识别理解的问题。行业针对不能理解的用户意图的普遍处理方法为:通过对这部分数据进行人工清洗,只将常用的无法理解的说法进行维护更新到语义引擎。这种处理方式需要大量人工对数据清洗,工作时间长,语义理解引擎更新慢,更新内容有限。
[0003]
因此,有必要开发一种新的语音无法理解说法数据的分流处理方法、系统及存储介质。
技术实现要素:
[0004]
本发明的目的是提供一种语音无法理解说法数据的分流处理方法、系统及存储介质,能减少人力投入,节省清洗数据时间,快速上线,以实现理解的能力提升。
[0005]
第一方面,本发明所述的一种语音无法理解说法数据的分流处理方法,包括以下步骤:第一步、建立数据库,将不能理解的用户说法收集并存储到数据库中;第二步、对不能理解的用户说法数据根据预设置信规则进行置信度标注,并给出置信度评估值;第三步、将置信度分为多个等级,根据置信度评估值及等级对不能理解的用户说法数据进行分流;第四步、对每一等级分流的数据设置不同的处理流程,对分流后的数据按照对应的处理流程进行处理,并将分流处理的数据更新优化到语义引擎中。
[0006]
进一步,所述第二步中:所述预设置信规则为:按照有动作有对象、有对象无动作、无对象有动作和无对象无动作进行分类。
[0007]
进一步,所述第三步中:将置信度分为四个等级,从高到低依次为自动级、引导级、澄清级和人工级;对不能理解的用户说法数据进行识别判断,若为有动作有对象,则分流至自动级,若为有对象无动作,则分流至引导级,若为无对象有动作,则分流至澄清级,若为无对象无动作,则分流至人工级。
[0008]
进一步,所述第四步中:对于自动级的数据,自动维护到语义引擎中;
对于引导级的数据,匹配出正确意图并下发至用户进行二次确认,确认后自动维护到语义引擎中;对于澄清级的数据,设定二次对话,收集用户真正意图,并人工维护到语义引擎中;对于人工级的数据,通过人工清洗数据后维护到语义引擎中或不做处理。
[0009]
第二方面,本发明所述的一种语音无法理解说法数据的分流处理系统,包括存储器和控制器,所述存储器内存储有计算机可读程序,所述计算机可读程序被控制器调用时,能执行如本发明所述语音无法理解说法数据的分流处理方法的步骤。
[0010]
第三方面, 本发明所述的一种存储介质,其内存储有计算机可读程序,所述计算机可读程序被调用时,能执行如本发明所述语音无法理解说法数据的分流处理方法的步骤。
[0011]
本发明具有以下优点:将无法理解的说法数据进行多级分流并对每一层级的数据进行差异化方案处理,极大地提升了数据清洗效率,提高了语义更新速度,丰富了语义库,缩减了人力投入。
附图说明
[0012]
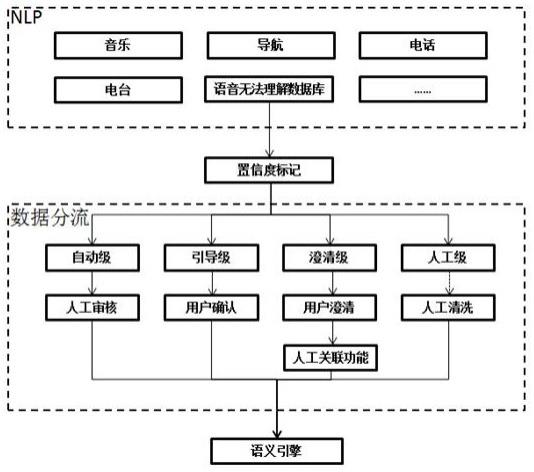
图1是本实施例的流程图。
具体实施方式
[0013]
下面结合附图对本发明作进一步说明。
[0014]
如图1所示,一种语音无法理解说法数据的分流处理方法,包括以下步骤:第一步、建立数据库,用于收集、存储当前语音系统不能理解的用户说法,将不能理解的用户说法收集并存储到数据库中。
[0015]
第二步、对不能理解的用户说法数据根据预设置信规则进行置信度标注,并给出置信度评估值;本实施例中,所述预设置信规则为:按照有动作有对象、有对象无动作、无对象有动作和无对象无动作进行分类。
[0016]
第三步、将置信度分为多个等级,根据置信度评估值及等级对不能理解的用户说法数据进行分流。本实施例中,将置信度分为四个等级,从高到低依次为自动级(90%及以上)、引导级(70%-89%)、澄清级(50%-69%)和人工级(价值较低)。其中,自动级的数据为高置信度数据;引导级数据为较高置信度数据,澄清级数据为置信度中等数据,人工级数据为置信度较低数据。将不能理解的用户说法数据按百分比进行意图置信度标记,然后将不同置信度的数据进行分流,具体为:对不能理解的用户说法数据进行识别判断,若为有动作有对象,则分流至自动级,若为有对象无动作,则分流至引导级,若为无对象有动作,则分流至澄清级,若为无对象无动作,则分流至人工级。
[0017]
第四步、对每一等级分流的数据设置不同的处理流程,对分流后的数据按照对应的处理流程进行处理,将分流处理的数据更新优化到语义引擎中。
[0018]
本实施例中,对于自动级的数据,自动维护到语义引擎中。对于引导级的数据,匹配出正确意图并下发至用户进行二次确认,确认后自动维护到语义引擎中;对于澄清级的数据,设定二次对话,收集用户真正意图,并人工维护到语义引擎中;对于人工级的数据,对于需要的数据通过人工清洗数据后维护到语义引擎中,对于人工级的数据亦可看作是“无
价值”的数据,可以不做处理。
[0019]
当用户下一次用相同说法时,其语义就能够被识别并执行。
[0020]
本实施例中,一种语音无法理解说法数据的分流处理系统,包括存储器和控制器,所述存储器内存储有计算机可读程序,所述计算机可读程序被控制器调用时,能执行如本实施例中所述语音无法理解说法数据的分流处理方法的步骤。
[0021]
本实施例中,一种车辆,采用如本实施例中所述的语音无法理解说法数据的分流处理系统。
[0022]
本实施例中,一种存储介质,其内存储有计算机可读程序,所述计算机可读程序被调用时,能执行如本实施例中所述语音无法理解说法数据的分流处理方法的步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1