一种基于并行化的类脑仿真编译的加速方法
1.本发明涉及神经网络仿真技术领域,具体涉及一种基于并行化的类脑仿真编译的加速方法。
背景技术:
2.在使用gpu进行仿真脉冲神经网络之前,需要将用户输入的神经网络拓扑结构数据编译成适合在gpu内并行仿真的数据结构。对于超大规模的神经网络,在cpu内串行地进行编译会消耗大量的时间,从而降低仿真框架的使用体验。中国专利cn110908667a公开了一种神经网络联合编译的方法、装置和电子设备,其中采用的是串行的方式进行编译,耗时长,使用体验差。
技术实现要素:
3.为了克服现有技术所存在的缺陷,本发明提供了一种基于并行化的类脑仿真编译的加速方法,通过并行算法加速仿真框架的速度,减少用户的等待时间。
4.为解决上述技术问题,本发明提供以下技术方案:
5.一种基于并行化的类脑仿真编译的加速方法,包括以下步骤:
6.s1、构建神经网络时,创建若干个族群,每个族群包含上百万个神经元;
7.s2、按照神经元族群并行构建神经元数组;
8.s3、按照族群之间的连接并行构建突触数组以及神经元到突触数组的映射关系。
9.目前很多主流的类脑仿真框架在用户输入神经网络数据的时候都是让用户按照神经元族群的方式输入神经元数据,并让用户在神经元族群之间按照用户指定的某种方式建立突触连接,所谓族群指的是一组具有相同模型和相同属性的神经元节点,在构建神经网络时,创建若干个族群,每个族群包含上百万个神经元,而进一步的,在步骤s2中,由于所有的神经元都要统一放在一个大数组中,而用户提供的又是神经元族群数据,因此先将所有族群的节点数进行并行前缀求和构建族群
‑
数组映射表,确定总的神经元数以及各个族群在神经元大数组中第一个神经元的下标。
10.进一步的,为大数组的每个元素分配一个线程,然后并行地编译神经元数据。
11.进一步的,每个线程按照所对应的大数组下标以及族群
‑
数组映射表,找到所对应的族群,将族群中的神经元参数复制到当前的数组元素中,完成神经元数据的编译。
12.进一步的,线程通过二分查找的方式找到所对应的族群。
13.进一步的,在步骤s3中,先根据用户输入的连接数据确定每个族群中单个神经元的总输出突触数,然后按照前面的族群
‑
数组映射表并行地将每个神经元的输出突触数存放在一个数组中,然后对该数组进行前缀求和,从而得到神经元
‑
输出突触映射表,根据该表最后一个元素可确定总的突触数,从而确定突触数组的长度,另外在仿真时还可以通过该表快速找到对应的输出突触,最后为每一个神经元、每一个突触分配一个线程,并行地构建突触数组。在确定突触数组元素方面,可根据神经元
‑
输出突触映射表以及线程的编号。
14.进一步的,突触是在族群之间建立,建立的方式为:一对一模式或全连接模式或按照全连接的比例进行随机构建,在确定突触后神经元的下标时,根据突触构建方式来决定具体方式。
15.进一步的,对于一对一模式,突触后神经元下标=当前神经元下标
‑
所在族群的第一个神经元下标+突触后的族群的第一个神经元下标。
16.进一步的,对于全连接模式,突触后神经元下标=突触后的族群的第一个神经元下标+线程相对于当前神经元以及当前连接的下标。
17.进一步的,对于按比例构建突触,具体方法如下:
18.由于比例p是浮点数,在计算过程中不够稳定,为此设定一个整型a代表精确度,令p=取整(pa);
19.对于所在族群的下标为j的突触前神经元的输出突触的个数为
20.n=[(jmp%a)+mp]/a;
[0021]
对于j=0,1,
…
,n
‑
1逐个循环,则:
[0022]
跨度=[a
‑
(当前总位置mod a)
‑
1]/p
[0023]
当前局部位置=当前局部位置+跨度;
[0024]
按照当前局部位置对应的突触后神经元构建突触,则:
[0025]
当前总位置=当前总位置+跨度+1
[0026]
当前局部位置=当前局部位置+1。
[0027]
与现有技术相比,本发明具有以下有益效果:
[0028]
本发明的基于并行化的类脑仿真编译的加速方法主要内容就是按照神经元族群并行构建神经元数组,然后按照族群之间的连接并行构建突触数组以及神经元到突触数组的映射关系,现有技术采用的是串行的方式,本发明采用的是并行的方式,因此与现有技术相比,本发明的速度更快,效率更高,用户体验更好。
附图说明
[0029]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据附图获得其他的附图
[0030]
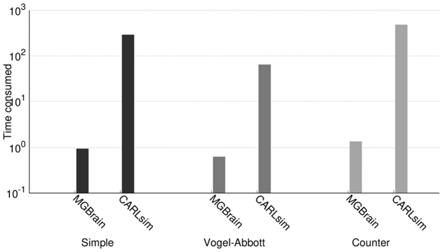
图1为本发明的基于并行化的类脑仿真编译的加速方法与现有技术的性能对比图。
具体实施方式
[0031]
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0032]
本发明实施例包括:
[0033]
实施例1:
[0034]
一种基于并行化的类脑仿真编译的加速方法,包括以下步骤:
[0035]
s1、构建神经网络时,创建若干个族群,每个族群包含上百万个神经元;
[0036]
s2、按照神经元族群并行构建神经元数组;
[0037]
s3、按照族群之间的连接并行构建突触数组以及神经元到突触数组的映射关系。
[0038]
目前很多主流的类脑仿真框架在用户输入神经网络数据的时候都是让用户按照神经元族群的方式输入神经元数据,并让用户在神经元族群之间按照用户指定的某种方式建立突触连接,所谓族群指的是一组具有相同模型和相同属性的神经元节点,在构建神经网络时,创建若干个族群,每个族群包含上百万个神经元,在步骤s2中,由于所有的神经元都要统一放在一个大数组中,而用户提供的又是神经元族群数据,因此先将所有族群的节点数进行并行前缀求和构建族群
‑
数组映射表,确定总的神经元数以及各个族群在神经元大数组中第一个神经元的下标最后,为大数组的每个元素分配一个线程,然后并行地编译神经元数据。
[0039]
其中,每个线程按照所对应的大数组下标以及族群
‑
数组映射表,通过二分查找的方式找到自己所对应的族群,将族群中的神经元参数复制到当前的数组元素中,完成神经元数据的编译。
[0040]
而在步骤s3中,先根据用户输入的连接数据确定每个族群中单个神经元的总输出突触数,然后按照前面的族群
‑
数组映射表并行地将每个神经元的输出突触数存放在一个数组中,然后对该数组进行前缀求和,从而得到神经元
‑
输出突触映射表,根据该表最后一个元素可确定总的突触数,从而确定突触数组的长度,另外在仿真时还可以通过该表快速找到对应的输出突触,最后为每一个神经元、每一个突触分配一个线程,并行地构建突触数组。在确定突触数组元素方面,可根据神经元
‑
输出突触映射表以及线程的编号。
[0041]
其中的突触是在族群之间建立,建立的方式为:一对一模式或全连接模式或按照全连接的比例进行随机构建,因此,在确定突触后神经元的下标时,需要根据突触构建方式来决定具体方式。
[0042]
其中,对于一对一模式,突触后神经元下标=当前神经元下标
‑
所在族群的第一个神经元下标+突触后的族群的第一个神经元下标。
[0043]
另外,对于全连接模式,突触后神经元下标=突触后的族群的第一个神经元下标+线程相对于当前神经元以及当前连接的下标。
[0044]
而对于按比例构建突触,具体方法如下:
[0045]
由于比例p是浮点数,在计算过程中不够稳定,为此设定一个整型a代表精确度,令p=取整(pa);
[0046]
对于所在族群的下标为j的突触前神经元的输出突触的个数为
[0047]
n=[(jmp%a)+mp]/a;
[0048]
对于j=0,1,
…
,n
‑
1逐个循环,则:
[0049]
跨度=[a
‑
(当前总位置mod a)
‑
1]/p
[0050]
当前局部位置=当前局部位置+跨度;
[0051]
按照当前局部位置对应的突触后神经元构建突触,则:
[0052]
当前总位置=当前总位置+跨度+1
[0053]
当前局部位置=当前局部位置+1。
[0054]
如图1所示,simple、vogel、counter都是测试所用的不同的脉冲神经网络,
mgbrain是使用本发明的仿真器,carlsim是用于对照的其他snn仿真器,该结果是测试不同网络在编译阶段所消耗的时间,可以看到使用并行编译的mgbrain与不使用该技术的carlsim相比有数量级上的差距。
[0055]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1