一种基于TuiGAN改进的脸谱图像风格迁移的方法
本发明属于计算机图形学处理技术领域,具体涉及一种基于tuigan改进的脸谱图像风格迁移的方法。
背景技术:
秦腔脸谱艺术风格强烈、纹饰鲜明,具有极高的研究价值,是探究秦地文化和精神内涵的极佳素材。由于其独特的艺术风格,使得创作绘制难度加大,创新发展也一直依赖于脸谱相关爱好者的耐心钻研,现存的秦腔脸谱图案稀缺,更使其发展进入瓶颈,为脸谱艺术传承和传播带来极大挑战。
目前,无监督的图像到图像转换任务(ui2i)对不成对的图像进行训练,将图像从源域映射到目标域,这通常需要收集大量的图像,比如cyclegan网络虽然已经改进到需要少量的数据集,100多张效果已经优异,但是其需要训练很长的时间,图像迁移效果才比较好,但是如果对于数据集只有两张图像的风格迁移问题,却无法实现。而现有技术中,tuigan可以在两个不成对的图像上训练,实现以粗到精的方式转换图像。但存在运行时间成本高,生成图像清晰度低的问题,并且在秦腔脸谱风格迁移中,可以发现眼睛也无法凸显,很多细节信息没有显示。
技术实现要素:
针对现有技术的缺点或不足,本发明的目的在于提供一种基于tuigan改进的脸谱图像风格迁移的方法,学习到图片中更精细的特征和减少运行的迭代次数,提高图像风格迁移效果,使所生成的脸谱更加精细。
为实现上述目的,本发明所采用的技术方案是:
一种基于tuigan改进的脸谱图像风格迁移的方法,包括以下步骤:
步骤1:搜集两张秦腔脸谱图像,设置尺寸为512x512mm;
步骤2:使用pytorch构建原始的tuigan网络结构,tuigan中的生成器
首先,使用φ将
其中,
然后,使用注意力模型ω生成一个平衡图像an,该平衡图像对图像区域之间的长期和多尺度依赖性进行建模,使用注意力模型ω将
其中,
最后,在
其中,x表示逐像素乘法;
类似地,第n个尺度的转换ib→iba的实现如下:
步骤3:在第n个尺度上,生成器生成一个注意图;
步骤4:对生成器的φ与ω添加两个卷积块,使其学习得到的特征更加明显;
步骤5:对判别器d添加两层卷积块nn.conv2d(32,32,kernel_size=(1,1),1),使用pytorch构建更改注意力机制并且生成器和判别器的网络结构φ与ψ两层卷积层后的tuigan后网络结构,设置迭代次数,其他参数与原始的tuigan网络结构;
步骤6:将步骤1的两张秦腔脸谱图像传入到该网络中,设置迭代次数,其他参数保持不变,进行训练得到迁移的图像。
进一步,所述步骤4中生成器的φ与都由原始的五个卷积块提升到了七个卷积块,φ的第一个卷积块是nn.conv2d(3,32,kernel_size=(1,1),1)和最后一个卷积块是nn.conv2d(32,3,kernel_size=(1,1),1),ω的第一个卷积块是nn.conv2d(9,32,kernel_size=(1,1),1)和最后一个卷积块是nn.conv2d(32,3,kernel_size=(1,1),1),其余卷积块全部是nn.conv2d(32,32,kernel_size=(1,1),1)。
进一步,所述步骤2和步骤6中设置迭代次数为100。
本发明基于tuigan改进的脸谱图像风格迁移的方法,首先对秦腔脸谱进行重新设置尺寸,然后对tuigan网络中生成器的注意力机制的网络顺序进行了调换;其次对生成器中的网络结构和判别器的网络结构加了两层卷积块,使其可以学习到更多精细的特征,实验发现,这样使脸谱纹理更加清晰;最后通过pytorch对网络进行构建,将处理好的秦腔脸谱图像传入到该网络中,得到了两张风格迁移化的脸谱图像,其解决了少量数据集的风格迁移问题,并且改进了tuigan生成图像细节不凸显的问题。
改进tuigan的网络结构和注意力机制,学习到图片中更精细的特征和减少运行的迭代次数,达到了在提高图像风格迁移效果的同时,增加运行速度,使所生成的脸谱更加精细。
附图说明
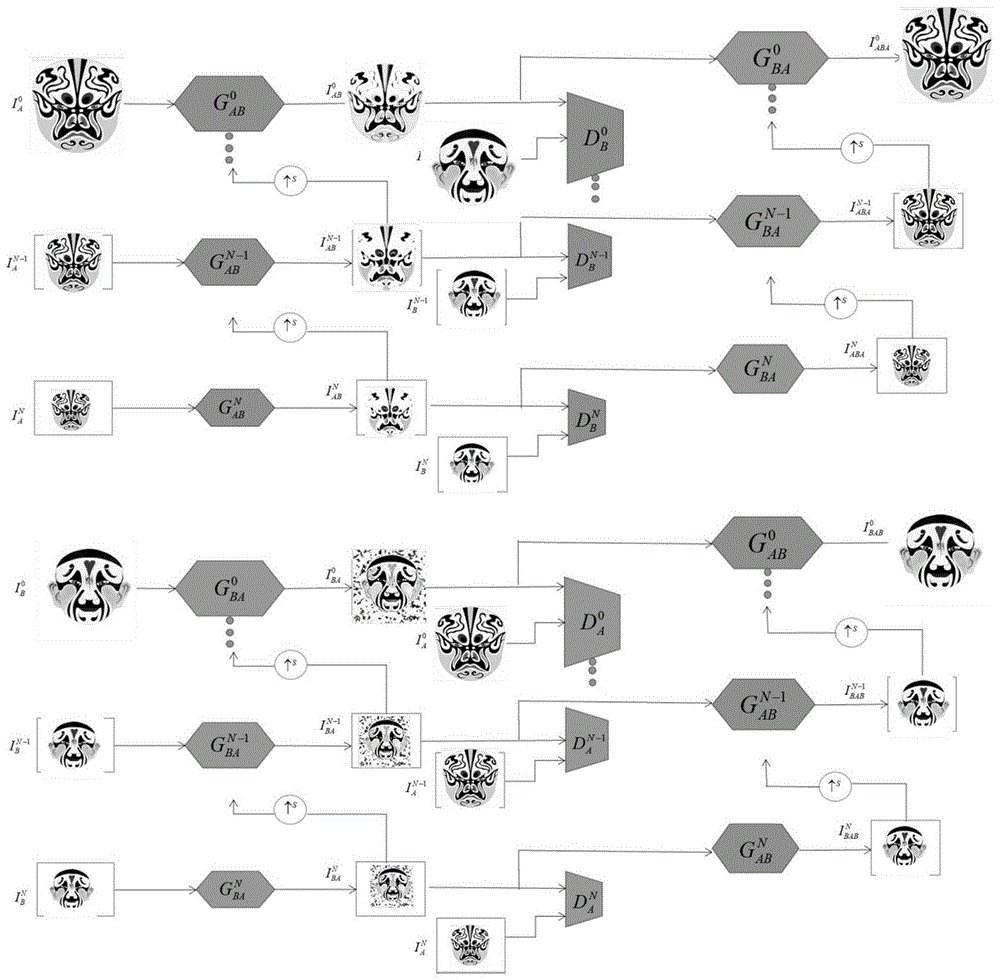
图1是本发明的网络结构图;
图2是本发明的生成器中的注意力机制;
图3(a)是本发明的生成器内部φ的网络结构图
图3(b)是本发明的生成器内部ω的网络结构图
图3(c)是本发明的判别器的网络结构
图4是本发明网络的两张输入图;
图5是通过tuigan网络进行脸谱迁移的结果图;
图6是对原始tuigan改变注意力机制进行脸谱迁移的结果图;
图7是对原始tuigan改变注意力机制并且生成器添加了两个卷积层之后的结果图;
图8是对原始tuigan改变注意力机制并且生成器和判别器同时添加了两个卷积层之后的结果图。
具体实施方式
如下面结合具体实施例对本发明作进一步详细描述,但不作为对本发明的限定。
如图1-图3所示,本发明提供一种基于tuigan改进的脸谱图像风格迁移的方法,具体包括以下步骤:
步骤1:首先在秦腔网站或者有关秦腔脸谱的网站上搜集数据集,然后更改图像尺寸为(512,512),如图4是搜集到的两张图像。
步骤2:使用pytorch构建原始的tuigan网络结构,设置迭代次数100次,其他参数保持不变。
原始tuigan中的生成器
第n个尺度的转换ia→iab的实现如下:
首先,使用φ将
其中,
然后,使用注意力模型ω生成一个平衡图像an,该平衡图像对图像区域之间的长期和多尺度依赖性进行建模。ω将
其中,
最后,在
其中,x表示逐像素乘法;
类似地,第n个尺度的转换ib→iba的实现如下:
这样,生成器将焦点集中在图像区域上,这些区域负责在当前比例尺上的合成细节,并在先前比例尺中保持先前学习的全局结构不变。先前的生成器已经在
将搜集得到的两张脸谱图像,输入到原始的tuigan网络中,进行训练100次,其他参数保持不变,开始训练,最后得到的两张迁移后的图像,如图5所示。
步骤3:在第n个尺度上,生成器生成一个注意图,以在脸谱上添加条纹细节,并产生更好的结果
为了验证本发明注意力机制的有效性,将两张脸谱图像,输入到更改注意力机制后的网络中,进行训练100次,得到的最后结果,如图6所示。可以发现眼睛和一些纹理特征已经显现出来,比图5效果更好。
在更改注意力机制之后,眼睛的问题得以解决,但是脸谱上其余的花纹却不是很明显,因此通过对生成器的φ与ω多添加了两个卷积块,使其学习得到的特征更加明显。
步骤4:使用pytorch构建更改注意力机制和生成器的网络结构φ与ψ两层卷积层后的tuigan网络结构,设置迭代次数100次,其他参数与tuigan的相同,开始训练。
生成器中φ与ω结构类似,φ与ω都由原始的五个卷积块提升到了七个卷积块,不同之处在于φ的第一个卷积块nn.conv2d(3,32,kernel_size=(1,1),1)和最后一个卷积块nn.conv2d(32,3,kernel_size=(1,1),1),ω的第一个卷积块nn.conv2d(9,32,kernel_size=(1,1),1)和最后一个卷积块nn.conv2d(32,3,kernel_size=(1,1),1),其余卷积块全部是nn.conv2d(32,32,kernel_size=(1,1),1),这样保证了生成图像尺度不变性,如图3(a)和图3(b)。
为了验证本发明增加注意力机制和生成器的网络结构φ与ψ两层卷积层后的有效性,将两张脸谱图像,输入到更改注意力机制和网络层数后的网络中,进行训练100次,生成的最后结构,如图7所示,可以发现将脸谱中的纹理上也添加了色彩特征,所以比图6效果更好。
步骤5:对于增加卷积块之后生成器细节明显凸显的问题,判别器d原始的五层卷积块却无法更好的对细节进行判断,因为本发明对判别器d也添加了两层卷积块nn.conv2d(32,32,kernel_size=(1,1),1),使其博弈效果更佳,如图3(c)。
使用pytorch构建更改注意力机制并且生成器和判别器的网络结构φ与ψ两层卷积层后的tuigan后网络结构,设置迭代次数100次,其他参数与tuigan的相同,开始训练。
为了验证本发明增加判别器网络结构φ与ψ两层卷积层的有效性,将两张脸谱图像,输入到更改注意力机制和网络层数后的网络中,进行训练100次,生成的最后结构,如图8所示,可以发现脸谱的每个区域都有了彼此特有的风格,所以比图7效果更好。
参照上述实施例对本发明进行了详细说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!