一种知识嵌入的领域识别方法、计算机设备及存储介质与流程
本发明涉及自然语言处理的领域识别技术领域,特别涉及一种知识嵌入的领域识别方法、计算机设备及存储介质。
背景技术:
领域识别目前使用的embedding方法,能够适应一般大量文本的领域识别,但在不同领域极相似说法的识别表现不够好,尤其当两种领域相似说法的训练数据差距较大时,数据较少领域的识别率下降明显。原因在于传统的embedding方法并不能很好的识别句子中的实体实质上是属于哪一领域。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供一种知识嵌入的领域识别方法、计算机设备及存储介质,可实现在多个领域极相似说法中,准确的识别目的领域。
为了达到上述的技术效果,本发明采取以下技术方案:
一种知识嵌入的领域识别方法,包括:利用分词词典对指令词语进行词性标注,将特殊名词的词性标注为目的领域词性,在提取词向量时判断指令词语的词性是否属于目的领域词性,如果是就对属于目的领域词性的指令词语进行词性提取转换,并将值传给分词结果的token.flag参数,在生成词向量时,将非空的token.flag与该指令词语原本的词向量进行合并后,再输入卷积神经网络进行计算。
进一步地,具体包括以下步骤:
步骤1.构造目的领域转换字典、一般词性检索列表及分词词典;
步骤2.获取指令语句并通过分词词典进行分词得到若干检索词语及其对应的词性;
步骤3.判断检索词语的词性是否在一般词性检索列表中,若是,则进入步骤4,否则,进入步骤5;
步骤4.将分词结果赋值给token.word参数,并将空字符赋值给token.flag参数;进入步骤6;
步骤5.将分词结果赋值给token.word参数,并将词性对应的中文字符赋值给token.flag参数;进入步骤6;
步骤6.生成词向量时,先判断token.flag参数是否有值,若是,则进入步骤7,否则,进入步骤9;
步骤7.判断检索词语的词性是否包含于目的领域转换字典中,若是,则进入步骤8,否则,进入步骤9;
步骤8.将检索词语的原始词向量和token.flag参数的词向量进行合并后输入卷积神经网络进行计算;
步骤9.将检索词语的原始词向量输入卷积神经网络进行计算。
进一步地,所述分词词典用于存储词语和词语出现的词频还有词性,且在分词词典中可进行特殊名词添加,并将其词性标注为想要其被识别成的领域。
进一步地,所述目的领域转换字典用于存放特殊名词的词性的中文转换词。
进一步地,所述一般词性检索列表用于存储词语的一般词性。
同时,本发明还公开了一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述知识嵌入的领域识别方法的步骤。
同时,本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至5中任一项所述知识嵌入的领域识别方法的步骤。
本发明与现有技术相比,具有以下的有益效果:
本发明的知识嵌入的领域识别方法、计算机设备及存储介质,使用分词词典的词性标注,将词语知识图谱归一化为词性,并在生成词向量时合并目的领域词向量和原本词向量,增强词语与对应词性之间的联系,最后供给卷积神经网络提取特征区分相似说法,分析相似说法时即使只有实体名有区别也能准确识别,在不损失其他领域识别准确率的同时大大提高了拥有大量相似说法的几个领域的区分效果。
附图说明
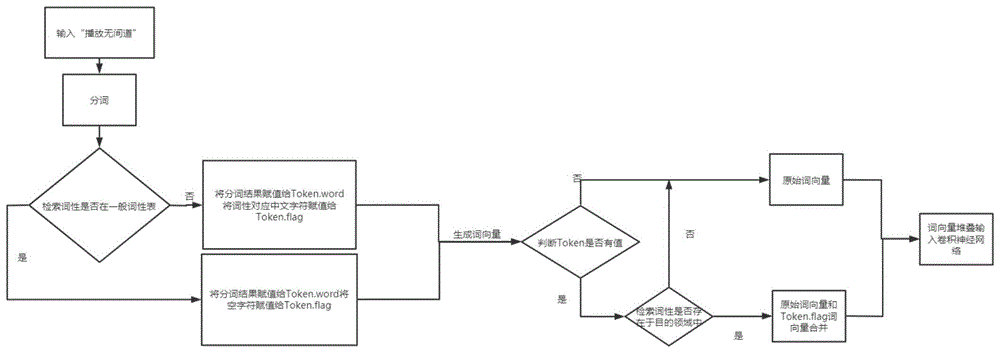
图1是本发明的知识嵌入的领域识别方法的流程示意图。
图2是本发明的一个实施例的一般词性表的示意图。
图3是本发明的一个实施例的一般词性检索列表的示意图。
图4是本发明的一个实施例的目的领域转换字典的示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
实施例一:
一种知识嵌入的领域识别方法,包括:利用分词词典对指令词语进行词性标注,将特殊名词的词性标注为目的领域词性,在提取词向量时判断指令词语的词性是否属于目的领域词性,如果是就对属于目的领域词性的指令词语进行词性提取转换,并将值传给分词结果的token.flag参数,在生成词向量时,将非空的token.flag与该指令词语原本的词向量进行合并后,再输入卷积神经网络进行计算。
本实施例中,如图1所示,具体包括以下步骤:
步骤1.构造目的领域转换字典、一般词性检索列表及分词词典。
其中,分词词典用于存储词语和词语出现的词频还有词性,且在分词词典中可进行特殊名词添加,并将其词性标注为想要其被识别成的领域(如video)。目的领域转换字典用于存放特殊名词的词性的中文转换词。一般词性检索列表用于存储词语的一般词性,如名词n(标注类于英文)。
目的领域转换字典主要是用于对在一般词性检索列表中没有成功匹配的进行词性提取转换,并将值传给分词结果的token.flag参数。
步骤2.获取指令语句并通过分词词典进行分词得到若干检索词语及其对应的词性;
步骤3.判断检索词语的词性是否在一般词性检索列表中,若是,则进入步骤4,否则,进入步骤5;
步骤4.将分词结果赋值给token.word参数,并将空字符赋值给token.flag参数;进入步骤6;
步骤5.将分词结果赋值给token.word参数,并将词性对应的中文字符赋值给token.flag参数;进入步骤6;
步骤6.生成词向量时,先判断token.flag参数是否有值,若是,则进入步骤7,否则,进入步骤9;
步骤7.判断检索词语的词性是否包含于目的领域转换字典中,若是,则进入步骤8,否则,进入步骤9;
步骤8.将检索词语的原始词向量和token.flag参数的词向量进行合并后输入卷积神经网络进行计算;
步骤9.将检索词语的原始词向量输入卷积神经网络进行计算。
实施例二
一种知识嵌入的领域识别方法,本实施例中,假设获取到的指令语句为“播放无某道”,期望结果返回最正确结果“video”,则该方法具体包括如下:
s1.在分词词典jieba_dict中添加新的条目,本实施例中添加的新的部分条目具体如下:
无某道1000video
难忘某宵1000music
其中,具体的数字表示其词频,video及music等表示词性。
s2.根据一般词性表生成一般词性检索列表。
具体的,本实施例中的一般词性表如图2所示,据此生成的般词性检索列表如图3所示。
s3.初始化目的领域转换字典field_dict。本实施例中的领域转换字典部分内容如图4所示。
s4.接收输入的“播放无某道”,并通过分词词典jieba_dict分词,结果为[pair('播放','v'),pair('无某道','video')]。
s5.检索一般词性检索列表flag_list,检索到无某道的词性video并不在其中,转s6。
s6.在目的领域转换字典field_dict中检索并取出video词性对应的中文并赋值给token.flag。
s7.合并词向量时,先判断token.flag是否有值,有值就合并原始词向量和token.flag参数的词向量并输入cnn,从而,提升该词语的特征,提高识别效率。
实施例三
本实施例中公开了一种计算机设备,该计算机设备可以是服务器,该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于存储知识嵌入的领域识别方法中涉及到的数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现知识嵌入的领域识别方法。
在另一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述实施例一中知识嵌入的领域识别方法的步骤。为避免重复,这里不再赘述。
在另一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述实施例一中知识嵌入的领域识别方法的步骤。为避免重复,这里不再赘述。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!