一种基于FREAK描述的虹膜特征提取方法与流程
一种基于freak描述的虹膜特征提取方法
技术领域
1.本发明属于生物特征识别及信息安全的技术领域,特别涉及一种基于freak描述的虹膜特征提取方法。
背景技术:
2.近年来虹膜识别因为其唯一性,非接触性,普遍性,可接受性等特点在近十年来发展迅速,在虹膜识别系统的核心算法方面已经取得了长足的进步,但是随着需求的不断更新,虹膜识别技术也需要不断地改进。
3.虹膜识别是利用计算机视觉在图像或视频中定位其虹膜并识别其身份的一种生物特征识别技术。虹膜识别主要有以下几个步骤:虹膜获取,虹膜分割,虹膜表征和虹膜匹配。
4.近些年,针对虹膜识别问题,国内外学者提出了一些相关算法。目前大多采用的是采用gabor滤波器对虹膜纹理进行滤波,根据滤波后的特征图进行编码,但是这种方法依赖于高清晰虹膜图像的获取,在受到不均匀光照以及纹理模糊的非理想虹膜识别上,识别性能显著下降,还有最近的基于特征点局部不变特征的非理想虹膜识别方法,例如基于尺度不变特征变换(sift)虹膜识别方法:region-based sift approach to iris recognition,optics and lasers in engineering,2009,以及加速稳健特征(surf)方法:speeded up robust features for efficient iris recognition,对于光照和虹膜纹理模糊具备良好的鲁棒性,但这些方法的实时性不高。
技术实现要素:
5.本发明的目的是在非均匀光照、纹理模糊、旋转等干扰在虹膜识别技术应用中普遍存在的情况下,提出一种基于freak描述的虹膜特征提取方法,以提高虹膜识别的整体性能。方法引用sift中的高斯差分金字塔检测模型,设计不同尺度的高斯核对虹膜进行滤波,根据不同尺度间的滤波特征图相减结果得到稳定的虹膜特征点集,并根据freak描述符对特征点及其周围采样点的相对大小关系进行编码得到初始描述子,之后对每一个特征点描述子进行重构减少特征向量的冗余度,提高描述子表征的区分性和匹配的速度,完成虹膜特征的提取。
6.本发明具体包括如下步骤:
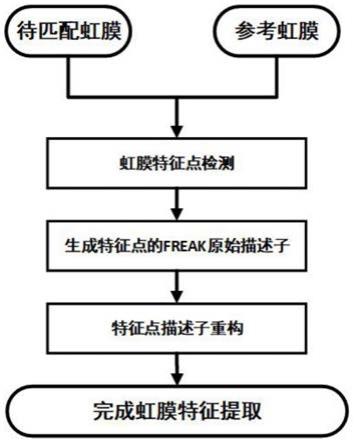
7.步骤一、虹膜特征点检测:
8.采用sift算法中的高斯金字塔模型提取稳定的虹膜特征点集合。
9.步骤二、特征点的freak描述子生成:
10.对步骤一得到特征点采用freak算法进行描述,该方法以特征点为圆心,构建7个同心圆,在每个同心圆上均匀采样使得每个同心圆上获得6个采样点,加上特征点总共获得43个采样点,可产生43*(43-1)/2=903个采样点对,对获得的采样点所在的感受野区域进行高斯模糊处理以降低噪声的影响,最后根据处理后采样点对灰度值大小的比较结果获得
每个特征点(维)的初始特征描述子;
11.步骤三、特征点描述子重构:
12.因为每个特征点周围较多的采样点会产生维度过高的特征描述子,而有些点对的比较结果对于虹膜图像的描述并非有效,所以需要对初始特征描述子进行重构:建立检测到的虹膜特征点矩阵,矩阵中的每一行表示一个特征点描述子,每一行中的每个二进制值表示步骤二得到的包括特征点在内的所有采样点对的比较结果,矩阵大小为n
×
903,n为检测到的特征点的数目。对虹膜特征点矩阵的每一列计算其均值,由于虹膜特征点矩阵中的元素都是0/1分布的,均值在0.5附近说明该列具有高的方差。最后计算每一列平均值与值0.5的差,根据差值由小到大进行排序,取前512列作为重构后的特征点描述子,完成虹膜特征提取。
13.本发明有益效果如下:
14.本发明通过构建高斯差分金子塔模型从虹膜纹理的多个尺度检测稳定的特征点集合,并利用freak描述符根据特征点周围像素强度关系进行编码,摒弃了传统点模式算法根据像素本身复杂的梯度信息进行编码,提升了了虹膜特征表征和匹配速度;另外通过对原始特征向量的有效重构,降低特征向量之间的相关性,提高特征点表征的区分性,本文发明在光照、虹膜旋转、纹理模糊等各种干扰下,所提取的特征表现出很好的鲁棒性。
附图说明
15.图1为虹膜特征提取流程图;
16.图2为高斯差分空间(difference of gaussian,dog)示意图;
17.图3为局部特征点检测示意图;
18.图4为特征点邻域采样模式示意图;
具体实施方式
19.下面结合附图对本发明进一步说明。
20.一种基于freak描述的虹膜特征提取方法,如图1所示,其具体步骤如下:
21.步骤一:虹膜特征点检测:
22.a、采用不同尺度因子σ的高斯函数与虹膜图像进行卷积后进行3次下采样构建3组5层的高斯尺度空间,方式如下:
23.l(x,y,σ)=i(x,y)*g(x,y,σ)
ꢀꢀꢀ
(1)
[0024][0025]
其中:l(x,y,σ)为虹膜图像的尺度空间表征,i(x,y)为虹膜图像,g(x,y,σ)为高斯核,*为卷积操作,σ是尺度空间因子,σ值的大小决定着虹膜图像被模糊平滑的程度,当σ连续变化时,l(x,y,σ)构成虹膜图像的尺度空间表征。将每一组中5层虹膜图像依次俩俩做差得后到3组4层的高斯差分尺度空间(difference ofgaussian,dog):
[0026]
[0027]
其中d(x,y,σ)为高斯差分尺度空间函数,k为常数,图2为不同σ下对应的dog图像,这些组的dog图像将作为下一步检测初始虹膜特征点的对象。
[0028]
b、特征点选择
[0029]
图3所示为dog空间中一个像素的空间位置分布图。将待检测像素点(叉号标记)与和它同尺度的周围邻域8个像素和上下相邻对应位置的9
×
2个像素共26个像素进行比较,在这局部区域内若为极大值或者为极小值,则标记为初始特征点。利用高斯差分尺度空间函数d(x,y,σ)在初始特征点处的泰勒展开式对初始特征点进行三维二次函数拟合确定初始特征点的精确位置;由于虹膜图像经过高斯差分处理后检测到的一部分特征点的边缘响应会大于设定的阈值,造成这些特征点并不稳定,所以需要在拟合的同时去除这些特征点和低对比度特征点,拟合公式如下所示:
[0030][0031]
其中,x0,y0,σ0为离散空间中极值点坐标,并不是真正的极值点精确位置,对公式(4)求导后令其等于零,得到特征点精确位置为再将带入公式(4),根据的响应的绝对值剔除不稳定的低对比度的特征点,之后根据在虹膜特征点处的hessian矩阵,如公式(5)所示:
[0032][0033]
求出特征点的特征值,其中d
xx
,d
xy
,d
yy
是通过特征点邻域对应位置的差分求得的,最后将不满足公式(6)的特征点去除掉:
[0034][0035]
其中tr(h)为矩阵h对角元素之和,det(h)矩阵的行列式,t为所设边缘响应的阈值,满足公式(6)的特征点将保留下来,不满足的点表明该点具有很大的主曲率,这样的点可能为边界点,应该去除掉。
[0036]
步骤二:特征点的freak描述子生成:
[0037]
对步骤一确定下来的特征点进行编码,freak算法的采样模式与视网膜感受域结构相似,如图4所示:以步骤一得到的特征点为中心,采样点均匀分布在以特征点为圆心的7层同心圆上。与特征点间隔越小,采样点越密集;与特征点间隔越大,采样点越稀疏。另外对每一个采样点需要进行高斯平滑以消除噪声对采样点的影响。根据采样点对之间的强度大小关系进行编码,得到二进制特征向量,方式如下:
[0038]
f=∑
0≤a<n2a
t(p
a
)
ꢀꢀꢀ
(7)
[0039]
其中:p
a
表示一对采样点,n为描述子长度,t(p
a
)为采样点对的输出结果。
[0040]
[0041]
其中:为经过高斯平滑后的采样点的灰度值强度,r1和r2为不同采样点所在的同心圆半径,每个特征点本身参与比较,最终得到维的特征点描述子。
[0042]
步骤三:由于在采样点的选取过程中,采样点之间部分区域会重叠,造成原特征向量的区分性不高,因此需要对原特征向量进行重构,针对信息量更大的维度实行保留,减少特征向量的冗余性。通过以下步骤对虹膜特征向量进行重构,筛选保留高信息量的维度:首先对检测到的虹膜特征点建立一个矩阵,矩阵中的每一行表示一个特征点,每一行中的每一列表示的是上面提到的包括该特征点在内的所有采样点对的比较结果,矩阵大小为n
×
903,n为检测到的特征点的数目。之后计算矩阵中每一列的平均值,为得到区分性强的特征,列向量的方差应该较大,即对应列的平均值应该更接近0.5。最后计算每一列平均值与值0.5的差,根据差值由小到大进行排序取前512列,完成虹膜特征提取。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1