一种飞行器仿真模型并行计算系统及方法与流程
1.本发明涉及半实物仿真技术领域,尤其涉及一种飞行器仿真模型并行计算系统及方法。
背景技术:
2.多飞行器协同对抗通常使用一种或多种打击单元,通过飞行器系统、发射平台间的信息配合,完成与目标之间的火力对抗。因此,对协同打击与对抗过程的仿真需要解决多参战节点仿真模型计算及仿真数据通信问题。
3.目前尚没有采用gpu计算芯片对参战仿真节点进行并行计算,并基于直接内存读取访问技术实现仿真数据的高效传输,并在协同制导半实物、数学仿真试验中采用上述方法进行多节点模型解算的应用案例。
技术实现要素:
4.鉴于上述的分析,本发明旨在提供一种飞行器模型并行计算的仿真系统及方法,以解决目前飞行器仿真模型存在的上述部分或全部问题。
5.本发明的目的主要是通过以下技术方案实现的:
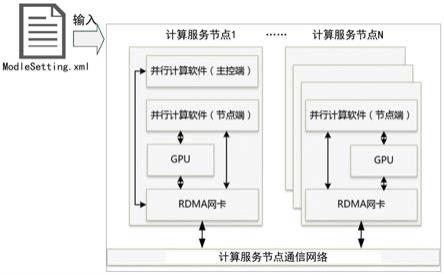
6.一方面,本发明提供了一种飞行器仿真模型并行计算系统,包括n个计算服务节点、n个计算服务节点间的通信网络及安装在各计算服务节点上的并行计算软件;
7.所述计算服务节点包括gpu、rmda光纤通讯网卡和并行计算软件;其中,第一计算服务节点上运行并行计算软件的主控端,并在gpu上运行并行计算软件的节点终端;其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端;
8.所述gpu,用于为设置为参战节点的飞行器仿真模型提供并行解算;
9.所述rmda光纤通讯网卡,用于构建所述n个计算服务节点间通信网络,并通过上述通信网络对飞行器仿真模型间进行数据分发。
10.进一步地,仿真试验开始时,第一计算服务节点运行所述并行计算软件的主控端,通过飞行器协同工作流程配置文件设置参战节点的飞行器仿真模型的名称和参战节点个数;所述参战节点个数为参与仿真的模型实例的个数;
11.第一计算服务节点运行所述并行计算软件的主控端,还用于根据所述配置文件对所述参战节点的飞行器仿真模型进行模型实例化,并采用静态平均分配或动态负载均衡的方式将模型实例分发到上述n个计算服务节点上,根据参战节点个数使得每个计算服务节点运行多个模型实例;
12.n个所述计算服务节点运行所述并行计算软件的节点终端,用于完成本地计算服务节点的gpu内存对主控端所在的第一计算服务节点的gpu内存的地址映射。
13.进一步地,参战节点的飞行器仿真模型运行时,各计算服务节点上运行并行计算软件的节点终端在gpu的sp计算核上并发运行模型实例,每个sp计算核心运行一个模型实例,并以配置的周期输出数据;
14.上述各模型实例的周期输出数据直接通过所述地址映射写入主控端所在的第一计算服务节点的gpu内存。
15.进一步地,所述第一计算服务节点上运行并行计算软件的主控端,包括:
16.编制并输入飞行器协同工作流程配置文件modlesetting.xml,进行各个计算服务节点的数据存储地址的配置和映射;
17.对各个计算服务节点的模型实例完成包括类型、数量和周期在内的参数配置。
18.进一步地,所述其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端,包括以下步骤:
19.s1,接收第一计算服务节点下发的参数,并对本地gpu进行初始化和计算资源分配;
20.s2,根据所述第一计算服务节点下发的参数进行模型实例化生成多个gpu并行计算模型节点;
21.s3,接收第一计算服务节点的主控端发送的仿真运行及帧计算开始消息;
22.s4,各本地gpu计算线程从本地gpu内存读取输入数据,并完成一帧模型计算;
23.s5,各本地gpu计算线程向第一计算服务节点的gpu内存写入输出数据,并返回帧计算完成消息;
24.s6,接收下一帧计算开始消息,转至执行s4,直至多个gpu并行计算模型节点全部完成仿真计算后结束。
25.另一方面,本发明提供了一种飞行器仿真模型并行计算方法,包括以下步骤:
26.构建n个计算服务节点间通信网络,所述通信网络用于对飞行器仿真模型间进行数据分发;
27.在n个计算服务节点上安装并行计算软件;其中,第一计算服务节点上运行主控端的并行计算软件,并在gpu上运行并行计算软件的节点终端;其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端;
28.基于所述并行计算软件并通过各计算服务节点的gpu为设置为参战节点的飞行器仿真模型提供并行解算。
29.进一步地,仿真试验开始时,第一计算服务节点运行所述并行计算软件的主控端,通过飞行器协同工作流程配置文件设置参战节点的飞行器仿真模型的名称和参战节点个数;所述参战节点个数为参与仿真的模型实例的个数;
30.第一计算服务节点运行所述并行计算软件的主控端,根据所述配置文件对所述参战节点的飞行器仿真模型进行模型实例化,并采用静态平均分配或动态负载均衡的方式将模型实例分发到上述n个计算服务节点上,根据参战节点个数使得每个计算服务节点运行多个模型实例;
31.n个所述计算服务节点运行所述并行计算软件的节点终端,完成本地计算服务节点的gpu内存对主控端所在的第一计算服务节点的gpu内存的地址映射。
32.进一步地,参战节点仿真模型运行时,各计算服务节点上运行并行计算软件的节点终端在gpu的sp计算核上并发运行模型实例,每个sp计算核心运行一个模型实例,并以配置的周期输出数据;
33.上述各模型实例的周期输出数据直接通过所述地址映射写入主控端所在的第一
计算服务节点的gpu内存。
34.进一步地,所述第一计算服务节点上运行并行计算软件的主控端,包括:
35.编制并输入飞行器协同工作流程配置文件modlesetting.xml,进行各个计算服务节点的数据存储地址的配置和映射;
36.对各个计算服务节点的模型实例完成包括类型、数量和周期在内的参数配置。
37.进一步地,所述其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端,包括以下步骤:
38.s1,接收第一计算服务节点下发的参数,并对本地gpu进行初始化和计算资源分配;
39.s2,根据所述第一计算服务节点下发的参数进行模型实例化生成多个gpu并行计算模型节点;
40.s3,接收第一计算服务节点的主控端发送的仿真运行及帧计算开始消息;
41.s4,各本地gpu计算线程从gpu内存读取输入数据,并完成一帧模型计算;
42.s5,各本地gpu计算线程向gpu内存写入输出数据,并返回帧计算完成消息;
43.s6,接收下一帧计算开始消息,转至执行s4,直至多个gpu并行计算模型节点全部完成仿真计算后结束。
44.本技术方案有益效果如下:本发明公开了一种飞行器仿真模型并行计算系统及方法,采用gpu计算芯片对参战节点的飞行器仿真模型进行并行计算,提高了单个计算节点对大量细粒度模型的计算处理能力;同时采用直接内存读取访问(remote direct memory access,rdma)解决了计算服务节点间的数据高通量、低延迟传输问题。
45.本发明的其他特征和优点将在随后的说明书中阐述,并且,部分的从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
附图说明
46.附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
47.图1为本发明实施例的飞行器仿真模型并行计算系统架构图;
48.图2为本发明实施例的飞行器仿真模型并行计算系统的数据流示意图;
49.图3为本发明实施例的飞行器仿真模型并行计算系统的数据处理流程框图;
50.图4为本发明实施例的飞行器仿真模型并行计算方法的流程图。
具体实施方式
51.下面结合附图来具体描述本发明的优选实施例,其中,附图构成本申请一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
52.本发明的一个具体实施例,如图1所示,公开了一种飞行器仿真模型并行计算系统,包括n个计算服务节点、n个计算服务节点间的通信网络及安装在各计算服务节点上的并行计算软件;
53.所述计算服务节点包括gpu、rmda光纤通讯网卡和并行计算软件;其中,第一计算
服务节点上运行并行计算软件的主控端,并在gpu上运行并行计算软件的节点终端;其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端;
54.所述gpu,用于为设置为参战节点的飞行器仿真模型提供并行解算;
55.所述rmda光纤通讯网卡,用于构建所述n个计算服务节点间通信网络,并通过上述通信网络对飞行器仿真模型间进行数据分发。
56.具体地,如图1所示的飞行器仿真模型并行计算系统由计算服务节点1到n、计算服务节点间的通信网络、并行计算软件(主控端和节点终端)组成。计算服务节点为高性能工作站,配置支持gpudirect的gpu和rdma光纤网卡服务器,计算服务节点个数的确定需结合战场场景中参战节点规模、gpu计算能力、模型的计算周期要求、仿真实验加速比等指标要求。飞行仿真模型行计算系统的软件部分由并行计算软件的主控端和节点终端构成,在计算服务节点1中运行并行计算软件的主控端和节点终端,在计算服务节点2到n中运行并行计算软件的节点终端,其中,节点终端均运行在gpu上。
57.本发明基于gpu的飞行器仿真模型并行计算构建起支持数百量级细粒度模型高效计算架构,解决了细粒度模型计算算力大、高通量数据交互延迟等制约对抗仿真精细度发展的问题,为协同智能算法、飞行器协同工作模式提供高效、逼真的仿真试验环境。
58.本发明的一个具体实施例,仿真试验开始时,第一计算服务节点运行所述并行计算软件的主控端,通过飞行器协同工作流程配置文件设置参战节点的飞行器仿真模型的名称和参战节点个数;所述参战节点个数为参与仿真的模型实例的个数;
59.第一计算服务节点运行所述并行计算软件的主控端,还用于根据所述配置文件对所述参战节点的飞行器仿真模型进行模型实例化,并采用静态平均分配或动态负载均衡的方式将模型实例分发到上述n个计算服务节点上,根据参战节点个数使得每个计算服务节点运行多个模型实例;
60.n个所述计算服务节点运行所述并行计算软件的节点终端,用于完成本地计算服务节点的gpu内存对主控端所在的第一计算服务节点的gpu内存的地址映射。
61.具体地,试验准备阶段,在飞行器协同工作流程配置文件modlesetting.xml中定义参战节点的飞行器仿真模型的名称、节点个数信息。主控端软件根据配置文件对所涉及仿真模型进行实例化,节点终端软件完成本地gpu内存对主控端软件所在计算服务节点1的gpu内存地址映射。
62.具体地,内存地址映射,将远程节点的内存地址映射到本地内存地址,通过此映射在向本地内存写入数据时,数据会自动拷贝到远程节点的内存。
63.具体地,模型实例分发采用静态分配和负载均衡相结合的方式。对于仿真开始时直接运行的模型采用静态分配的方式,将所有的模型实例平均分配到多个计算节点中;而对于仿真过程中动态加入的模型实例,则采用负载均衡的方式,通过计数器和计时器对每个计算服务节点的计算耗时进行记录,来判断每个计算服务节点的负载情况,并将新加入的模型实例分发到负载最低的计算节点上。
64.本发明的一个具体实施例,参战节点的飞行器仿真模型运行时,各计算服务节点上运行并行计算软件的节点终端在gpu的sp计算核上并发运行模型实例,每个sp计算核心运行一个模型实例,并以配置的周期输出数据;
65.上述各模型实例的周期输出数据直接通过所述地址映射写入主控端所在的第一
计算服务节点的gpu内存。
66.具体地,仿真运行阶段,各计算服务节点上的节点终端软件在gpu的sp计算核上并发运行各模型实例,模型实例的周期输出数据直接通过地址映射写入主控端所在计算服务节点1的gpu内存,同理,所有模型实例对周期输出数据的读取仍通过映射地址,访问计算服务节点1的gpu内存。
67.本发明的一个具体实施例,所述第一计算服务节点上运行并行计算软件的主控端,包括:
68.编制并输入飞行器协同工作流程配置文件modlesetting.xml,进行各个计算服务节点的数据存储地址的配置和映射;
69.对各个计算服务节点的模型实例完成包括类型、数量和周期在内的参数配置。
70.具体地,编制协同工作过程说明文件modlesetting.xml,在计算服务节点1运行主控端软件:
71.1)输入modlesetting.xml,完成对各个计算节点的数据存储地址进行配置和映射;
72.2)完成对各个计算节点的模型实例类型、数量、周期等参数进行配置。
73.具体举例来说,所述飞行器协同工作流程配置文件设置参战节点个数为256个,并分别部署于两个计算服务节点。如图2所示的并行计算系统的数据流示意图。
74.本发明的一个具体实施例,所述其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端,包括以下步骤:
75.s1,接收第一计算服务节点下发的参数,并对本地gpu进行初始化和计算资源分配;
76.s2,根据所述第一计算服务节点下发的参数进行模型实例化生成多个gpu并行计算模型节点;
77.s3,接收第一计算服务节点的主控端发送的仿真运行及帧计算开始消息;
78.s4,各本地gpu计算线程从本地gpu内存读取输入数据,并完成一帧模型计算;
79.s5,各本地gpu计算线程向第一计算服务节点的gpu内存写入输出数据,并返回帧计算完成消息;
80.s6,接收下一帧计算开始消息,转至执行s4,直至多个gpu并行计算模型节点全部完成仿真计算后结束。
81.多个gpu并行计算模型节点全部完成仿真计算后,仿真结束。
82.具体举例来说,计算服务节点1、计算服务节点2分别运行节点终端软件,依次进行以下操作:
83.1)接收主控端下发参数;
84.2)对gpu进行初始化和计算资源分配;
85.3)按主控端参数对模型进行实例化生成多个gpu并行计算模型节点;
86.4)接收仿真计算开始消息;
87.5)接收帧计算开始消息;
88.6)各gpu计算线程从gpu内存读取输入数据;
89.7)各gpu计算线程完成一帧模型计算;
90.8)各gpu计算线程向gpu内存写入输出数据,并返回帧计算完成消息;
91.9)接收下一帧计算开始消息。
92.以上结合计算服务节点间数据流,如图2所示,模型实例线程将计算结果作为输出写入相应的数据块,并从gpu内存中获取其它模型实例输出数据,待参战节点的模型全部完成仿真计算后,仿真结束。
93.如图3所示的飞行器仿真模型并行计算系统的数据处理流程框图。
94.仿真数据包括作战想定数据、模型基本信息、模型初始化数据、模型运行时数据、仿真主题数据。其中,作战想定数据和模型基本信息都保存在作战想定文件中,主要用于模型的多节点实例化和基本信息设置;每个模型实例对应一份模型初始化数据,包括发射点、目标点等需要装订的初始化数据;模型运行时数据为仿真开始后,模型每帧计算输出的数据;仿真主题数据是在模型运行时数据的基础上,根据数据的用途进行格式化装配后的结构化数据。
95.仿真开始后,平台首先加载作战想定文件,根据想定数据中的模型数量、模型类型、基本信息进行多节点实例化,并通过仿真网络将模型实例分配到各个计算节点上。在进行初始化数据加载时,多节点模型实例各自加载本实例所对应的初始化数据,进行模型初始状态的设置。模型运行开始后,各模型实例在帧同步下进行逐帧解算,并输出模型运行时数据。在数据装配阶段,模型运行时数据被装配为有特定用途的主题数据,包括用于场景显示的主题数据、用于数据链通信的主题数据以及用于其他仿真节点的主题数据等。装配完成后的各类主题数据在数据分发时,会根据预先设定的网络地址被分发到需要使用相应主题数据的各个节点上。
96.本发明的一个具体实施例,如图4所示,公开了一种飞行器仿真模型并行计算方法,包括以下步骤:
97.步骤1、构建n个计算服务节点间通信网络,所述通信网络用于对飞行器仿真模型间进行数据分发;
98.步骤2、在n个计算服务节点上安装并行计算软件;其中,第一计算服务节点上运行主控端的并行计算软件,并在gpu上运行并行计算软件的节点终端;其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端;
99.步骤3、基于所述并行计算软件并通过各计算服务节点的gpu为设置为参战节点的飞行器仿真模型提供并行解算。
100.本发明的一个具体实施例,仿真试验开始时,第一计算服务节点运行所述并行计算软件的主控端,通过飞行器协同工作流程配置文件设置参战节点的飞行器仿真模型的名称和参战节点个数;所述参战节点个数为参与仿真的模型实例的个数;
101.第一计算服务节点运行所述并行计算软件的主控端,根据所述配置文件对所述参战节点的飞行器仿真模型进行模型实例化,并采用静态平均分配或动态负载均衡的方式将模型实例分发到上述n个计算服务节点上,根据参战节点个数使得每个计算服务节点运行多个模型实例;
102.n个所述计算服务节点运行所述并行计算软件的节点终端,完成本地计算服务节点的gpu内存对主控端所在的第一计算服务节点的gpu内存的地址映射。
103.本发明的一个具体实施例,参战节点仿真模型运行时,各计算服务节点上运行并
行计算软件的节点终端在gpu的sp计算核上并发运行模型实例,每个sp计算核心运行一个模型实例,并以配置的周期输出数据;
104.上述各模型实例的周期输出数据直接通过所述地址映射写入主控端所在的第一计算服务节点的gpu内存。
105.本发明的一个具体实施例,所述第一计算服务节点上运行并行计算软件的主控端,包括:
106.编制并输入飞行器协同工作流程配置文件modlesetting.xml,进行各个计算服务节点的数据存储地址的配置和映射;
107.对各个计算服务节点的模型实例完成包括类型、数量和周期在内的参数配置。
108.本发明的一个具体实施例,所述其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端,包括以下步骤:
109.s1,接收第一计算服务节点下发的参数,并对本地gpu进行初始化和计算资源分配;
110.s2,根据所述第一计算服务节点下发的参数进行模型实例化生成多个gpu并行计算模型节点;
111.s3,接收第一计算服务节点的主控端发送的仿真运行及帧计算开始消息;
112.s4,各本地gpu计算线程从gpu内存读取输入数据,并完成一帧模型计算;
113.s5,各本地gpu计算线程向gpu内存写入输出数据,并返回帧计算完成消息;
114.s6,接收下一帧计算开始消息,转至执行s4,直至多个gpu并行计算模型节点全部完成仿真计算后结束。
115.多个gpu并行计算模型节点全部完成仿真计算后,仿真结束。
116.综上所述,本发明公开了一种飞行器仿真模型并行计算系统,包括n个计算服务节点、n个计算服务节点间的通信网络及安装在各计算服务节点上的并行计算软件;所述计算服务节点包括gpu、rmda光纤通讯网卡和并行计算软件;其中,第一计算服务节点上运行并行计算软件的主控端,并在gpu上运行并行计算软件的节点终端;其余n
‑
1个计算服务节点的gpu上分别运行并行计算软件的节点终端;所述gpu,用于为设置为参战节点的飞行器仿真模型提供并行解算;所述rmda光纤通讯网卡,用于构建所述n个计算服务节点间通信网络,并通过上述通信网络对飞行器仿真模型间进行数据分发。同时公开了与上述系统构成同一发明构思的并行计算方法。本发明实施例采用gpu计算芯片对参战节点的飞行器仿真模型进行并行计算,提高了单个计算节点对大量细粒度模型的计算处理能力;同时采用直接内存读取访问(remote direct memory access,rdma)解决了计算服务节点间的数据高通量、低延迟传输问题。
117.本领域技术人员可以理解,实现上述实施例中方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
118.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1