一种基于液质联用仪和AI算法的生物分析中消除基质效应的方法与流程
本发明涉及液质联用仪生物分析技术领域,具体为一种基于液质联用仪和ai算法的生物分析中消除基质效应的方法。
背景技术:
基质是指样品中除被分析物以外的一切组分,这些组分能明显降低或增强目标离子的生成速率与离子强度,从而严重影响检测结果的准确性。这种离子抑制或离子增强的效应便称为基质效应。
液相色谱-串联质谱(lc-ms/ms)联用检测技术中,与目标物共流出的干扰物在离子源离子化时影响了分析物,从而产生了基质效应。主要包括:1.由于离子化时,带电液滴的表面大小和额外电量的数量(10-5mol/l)都是有限的,所以干扰物会与目标物竞争这有限的表面和电量导致目标物离子化不完全;(2)干扰物的存在会改变分析物粘度、表面张力等物化性质而影响目标物的离子化;(3)基质中一些非挥发性物质会与目标化合物形成络合物或沉积物导致无法成功生成气态离子。基质效应按照影响效果可分为三类:me<0,意味基质的存在抑制了分析物的响应值;me=0,表明基质的存在对该分析物的响应值无影响;me>0,意味着基质的存在增强了分析物的响应。
基质效应按绝对值大小可以分为三个等级:
∣me∣≥50%,称为强基质效应;
20%≤∣me∣<50%,称为中等强度基质效应;
0%≤∣me∣<20%,称为弱基质效应。
近几年,基质效应的消除和弥补方法得到广泛的研究,,通常以空白基质配制标准曲线,以消除基质效应的影响。但由于不同样品的基质效应各不相同,有的甚至呈相反的作用。在实际操作中,不可能针对每一个样品都以相应的基质配制一条标准曲线进行校准。
技术实现要素:
本发明的目的在于提供一种基于液质联用仪和ai算法的生物分析中消除基质效应的方法,可最大限度地消除基质效应,对生物分析结果进行修正,避免了不同样品基质引起的偏差,保证了结果的准确性,同时降低了检测成本,降低了检测时间,提高了检测效率,更为简单快捷,节约人力和物质成本,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于液质联用仪和ai算法的生物分析中消除基质效应的方法,包括以下步骤:
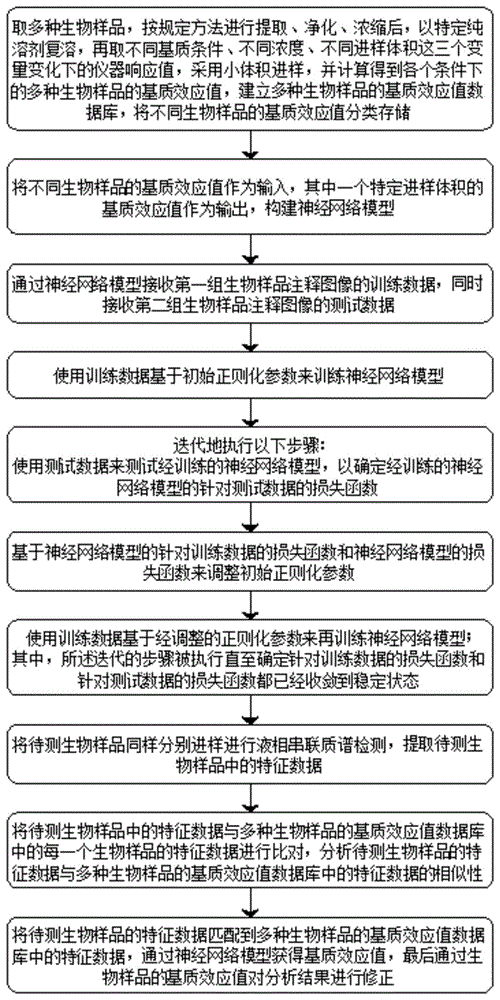
s1、取多种生物样品,按规定方法进行提取、净化、浓缩后,以特定纯溶剂复溶,再取不同基质条件、不同浓度、不同进样体积这三个变量变化下的仪器响应值,采用小体积进样,并计算得到各个条件下的多种生物样品的基质效应值,建立多种生物样品的基质效应值数据库,将不同生物样品的基质效应值分类存储;
s2、将不同生物样品的基质效应值作为输入,其中一个特定进样体积的基质效应值作为输出,构建神经网络模型;
s3、通过神经网络模型接收第一组生物样品注释图像的训练数据,同时接收第二组生物样品注释图像的测试数据;
s4、使用训练数据基于初始正则化参数来训练神经网络模型;
s5、迭代地执行以下步骤:
使用测试数据来测试经训练的神经网络模型,以确定经训练的神经网络模型的针对测试数据的损失函数;
s6、基于神经网络模型的针对训练数据的损失函数和神经网络模型的损失函数来调整初始正则化参数;
s7、使用训练数据基于经调整的正则化参数来再训练神经网络模型;
其中,所述迭代的步骤被执行直至确定针对训练数据的损失函数和针对测试数据的损失函数都已经收敛到稳定状态;
s8、将待测生物样品同样分别进样进行液相串联质谱检测,提取待测生物样品中的特征数据;
s9、将待测生物样品中的特征数据与多种生物样品的基质效应值数据库中的每一个生物样品的特征数据进行比对,分析待测生物样品的特征数据与多种生物样品的基质效应值数据库中的特征数据的相似性;
s10、将待测生物样品的特征数据匹配到多种生物样品的基质效应值数据库中的特征数据,通过神经网络模型获得基质效应值,最后通过生物样品的基质效应值对分析结果进行修正。
优选的,所述s1中采用小体积进样时当样品为弱基质效应生物样品时,进样体积小于5μl,当样品为中等强度基质效应生物样品时,进样体积小于等于2μl,当样品为强基质效应生物样品时,先通过一定程度的基质稀释,再采用小体积进样。
优选的,所述s1中仪器中质谱的扫描模式为多反应监测扫描模式;离子模式为电喷雾正离子源esi+;质谱的参数如下:池加速电压为4v,驻留时间为20ms;干燥气温度为325℃;干燥气流速为8l/min;雾化器压力为35psi;鞘气温度为375℃;鞘气流速为11l/min;毛细管电压为4000v;光电倍增管电压为300v;
液相色谱柱为50mm×2.1mm,1.8μm粒径,流速为0.3ml/min,运行时间为8min,柱温为35℃;液相色谱流动相a为纯水,流动相b为甲醇;梯度洗脱程序为,起始时间,流动相a:b的体积比为90:10,维持0.2min;在0.2-5min内,体积比由90:10线性变化至10:90,并维持该体积至6min,6.1min时,体积比迅速变回起始体积比90:10。
优选的,所述生物样品的提取和净化的方法为:将生物样品放至离心管中加入提取剂,再在匀浆机上匀质后加入nacl和无水mgso4,然后震荡离心,取上层清液干燥后加入流动相a和b的混合液溶解,最后将溶液过尼龙膜后进样。
优选的,所述正则化参数包括以下中的至少一项:与所述神经网络模型中的神经元相关的dropout参数或与所述神经网络模型中的神经元之间的连接相关的dropconnect参数。
优选的,所述s7中当神经网络模型的损失函数在随后的迭代之间改变小于限定量时,所述神经网络模型的针对训练数据的损失函数被认为已经收敛到稳定状态。
优选的,所述s7中再训练神经网络模型包括基于前次迭代期间的神经网络模型的一个或多个层中的神经元的权重来设置神经元的权重。
优选的,所述s8中提取待测生物样品中的特征数据的具体方法包括:
s81、对待测生物样品进行检测跟踪,得到待测生物样品中精确特征点;
s82、根据精确特征点,插值获得其他选取的生物样品特征点;
s83、计算得到特征点i的gabor特征
其中,n为选取的特征点个数。
优选的,所述s9的具体方法包括:
s91、选取多种生物样品的基质效应值数据库中的一个基质效应值k的特征模板库,如下:
s92、从特征模板库中选取特征模板,如下:
其中,m为生物样品的特征模板个数,i为生物样品特征;
计算待测生物样品的特征
s93、计算待测生物样品与特征模板
其中,n为选取的待测生物样品的特征点个数;
s94、计算待测生物样品与其中一个生物样品的基质效应值k的相似度为
s95、重复步骤s91-s94,获得待测生物样品与多种生物样品的基质效应值数据库中所有k个生物样品的相似度,取其中最大者
优选的,所述s10中还包括设δ为相似度阈值,若smax>δ,则判断待测生物样品与多种生物样品的基质效应值数据库中的基质效应值k′相匹配。
与现有技术相比,本发明的有益效果是:
本发明取多种生物样品的基质效应值构建神经网络模型,再使用训练数据基于初始正则化参数来训练神经网络模型,使用测试数据来测试经训练的神经网络模型,以确定经训练的神经网络模型的针对测试数据的损失函数,然后通过损失函数调整初始正则化参数,使用训练数据基于经调整的正则化参数来再训练神经网络模型,直至收敛到稳定状态,最后提取待测生物样品中的特征数据后与多种生物样品的基质效应值数据库中的每一个生物样品的特征数据进行比对,分析出相似性,获得基质效应值,最后通过生物样品的基质效应值对分析结果进行修正,本发明在构建神经网络模型后又改善了神经网络的准确性,且基于ai算法对特征数据进行比对,分析出相似性,可最大限度地消除基质效应,对生物分析结果进行修正,避免了不同样品基质引起的偏差,保证了结果的准确性,同时降低了检测成本,降低了检测时间,提高了检测效率,更为简单快捷,节约人力和物质成本。
附图说明
图1为本发明的一种基于液质联用仪和ai算法的生物分析中消除基质效应的方法的流程示意图;
图2为本发明的神经网络模型的范例的简化示意图;
图3为本发明在dropout参数被应用的情况下的图2的神经网络模型的简化示意图;
图4为本发明在dropconnect参数被应用的情况下的图2的神经网络模型的简化示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
因此,以下对在附图中提供的本发明的实施方式的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
请参阅图1-4,本发明提供一种技术方案:
一种基于液质联用仪和ai算法的生物分析中消除基质效应的方法,包括以下步骤:
s1、取多种生物样品,按规定方法进行提取、净化、浓缩后,以特定纯溶剂复溶,再取不同基质条件、不同浓度、不同进样体积这三个变量变化下的仪器响应值,采用小体积进样,并计算得到各个条件下的多种生物样品的基质效应值,建立多种生物样品的基质效应值数据库,将不同生物样品的基质效应值分类存储;
s2、将不同生物样品的基质效应值作为输入,其中一个特定进样体积的基质效应值作为输出,构建神经网络模型;
s3、通过神经网络模型接收第一组生物样品注释图像的训练数据,同时接收第二组生物样品注释图像的测试数据;
s4、使用训练数据基于初始正则化参数来训练神经网络模型;
s5、迭代地执行以下步骤:
使用测试数据来测试经训练的神经网络模型,以确定经训练的神经网络模型的针对测试数据的损失函数;
s6、基于神经网络模型的针对训练数据的损失函数和神经网络模型的损失函数来调整初始正则化参数;
s7、使用训练数据基于经调整的正则化参数来再训练神经网络模型;
其中,所述迭代的步骤被执行直至确定针对训练数据的损失函数和针对测试数据的损失函数都已经收敛到稳定状态;
s8、将待测生物样品同样分别进样进行液相串联质谱检测,提取待测生物样品中的特征数据;
s9、将待测生物样品中的特征数据与多种生物样品的基质效应值数据库中的每一个生物样品的特征数据进行比对,分析待测生物样品的特征数据与多种生物样品的基质效应值数据库中的特征数据的相似性;
s10、将待测生物样品的特征数据匹配到多种生物样品的基质效应值数据库中的特征数据,通过神经网络模型获得基质效应值,最后通过生物样品的基质效应值对分析结果进行修正。
作为本发明的一种技术优化方案,所述s1中采用小体积进样时当样品为弱基质效应生物样品时,进样体积小于5μl,当样品为中等强度基质效应生物样品时,进样体积小于等于2μl,当样品为强基质效应生物样品时,先通过一定程度的基质稀释,再采用小体积进样。
作为本发明的一种技术优化方案,所述s1中仪器中质谱的扫描模式为多反应监测扫描模式;离子模式为电喷雾正离子源esi+;质谱的参数如下:池加速电压为4v,驻留时间为20ms;干燥气温度为325℃;干燥气流速为8l/min;雾化器压力为35psi;鞘气温度为375℃;鞘气流速为11l/min;毛细管电压为4000v;光电倍增管电压为300v;
液相色谱柱为50mm×2.1mm,1.8μm粒径,流速为0.3ml/min,运行时间为8min,柱温为35℃;液相色谱流动相a为纯水,流动相b为甲醇;梯度洗脱程序为,起始时间,流动相a:b的体积比为90:10,维持0.2min;在0.2-5min内,体积比由90:10线性变化至10:90,并维持该体积至6min,6.1min时,体积比迅速变回起始体积比90:10。
作为本发明的一种技术优化方案,所述生物样品的提取和净化的方法为:将生物样品放至离心管中加入提取剂,再在匀浆机上匀质后加入nacl和无水mgso4,然后震荡离心,取上层清液干燥后加入流动相a和b的混合液溶解,最后将溶液过尼龙膜后进样。
作为本发明的一种技术优化方案,所述正则化参数包括以下中的至少一项:与所述神经网络模型中的神经元相关的dropout参数或与所述神经网络模型中的神经元之间的连接相关的dropconnect参数。
作为本发明的一种技术优化方案,所述s7中当神经网络模型的损失函数在随后的迭代之间改变小于限定量时,所述神经网络模型的针对训练数据的损失函数被认为已经收敛到稳定状态。
作为本发明的一种技术优化方案,所述s7中再训练神经网络模型包括基于前次迭代期间的神经网络模型的一个或多个层中的神经元的权重来设置神经元的权重。
作为本发明的一种技术优化方案,所述s8中提取待测生物样品中的特征数据的具体方法包括:
s81、对待测生物样品进行检测跟踪,得到待测生物样品中精确特征点;
s82、根据精确特征点,插值获得其他选取的生物样品特征点;
s83、计算得到特征点i的gabor特征
其中,n为选取的特征点个数。
作为本发明的一种技术优化方案,所述s9的具体方法包括:
s91、选取多种生物样品的基质效应值数据库中的一个基质效应值k的特征模板库,如下:
s92、从特征模板库中选取特征模板,如下:
其中,m为生物样品的特征模板个数,i为生物样品特征;
计算待测生物样品的特征
s93、计算待测生物样品与特征模板
其中,n为选取的待测生物样品的特征点个数;
s94、计算待测生物样品与其中一个生物样品的基质效应值k的相似度为
s95、重复步骤s91-s94,获得待测生物样品与多种生物样品的基质效应值数据库中所有k个生物样品的相似度,取其中最大者
作为本发明的一种技术优化方案,所述s10中还包括设δ为相似度阈值,若smax>δ,则判断待测生物样品与多种生物样品的基质效应值数据库中的基质效应值k′相匹配。
综上所述,本发明取多种生物样品的基质效应值构建神经网络模型,再使用训练数据基于初始正则化参数来训练神经网络模型,使用测试数据来测试经训练的神经网络模型,以确定经训练的神经网络模型的针对测试数据的损失函数,然后通过损失函数调整初始正则化参数,使用训练数据基于经调整的正则化参数来再训练神经网络模型,直至收敛到稳定状态,最后提取待测生物样品中的特征数据后与多种生物样品的基质效应值数据库中的每一个生物样品的特征数据进行比对,分析出相似性,获得基质效应值,最后通过生物样品的基质效应值对分析结果进行修正,本发明在构建神经网络模型后又改善了神经网络的准确性,且基于ai算法对特征数据进行比对,分析出相似性,可最大限度地消除基质效应,对生物分析结果进行修正,避免了不同样品基质引起的偏差,保证了结果的准确性,同时降低了检测成本,降低了检测时间,提高了检测效率,更为简单快捷,节约人力和物质成本。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!