一种基于数据增强的蒙汉神经机器翻译方法
本发明属于人工智能技术领域,涉及语言的机器翻译,特别涉及一种基于数据增强的蒙汉神经机器翻译方法。
背景技术:
在应用于蒙汉平行语料库较少的情况,但是数据对于机器翻译领域又是相当重要的前提下,提出一种通过增强原始数据集的方法或者是通过语义树的建立来得到一组新的平行的语句。
技术实现要素:
为了克服上述语料集匮乏对于蒙汉神经机器翻译下的影响,本发明的目的在于提供一种基于数据增强的蒙汉神经机器翻译方法,通过对数据集增强得到一个翻译效果较好的模型。
为了实现上述目的,本发明采用的技术方案是:
一种基于数据增强的蒙汉神经机器翻译方法,包括:
第一步:使用数据增强的方法对现有的蒙汉平行语料库和现有的单语语料库进行数据增强,得到蒙汉伪平行语料库c1和伪汉语单语语料库h1;
第二步:将得到的蒙汉伪平行语料库c1和伪汉语单语语料库h1分别进行筛选得到更高质量的蒙汉伪平行语料库c2和伪汉语单语语料库h2,用于优化模型;
第三步:构建三个蒙汉翻译模型t1、t2、t3;
第四步:利用t1、t2、t3分别对蒙语单语语句翻译,每个翻译模型学习另外两个翻译模型学习到的特征,实现模型优化过程,得到模型t;
第五步:利用蒙汉伪平行语料库c2和伪汉语单语语料库h2得到新的loss值,将模型t进行优化;
第六步:利用优化得到的模型进行蒙汉翻译。
所述第一步中,进行数据增强方法为:
(1)通过改变句子达到扩充蒙汉平行语料库的目的,将原有的语句设为变量s={x1,x2,x3…xn},对句子原有的词语进行替换、删减以及改变位置的操作,对原有的语句进行扩充,得到蒙汉伪平行语料库a1,其中xn代表的是语句的每一个词语,n是语句中词的位置;
(2)通过对上下文词语的预测对当前的蒙汉平行语料库中的汉语进行词语的替换得到蒙汉伪平行语料库a2;
(3)利用对抗神经网络训练一个生成器和鉴别器,鉴别器利用翻译效果不好的蒙汉语句对,进行进一步的训练得到一个可以针对训练效果较差的语句进行翻译的生成器,对训练效果较差的语句进行进一步充分的学习,从而得到蒙汉伪平行语料库a3,其中所述训练效果较差的语句指当前的语句对在模型中的loss值依然高于设定值;
(4)利用数据训练一个蒙语的图片描述模型和一个汉语图片描述模型,得到模型后对同一个图片的描述将得到蒙汉伪平行语料库a4;
(5)通过预训练的bert模型进行微调对蒙汉翻译中的遮蔽词语进行预测,得到新的蒙汉伪平行语料库a5;
(6)利用字典得到蒙汉对应的词语,使用语义树将词语进行组合,得到蒙汉伪平行语料库a6;
将上述(1)~(6)得到的蒙汉伪平行语料库a1~a6放入到同一个文件中,整合为伪平行语料库c1;
(7)利用现在有的英汉和汉英翻译的模型将汉语单语由汉语翻译到英语再翻译到汉语得到伪汉语单语语料库h1。
所述第二步中,利用lstm建立语言模型和利用对抗神经网络生成的鉴别器来对语料进行挑选,其中,利用语言模型对蒙汉伪平行语料库c1和伪汉语单语语料库h1中的语句进行ppl值的测评,设定阈值,将ppl值低于阈值的语句留在文件中得到蒙汉伪平行语料库c2和伪汉语单语语料库h2。
所述第三步中,将现有的蒙汉平行语料库分为三份,得到蒙汉平行语料库c2、c3和c4,分别利用c2、c3和c4通过如下方法得到蒙汉翻译模型t1、t2、t3:
采用基于rnn神经网络的编码器和解码器,由上一时刻隐状态和当前时刻输入进行隐状态更新,得到每一个字的隐含层输出,公式为:h(t)=f(h<t-1>,xt);汇总所有的隐含层输出得到源语言中间隐含层变量ht的汇总c,c=q(h1,h2,h3,...,htx),其中q()表示汇总函数,即将中间变量进行排列,htx表示最后一个输入量;解码器输出为p(yi∣y1,...,yi-1,x)=g(yi-1,si,ci),yi表示输出结点的结果,g()是softmax函数;x表示输入的句子,si是i时刻解码器的隐藏状态,si=f(si-1,yi-1,ci);f()表示经由上一个状态来得到当前状态的函数;ci是编码器-译码器中的上下文向量,h(t)代表t时刻的隐含层的输入,ht代表每一层隐藏层,h<t-1>代表上一个时刻隐含层的数值,xt是t时刻的输入层的数值,yi是i序列得到的输出的值,tx是输入为x时的隐含层数值;
ci是一个变化信息,代表输入句子的表征,不同时刻注意力集中在不同的词上面,由输入序列的h1,...,htx产生,每个输入序列hi包含整个序列的信息的同时更多地关注第i个字的上下文信息,
所述第四步中,利用t1、t2、t3分别对蒙语单语语料库m1翻译得到蒙汉伪平行语料库fc1、fc2、fc3,将蒙汉伪平行语料库fc1、fc2、fc3整合得到新的蒙汉伪平行语料库fc4,利用t1、t2、t3继续从蒙汉伪平行语料库fc4中学习得到新的特征,重复k次,直到t1、t2、t3对同一个蒙语单语语料库翻译的效果相同,则认为模型学习到了所有的特征,得到最终的翻译模型t。
所述第五步中,将模型t对蒙汉伪平行语料库c2进行翻译得到的语句与蒙汉伪平行语料库c2对应的语句进行熵的对比得出loss1,对模型t进行修正,利用模型t对蒙语单语语料库m1和伪汉语单语语料库h1翻译的结果的熵最小的特性,得出loss2,结合loss1和loss2对模型t进行修正,公式如下:
loss1=pmodel(y|x;θ)+h(augment(y),pmodel(x;θ))
计算总的loss值:
loss=minloss1+loss2
其中,x代表输入的源语言,y是通过翻译模型得到的预测的效果,θ是翻译模型的参数,pmodel代表翻译模型t,h()代表交叉熵,augument()代表进行了数据增强。
与现有技术相比,本发明的有益效果是:
1.可以在较少的平行语料库的情况下可以达到较好的翻译的效果。
2.在对数据进行位置的标注之后可以达到的效果是对数据的二义性可以得到很好的处理。
3.利用语言树模型对单语言数据库进行处理,进行数据的扩充使得可以增加平行语料库的大小。
4.使用多层的cnn模型可以使对多层数据的信息进行更多的查找而且cnn具有并行的效果可以达到提高运行速度的效果。
5.利用多层的loss进行对模型的修正达到了对单语语料库的应用。
附图说明
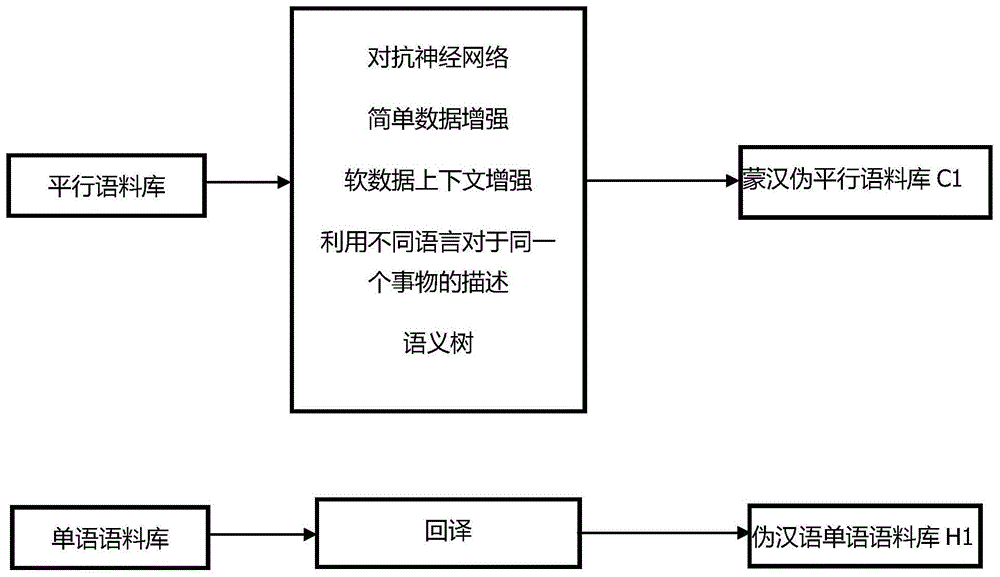
图1是生成蒙汉伪平行语料库c1和伪汉语单语语料库h1的过程。
图2是训练得到三个蒙汉翻译模型t1、t2、t3的过程。
图3是蒙汉翻译模型t1、t2、t3之间互相学习的过程。
图4是利用蒙汉伪平行语料库c2和伪汉语单语语料库h2对模型t进行优化的过程。
具体实施方式
下面结合附图和实施例详细说明本发明的实施方式。
本发明为一种基于数据增强的蒙汉神经机器翻译方法,利用数据增强的方式对原始的平行语料库进行数据增强形成伪平行语料库,对单语语料库进行数据增强形成伪单语语料库用来对模型进行优化,使得模型可以更好地提升翻译的效果。然后利用卷积神经网络与自注意力机制的结合搭建一个翻译模型,和利用区块学习搭建一个翻译模型通过两个翻译模型学习到的特征学习不同进行互补学习得到一个新的翻译模型,利用对双语伪平行语料的学习和单语伪语料的利用来达到对模型优化的目的。
本发明主要包括如下步骤:
第一步:使用数据增强的方法对现有的蒙汉平行语料库和现有的单语语料库进行数据增强,得到蒙汉伪平行语料库c1和伪汉语单语语料库h1,此步骤的目的是对数据进行一步的扩充。
如图1所示,本发明进行数据增强方法为:
(1)通过改变句子达到扩充蒙汉平行语料库的目的,将原有的语句设为变量s={x1,x2,x3…xn},对句子原有的词语进行替换、删减以及改变位置的操作,对原有的语句进行扩充,得到蒙汉伪平行语料库a1,其中xn代表的是语句的每一个词语,n是语句中词的位置;
(2)通过对上下文词语的预测对当前的蒙汉平行语料库中的汉语进行词语的替换得到蒙汉伪平行语料库a2;
(3)利用对抗神经网络训练一个生成器和鉴别器,鉴别器利用翻译效果不好的蒙汉语句对,进行进一步的训练得到一个可以针对训练效果较差的语句进行翻译的生成器,对训练效果较差的语句进行进一步充分的学习,从而得到蒙汉伪平行语料库a3,其中所述训练效果较差的语句指当前的语句对在模型中的loss值依然高于设定值;
此处,训练鉴别器是为了更加符合模型需求,所生成的语句是为了更好地弥补训练所缺少的语句。因此,训练时将鉴别器的分为多个类,鉴别器的判定不再是对与错,而是鉴别到某一类上。
本发明鉴别器使用的是基于多头注意力机制和编码器的组合,在使用多头注意力的情况下,将会训练两个鉴别器,对数据进行进一步的细化,其中一个鉴别器用来判断数据类型的分类,另一个鉴别器用来进行翻译语句的比对,以实现快速比对。
本发明在训练鉴别器时,不同于现有的数据标签,而是对鉴别器的句子进行新的预训练,提取句子关键的语句信息,从而达到简化训练的效果。
本发明利用鉴别器将数据鉴别在某几个分类上,然后对分类的内容再进行下一步的鉴别,将类进行细化,可以对训练不好的类进行数据增强,提高模型的翻译的能力。公式为:
min(g)max(d)v(g,d)=ex~pdata(x)[logd(x)]+ez~pz(z)[log(1-d(g(z)))]
本发明可利用汉语单语语料训练一个语言模型,对得到的汉语单语进行判断,将较好的语料添加到语料库,利用生成器对语句进行判断。
(4)利用数据训练一个蒙语的图片描述模型和一个汉语图片描述模型,得到模型后对同一个图片的描述将得到蒙汉伪平行语料库a4;
(5)通过预训练的bert模型进行微调对蒙汉翻译中的遮蔽词语进行预测,得到新的蒙汉伪平行语料库a5;
(6)利用字典得到蒙汉对应的词语,使用语义树将词语进行组合,得到蒙汉伪平行语料库a6;
将上述(1)~(6)得到的蒙汉伪平行语料库a1~a6放入到同一个文件中,即可整合得到蒙汉伪平行语料库c1。
(7)利用现在有的英汉和汉英翻译的模型将汉语单语由汉语翻译到英语再翻译到汉语得到伪汉语单语语料库h1。
第二步:将得到的蒙汉伪平行语料库c1和伪汉语单语语料库h1分别进行筛选得到更高质量的蒙汉伪平行语料库c2和伪汉语单语语料库h2,用于优化模型。
本发明中,利用lstm建立语言模型和利用对抗神经网络生成的鉴别器来对语料进行挑选,其中,利用语言模型对蒙汉伪平行语料库c1和伪汉语单语语料库h1中的语句进行ppl值的测评,设定阈值,将ppl值低于阈值的语句留在文件中得到蒙汉伪平行语料库c2和伪汉语单语语料库h2。
优选地,训练翻译模型之前,将数据转换为one-hot编码时,可以将数据进行向量的扩充,将数据向量的大小增加词性,语义等的向量,在训练之前经过处理之后可以达到的是相同的词语但是拥有不同的含义和其他的不同的内容的可以转换为不同的向量,人工进行的标注或者通过学习得到新的矩阵来达到这个目的。然后利用transformer的编码器对模型进行学习,分别进行双向的学习,对句子的词语,上下文和位置进行学习。
第三步:构建三个蒙汉翻译模型t1、t2、t3,参考图2,具体方法如下:
将现有的蒙汉平行语料库分为三份,得到蒙汉平行语料库c2、c3和c4,分别利用c2、c3和c4通过如下方法得到蒙汉翻译模型t1、t2、t3:
采用基于rnn神经网络的编码器和解码器,由上一时刻隐状态和当前时刻输入进行隐状态更新,得到每一个字的隐含层输出,公式为:h(t)=f(h<t-1>,xt);汇总所有的隐含层输出得到源语言中间隐含层变量ht的汇总c,c=q(h1,h2,h3,...,htx),其中q()表示汇总函数,即将中间变量进行排列,htx表示最后一个输入量;解码器输出为p(yi∣y1,...,yi-1,x)=g(yi-1,si,ci),yi表示输出结点的结果,g()是softmax函数;x表示输入的句子,si是i时刻解码器的隐藏状态,si=f(si-1,yi-1,ci);f()表示经由上一个状态来得到当前状态的函数;ci是编码器-译码器中的上下文向量,h(t)代表t时刻的隐含层的输入,ht代表每一层隐藏层,h<t-1>代表上一个时刻隐含层的数值,xt是t时刻的输入层的数值,yi是i序列得到的输出的值,tx是输入为x时的隐含层数值;
ci是一个变化信息,代表输入句子的表征,不同时刻注意力集中在不同的词上面,由输入序列的h1,...,htx产生,每个输入序列hi包含整个序列的信息的同时更多地关注第i个字的上下文信息,
第四步:利用t1、t2、t3分别对蒙语单语语句翻译,每个翻译模型学习另外两个翻译模型学习到的特征,实现模型优化过程,得到模型t。
参考图3,本步骤中,利用t1、t2、t3分别对蒙语单语语料库m1翻译得到蒙汉伪平行语料库fc1、fc2、fc3,将蒙汉伪平行语料库fc1、fc2、fc3整合得到新的蒙汉伪平行语料库fc4,利用t1、t2、t3继续从蒙汉伪平行语料库fc4中学习得到新的特征,重复k次,直到t1、t2、t3对同一个蒙语单语语料库翻译的效果相同,则认为模型学习到了所有的特征,得到最终的翻译模型t。
此步骤中,通过构建一个相互学习的翻译模型,利用翻译模型相互学习其他模型学习到特征,来优化自己的翻译模型。
第五步:利用蒙汉伪平行语料库c2和伪汉语单语语料库h2得到新的loss值,将模型t进行优化。
参考图4,本步骤中,将模型t对蒙汉伪平行语料库c2进行翻译得到的语句与蒙汉伪平行语料库c2对应的语句进行熵的对比得出loss1,对模型t进行修正,利用模型t对蒙语单语语料库m1和伪汉语单语语料库h1翻译的结果的熵最小的特性,得出loss2,结合loss1和loss2对模型t进行修正,公式如下:
loss1=pmodel(y|x;θ)+h(augment(y),pmodel(x;θ))
即,loss1的获取是通过翻译模型t对输入语句的翻译结果与蒙汉伪平行语料库c2的目标语言进行交叉熵的求解加上翻译结果的最小熵得到loss1,loss2是保证对同一个单语语句增强后,翻译结果的交叉熵应该最小得到loss2。
计算总的loss值:
loss=minloss1+loss2
其中,x代表输入的源语言,y是通过翻译模型得到的预测的效果,θ是翻译模型的参数,pmodel代表翻译模型t,h()代表交叉熵,augument()代表进行了数据增强。
loss1和loss2是同时获取的关系,利用现在的已有的翻译模型t对蒙汉伪平行语料库c2求loss1,利用翻译模型t对伪汉语单语语料库h2求loss2,经过让二者之和loss最小化的过程,优化翻译模型t,经过迭代得到最终模型。
即,此步骤中,通过对伪平行语料库翻译得到的损失函数值和对伪单语语料库翻译得到的损失函函数值进行相加,对模型t进行优化。
第六步:利用优化得到的模型进行蒙汉翻译。
综上,深度学习的机器翻译容易饱和而对偶学习的挖掘可以进行更加深沉的挖掘,初始模型比较弱。本发明使用数据增强的方法,通过对双语和单语数据的使用充分的挖掘了数据集的信息,可以得到对数据较好的使用。同时实验发现,数据增强之后的模型学习更不容易饱和,因为无标签的单语数据非常丰富、非常多样化,因此通过不断调节单语数据源和调整反馈信息,可以持续提高模型的有效性。相反,使用双语语料比较容易饱和,过几遍数据以后,当信息被挖掘得足够充分,想要再提升模型精度就变得非常困难。
因此,本发明可降低对大数据的依赖性,使得数据的标记数据减少,使得数据的利用率更大。
- 还没有人留言评论。精彩留言会获得点赞!