一种基于径向树结构的可视化分析方法与流程
1.本发明涉及司法文书管理技术,特别涉及一种基于径向树结构的可视化分析方法。
背景技术:
2.一份结构完整、要素齐全、逻辑严谨的裁判文书,既是当事人享有权利和负担义务的凭证,也是上级人民法院监督下级人民法院民事审判活动的重要依据。为此,获取裁判文书的关键要素是辅助法律工作者的重要需求。对于裁判文书的关键要素,可以按照涉案人员、司法案件、涉案物品(又简称为“人”、“案”、“物”)三种实体要素进行划分。由于裁判文书中“人案物”的实体元素和关系复杂繁多,为了实现对裁判文书的“人案物”间复杂繁多的关系的梳理,使法律工作者能快速定位和分析到裁判文书中的关键要素,可采用可视化布局,将抽象的文字逻辑转化成更利于查看和理解的图像形式实现的方式对“人案物”的实体和实体间关系进行清晰化展示。
3.为了实现此种布局,技术中需要实现三元组特征抽取、关键三元组过滤、三元组可视化几部分,以法律文书“人案物”要素的知识图谱并加以可视化实现,从而对文书中的“人”、“案”、“物”进行数据展示和关联分析,以此来解决查看裁判文书中存在的重要信息挖掘成本较大、信息呈现方式单一、信息的理解和分析的时间和人力成本较高的问题。
4.由于单篇裁判文书中已包含较为丰富和复杂的“人案物”要素和关联关系,因此当根据搜索需求,需要结合多种案由或多篇文书进行分析和对比时,分析和展示的成本将进一步增大,因此需要以合理的方式对多篇文书中不同的“人案物”关系形成的知识图谱进行组合和划分,从而过滤出各篇文书中关键且具有代表性,同时在各类文书中相似且同等重要从而利于对比的关键三元组。
5.对此,为了在多案由、多文书的情况下能够展示出实体关联,本技术将基于径向树结构实现可视化分析,即对在提取到各篇文书的三元组后,过滤出对分析价值较高的三元组,并结合数据的语义逻辑形成树形数据结构进行分析和管理,从而保证了同一树分支上三元组语义逻辑同类,同一树深度层次上语义逻辑等级相同,并通过径向树布局加以展示。
6.技术采用的径向树是一种树布局算法,适用于任何类型的逻辑示意图。此布局算法会对逻辑示意图要素进行等级排列,并根据指定的半径参数将它们置于径向树中。在此技术中,逻辑示意图来源于经过数据处理中过滤得到的关键三元组树形结构。径向树布局算法实现可通过从直角坐标系转化为图坐标系的方式进行实现,在设定了一个用作圆心的根交汇点后,将数据结构对应为树结构,并围绕根交汇点为圆心的上圆排列子树进行布局。因此径向树布局算法在保留树的结构的同时,根据树的叶子节点的深度,从常规树结构的水平层数转换为围绕跟交汇点的圆形层数。
7.通过查阅知识图谱等大规模数据网络可视化的相关文献可知,如何解决大规模数据的图结构难以阅读和分析的问题是研究的热点,主要方式可分为多页面划分、聚类同种类节点或边、对图结构进行约束等。现有的对大规模图结构进行可视化分析的优化布局方
式主要集中于处理社群关系、电商平台、电影推荐等领域,对司法领域的研究相对较少。由于单案由的单篇裁判文书进行分析已可以获取一定规模的包含“人案物”实体和实体关系的三元组,因此当案由数量、裁判文书数量增加时,如何凸显各篇文书本身的关键信息和独特性,同时挖掘到各篇文书之间的相同和不同形成对比分析,并转化成利于法律工作者查看和分析的可视化图像成为一个新的难点。
技术实现要素:
8.本发明的目的在于提供一种基于径向树结构的可视化分析方法,用于解决上述现有技术的问题。
9.本发明一种基于径向树结构的可视化分析方法,其中,包括:数据处理以及可视化处理;数据处理包括:步骤1:对所分析的每一篇文书,调用文书分割模板,利用正则表达式匹配并分割出基本文书结构,对每部分使用正则表达式匹配、命名实体识别和依存句法分析,提取出每部分对应的三元组,并将三元组以txt文件和json文件的方式进行存储,并以文书案号和罪名作为文件名;步骤2:通过对得到的各篇三元组文件进行正则匹配,提取匹配到读取的每篇文书的关键部分及各部分含有关键信息的三元组;步骤3:提取的部分将采用树形结构重新存储于json文件中,当分析多篇文书时,将各篇文书的关键三元组存储进json文件中;步骤4:生成多文书查询json文件,为本次查询设查询id并作为跟节点存储的数据结构;对于可视化处理包括:利用g2.js对进行了数据处理的数据,进行具有web前端可视化实现功能的可视化系统中的可视化实现。
10.根据本发明所述的基于径向树结构的可视化分析方法的一实施例,其中,基本文书结构包括文书头部、指控内容、辩护意见、证据证实、综合评判、文书尾部部分。
11.根据本发明所述的基于径向树结构的可视化分析方法的一实施例,其中,对于可视化处理具体包括:页面设置步骤:页面设置中为可视化的展示设置web页面的基本属性;json文件读取,在数据分析中已提取了关键的三元组并形成了相应的json文件,作为可视化的数据输入;创建径向树布局,创建径向树图表并设置径向树图表的基本属性;绘制径向树的边,对径向树中的边创建连线,并从连线的样式和数据间的关系对径向树的边进行设定;绘制径向树的叶子节点,对径向树中的叶子节点创建圆形节点,并从圆形节点的样式和数据的实体属性对径向树的叶子节点进行设定;增加交互事件;根据可视化效果可对径向树图表中的参数进行调整优化。
12.根据本发明所述的基于径向树结构的可视化分析方法的一实施例,其中,创建径向树布局包括:使用g2.chart()创建图表,使用g2.chart()函数创建并初始化定义chart变量,作为可视化实现的图表;定义chart标签,通过定义chart标签的相关属性设置图表的大小、边界、数据类型和展示方式相关属性;指定chart坐标,根据径向树图的表达方式,需将图表的坐标系指定为极坐标系,并设置极坐标的度量定义数据的类型和展示方式。
13.根据本发明所述的基于径向树结构的可视化分析方法的一实施例,其中,绘制径向树的边具体包括:设定连线的指向,连线代表了对数据关系的展示,根据数据间的关系指定边的来源起点和目标终点属性;设定连线的样式的属性,连线的样式的属性设定包括边的位置、形状、颜色、透明度和边信息。
14.根据本发明所述的基于径向树结构的可视化分析方法的一实施例,其中,设定连
线的样式的属性具体包括:根据坐标系的度量和数据关系指定边的位置;设计边的形状;设计边的颜色;设计边的透明度;设计边的边信息。
15.根据本发明所述的基于径向树结构的可视化分析方法的一实施例,其中,绘制径向树的叶子节点包括:设定圆形节点的数据属性,节点代表了叶子节点的数据属性,根据叶子节点的数据属性指定节点实现时的深度、名称、有无孩子节点、值信息;设定圆形节点的样式属性,圆形节点的样式的属性设定包括圆形节点的位置、颜色以及标签显示信息。
16.根据本发明所述的基于径向树结构的可视化分析方法的一实施例,其中,设定圆形节点的样式属性包括:根据坐标系的度量指定节点的位置;设计节点的颜色;设计节点的标签,设计标签对应的数据和相关显示属性,实现节点对应数据的文字标签的显示。
17.根据本发明所述的基于径向树结构的可视化分析方法的一实施例,其中,增加交互事件包括:增加文字提示框实现;增加图表放在实现;增加高亮显示的实现;增加节点展开的实现。
18.本发明实现了通用搜索情况下的径向图布局方案和特殊情况下的径向树布局调整方法。在径向树布局的数据结构为树结构,形成的布局效果为圆形布局。此径向树布局中,节点间的连线实现了树的边结构,展现出数据的间的联系,叶子节点分布在以根交汇点为圆心的同心圆上,体现了数据的层次关系。在径向树布局可视化实现中,用户可沿径向树形成的圆形布局的半径方向,逐层获取同一类型文书在不同层次结构下的具体数据(罪名、具体文书、关键三元组分类及分类下的具体三元组内容);同时为了对比不同文书在相同数据结构下的区别,用户可根据节点颜色确认处于同一数据结构层次(即围绕代表搜索条件的根交汇点的圆形层次,其等价于常规树形结构的深度层次)的具体三元组内容,进行跨案由跨文书的数据分析。
附图说明
19.图1为数据分析流程图;
20.图2为json的树状结构;
21.图3为进行数据分析并存为json树结构的数据处理流程图;
22.图4为径向树布局示意图;
23.图5为径向树布局可视化实现流程图。
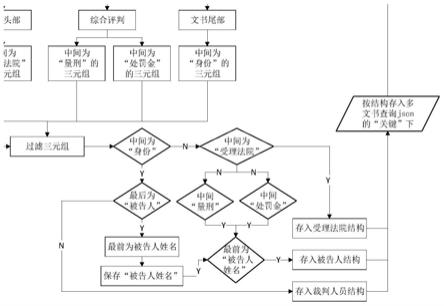
具体实施方式
24.为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
25.本发明提供了一种基于径向树结构的可视化分析方法包括数据处理(抽取三元组并进行过滤、分类和结构化)和可视化实现(采用径向树布局)部分。
26.本发明主要设计一种基于数据分析技术、antv的g2.js技术从而实现web前端可视化实现的可视化系统,包括:
27.1.数据处理部分
28.数据处理主要利用数据分析技术对各篇文书进行三元组的抽取、过滤、分类和结构化,并生成相应的json文件。对各篇文书的数据处理具体实现步骤如下:
29.图1为数据分析流程图,如图1所示,
30.步骤1:单篇文书的三元组的抽取和对应文件生成。对所分析的每一篇文书,调用文书分割模板,利用正则表达式匹配并分割出如下基本文书结构:文书头部、指控内容、辩护意见、证据证实、综合评判、文书尾部部分。对每部分使用正则表达式匹配、命名实体识别和依存句法分析,提取出各部分对应的三元组,并将三元组以txt文件和json文件的方式进行存储,并以文书案号和罪名作为文件名(如“文书案号_罪名.txt”、“文书案号_罪名.json”)。txt文本和json文件中采用“文书案号+罪名——文书结构——对应部分所提取的三元组”的结构进行存储。
31.步骤2:各篇文书关键三元组过滤提取。通过对得到的各篇三元组文件进行正则匹配,匹配到读取的每篇文书的关键部分(文书头部、综合评判、文书尾部)及各部分含有关键信息的三元组。各关键部分提取的关键三元组如下:
[0032][0033][0034]
表1关键三元组内容
[0035]
步骤3:提取的部分将采用树形结构重新存储于json文件中。当分析多篇文书时,将各篇文书的关键三元组存储进json文件中。json文件使用树形结构,其结构如下:
[0036]
图2为json的树状结构,如图2所示,
[0037]
步骤4:生成多文书查询json文件。为该次查询设查询id并作为跟节点存储上述数据结构。其中第3层“详细”存有步骤1中提取的三元组,可用“基于多维联动的可视化分析技术”实现可视化。第3层“关键”存有后提取的关键三元组,将用本技术实现基于径向树结构布局的可视化。
[0038]
根据搜索条件对各篇文书进行数据处理部分的数据分析并存为json树结构全过程流程示意图如下:
[0039]
图3为进行数据分析并存为json树结构的数据处理流程图,如图3所示,
[0040]
2.可视化实现部分
[0041]
可视化实现部分主要利用g2.js技术,对上一部分进行了预处理和数据分析的数据,进行具有web前端可视化实现功能的可视化系统中的可视化实现。
[0042]
径向树布局的可视化实现的具体步骤如下:
[0043]
图4为径向树布局示意图,如图4所示,
[0044]
步骤1:页面设置。页面设置中需要为可视化的展示设置web页面的基本属性,如加载的资源,解析和渲染的方式等。
[0045]
步骤2:json文件读取。在数据分析中已提取了关键的三元组并形成了相应的json文件,可作为可视化的数据输入。为了控制在页面上显示的节点密度,也可选择进一步简化json,即将原json中的第3层及以下内容简化为原第3层“关键”下的第四层的结构和内容。
通过fetch()方法作为获取资源的接口,为图表指定了数据源为层次结构且布局方式为树结构,实现了json文件的数据获取、http的访问和操纵和web请求和处理响应的进行。
[0046]
步骤3:创建径向树布局。为了进行径向树布局可视化,需要创建径向树图表并设置径向树图表的基本属性。
[0047]
步骤3.1:使用g2.chart()创建图表。使用g2.chart()函数创建并初始化定义chart变量,作为可视化实现的图表。
[0048]
步骤3.2:定义chart标签。通过定义chart标签的相关属性设置图表的大小、边界、数据类型和展示方式等相关属性。
[0049]
步骤3.3:指定chart坐标。根据径向树图的表达方式,需将图表的坐标系指定为极坐标系,并设置极坐标的度量定义数据的类型和展示方式。
[0050]
步骤4:绘制径向树的边。对径向树中的边创建连线,并从连线的样式和数据间的关系对径向树的边进行设定。
[0051]
步骤4.1:设定连线的指向。连线代表了对数据关系的展示,因此根据数据间的关系指定边的来源起点和目标终点等属性。
[0052]
步骤4.2:设定连线的样式的属性。连线的样式的属性设定包括边的位置、形状、颜色、透明度和边信息等。
[0053]
步骤4.2.1:根据坐标系的度量和数据关系指定边的位置。
[0054]
步骤4.2.2:设计边的形状,如“smooth”,美化边的形状。
[0055]
步骤4.2.3:设计边的颜色,如“grey”,降低边密集时的颜色堆积。
[0056]
步骤4.2.4:设计边的透明度,如“0.5”,降低边对文字标签的遮盖效果。
[0057]
步骤4.2.5:设计边的边信息,用于鼠标事件等的调用。
[0058]
步骤5:绘制径向树的叶子节点。对径向树中的叶子节点创建圆形节点,并从圆形节点的样式和数据的实体属性对径向树的叶子节点进行设定。
[0059]
步骤5.1:设定圆形节点的数据属性。节点代表了叶子节点的数据属性,因此根据叶子节点的数据属性指定节点实现时的深度、名称、有无孩子节点、值信息等属性。
[0060]
步骤5.2:设定圆形节点的样式属性。圆形节点的样式的属性设定包括圆形节点的位置、颜色、标签显示信息等。
[0061]
步骤5.2.1:根据坐标系的度量指定节点的位置。
[0062]
步骤5.2.2:设计节点的颜色,如指定为对应于叶子节点深度的颜色,使观察者能根据颜色区别和判断叶子节点的深度。
[0063]
步骤5.2.3:设计节点的标签,设计标签对应的数据和相关显示属性,实现节点对应数据的文字标签的显示,并可用于鼠标事件等的调用。
[0064]
步骤6:增加交互事件。增加交互时间,实现文字提示框、图表放缩、高亮显示、节点展开等用户交互操作。
[0065]
步骤6.1:增加文字提示框实现。通过对tooltip的设计实现鼠标在chart上移动时显示提示信息(如:边的边信息、叶子节点的值信息)。
[0066]
步骤6.2:增加图表放在实现。利用g2的view
‑
zoom实现图表的放缩。
[0067]
步骤6.3:增加高亮显示的实现。利用g2的element
‑
active,实现鼠标移入图表元素(如叶子节点)时触发active,实现叶子节点的高亮显示。
[0068]
步骤6.4:增加节点展开的实现。增加节点事件,事件中包含鼠标触发、开关函数的调用。开关函数根据判断节点代表的叶子节点有无孩子,决定节点的隐藏或展示。
[0069]
步骤7:实现展示并进行检验。使用chart.render()调用设计的图表并进行展示。后续可根据可视化效果可对径向树图表中的参数进行调整优化。
[0070]
图5为径向树布局可视化实现流程图,如图5所示,
[0071]
本发明采用径向树布局算法,实现对多案由的多篇文书的数据分析展示。为了实现该技术,需要采用数据分析技术、antv的g2.js技术,通过数据分析部分和可视化实现部分设计一款通过web前端展示可视化结果的可视化系统。
[0072]
对于数据分析技术,由于裁判文书具有相识的文书结构,因此可以实现从案由、文书结构的分类。考虑到多篇文书时三元组过多的情况,为了突出各篇文书的关键信息,并利于文书间关键信息的比较,需对经过正则表达式匹配、命名实体识别和依存句法分析的算法提取三元组,并对所提取的各篇文书的三元组进行过滤,提取出各类案由通用且能展示各文书的关键信息的三元组,并按符合语义逻辑和文书结构的树形数据结构存为json文件,作为后续可视化实现的数据来源。
[0073]
对于可视化技术,主要依靠web编程技术和g2.js技术。其中主要依靠g2.js中的方法实现径向树的布局算法。在读取数据分析技术得到的json数据文件后,将对数据指定为层次结构中的树结构。为了将一般的树布局转化为径向树布局,需要将坐标系从直角坐标系转化为极坐标系,从而确定径向树的边和叶子节点位置。在对边、叶子节点进行基本信息设置后,为了保证布局效果,需要为用户提供具备区分度的设置,如对文字标签,按叶子深度区分的叶子颜色和文本提示框内容等进行设计。同时增加交互事件,为用户提供文字提示框、图表放缩、高亮显示、节点展开等常用交互方式。
[0074]
本发明实现了通用搜索情况下的径向图布局方案和特殊情况下的径向树布局调整方法。在径向树布局的数据结构为树结构,形成的布局效果为圆形布局。此径向树布局中,节点间的连线实现了树的边结构,展现出数据的间的联系,叶子节点分布在以根交汇点为圆心的同心圆上,体现了数据的层次关系。在径向树布局可视化实现中,用户可沿径向树形成的圆形布局的半径方向,逐层获取同一类型文书在不同层次结构下的具体数据(罪名、具体文书、关键三元组分类及分类下的具体三元组内容);同时为了对比不同文书在相同数据结构下的区别,用户可根据节点颜色确认处于同一数据结构层次(即围绕代表搜索条件的根交汇点的圆形层次,其等价于常规树形结构的深度层次)的具体三元组内容,进行跨案由跨文书的数据分析。
[0075]
本发明基于知识图谱思想、树形结构和径向树布局实现径向树布局可视化;为了保证可视化的效果,将径向树将主要展现各文书的抽取的关键三元组,从而很好地实现分层次展示“人案物”数据实体和实体关系,解决对大规模“人案物”数据可视化实现时难以呈现、难以分析以及数据关联过于繁杂的问题。
[0076]
本方法侧重与对多案由多篇文书的各篇文书关键信息的展示和和跨案由跨文书的同类别不同文书下的关键信息对比分析。同时通过径向树形成的圆形布局方式,在保证信息显示的效果的同时提高了web页面可视化时显示空间的利用率。
[0077]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形
也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1