一种自适应调整激活量化位宽的方法与流程
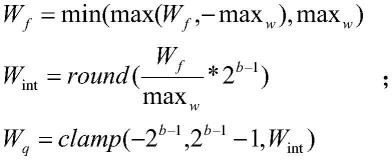
1.本发明涉及卷积神经网络加速技术领域,特别涉及一种自适应调整激活量化位宽的方法。
背景技术:
2.近年来,随着科技的飞速发展,大数据时代已经到来。深度学习以深度神经网络(dnn)作为模型,在许多人工智能的关键领域取得了十分显著的成果,如图像识别、增强学习、语义分析等。卷积神经网络(cnn)作为一种典型的dnn结构,能有效提取出图像的隐层特征,并对图像进行准确分类,在近几年的图像识别和检测领域得到了广泛的应用。
3.现有的量化模型方法中,将模型的层都会量化到一样的位宽,或者手动调整模型某一层的量化位宽。
4.然而,神经网络模型中不同层量化的到不同的位宽时精度损失是不一样的,当将整个模型量化到一样的位宽可能会出现整体量化位宽降不下来,或者模型的收敛效果不理想,无法达到最佳的加速比。
5.现有技术中常用的技术术语包括:
6.卷积神经网络(convolutional neural networks,cnn):是一类包含卷积计算且具有深度结构的前馈神经网络。
7.量化:量化指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。
8.低比特:将数据量化为位宽为8bit,4bit或者2bit的数据。
9.simd全称single instruction multiple data,单指令多数据流。是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在图像处理过程中,由于图像的数据常用的数据类型是rgb565,rgba8888,yuv422等格式,这些格式的数据特点是一个像素点的一个分量总是用小于等于8bit的数据表示的。如果使用传统的处理器做计算,虽然处理器的寄存器是32位或是64位的,处理这些数据却只能用于他们的低8位,效率太低。如果把64位寄存器拆成8个8位寄存器就能同时完成8个操作,计算效率提升了8倍。这就是simd指令的核心思想。
技术实现要素:
10.为了解决上述问题,本方法的目的在于,克服上述现有技术中存在的缺陷,解决量化后模型无法达到最佳加速比和精度的问题。
11.具体地,本发明提出一种自适应调整激活量化位宽的方法,所述方法包括以下步骤:
12.s1,数据量化:对于待量化的数据进行量化,得到低比特的数据;
13.s2,在训练低比特模型时传给下一层的数据,对于激活采用relu6模型,量化后卷积,其结果为:
[0014][0015]
这个等式是为了阐述conv(w
sqf
,f
uqf
)和conv(wq,fq)之间的关系,其中wb,fb分别为权重和feature map的量化位宽,w
sqf
是权重数据量化到低比特并归一化到[-1到1]的数据,f
uqf
是量化到底比特并归一化到[-1到1]的数据,wq,fq分别为权重和feature map量化到低比特的数据;
[0016]
s3,在推理的时候,在不改变权重通道的情况下,减小激活的位宽能够减小卷积累加结果超过16bit的情况,如果conv(w
sqf
,f
uqf
)》1.0就减小激活的量化位宽直至满足conv(w
sqf
,f
uqf
)≤1.0;并且对该层的每一个输出通道作相同的操作,从而达到根据每个通道的分布情况来决定其相应的位宽。
[0017]
所述步骤s1中包括:
[0018]
1),有符号数据量化:
[0019][0020]
2),无符号数据量化:
[0021][0022]
变量说明:wf为全精度数据是一个数组,wq为模拟量化后的数据,maxw为全精度数据wf中最大值,b为量化后的位宽。
[0023]
所述步骤s2中,所述传给下一层的数据为:
[0024]
如果有符号
[0025]
如果无符号。
[0026]
所述relu6的公式如下:
[0027]
relu6(x)=min(max(x,0),6)∈[0,6]。
[0028]
所述步骤s3中,采用simd加速的方式来加速卷积的运算。
[0029]
所述步骤s3中的操作可以在模型训练中完成,即在训练模型时第n步时conv(w
sqf
,f
uqf
)》1.0则第n+1步fb
n+1
=fb
n-1,若第n步时conv(w
sqf
,f
uqf
)≤1.0则第n+1步fb
n+1
=fbn。
[0030]
所述方法进行全精度模型训练。
[0031]
由此,本技术的优势在于:通过调整激活的位宽来减小卷积的累加结果,从而将累加和压缩到16bit以内,以提高使用simd加速效果。
附图说明
[0032]
此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,并不构成对本发明的限定。
[0033]
图1是本发明方法的流程示意图。
具体实施方式
[0034]
为了能够更清楚地理解本发明的技术内容及优点,现结合附图对本发明进行进一步的详细说明。
[0035]
如图1所示,本发明涉及卷积神经网络在量化时提高模型精度的方法,特别是一种自适应调整激活量化位宽的方法。
[0036]
一种自适应调整激活量化位宽的方法,所述方法包括以下步骤:
[0037]
s1,数据量化:对于待量化的数据进行量化,得到低比特的数据;
[0038]
s2,在训练低比特模型时传给下一层的数据,对于激活采用relu6模型,量化后卷积,其结果为:
[0039][0040]
这个等式是为了阐述conv(w
sqf
,f
uqf
)和conv(wq,fq)之间的关系,其中wb,fb分别为权重和feature map的量化位宽,w
sqf
是权重数据量化到低比特并归一化到[-1到1]的数据,f
uqf
是量化到底比特并归一化到[-1到1]的数据,wq,fq分别为权重和feature map量化到低比特的数据;
[0041]
s3,在推理的时候,在不改变权重通道的情况下,减小激活的位宽能够减小卷积累加结果超过16bit的情况,如果conv(w
sqf
,f
uqf
)》1.0就减小激活的量化位宽直至满足conv(w
sqf
,f
uqf
)≤1.0,这个操作可以在模型训练中完成,即在训练模型时第n步时conv(w
sqf
,f
uqf
)》1.0则第n+1步fb
n+1
=fb
n-1,若第n步时conv(w
sqf
,f
uqf
)≤1.0则第n+1步fb
n+1
=fbn;并且对该层的每一个输出通道作相同的操作,从而达到根据每个通道的分布情况来决定其相应的位宽。换句话,为了提高simd的加速效果,希望在推理时conv(wq,fq)的结果小于16bit,当wb=8,fb=8时由上面等式可以得出需要conv(wq,fq)结果小于16bit则conv(w
sqf
,f
uqf
)的结果必须小于1.0,在不改变wb的情况下可以改变fb的大小来调整conv(w
sqf
,f
uqf
)的结果,从而达到自适应调整激活量化的位宽。
[0042]
具体地,所述方法包括进行全精度模型训练:
[0043]
1.数据量化:对于待量化的数据按照所示的公式进行量化,得到低比特的数据:
[0044]
如以下有符号和无符号量化组成的公式组1所示:
[0045]
有符号数量化:
[0046]
wf=min(max(wf,-maxw),maxw)
[0047][0048]
wq=clamp(-2
b-1
,2
b-1-1,w
int
)
[0049]
无符号量化:
[0050]
wf=min(max(wf,0),maxw)
[0051][0052]
wq=clamp(0,2
b-1,w
int
)
[0053]
变量说明:wf为全精度数据是一个数组,wq为模拟量化后的数据,maxw全精度数据wf中最大值,b为量化后的位宽。
[0054]
2.在训练低比特模型时传给下一层的数据,如公式组2所示:
[0055][0056]
对于激活采用relu6的模型,量化后卷积的结果,如公式3所示:
[0057][0058]
3.由于在推理的时候,采用simid加速的方式来加速卷积的运算,根据simid的特性如果将卷积累加后的结果保存到16bit将会比将累加结果保存到32bit会快一倍,由公式组1和公式3可知在不改变权重通道的情况下,减小激活的位宽可以减小卷积累加结果超过16bit的情况,所以根据公式3,如果conv(w
sqf
,f
uqf
)》1.0就减小激活的量化位宽直至满足conv(w
sqf
,f
uqf
)≤1.0。并且可以对该层的每一个输出通道作相同的操作,从而达到根据每个通道的分布情况来决定其相应的位宽。
[0059]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1