分布式系统中的神经网络训练的制作方法
分布式系统中的神经网络训练
背景技术:
1.人工神经网络是具有基于生物神经网络的架构的计算系统。人工神经网络可包含权重集合。在全部计算中,权重可以与输入数据组合以提取信息,且可以基于所述信息作出决策。举例来说,对于检测对象的计算机视觉应用,人工神经网络可将权重与输入图像组合以从图像提取对象的某些特征。基于所提取特征,人工神经网络可产生对象是否在图像中的决策。
2.可通过训练过程产生/更新人工神经网络的权重集合,在所述训练过程中人工神经网络可学习如何针对应用执行某一计算任务。训练过程涉及为人工神经网络供应训练输入数据,所述训练输入数据可被标记有支持特定决策(例如,检测到或未检测到图像中的对象)的参考输出集合。人工神经网络可执行计算以将权重与训练输入数据组合以产生训练输出数据集合,且可将训练输出数据集合与参考输出数据集合进行比较以产生差集合。在训练期间,可将不同的训练输入数据集合提供到人工神经网络以产生不同的训练输出数据集合。可基于例如使训练输出数据集合与参考输出数据集合之间的差最小化的目的而调整人工神经网络的权重集合。
3.为了改善人工神经网络产生正确决策的可能性,通常使用涵盖大量操作情境的大量训练输入数据来训练人工神经网络。因此,训练操作通常需要大量的时间和计算资源。
附图说明
4.将参考各图描述根据本公开的各种实施例,图中:
5.图1示出使用本文所公开的技术处理数据的分类器装置的实例;
6.图2a-2b是示出根据本公开的某些方面的使用本文所公开的技术的预测模型和计算的简化框图;
7.图3a-3c示出神经网络的训练过程的实例;
8.图4a-4c示出根据本公开的某些方面的在分布式系统中执行神经网络的训练过程的实例;
9.图5a-5e示出用以支持图4a-4c的实例训练过程的计算系统的组件的实例;
10.图6示出根据本公开的某些方面的在分布式系统中执行神经网络的训练过程的实例方法;
11.图7示出可支持图4a-4c的实例训练过程的集成电路装置的实例;
12.图8示出可支持图4a-4c的实例训练过程的主机系统的实例;以及
13.图9包含实例网络的图式。
具体实施方式
14.本公开的实例涉及神经网络处理,且更具体来说,涉及在分布式系统中执行神经网络的训练过程。
15.人工神经网络(下文称为神经网络)通常在计算系统中实施为具有基于生物神经
网络的架构,且以与生物神经网络类似的方式处理输入数据。神经网络通常包含若干级联的神经网络层,其中每一层包含权重集合。在推断操作中,第一神经网络层可接收输入数据集合,将输入数据集合与权重组合(例如,通过将输入数据集合与权重相乘,并且接着将乘积求和)以产生用于神经网络层的第一输出数据集合,且在向前传播操作中将输出数据集合传播到第二神经网络层。第二神经网络层对来自第一神经网络层的第一输出数据集合执行另一向前传播操作以产生第二输出数据集合,且将第二输出数据集合传播到较高神经网络层。向前传播操作可在第一神经网络层处开始且在最高神经网络层处结束。在每一神经网络层处的向前传播操作可表示来自输入数据集合的信息的提取和处理的不同阶段。随后可基于最高神经网络层的输出数据作出决策。举例来说,每一神经网络层可从图像提取和/或处理特征,且可基于在神经网络层处处理所提取特征的结果而产生对象是否在图像中的决策。
16.可通过训练过程产生和/或更新神经网络的权重集合以改善神经网络产生正确决策的可能性。实例训练过程可使用梯度下降方案。具体地,作为训练过程的部分,可使用在每一神经网络层处的权重集合对训练输入数据集合执行向前传播操作,以在最高层级神经网络层处产生训练输出数据集合。可将训练输出数据集合与支持特定决策的参考输出数据集合进行比较。可例如基于训练输出数据集合与参考输出数据集合之间的差产生输入数据梯度的集合。
17.作为训练过程的部分,每一神经网络层可随后执行向后传播过程以调整每一神经网络层处的权重集合。具体地,最高神经网络层可接收输入数据梯度集合,且在向后传播操作中基于在与向前传播操作相似的数学运算中将权重集合应用于输入数据梯度来计算第一数据梯度集合和第一权重梯度集合。最高神经网络层可基于第一权重梯度集合调整层的权重集合,而第一数据梯度集合可传播到第二高的神经网络层以影响前一神经网络层的权重集合的调整。向后传播操作可从最高神经网络层开始且在第一神经网络层处结束。可调整每一神经网络层处的权重集合以完成训练过程的一个迭代。可针对同一输入数据集合重复训练过程若干次迭代,直到实现损失目标(例如,阈值输入数据梯度)。
18.由于训练过程中涉及的操作之间的顺序性质和数据相依性,训练过程通常是极耗时的过程。具体地,如上文所描述,在训练过程中首先在每一神经网络层处执行向前传播操作以计算训练输出数据集合,并且接着基于训练输出数据集合(和参考输出数据集合)计算输入数据梯度,并且接着在每一神经网络层处执行向后传播操作以计算权重梯度,随后是在每一神经网络层处的权重的更新。由于向后传播操作取决于向前传播操作,因此无法并行执行两组操作。此外,由于神经网络层之间的数据相依性,因此还需要针对每一神经网络层循序地执行向前传播操作和向后传播操作。缺乏并行性会大幅度增加训练时间,当对同一输入数据集合执行训练过程的多个迭代以实现损失目标时所述训练时间进一步增加。此外,训练过程通常涉及为神经网络供应多个训练输入数据集合以涵盖不同操作条件,使得可训练神经网络以在那些不同操作条件下提供正确决策。实施神经网络的计算系统将需要执行额外训练过程以处理额外输入数据集合,这将进一步增加训练时间。与训练过程通常需要比推断操作高的精度的事实结合,缓慢的训练过程会给计算资源带来很大压力。
19.加速训练过程的一种方式是使用分布式系统以跨越多个计算系统分布训练过程,所述多个计算系统可各自被配置为工作者节点。训练输入数据集合可被分裂成多个部分,
其中每一部分将由工作者节点处理。每一工作者节点可基于训练输入数据的一部分独立地且彼此并行地执行向前和向后传播操作,以产生用于每一神经网络层的权重梯度集合。每一工作者节点可与其它工作者节点交换其权重梯度集合,且将其权重梯度集合和从其它工作者节点接收的权重梯度集合进行平均化。每一计算节点可具有同一平均化权重梯度集合,且可随后基于平均化权重梯度更新用于每一神经网络层的权重集合。
20.跨越多个工作者节点分布训练过程可减少在每一工作者节点处将处理的训练输入数据的量,这可减少在每一神经网络层处的向前和向后传播操作的执行时间且加速训练过程。然而,工作者节点之间的权重梯度的交换会引入实质瓶颈。举例来说,在分布式系统处于云基础结构中且工作者节点通过发送网络包而彼此交换权重梯度的情况下网络时延相对于向前/向后传播操作的执行时间可为实质的。网络时延会削弱由分布式系统带来的训练时间减少,或甚至增加训练时间。
21.本公开的实例涉及神经网络处理,且更具体来说,涉及在分布式系统中执行神经网络的训练过程。在一个实例中,分布式系统包含多个工作者节点。每一工作者节点接收训练输入数据集合的一部分且对相应部分执行向前传播计算以产生输入数据梯度。在输入数据梯度的产生后,每一工作者节点可执行向后传播操作以产生数据梯度和权重梯度,且与其它工作者节点交换权重梯度。
22.为了加速训练过程,工作者节点可并行执行一些向后传播操作和权重梯度的交换。具体地,工作者节点可基于输入数据梯度针对较高神经网络层(例如,第二神经网络层)执行向后传播操作以产生第二数据梯度和第二权重梯度,并且接着针对较低神经网络层(例如,第一神经网络层)执行向后传播操作以产生第一数据梯度和第一权重梯度。当针对第一神经网络层的向后传播操作在进行中时,工作者节点也可执行工作者节点之间的第二权重梯度的交换,以及基于交换的第二权重梯度在第二神经网络层处的权重集合的后续更新。因此,用于神经网络层的向后传播操作可与用于较高神经网络层的权重梯度交换和权重更新并行执行。并行性既不影响用于较高神经网络层的权重更新操作也不影响用于较低神经网络层的向后传播操作,因为所述两个操作彼此之间无数据相依性。此外,通过将较高神经网络层的权重梯度交换与较低神经网络层的向后传播操作并行化,而不是将这两个操作串行化,可减小在权重梯度交换期间经历的网络时延的影响,这可进一步加速训练过程。
23.在一些实例中,较低神经网络层的第一权重梯度的交换可相对于较高神经网络层的第二权重梯度的交换优先化。所述优先化可基于例如工作者节点交换第一权重梯度中的至少一些,随后是第二权重梯度中的至少一些,即使在工作者节点处第二权重梯度是在第一权重梯度之前产生也是如此。此类布置可有利于缩短训练时间。具体地,由于数据相依性,用于一个神经网络层的权重梯度的交换和权重的更新必须与在所述神经网络层处的向前传播操作串行化。由于向前传播操作和向后传播操作跨越神经网络层以相反次序执行,因此向后传播操作与向前传播操作之间的时间窗口针对较低层通常比较高层更短。通过将较低神经网络层优先化以首先执行权重梯度的交换,可减小较低神经网络的权重梯度的交换的等待时间。此外,用于较高神经网络层的权重梯度的交换可与较低神经网络层的向前传播并行执行。因此,总体训练时间可减少。
24.在一些实例中,为了支持前述优先化方案,针对每一神经网络节点产生的权重梯度可被分裂成多个部分,其中每一部分与交换任务相关联。包含于交换任务中的权重梯度
的一部分的大小可基于各种因数,包含例如传输权重梯度时的网络效率的预定阈值水平、训练过程完成的目标时间等。每一交换任务包含工作者节点传输权重梯度的相关联部分以及从其它工作者节点中的每一个接收权重梯度的对应部分。交换任务可存储于受仲裁器管理的缓冲器中。缓冲器包含多个条目。每一条目可存储交换任务,以及交换任务的完成状态。缓冲器还包含写入指针和读取指针。写入指针指向用以接收下一交换任务的空条目,而读取指针指向最近存储的交换任务。在一些实例中,缓冲器可被实施为堆栈。在其它实例中,可使用例如队列、链表或其它类型的缓冲器等其它数据结构来存储和管理交换任务。
25.在产生用于较高神经网络层的第二权重梯度之后,工作者节点可将权重梯度分裂为若干部分,且将用于每一部分的第一交换任务集合循序地存储到缓冲器中。由于存储每一第一交换任务,因此还相应地调整读取指针和写入指针。在存储下一交换任务集合之前,工作者节点可开始处理由读取指针指示的最近存储的第一交换任务。在第一交换完成(其中工作者节点已传输第二权重梯度的部分且已从其它工作者节点中的每一个接收第二权重梯度的对应部分)之后,所述条目的完成状态可被标记为完成,且工作者节点可处理第二最近存储的第一交换任务。工作者节点可以与任务的存储反向的次序处理第一交换任务的剩余部分。
26.当工作者节点在处理第一交换任务集合时,工作者节点还可以将与第一权重梯度相关联的第二交换任务集合存储到缓冲器中。因此随后可以基于第二交换任务集合的存储而移动读取指针和写入指针。读取指针可以指向最近存储的第二交换任务。由于新交换任务的存储,因此工作者节点可以在进行中完成第一交换任务,并且接着暂停剩余第一交换任务的处理。工作者节点随后可以开始处理最近存储的第二交换任务。在将下一交换任务集合(用于下一较低层)存储到缓冲器中之前,工作者节点可以在执行向前传播操作的同时处理第二交换任务的剩余部分,随后处理剩余第一交换任务。读取指针可以遵循与任务的存储反向的次序来遍历通过缓冲器。
27.在以上实例中,首先通过将读取指针与写入指针一起移动来处理稍后存储的交换任务。此类布置使得能够将较低神经网络层的交换任务优先于较高神经网络层的那些交换任务,因为较低神经网络层的交换任务通常比较高神经网络层的交换任务更晚产生(且因此更晚存储到缓冲器中)。在一些实例中,读取指针也可受仲裁器控制,所述仲裁器可确定新存储的交换任务的优先级。如果仲裁器确定新存储的交换任务具有最高优先级,那么仲裁器可将读取指针移动到存储高优先级交换任务的条目以首先处理那些任务。
28.通过所描述的技术,在分布式系统中权重梯度的交换操作中的至少一些可与向后传播操作和向前传播操作并行执行,这可进一步加速训练过程。此外,通过使较低神经网络层的权重梯度的交换优先于较高神经网络层,可缩短由最低神经网络层完成权重梯度的交换和权重的更新所花费的时间带来的训练过程的两个迭代之间的等待时间,这可进一步加速训练过程。所有这些可改善训练过程的效率且可减少计算资源上的压力。
29.在下面的描述中,将描述各种实例。出于解释的目的,阐述特定配置和细节以便提供对实例的透彻理解。然而,对于所属领域的技术人员来说还将显而易见的是,可在没有所述具体细节的情况下实践示例。此外,可省略或简化众所周知的特征以免混淆所描述的实施例。
30.图1示出使用本文所公开的技术处理数据的示例分类器装置100。分类器装置100
可以是例如操作软件应用程序102和预测模型103以预测包括在数据序列中的信息并且基于预测执行预定功能的计算装置。例如,分类器装置100可以是被设置成从图像识别某些对象(例如,文字、人等)的图像辨识服务的一部分。应理解,图像辨识服务仅作为说明性实例提供,并且本文所公开的技术可用于其它数据处理应用,包括例如基于文本的数据处理(例如,搜索查询的处理)、音频数据处理等。此外,分类器装置100可操作多个不同预测模型以同时或在不同时间处理不同输入数据。
31.在一些实例中,图像辨识服务可设置在多租户计算服务系统中。多租户计算服务系统通常可包括多个服务器,所述多个服务器可托管数据并且可由多个客户端或组织用于运行实例,例如虚拟机实例或裸机实例(例如,直接在服务器硬件上运行的操作系统)。在大多数情况下,例如裸机或虚拟机实例之类的多租户计算服务系统可在客户端需要它们时分配给客户端,并且在不再被需要时退出,使得可将资源重新分配给其它客户端。在本公开中,术语“租户”、“客户端”和“客户”可互换使用,但此类术语不一定意味着存在任何特定的业务布置。术语“实例”可指例如直接在服务器硬件上运行或作为虚拟机运行的实例。不同类型的实例通常对应于不同硬件功能和/或硬件布置(例如,不同量的可用存储器和/或处理硬件)。在图1的实例中,多租户计算服务系统可在客户端需要时提供图像辨识服务,并且服务不再被需要时被停用,使得支持图像辨识服务的资源(例如,对软件应用程序102的存取和用于处理软件应用程序102的底层硬件资源)可重新分配到其它客户端。不同客户端(或一个客户端)可请求应用程序102使用包括预测模型103的相同或不同预测模型来执行不同输入数据的处理。
32.在图1的实例中,软件应用程序102可从用户接收图像104的像素数据。图像104可包含像素阵列。软件应用程序102可对像素数据执行分析,并且预测图像104中所描绘的一个或多个对象106。所述分析可包含例如将所述像素数据与预定特征数据集合进行比较。预定特征数据可包括与例如鼻子对象、嘴巴对象等预定视觉图像特征集合相关联的数据。预定特征数据还可包含与非视觉图像特征或视觉和非视觉图像特征的组合相关联的数据。如下文将更详细地论述,软件应用程序102可采用预测模型103以基于图像104的像素数据计算得分集合。所述得分集合可表示例如图像104包含由特征数据表示的图像特征的概率。软件应用程序102可接着基于得分确定关于图像104的内容的其它信息。例如,基于得分,软件应用程序102可确定图像104是例如熊猫、猫或其它对象的图像。
33.预测模型103可呈人工神经网络的形式。人工神经网络可包括多个处理节点,其中每个处理节点被配置成处理输入像素数据的部分,或进一步处理来自其它处理节点的中间输出。图1示出使用本文所公开的技术的预测模型103的实例。在图1中,预测模型103可以是多层神经网络,例如深度神经网络(dnn)、卷积神经网络(cnn)等。预测模型103可包含输入层207、包含中间层209和211的中间层集合以及输出层(图2a中未示出)。应理解,预测模型103还可包含其它不同类型的神经网络,包含例如长期存储器(lstm)、多层感知(mtp)、多尺度密集网络(msdnet)等。
34.层207可处理表示图像104的不同部分的像素数据。例如,在图2a的实例中,层207可处理图像204的像素数据。层207的每个处理节点被指定以接收对应于图像104内的预定像素的像素值(例如,x0、x1、x2......xn),并且将具有所接收的像素值的一个或多个权重传输到层209。在预测模型203是dnn的情况下,可对层207的每个处理节点指定基于矩阵w1限
定的权重集合。层207的每个处理节点可将所接收的像素值和所指定的权重发送到层209的每个处理节点。在预测模型103是cnn的情况下,层207的处理节点群组可共享权重集合,并且每个群组可将由处理节点群组接收到的权重集合和像素值发送到层209的单个处理节点。不同神经网络模型可包含不同拓扑(例如,包含不同数目的层、层之间的不同连接等),和/或包含用于每一层的不同权重集合。
35.层209可处理来自层207的按比例缩放的输出以产生中间输出集合。例如,假设层209的处理节点210a连接到层207中的n个处理节点,则处理节点210a可基于以下等式而产生从层207接收的按比例缩放的输出的总和:
[0036][0037]
此处,总和
210a
表示由处理节点210a产生的中间输出。w1i×
xi表示层207的处理节点用相关联权重(例如,w10)对特定像素值(例如,x0)的按比例缩放。在预测模型103是dnn的情况下,层209的每个处理节点可基于来自层207的每个处理节点的像素值的按比例缩放而产生总和,并且接着通过对按比例缩放的像素值进行求和而产生总和(例如,总和
210a
)。所述总和还可表示包括多个元素(例如,像素值)的输入向量与权重向量(例如,w1)之间的点积。在一些实例中,还可将偏置添加到按比例缩放的输出以产生中间输出。
[0038]
在预测模型103是cnn的情况下,层209的每个处理节点可基于来自层207的一组处理节点的像素值的按比例缩放而产生中间输出。中间输出可表示像素值群组与包括权重值的滤波器之间的卷积结果。图2b示出层209可执行的卷积操作的实例。在图2b中,滤波器230可包含权重的二维阵列。滤波器230中的权重可表示待根据图像检测的某些特征的像素的空间分布。二维阵列可具有r行的高度和s列的宽度,并且通常小于具有h像素的高度和w像素的宽度的输入图像。每个权重可映射到呈具有相同r行和s列的像素值的矩形块的像素。层209的处理节点(例如,处理节点210a)可从输入层207的处理节点群组接收对应于来自输入图像的像素的第一矩形块的像素值的群组240,所述像素值的群组240对应于滤波器230的第一步幅位置,并且根据等式1基于滤波器230的每个权重与群组240中的每个对应像素之间的相乘结果的总和而产生卷积输出242,以产生由滤波器230表示的矩阵与由群组240表示的矩阵之间的点积。层209的另一处理节点还可从输入层207的处理节点的另一群组接收像素值的群组244,所述像素值的群组244对应于来自输入图像的对应于滤波器230的第二步幅位置的像素的第二矩形块,并且根据等式1基于滤波器230的每个权重与群组244中的每个对应像素之间的相乘结果的总和而产生卷积输出246,以产生滤波器230的矩阵与由群组240表示的矩阵之间的点积。在一些实例中,图2b中的每个卷积输出(例如,卷积输出242、卷积输出346等)可对应于层209的处理节点的输出。在一些实例中,输入图像中的像素数据可被称为输入特征映射以指示像素由对应于某特征的相同滤波器(或相同滤波器集合)处理。卷积输出可被称为输出特征映射以指示输出是通过滤波器处理输入特征映射的结果。
[0039]
如图2b所示,卷积操作可布置在滑动窗口中以使得第二矩形块与输入图像中的第一矩形块重叠,或以其它方式邻近于输入图像中的第一矩形块。例如,在图2b的实例中,d可以是用于每个卷积操作的滑动窗的步幅(以像素计)的距离,使得对应于群组244的像素块可位于距对应于群组240的像素块的距离d(就像素来说)处,并且像素的下一块也可位于距群组244的相同距离d处。层209的其它处理节点还可接收对应于其它矩形块的像素群组并
且产生其它中间输出。卷积输出可以是卷积输出阵列的部分。卷积输出阵列可具有比输入图像更小的高度和更小的宽度。可进一步对卷积输出的矩形块进行分组,并且可在卷积输出群组与另一组滤波器权重之间的层211处执行卷积操作以产生另一组卷积输出。
[0040]
返回参考图2a,层209的一个处理节点可被配置成产生一个卷积输出阵列的卷积输出元素,并且层209的处理节点的集合m可对应于卷积输出阵列的集合m。层209的处理节点还可处理具有激活函数的每个卷积输出以产生激活输出。激活函数可将卷积输出转换为是否将卷积输出转发到中间层211以影响分类器决策的决策(类似于生物神经元的放电)。激活函数的实例可以是根据以下等式限定的整流线性单元(relu):
[0041][0042]
除了relu之外,还可使用其它形式的激活函数,包含例如软加函数(其可以是relu函数的光滑逼近)、双曲线切线函数(tanh)、弧切线函数(arctan)、s型函数、高斯函数等。
[0043]
层209的处理节点(例如,处理节点210a)可处理与relu函数的和以基于以下等式产生层209的第一输出:
[0044]
第一_输出
210a
=relu(总和
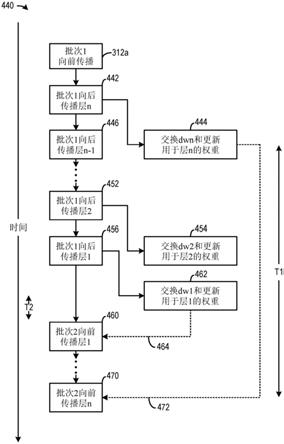
210a
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(等式3)
[0045]
任选地,预测模型103可以包含池化层以减少层209的中间输出(例如,总和
210a
)的数目。池化层可以将中间输出分组且对每一群组执行池化操作。池化操作可包含例如最大池化(例如,选择群组内的最大中间输出)、最小池化(例如,选择最小中间输出)、平均池化(例如,寻找每一群组的平均)、求和池化(寻找每一群组的总和)等,且可通过激活函数处理减少的中间输出以产生层209的第一输出。可执行池化操作以减少与激活函数处理相关联的计算成本。
[0046]
层211可进一步通过例如基于不同组滤波器执行额外卷积操作来处理来自层209的按比例缩放的中间输出。可将来自层211的每个处理节点的输出转发到其它较高中间层,或转发到输出层(图2a中未示出)。输出层可形成表示例如特定特征包含在图像104中的概率和/或图像204包含熊猫的图像的概率的输出向量。例如,可将输出向量与同熊猫的鼻对象相关联的参考向量或与熊猫相关联的参考向量进行比较。可基于比较结果来确定关于图像104是否为熊猫的图像的决策。
[0047]
在图2a和图2b中描述的权重和滤波器系数可由训练过程产生和更新,以改善预测模型103产生正确决策的可能性。参考图2a和图2b的实例,可基于训练图像的集合训练预测模块103。训练图像可包含不同熊猫的图像、其它动物的图像和其它假象等。预测模型103可处理那些图像且产生不同输出向量。预测模型103可更新预测模型103的神经网络层中的权重以最大化正确决策(例如,含有熊猫的训练图像中检测到熊猫、不含有熊猫的训练图像中未检测到熊猫)的数目。
[0048]
图3a示出用以训练神经网络的训练过程300的实例,所述神经网络包含预测模型103的神经网络。训练过程可由例如神经网络硬件加速器执行,所述神经网络硬件加速器实施支持如上文所描述的神经网络处理中涉及的算术操作的神经网络、通用硬件处理器或其它合适的计算系统。训练可基于梯度下降方案,其包含向前传播操作、损失梯度操作和向后传播操作。具体地,如图3a所示,可针对每一神经网络层执行向前传播操作,例如用于最低层1(其可对应于图2a的输入层207)的向前传播操作302a、用于层2(其可对应于图2a的层
209)的向前传播操作302a、用于最高层n(其可对应于图2a的层211)的向前传播操作302n等。在神经网络层处的向前传播操作可包含用于所述层的输入数据和权重集合之间的乘法和求和计算,随后是如上文等式1和2中所描述的激活函数处理,以产生输出数据。输出数据可随后传播到下一神经网络层作为对所述层处的向前传播操作的输入。举例来说,如图3a中所示,向前传播操作302a可组合训练输入数据与层1的w1权重以产生输出数据out1,其传播到层2作为输入。向前传播操作302b可组合数据out1与层2的w2权重以产生输出数据out2,其可随后传播到下一层。在最高层n处,向前传播操作302n接收来自层n-1(图3a中未图示)的数据outn-1,与层n的wn权重组合,且产生输出数据outn。
[0049]
损失梯度操作304可将层n的输出数据outn与参考输出数据refoutn进行比较以产生输入数据梯度din。输入数据梯度din可相对于输出数据outn的每一数据元素测量outn与refoutn之间的差的比率。在一些实例中,训练的目标是最小化outn与refoutn之间的差以使得输入数据梯度din变为接近于零。
[0050]
在通过损失梯度操作304产生输入数据梯度din后,可针对每一神经网络层执行向后传播操作306。举例来说,可在最高层n处执行向后传播操作306n,可在层2处执行向后传播操作306b,可在层1处执行向后传播操作306a。在神经网络层处的向后传播操作可基于神经网络层的权重、对所述神经网络层的数据梯度输入,以及对所述层的向前传播操作的输入。举例来说,针对层n,向后传播操作306n可接收权重wn、输入数据outn-1(来自神经网络层n-1处的向前传播操作)和输入数据梯度din作为输入。向后传播操作可对输入执行与等式1的那些类似的乘法和求和计算以产生输出数据梯度(图3a中的dn-1、d2、d1等)和权重梯度wgrad(图3a中的dwn、dw2、dw1等)。输出数据梯度可转发到下一较低神经网络层作为对所述层中的向后传播操作的输入,而权重梯度可表示将对神经网络层处的权重应用的改变。层n处的权重可通过更新操作308(例如,用于层n的更新操作308n)基于权重梯度dwn基于以下等式来更新:
[0051]
wn
′
=wn-α
×
dwn
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(等式4)
[0052]
在等式4中,wn
′
可以指经更新的权重wn,而α可包含预定常数集合。
[0053]
由层n产生的输出数据梯度dn-1可随后传播到下一较低神经网络层n-1作为对所述层处的向后传播操作的输入。层2的向后传播操作302b可对数据梯度d2、权重w2和输入数据out1操作以产生输出数据梯度d1以及权重梯度dw2。权重梯度dw2可由更新操作308b使用以基于等式4更新w2权重。数据梯度d1可传播到层1。层1的向后传播操作302a可对数据梯度d2、权重w1和训练输入数据操作以产生权重梯度dw1。权重梯度dw1可由更新操作308a使用以基于等式4更新w1权重。
[0054]
训练过程通常涉及为神经网络供应多个训练输入数据集合以涵盖不同操作条件,使得可训练神经网络以在那些不同操作条件下提供正确决策。由于有限的计算资源,计算系统(例如,神经网络硬件加速器)通常缺乏同时使用所有训练输入数据集合执行训练的能力。实际上,训练输入数据可划分成多个部分。计算系统可循序地分批执行训练过程,其中每一批次对训练输入数据的一部分操作。
[0055]
图3b示出训练过程相对于时间的批次的实例310。如图3b所示,可执行批次1训练操作,其包括操作312、314和316。在操作312中,可基于批次1训练输入数据和初始权重在每一神经网络层处执行向前传播操作。且接着在操作314中,可基于操作312的输出在每一神
经网络层处执行向后传播操作,随后是操作316,其中基于来自操作314中的向后传播操作的权重梯度更新每一神经网络层处的权重。在批次1训练操作完成之后,可执行批次2训练操作,其包括操作322、324和326。操作322包含基于批次2训练输入数据和来自批次1训练操作的经更新权重的向前传播操作,操作324包含基于操作322的输出的向后传播操作,随后是操作326,其中基于来自操作324中的向后传播操作的权重梯度进一步更新每一神经网络层处的权重。在批次2的完成后,可对训练输入数据的其它部分执行训练操作的其它批次。也可以多个迭代重复训练操作的批次,直到例如来自损失梯度操作304的输入数据梯度din变为接近于零,其指示训练输出outn与参考输出refout之间的差被最小化。
[0056]
如图3b所示,对单个计算系统执行的训练过程由于训练过程的顺序性质而会是极耗时的。具体地,如上文所描述,在训练过程中首先在每一神经网络层处执行向前传播以计算训练输出数据集合,并且接着基于训练输出数据集合(和参考输出数据集合)计算输入数据梯度,并且接着在每一神经网络层处执行向后传播以计算权重梯度,随后是在每一神经网络层处的权重的更新。由于向后传播操作取决于向前传播操作,因此无法并行执行两组操作。这在图3b中显而易见,其中向后传播操作是在向前传播操作之后执行,且权重更新操作是在向后传播操作之后执行。此外,由于神经网络层之间的数据相依性,因此还需要针对每一神经网络层循序地执行向前传播操作和向后传播操作。缺乏并行性可大幅度增加训练时间,当针对训练输入数据集合的不同部分执行训练过程的多个批次,且以多个迭代重复批次以朝向最小数据梯度收敛时所述训练时间进一步增加。
[0057]
加速训练过程的一种方式是使用分布式系统以跨越多个计算系统分布训练过程,所述多个计算系统中的每一个被配置为工作者节点。具体地,参考上文图3b的批次实例,训练输入数据的每一部分可进一步细分为子部分,其中每一子部分将由分布式系统的每一工作者节点在并行训练过程中处理。图3c示出分布式系统中的并行训练过程的实例。如图3c所示,用于批次训练操作的训练输入数据的一部分可进一步细分为子部分0、子部分1、子部分p等。可在每一工作者节点处执行并行训练过程(例如,训练过程330a、330b、330p等)。举例来说,大约在同一时间,每一工作者节点可基于训练输入数据的相应子部分和初始权重的同一集合执行操作312(例如,312a、312b、312p等),其包含向前传播操作。在向前传播操作的完成后,每一工作者节点可执行操作314(例如,314a、314b、314p等),其包含向后传播操作。每一工作者节点可大约在同一时间执行其相应操作314以产生用于每一神经网络层的权重梯度。每一工作者节点基于由所述工作者节点接收的训练输入数据的相应子部分产生权重梯度。
[0058]
在向后传播操作的完成后,每一工作者节点可执行交换操作332(例如,332a、332b、332p等)以与其它工作者节点交换在每一工作者节点处产生的权重梯度。每一交换操作包含工作者节点将用于每一神经网络层的权重梯度集合传输到其它工作者节点中的每一个,且从其它工作者节点中的每一个接收用于每一神经网络的权重梯度集合。工作者节点可将其权重梯度集合和从其它工作者节点接收的权重梯度集合进行平均化。在交换操作332结束时,每一工作者节点可具有平均化权重梯度的同一集合。每一工作者节点可随后执行操作316(例如,316a、316b、316p等)以基于平均化权重梯度更新用于每一神经网络层的权重,并且接着基于经更新的权重并行地开始批次2向前传播操作322(例如,322a、322b、322p等)。
[0059]
跨越多个工作者节点分布训练过程可减少在每一工作者节点处将处理的训练数据的量,这可减少向前和向后传播操作的执行时间且加速训练过程。举例来说,由于由每一工作者节点处理的训练数据量已减少,因此图3c中的向前传播操作312和向后传播操作314的持续时间可短于图3b中的相同操作的持续时间。然而,在操作332中,工作者节点之间的权重梯度的交换会引入实质瓶颈。举例来说,在分布式系统处于云基础结构中且每一工作者节点通过发送网络包而彼此交换权重梯度的情况下,网络时延相对于向前/向后传播操作的执行时间可为实质的。因此,交换权重梯度操作332的持续时间可比向前传播操作312和向后传播操作314的持续时间大得多。由于权重梯度交换操作332与向前传播操作312和向后传播操作314串行化,因此权重梯度交换操作332会对训练过程增加显著延迟且增加训练时间。
[0060]
图4a、图4b和图4c示出可执行用于神经网络的训练过程的分布式系统400。如图4a所示,分布式系统400包含多个计算系统402a、402b、402p等。每一计算系统可包含硬件接口以经由网络404彼此通信。网络404可为以太网网络、点对点互连、基于环的互连等。每一计算系统可表示工作者节点且包含计算资源以执行图3a-3c中的训练过程的操作,包含向前传播操作312、向后传播操作314、更新权重操作316等。计算资源可以包含(例如)神经网络硬件加速器、通用硬件处理器,或支持训练过程中涉及的算术操作的其它合适的计算系统。每一计算装置可经由网络404与每一其它装置通信以交换权重梯度来执行交换操作332,且在交换操作332完成之后执行更新权重操作316。
[0061]
图4b示出计算系统402的内部组件的实例。如图4b所示,计算系统402包含神经网络处理器412、交换处理器414、权重更新模块416和硬件接口418。在一些实例中,交换处理器414和权重更新模块416可以软件实施。在一些实例中,交换处理器414和权重更新模块416也可被实施为硬件组件,例如为专用集成电路(asic)、现场可编程门阵列(fpga)装置等的部分。计算系统402进一步包含控制器(图4b中未图示)以协调神经网络处理器412、交换处理器414、权重更新模块416和硬件接口418之间的操作。
[0062]
神经网络处理器412可针对所有神经网络层执行向前传播操作312,随后是用于所有神经网络层的向后传播操作314。在神经网络处理器412产生用于一个神经网络层的权重梯度(例如,权重梯度420)之后,其将权重梯度发送到交换处理器414,所述交换处理器管理权重梯度的交换操作。作为交换操作的部分,交换处理器414可将权重梯度转发到硬件接口418以用于经由网络404传输到其它工作者节点。交换处理器414也可经由网络404和硬件接口418从其它工作者节点接收其它权重梯度。交换处理器414可将权重梯度420和422进行平均化以产生用于神经网络层的平均化权重梯度425,并且接着将平均化权重梯度425传送到权重更新模块416。
[0063]
权重更新模块416可执行权重更新操作316。权重更新模块416可包含软件指令和/或硬件电路(例如,算术电路)以基于上文的等式4更新权重。作为权重更新操作316的部分,权重更新模块416可从神经网络处理器412(或从其它源)接收用于所述神经网络层的权重428,根据上文等式4基于来自交换处理器414的平均化权重梯度425更新权重,且在向前传播操作322的下一批次之前将经更新的权重429发送到神经网络处理器412。
[0064]
同时,在权重梯度的交换和权重的更新期间,神经网络处理器412可开始用于下一(较低)神经网络层的向后传播操作。神经网络处理器412可随后在用于下一神经网络层的
向后传播操作完成之后将用于下一神经网络层的另一权重梯度集合发送到交换处理器414。
[0065]
在一些实例中,交换处理器414可包含缓冲器430以存储从神经网络处理器412接收的权重梯度作为用于神经网络层的交换任务。缓冲器430可实施于与交换处理器414耦合或作为其部分的存储器中。缓冲器430可包含多个条目。每一条目可存储包含神经网络层的权重梯度的交换任务424,以及交换任务执行的完成/未完成的指示426。如图4b所示,缓冲器430可例如存储用于层n的交换任务、用于层n-1的交换任务等。交换处理器414可通过每当硬件接口418可用(例如,不发送其它数据包)时将交换任务的权重梯度释放到硬件接口418来执行交换任务。在一些实例中,交换处理器414可按其在缓冲器430中存储任务的次序执行交换任务,使得缓冲器430作为先进先出缓冲器操作。在一些实例中,如下文描述,交换处理器414可基于将较低神经网络层优先化而执行交换任务,使得交换任务中的至少一些不是以任务存储于缓冲器430中的次序执行。
[0066]
为了执行交换任务,硬件接口418可与其它工作者节点中的每一个建立通信通道,使用通信通道与其它工作者节点中的每一个交换权重梯度,且将所接收权重梯度转发回到交换处理器414。当交换处理器414检测到用于神经网络层的所有权重梯度已经接收时,交换处理器414可确定用于所述神经网络层的交换任务完成,且将权重梯度的完整集合转发到权重更新模块416以执行如上文所描述的权重更新操作316a。
[0067]
图4b的布置允许权重梯度的交换与向后传播操作并行执行。图4c示出训练过程440的实例。如图4c所示,在用于层n的向后传播操作442完成之后,包含用于层n的权重梯度交换(dwn)和用于层n的权重更新的操作444可与用于层n-1的向后传播操作446并行执行。同样,在用于层2的向后传播操作452完成之后,包含用于层2的权重梯度交换(dw2)和用于层2的权重更新的操作454可与用于层1的向后传播操作456并行执行。与其中权重梯度交换与向后传播操作串行化的图3c相比,图4b的布置可基本上减少训练时间且可进一步加速训练过程。此外,并行性不影响用于较高神经网络层(例如,层n)的权重更新操作,也不影响用于较低神经网络层(例如,层n-1)的向后传播操作,因为所述两个操作彼此之间无数据相依性。
[0068]
虽然图4b的布置可加速训练过程,但通过优先化用于较低层的权重梯度交换可进一步减少训练时间。举例来说,最低层1的权重梯度(dw1)中的至少一些的交换可首先执行,随后是包含层2和n的其它层的权重梯度的交换。使用于较低层的权重梯度交换优先于较高层可缩短训练时间。此外,层1的第二批次向前传播操作(操作460)取决于层1的先前第一批次向后传播操作中的权重梯度dw1的交换以及层1的权重的更新操作462,如由数据相依性箭头464所示。因此,层1的更新操作462必须与层1的第二批次向前传播操作460串行化。因此,操作462完成所花费的时间可决定第一批次训练过程与第二批次训练过程之间的等待时间,且可显著贡献于总体训练时间。优先化用于层1的权重梯度交换和权重操作462的更新可减少在等待其它层的权重梯度交换完成的同时将操作462暂停的可能性,所述暂停会进一步延迟操作462的完成和第二批次训练过程的开始。具体地,一旦用于层1的批次1向后操作456完成,操作462就可开始。因此操作462完成所花费的时间可减少,这可进一步减少总体训练时间。
[0069]
同时,延迟用于较高层级的权重梯度交换不一定增加总体训练时间。这是由于在
用于较高层的下一批次向前传播操作中需要经更新的权重之前较高层具有较大定时窗口来执行权重梯度交换和权重更新。这是由于向前传播操作和向后传播操作在神经网络层之间以相反次序执行。如上文所描述,向后传播操作在最高神经网络层处开始且在最低神经网络层处结束。在更新权重之后,训练过程的新迭代可开始,其中向前传播操作在最低神经网络层处开始且在最高神经网络层处结束。由于最低神经网络层是用以产生权重梯度的最后层但也是在用于训练过程的下一迭代的向前传播操作中使用经更新权重的第一层,因此提供到最低神经网络层用于权重梯度交换和权重的后续更新的定时窗口在所有神经网络层之间是最短的。如图4c所示,虽然层n具有t1的窗口以在用于层n的批次2向前操作470需要经更新的权重之前完成权重梯度交换和权重更新,如由数据相依性箭头472所指示,但层1具有t2的短得多的窗口来完成权重梯度交换和权重更新。可延迟较高层的权重梯度交换,使得它们与较低层的批次2向前传播操作(对较高层的经更新权重无数据相依性)并行执行,以进一步减少训练时间。
[0070]
图5a示出可支持较低神经网络层的交换任务的优先化的交换处理器414的额外组件。具体地,针对每一层将交换的权重梯度可分裂成若干部分,其中每一部分与交换任务相关联。当产生用于较低神经网络层的新交换任务时可暂停用于较高神经网络层的交换任务的执行以允许新交换任务的执行。由于较低神经网络层具有较短窗口来完成权重梯度交换和权重更新,因此此类布置可确保较低神经网络层的权重梯度交换和权重更新操作在权重梯度产生之后尽快开始。因此,由于在等待权重梯度交换的完成时将较低神经网络的下一批次向前传播计算暂停而对训练操作引入的延迟可减小。
[0071]
参看图5a,除缓冲器430之外,交换处理器414还包含可受控制器(图5a中未图示)控制的权重梯度分裂器502和仲裁器504。权重梯度分裂器502可将由神经网络处理器412提供的用于神经网络层的权重梯度分裂为多个相等部分,且每一部分可与交换任务相关联。如下文描述,包含于交换任务中的权重梯度的一部分的大小可基于各种因数,包含例如传输权重梯度的网络效率的预定阈值水平、训练过程完成的目标时间等。另外,仲裁器504可控制存储于缓冲器430中的交换任务的执行次序。缓冲器430进一步与写入指针506和读取指针508相关联。写入指针506可指向用以存储下一新交换任务的空条目并且可针对每一新存储的交换任务进行调整。读取指针508指示存储正被执行的执行任务的条目。如下文描述,仲裁器504可控制读取指针508以优先化较低神经网络层的交换任务和/或优先化新存储的交换任务。
[0072]
参看图5a,在神经网络处理器412完成神经网络层(例如,层n)的向后传播操作且将权重梯度(例如,权重梯度420)提供到权重梯度分裂器502之后。权重梯度分裂器502可包含用以存储权重梯度的内部缓冲器(图5a中未图示)。基于指定将包含于每一部分中的权重梯度的数目的配置信息,权重梯度分裂器502可从内部缓冲器检索权重梯度420的部分,且将权重梯度420的部分以及与所述部分相关联的交换任务识别符发送到缓冲器430。缓冲器430可将基于相关联交换任务识别符而识别的权重梯度420的每一部分存储为交换任务,且第一多个交换任务510可存储于缓冲器430中。
[0073]
作为说明性实例,对于层n,权重梯度分裂器502可将权重梯度分裂为部分0到kn,而对于层n-1,权重梯度分裂器502可将权重梯度分裂为部分0到k
n-1
。每次可将一个交换任务存储到缓冲器430的条目中,其中写入指针506被调整为指向用以存储下一交换任务的下
一条目。在所述第一多个交换任务存储于缓冲器430中之后,仲裁器504可基于检测到硬件接口418空闲而开始从缓冲器430执行所述第一多个交换任务。仲裁器504可将读取指针508设定到最近存储的执行任务,并且接着以任务存储于缓冲器430中的反向次序执行任务,直到缓冲器430存储用于来自不同神经网络层(例如,层n-1)的不同权重梯度集合的第二多个交换任务512。
[0074]
当缓冲器430存储第二多个交换任务512时,仲裁器504可确定所述第二多个交换任务是否用于比与第一多个交换任务510相关联的层低的神经网络层。在图5a的实例中,仲裁器504可确定它们是这样。仲裁器504可随后等待直到第一多个交换任务510的在进行中的交换任务已经完成。当那些交换任务完成(例如,用于层n分裂kn的任务510a)时,仲裁器504可暂停所述第一多个交换任务的剩余部分的执行,将读取指针设定到所述第二多个交换任务中的最后一个,且开始执行所述第二多个交换任务,因此对所述第二多个交换任务给予较高优先级。在第二多个交换任务完成之后,剩余第一多个交换任务可与较低层(层n-1)的向前传播操作并行执行。
[0075]
给予所述第二多个交换任务的较高优先级可以例如基于所述第二多个交换任务是针对比所述第一多个交换任务低的神经网络层产生,和/或所述第二多个交换任务比所述第一多个交换任务更晚存储于缓冲器430中。恰如所述第一多个交换任务,所述第二多个交换任务也可以任务存储于缓冲器430中的反向次序执行,随后是所述第一多个交换任务且跳过已经完成的所有交换任务,直到缓冲器430存储用于来自又一不同神经网络层的另一权重梯度集合的第三多个交换任务。通过图5a的布置,较低神经网络层的交换任务可以优先于较高神经网络层的交换任务,这可减少如上文所描述的训练时间。
[0076]
包含于交换任务中的权重梯度的一部分的大小是基于划分将由工作者节点传输的权重梯度的总数目和将执行以交换权重梯度的交换任务的数目确定的。交换任务的数目(和与交换任务相关联的部分中的权重梯度的数目)可以基于各种因数确定以最小化总体训练时间。
[0077]
在一个实例中,为了最小化或至少减少总体训练时间,可确定在传输权重梯度的网络效率的阈值水平,使得可在目标时间周期内在具有某一网络带宽的网络中完成交换任务,且整个训练过程可在目标训练时间内完成。具体地,每一交换任务包含在工作者节点之间建立通信通道,以及准备用于在网络上传输的数据以及经由通信通道的权重梯度的交换。通信通道的建立和用于传输的数据的准备产生开销时间。增加交换任务的数目可导致开销时间的累积,这可减少网络在传输权重梯度时所花费的时间的份额,且所述时间的份额可定义传输权重梯度的网络效率。可确定交换任务的数目以使得与超时的份额相比,传输权重梯度的时间份额满足网络效率的预定阈值水平。
[0078]
将权重梯度分裂为若干部分且将所述部分指派于不同交换任务也可改善硬件接口418和网络404的利用率,同时减少由于优先化而对较低层交换任务带来的延迟。具体地,通过将权重梯度分裂为若干部分且将所述部分指派于不同交换任务,较高层权重梯度中的至少一些可与较低层的向后传播操作并行交换。与其中较高层的所有交换任务暂停直到最低层的交换任务完成的布置相比,图5a的布置可减少硬件接口418和网络404空闲等待最低层的交换任务的可能性,这可改善硬件资源的利用率且维持工作者节点之间的网络的效率。此外,由于较高层的交换任务中的至少一些可首先执行而不是将其全部暂停以等待最
低层的交换任务完成,也可减少较高层的交换任务由于优先化而变成瓶颈的可能性。
[0079]
图5b到图5e示出缓冲器430在训练过程的不同阶段的实例状态。图5b指示在层n的向后传播操作结束时缓冲器430的状态。权重梯度分裂成部分0到k,每一部分与交换任务相关联,且交换任务从部分0到部分k循序地存储。写入指针506可指向在用于层n部分k(“层n分裂k
n”)的交换任务之后的第一空条目,而读取指针508可指向存储用于层n部分kn的其执行处于进展中的交换任务的条目(写入指针506上方的一个条目)。基于任务存储于缓冲器430中的反向次序,将执行的下一交换任务可以是层n部分k-1(“层n分裂k
n-1”)。
[0080]
图5c示出在层n-1的向后传播操作结束时缓冲器430的状态。权重梯度分裂成部分0到2,每一部分与交换任务相关联,且交换任务从部分0到部分2循序地存储。写入指针506可指向在用于层n-1部分2(“层n-1分裂2”)的交换任务之后的第一空条目。在存储用于层n-1的交换任务时,层n分裂k的执行完成,而层n分裂k
n-1-1的执行处于进展中。仲裁器504可等待直到层n分裂k
n-1-1的执行完成,并且接着暂停用于层n的交换任务的剩余部分的执行,且将读取指针508移动到层n-1分裂2以使其接下来执行。
[0081]
图5d示出在层1(最低层)的向后传播操作结束时缓冲器430的状态。权重梯度分裂成部分0到1,每一部分与交换任务相关联,且交换任务从部分0到部分1循序地存储。写入指针506可指向在用于层1部分1(“层1分裂1”)的交换任务之后的第一空条目。在存储用于层1的交换任务时,层n分裂k、层n分裂k-1、层n-1分裂2以及层n-1分裂1的执行已完成。这些交换任务的执行可与较高层的向后传播操作并行进行,如上文所解释。仲裁器504可将读取指针508移动到执行处于进展中的层1部分1。
[0082]
图5e示出在层1的下一批次向前传播操作结束时缓冲器430的状态。如图5e所示,交换任务层1分裂0和层1分裂1的执行已完成,且权重更新模块416具有用于层1的权重梯度的完整集合以更新用于层1的权重。权重更新模块416可将用于层1的经更新权重提供到神经网络处理器412,所述神经网络处理器可随后执行层1的下一批次向前传播操作。同时,仲裁器504可移动读取指针508以遵循任务存储的反向次序遍历通过剩余未完成交换任务,同时跳过完成的交换任务。在图5e中,仲裁器504可将读取指针508移动到存储执行处于进展中的层n-1分裂0的条目。
[0083]
图5e示出所有交换任务已经完成的缓冲器430的状态。仲裁器504可复位缓冲器430以准备向后传播操作的下一批次或迭代。
[0084]
图6示出在例如分布式系统400等分布式系统中训练神经网络的方法。分布式系统400包含被配置为通过网络404连接的工作者节点的多个计算系统。可对输入数据集合执行训练过程。输入数据集合可划分成多个部分。每一部分随后划分成若干子部分。每一工作者节点可执行训练过程第一批次中的输入数据的子部分,随后是第二批次中的另一子部分,直到已经使用输入数据的所有子部分。训练过程的每一批次可由神经网络硬件执行,且可包含用于每一层的向前传播操作,随后是用于每一层的向后传播操作。在图6的实例中,神经网络可包含多个神经网络层,包含第一神经网络层和第二神经网络。第二神经网络层接收第一神经网络的输出作为输入。
[0085]
方法600在步骤602中开始,其中分布式系统400的第一工作者节点的神经网络处理器执行用于第二神经网络层的向后传播计算以产生第二层数据梯度和第二层权重梯度。向后传播计算可为第一批次。可在第一神经网络层和第二神经网络层的第一批次向前传播
操作已完成且输入数据梯度(图3a的din)已产生之后执行步骤602。可基于输入数据梯度或由较高神经网络层(如果神经网络具有多于两个神经网络层)输出的数据梯度执行第一批次向后传播计算。
[0086]
在步骤604中,第一工作者节点产生第一多个交换任务,其各自对应于第二层权重梯度的一部分与网络404上的其它工作者节点的交换。具体地,权重梯度分裂器502可将第二层权重梯度划分成多个部分,其中每一部分包含预定数目的第二层权重梯度。所述第一多个交换任务中的每一个可包含工作者节点与其它工作者节点中的每一个建立通信通道,以及经由所述通信通道将第二层权重梯度的一部分传输到其它工作者节点中的每一个且接收在其它工作者节点中的每一个处产生的第二层权重梯度的一部分。包含于交换任务中的权重梯度的一部分的大小是基于划分将由工作者节点传输的权重梯度的总数目和将执行以交换权重梯度的交换任务的数目确定的。交换任务的数目(和与交换任务相关联的部分中的权重梯度的数目)可基于各种因数确定以最小化总体训练时间,例如基于维持某一程度的传输权重梯度的网络效率。
[0087]
在一些实例中,权重梯度分裂器502包含内部缓冲器以存储权重梯度。基于指示针对每一交换任务将包含的权重梯度的数目的配置信息,权重梯度分裂器502可从内部缓冲器获得第二层权重梯度的数目以形成用于交换任务的部分,且将第二层权重梯度和执行任务识别符提供到交换处理器414。交换处理器414可基于执行任务识别符识别第二层权重梯度的每一部分,且将所述部分存储于缓冲器430的条目中。交换处理器414可在缓冲器430的多个条目中循序地存储与所述第一多个交换任务相关联的第二层权重梯度的所述多个部分。交换处理器414可维持读取指针(例如,读取指针508)和写入指针(例如,写入指针506)以跟踪交换任务的存储。读取指针508可指向具有最近存储的执行任务的条目,而写入指针506可指向在读取指针508之后的下一条目以接收下一交换任务。
[0088]
在步骤606中,第一工作者节点执行所述第一多个交换任务中的第一交换任务以与第二工作者节点交换第二权重梯度的第一部分。第一工作者节点可从缓冲器430的第一条目获得第二权重梯度的第一部分。第一条目可为读取指针508指向的条目。为了执行第一交换任务,交换处理器414可控制硬件接口418以与其它工作者节点中的每一个建立通信通道且经由所述通信通道将第二权重梯度的第一部分传输到其它工作者节点。硬件接口418也可从其它工作者节点中的每一个接收与第一部分相同数目的第二权重梯度,作为第一交换任务的部分。
[0089]
在步骤608中,第一工作者节点的神经网络处理器基于第二层数据梯度(来自步骤602)与第一交换任务并行执行用于第一神经网络层的向后传播计算以产生第一层数据梯度和第一层权重梯度。用于第一神经网络层的向后传播计算是与步骤602的用于第二神经网络层的向后传播计算相同的批次(例如,第一批次)。
[0090]
在步骤610中,第一工作者节点产生第二多个交换任务,其各自对应于第一层权重梯度的一部分与其它工作者节点的交换。权重梯度分裂器502可将第一层权重梯度划分成多个部分,其中每一部分包含预定数目的第一层权重梯度且与交换任务相关联。包含于所述第二多个交换任务中的每一个中的第一层权重梯度的数目可以相同或不同于包含于所述第一多个交换任务中的每一个中的第二层权重梯度的数目。如步骤604中,所述第二多个交换任务中的每一个可包含工作者节点与其它工作者节点中的每一个建立通信通道,以及
经由所述通信通道将第一层权重梯度的一部分传输到其它工作者节点中的每一个且接收在其它工作者节点中的每一个处产生的第一层权重梯度的一部分。
[0091]
在步骤612中,在第一交换任务的执行完成之后,第一工作者节点执行所述第二多个交换任务以与第二工作者节点交换第一层权重梯度。具体地,交换处理器414可基于任务存储于缓冲器430中的次序执行交换任务,但可在一旦较低层的交换任务存储于缓冲器430中就使较低层的交换任务的执行优先于较高层。举例来说,在第一交换任务(交换第二层权重梯度的第一部分)的完成之后,交换处理器414可将读取指针508移动到具有所述第二多个交换任务当中的最近存储的交换任务的条目(用于第一层权重梯度)以执行交换任务。交换处理器414可随后遍历存储所述第二多个交换任务的剩余部分的条目以完成第一层权重梯度的交换。在第一层权重梯度的交换完成之后,交换处理器414可基于将由第一工作者节点产生的第一层权重梯度和从其它工作者节点接收的第一层权重梯度平均化而确定平均化的第一层权重梯度。
[0092]
在步骤614中,在第一层权重梯度的交换完成之后,第一工作者节点的权重更新模块416基于平均化第一层权重梯度更新用于第一神经网络层的权重。所述更新可基于上述等式4。
[0093]
在步骤616中,第一工作者节点基于经更新权重执行用于第一神经网络层的向前传播计算。所述向前传播计算是第二批次且基于与第一批次不同的输入数据的子部分。
[0094]
在步骤618中,第一工作者节点执行所述第一多个交换任务中的剩余交换任务以与其它工作者节点交换第二层权重梯度的剩余部分,所述剩余交换任务中的至少一些与用于第一神经网络层的权重的更新和用于第一神经网络层的向前传播计算并行执行。在步骤614中完成第一层权重梯度的交换之后,第一工作者节点可开始与步骤616的用于第一神经网络层的权重的更新并行执行所述第一多个交换任务中的剩余交换任务,随后是用于第一神经网络层的向前传播计算。在第二权重梯度的交换完成之后,交换处理器414可基于将由第一工作者节点产生的第二层权重梯度和从其它工作者节点接收的第二层权重梯度平均化而确定平均化第二层权重梯度。
[0095]
在步骤620中,第一工作者节点基于平均化第二层权重梯度更新用于第二神经网络层的权重。所述更新可基于上述等式4。在用于第二神经网络层的权重的更新后,第一工作者节点可执行用于第二神经网络层的第二批次向前传播操作。
[0096]
还可根据以下条款描述本公开的实施例:
[0097]
1.一种存储指令的非暂时性计算机可读介质,所述指令在由一个或多个硬件处理器执行时致使所述一个或多个硬件处理器:
[0098]
执行用于神经网络的第二层的向后传播计算以产生第二权重梯度;
[0099]
将所述第二权重梯度分裂为若干部分;
[0100]
致使硬件接口与第二计算机系统交换所述第二权重梯度的第一部分;
[0101]
当所述第二权重梯度的所述第一部分的所述交换在进行中时执行用于所述神经网络的第一层的向后传播计算以产生第一权重梯度,所述第一层在所述神经网络中是比所述第二层低的层;
[0102]
在所述第二权重梯度的所述第一部分的传输完成之后,致使所述硬件接口将所述第一权重梯度传输到所述第二计算机系统;以及
[0103]
在所述第一权重梯度的所述传输完成之后,致使所述硬件接口将所述第二权重梯度的剩余部分传输到所述第二计算机系统。
[0104]
2.根据条款1所述的非暂时性计算机可读介质,其中所述第二权重梯度是在所述第一权重梯度之前产生的。
[0105]
3.根据条款1或2所述的非暂时性计算机可读介质,其进一步存储指令,所述指令当由一个或多个硬件处理器执行时致使所述一个或多个硬件处理器:
[0106]
将所述第二权重梯度的每一部分指派于多个第一交换任务中的每一个;
[0107]
在缓冲器中循序地存储所述多个第一交换任务;以及
[0108]
接收硬件接口空闲的指示:
[0109]
从所述缓冲器检索所述多个第一交换任务中的第一交换任务;以及
[0110]
基于以下各项执行所述第一交换任务:
[0111]
致使所述硬件接口将指派于所述多个第一交换任务中的所述一个的所述第二权重梯度的所述第一部分传输到所述第二计算机系统;以及
[0112]
经由所述硬件接口从所述第二计算机系统接收第三权重梯度。
[0113]
4.根据条款3所述的非暂时性计算机可读介质,其进一步存储指令,所述指令当由一个或多个硬件处理器执行时致使所述一个或多个硬件处理器:
[0114]
将所述第一权重梯度划分成多个部分;
[0115]
将所述第一权重梯度的每一部分指派于多个第二交换任务中的每一个;
[0116]
在所述多个第一交换任务之后在所述缓冲器中循序地存储所述多个第二交换任务;以及
[0117]
响应于确定所述第二权重梯度的所述部分的所述传输和所述第三权重梯度的所述接收完成:
[0118]
循序地从所述缓冲器检索所述多个第二交换任务中的每一个;以及
[0119]
基于致使所述硬件接口传输指派于所述多个第二交换任务中的所述每一个的所述第一权重梯度的每一部分而执行所述多个第二交换任务中的所述每一个;
[0120]
循序地从所述缓冲器检索剩余第一交换任务中的每一个;以及
[0121]
基于致使所述硬件接口传输指派于所述剩余第一交换任务中的所述每一个的所述第二权重梯度的每一部分而执行所述剩余第一交换任务中的所述每一个。
[0122]
5.根据条款4所述的非暂时性计算机可读介质,其中基于所述第一层在所述神经网络中是比所述第二层低的层而在所述剩余第一交换任务之前从所述缓冲器检索所述多个第二交换任务。
[0123]
6.根据条款4或5所述的非暂时性计算机可读介质,其中基于所述多个第二交换任务比所述多个第一交换任务更晚存储于所述缓冲器中而在所述剩余第一交换任务之前从所述缓冲器检索所述多个第二交换任务。
[0124]
7.根据条款4到6中任一项所述的非暂时性计算机可读介质,其中以所述多个第二交换任务存储于所述缓冲器中的反向次序循序地从所述缓冲器检索所述多个第二交换任务;且
[0125]
其中遵循从所述缓冲器检索所述多个第二交换任务的次序来传输所述第一权重梯度的每一部分。
[0126]
8.根据条款4到7中任一项所述的非暂时性计算机可读介质,其中所述第一权重梯度和第二权重梯度的每一部分的大小是基于以下各项中的至少一个确定的:在将所述权重梯度传输到所述第二计算机系统中的某一程度的网络效率,或所述神经网络的训练的目标完成时间。
[0127]
9.根据条款4到8中任一项所述的非暂时性计算机可读介质,其进一步存储指令,所述指令当由一个或多个硬件处理器执行时致使所述一个或多个硬件处理器:
[0128]
当执行用于所述第一层的所述向后传播计算时致使硬件接口将所述第二权重梯度的至少一部分传输到所述第二计算机系统,
[0129]
其中由所述第二计算机系统响应于接收到所述第二权重梯度的所述至少一部分而传输所述第三权重梯度。
[0130]
10.根据条款1到9中任一项所述的非暂时性计算机可读介质,其进一步存储指令,所述指令当由一个或多个硬件处理器执行时致使所述一个或多个硬件处理器:
[0131]
执行用于所述第一层的向前传播计算;以及
[0132]
当执行用于所述第一层的所述向前传播计算时致使硬件接口将所述第二权重梯度的至少一部分传输到所述第二计算机系统。
[0133]
11.一种设备,其包括:
[0134]
神经网络处理器;
[0135]
硬件接口;
[0136]
集成电路,其包括权重梯度分裂器和交换处理器;以及
[0137]
控制器,所述控制器被配置成:
[0138]
控制所述神经网络处理器被配置成执行用于神经网络的第二层的向后传播计算以产生第二权重梯度;
[0139]
控制所述权重梯度分裂器以将所述第二权重梯度分裂为若干部分;
[0140]
经由所述交换处理器控制所述硬件接口以与第二计算机系统交换所述第二权重梯度的第一部分;
[0141]
控制所述神经网络处理器以当所述第二权重梯度的所述第一部分的所述交换在进行中时执行用于所述神经网络的第一层的向后传播计算以产生第一权重梯度,所述第一层在所述神经网络中是比所述第二层低的层;
[0142]
在所述第二权重梯度的所述第一部分的传输完成之后,经由所述交换处理器控制所述硬件接口将所述第一权重梯度传输到所述第二计算机系统;以及
[0143]
在所述第一权重梯度的所述传输完成之后,经由所述交换处理器控制所述硬件接口将所述第二权重梯度的剩余部分传输到所述第二计算机系统。
[0144]
12.根据条款11所述的设备,其中所述控制器被配置成控制所述神经网络处理器以与所述第二权重梯度的所述剩余部分的至少一部分到所述第二计算机系统的传输并行执行用于所述第二层的向前传播计算。
[0145]
13.根据条款11或12所述的设备,其进一步包括存储缓冲器的存储器;
[0146]
其中所述交换处理器被配置成:
[0147]
将所述第二权重梯度的每一部分指派于多个第一交换任务中的每一个;
[0148]
在所述缓冲器中循序地存储所述多个第一交换任务;以及
[0149]
接收硬件接口空闲的指示:
[0150]
从所述缓冲器检索所述多个第一交换任务中的第一交换任务;以及
[0151]
基于以下各项执行所述第一交换任务:
[0152]
控制所述硬件接口将指派于所述多个第一交换任务中的所述一个的所述第二权重梯度的所述第一部分传输到所述第二计算机系统;以及
[0153]
经由所述硬件接口从所述第二计算机系统接收第三权重梯度。
[0154]
14.根据条款13所述的设备,其中基于所述多个第二交换任务比所述多个第一交换任务更晚存储于所述缓冲器中而在所述剩余第一交换任务之前从所述缓冲器检索所述多个第二交换任务。
[0155]
15.根据条款13或14所述的设备,其中基于所述第一层在所述神经网络中是比所述第二层低的层而在所述剩余第一交换任务之前从所述缓冲器检索所述多个第二交换任务。
[0156]
16.一种在分布式系统中训练神经网络模型的方法,所述分布式系统包括第一工作者节点和第二工作者节点,所述神经网络模型包括第一神经网络层和第二神经网络层,所述方法由所述第一工作者节点执行且包括:
[0157]
执行用于所述第二神经网络层的向后传播计算以产生第二层数据梯度和第二层权重梯度;
[0158]
产生第一多个交换任务,其各自对应于所述第二层权重梯度的一部分与所述第二工作者节点的交换;
[0159]
执行所述第一多个交换任务中的第一交换任务以与所述第二工作者节点交换所述第二层权重梯度的第一部分;
[0160]
基于所述第二层数据梯度执行用于所述第一神经网络层的向后传播计算以产生第一层数据梯度和第一层权重梯度;
[0161]
产生第二多个交换任务,其各自对应于所述第一层权重梯度的一部分与所述第二工作者节点的交换;
[0162]
在所述第一交换任务的所述执行完成之后,执行所述第二多个交换任务以与所述第二工作者节点交换所述第一层权重梯度;
[0163]
基于所述交换的第一层权重梯度更新用于所述第一神经网络层的权重;
[0164]
由所述第一工作者节点基于所述经更新权重执行用于所述第一神经网络层的向前传播计算;
[0165]
执行所述第一多个交换任务中的剩余交换任务以与所述第二工作者节点交换所述第二层权重梯度的剩余部分;以及
[0166]
基于所述交换的第二层权重梯度更新用于所述第二神经网络层的权重。
[0167]
17.根据条款16所述的方法,其中用于所述第一神经网络层的所述向后传播计算和所述第二层权重梯度的所述第一部分与所述第二工作者节点的所述交换并行执行。
[0168]
18.根据条款16或17所述的方法,其中所述第二层权重梯度的部分与所述第二工作者节点的交换包括:
[0169]
向所述第二工作者节点传输在所述第一工作者节点处产生的所述第二层权重梯度的所述第一部分;
[0170]
由所述第一工作者节点从所述第二工作者节点接收在所述第二工作者节点处产生的所述第二层权重梯度的第一部分;
[0171]
由所述第一工作者节点基于将在所述第一工作者节点处产生的所述第二层权重梯度的所述第一部分和在所述第二工作者节点处产生的所述第二层权重梯度的所述第一部分平均化而确定平均化第二权重梯度;以及
[0172]
使用所述平均化第二权重梯度更新用于所述第二神经网络层的权重。
[0173]
19.根据条款16到18中任一项所述的方法,其进一步包括:
[0174]
在缓冲器中存储所述第一多个交换任务;
[0175]
从所述缓冲器检索所述第一交换任务用于执行;以及
[0176]
在所述缓冲器中存储所述第二多个交换任务;以及
[0177]
响应于第二多个交换任务存储于所述缓冲器中且所述第一交换任务的执行完成,在执行所述第一多个交换任务中的剩余交换任务之前从所述缓冲器检索所述第二多个交换任务用于执行。
[0178]
20.根据条款16到19中任一项所述的方法,其中在网络上交换所述第一权重梯度和第二权重梯度;且
[0179]
其中所述第一权重梯度和第二权重梯度的每一部分的大小是基于以下各项中的至少一个确定:在所述第一工作者节点与所述第二工作者节点之间传输所述权重梯度中的某一程度的网络效率,或所述神经网络模型的训练的目标完成时间。
[0180]
21.根据条款16到20中任一项所述的方法,其进一步包括:
[0181]
基于用于所述第一神经网络层的所述经更新权重执行用于所述第一神经网络层的向前传播计算,
[0182]
其中用于所述第一神经网络层的所述向前传播计算与所述第二层权重梯度的所述剩余部分中的至少一些的交换并行执行。
[0183]
22.一种在分布式系统中训练神经网络模型的方法,所述分布式系统包括第一工作者节点和第二工作者节点,所述神经网络模型包括第一神经网络层和第二神经网络层,所述方法由所述第一工作者节点执行且包括:
[0184]
执行用于所述第二神经网络层的向后传播计算以产生第二层数据梯度和第二层权重梯度;
[0185]
产生第一多个交换任务,其各自对应于所述第二层权重梯度的一部分与所述第二工作者节点的交换;
[0186]
执行所述第一多个交换任务中的第一交换任务以与所述第二工作者节点交换所述第二层权重梯度的第一部分;
[0187]
基于所述第二层数据梯度执行用于所述第一神经网络层的向后传播计算以产生第一层数据梯度和第一层权重梯度;
[0188]
产生第二多个交换任务,其各自对应于所述第一层权重梯度的一部分与所述第二工作者节点的交换;
[0189]
在所述第一交换任务的所述执行完成之后,执行所述第二多个交换任务以与所述第二工作者节点交换所述第一层权重梯度;
[0190]
基于所述交换的第一层权重梯度更新用于所述第一神经网络层的权重;
[0191]
由所述第一工作者节点基于所述经更新权重执行用于所述第一神经网络层的向前传播计算;
[0192]
执行所述第一多个交换任务中的剩余交换任务以与所述第二工作者节点交换所述第二层权重梯度的剩余部分;以及
[0193]
基于所述交换的第二层权重梯度更新用于所述第二神经网络层的权重。
[0194]
23.根据条款22所述的方法,其中用于所述第一神经网络层的所述向后传播计算和所述第二层权重梯度的所述第一部分与所述第二工作者节点的所述交换并行执行。
[0195]
24.根据条款22或23所述的方法,其中所述第二层权重梯度的部分与所述第二工作者节点的交换包括:
[0196]
向所述第二工作者节点传输在所述第一工作者节点处产生的所述第二层权重梯度的所述第一部分;
[0197]
由所述第一工作者节点从所述第二工作者节点接收在所述第二工作者节点处产生的所述第二层权重梯度的第一部分;
[0198]
由所述第一工作者节点基于将在所述第一工作者节点处产生的所述第二层权重梯度的所述第一部分和在所述第二工作者节点处产生的所述第二层权重梯度的所述第一部分平均化而确定平均化第二权重梯度;以及
[0199]
使用所述平均化第二权重梯度更新用于所述第二神经网络层的权重。
[0200]
25.根据条款22到24中任一项所述的方法,其进一步包括:
[0201]
在缓冲器中存储所述第一多个交换任务;
[0202]
从所述缓冲器检索所述第一交换任务用于执行;
[0203]
在所述缓冲器中存储所述第二多个交换任务;以及
[0204]
响应于第二多个交换任务存储于所述缓冲器中且所述第一交换任务的执行完成,在执行所述第一多个交换任务中的剩余交换任务之前从所述缓冲器检索所述第二多个交换任务用于执行。
[0205]
26.根据条款22到25中任一项所述的方法,其中在网络上交换所述第一权重梯度和第二权重梯度;且
[0206]
其中所述第一权重梯度和第二权重梯度的每一部分的大小是基于以下各项中的至少一个确定:在所述第一工作者节点与所述第二工作者节点之间传输所述权重梯度中的某一程度的网络效率,或所述神经网络模型的训练的目标完成时间。
[0207]
27.根据条款22到27中任一项所述的方法,其进一步包括:
[0208]
基于用于所述第一神经网络层的所述经更新权重执行用于所述第一神经网络层的向前传播计算,
[0209]
其中用于所述第一神经网络层的所述向前传播计算与所述第二层权重梯度的所述剩余部分中的至少一些的交换并行执行。
[0210]
图7是示出可被配置成执行例如图2a到图3b中所述的那些的各种类型的神经网络操作并且可为图4a到图4c的神经网络处理器412的部分的集成电路装置的实例的框图。图7的实例示出加速器702。在各种实例中,对于一组输入数据(例如,输入数据750),加速器702可以使用处理引擎阵列710、激活引擎716和/或池化引擎718执行计算。处理器可具有其它集成电路组件,包括额外加速器引擎。加速器702可包含控制器722以控制处理引擎阵列
710、激活引擎716和/或池化引擎718的操作。
[0211]
在各种实施方案中,存储器子系统704可以包含多个存储器存储体714。在这些实施方案中,每个存储器存储体714可以独立地存取,这意指一个存储器存储体的读取不依赖于另一存储器存储体的读取。类似地,写入到一个存储器存储体不影响或限制写入到不同存储器存储体。在一些情况下,可以同时读取和写入每个存储器存储体。各种技术可以用于具有可独立存取的存储器存储体714。例如,每个存储器存储体可以是物理上独立的存储器组件,其具有单独的且独立于每个其它存储器存储体的地址空间的地址空间。在此实例中,每个存储器存储体可具有至少一个读取通道并且可具有可同时使用的至少一个单独写入通道。在这些实例中,存储器子系统704可以准许同时存取多个存储器存储体的读取或写入通道。作为另一实例,存储器子系统704可以包含仲裁逻辑,使得例如多个存储器存储体714的输出之间的仲裁可以使得多于一个存储器存储体的输出被使用。在这些和其它实例中,尽管由存储器子系统704全局地管理,但是可以独立于任何其它存储器存储体来操作每一存储器存储体。
[0212]
使存储器存储体714可独立地存取可以提高加速器702的效率。例如,值可以被同时读取并提供到处理引擎阵列710的每个行,使得整个处理引擎阵列710可以在一个时钟循环中使用。作为另一实例,可以在由处理引擎阵列710计算的结果被写入到存储器子系统704的同时读取存储器存储体714。相比之下,单个存储器可能每次仅能够服务一个读取或写入。在单个存储器的情况下,在可以开始处理引擎阵列710之前,例如可能需要多个时钟循环来读取处理引擎阵列710的每个行的输入数据。
[0213]
在各种实施方案中,存储器子系统704可被配置成同时服务多个客户端,所述客户端包含处理引擎阵列710、激活引擎716、池化引擎718以及通过通信结构720接入存储器子系统704的任何外部客户端。在一些实施方案中,能够服务多个客户端可以意指存储器子系统704至少具有与客户端一样多的存储器存储体。在一些情况下,处理引擎阵列710的每个行可以算作单独的客户端。在一些情况下,处理引擎阵列710的每个列可以输出结果,使得每个列可以算作单独的写入客户端。在一些情况下,来自处理引擎阵列710的输出可以被写入到存储器存储体714中,所述存储器存储体随后可以为处理引擎阵列710提供输入数据。作为另一实例,激活引擎716和池化引擎718可以包含多个执行通道,每个执行通道可以是单独的存储器客户端。举例来说,存储器存储体714可使用静态随机存取存储器(sram)实施。
[0214]
在各种实施方案中,存储器子系统704可以包含控制逻辑。例如,控制逻辑可以跟踪存储器存储体714中的每一个的地址空间,识别要读取或写入的存储器存储体714,和/或在存储器存储体714之间移动数据。在一些实施方案中,存储器存储体714可以硬连线到特定客户端。例如,一组存储器存储体714可被硬连线以将值提供到处理引擎阵列710的各行,其中一个存储器存储体服务一个行。作为另一实例,一组存储器存储体可硬连线以从处理引擎阵列710的列接收值,其中一个存储器存储体接收每一列的数据。
[0215]
处理引擎阵列710是实例加速器702的计算矩阵。例如,处理引擎阵列710可以执行并行积分、卷积、相关和/或矩阵乘法等。处理引擎阵列710包含以行和列布置的多个处理引擎711,使得由一个处理引擎711输出的结果可直接输入到另一处理引擎711中。因此,不在处理引擎阵列710的外部边缘上的处理引擎711可以从其它处理引擎711,而不是从存储器
子系统704接收数据以进行操作。
[0216]
在各种实例中,处理引擎阵列710使用脉动执行,其中数据从不同方向以规律间隔到达每个处理引擎711。在一些实例中,输入数据可以从左流入处理引擎阵列710中,并且权重值可以在顶部处加载。在一些实例中,权重和输入数据可以从左边流动,且部分和可以从顶部流动到底部。在这些和其它实例中,相乘和累加操作作为对角波前移动通过处理引擎阵列710,其中数据在阵列上向右和向下移动。控制信号可与权重同时在左边输入,并且可连同计算一起流过并且向下流动。
[0217]
在各种实施方案中,处理引擎阵列710中的列的数目确定处理引擎阵列710的计算容量,并且行的数目确定用于实现处理引擎阵列710的最大利用率的所需存储器带宽。处理引擎阵列710可具有例如64列和64行,或某一其它数目的列和行。
[0218]
图7中以插图说明处理引擎711的实例。如通过此实例说明,处理引擎711可以包含乘法器-累加器电路。来自左边的输入可包括例如输入数据i和权重值w,其中输入数据是取自一组输入数据或一组中间结果的值,并且权重值来自将神经网络的一个层连接到下一层的一组权重值。例如,一组输入数据可以是提交以用于识别或对象辨识的图像、提供用于语音辨识的音频片段、用于自然语言处理或机器翻译的文本的字符串,或需要分析以确定下一移动的游戏的当前状态等。在一些实例中,输入数据和权重值输出到右边,以用于输入到下一处理引擎711。
[0219]
在所说明的实例中,来自上方的输入可以包含部分和p_in,其从另一处理引擎711或从前一轮计算通过处理引擎阵列710提供。当开始用于新的一组输入数据的计算时,处理引擎阵列710的顶部行可以接收用于p_in的固定值,例如零。如通过此实例所说明,i和w在一起相乘,且结果与p_in进行求和以产生新的部分和p_out,其可以被输入到另一处理引擎711中。处理引擎411的各种其它实施方案是可能的。
[0220]
来自处理引擎阵列710中的最后一行的输出可以暂时地存储在求和缓冲器712中。所述结果可以是中间结果,其可以被写入到存储器存储体714以提供给处理引擎阵列710以进行额外计算。或者,所述结果可以是最终结果,其一旦被写入到存储器存储体714就可以通过通信结构720从存储器子系统704读取,以由系统输出。
[0221]
在一些实施方案中,加速器702包含激活引擎716。在这些实施方案中,激活引擎716可以将来自处理引擎阵列710的结果组合成一个或多个输出激活。例如,对于卷积神经网络,可对来自多个通道的卷积进行求和以产生用于单个通道的输出激活。在其它实例中,可以需要累加来自处理引擎阵列710中的一个或多个列的结果以产生用于神经网络中的单个节点的输出激活。在一些实例中,可以绕过激活引擎716。
[0222]
在各种实例中,激活引擎716可以包含多个单独执行通道。在这些实例中,所述执行通道可以对应于处理引擎阵列710的列,并且可以对列的输出执行操作,其结果可以存储在存储器子系统704中。在这些实例中,激活引擎716能够执行1个与n个之间的并行计算,其中n等于处理引擎阵列710中的列的数目。在一些情况下,可同时执行所述计算中的一个或多个。每个执行通道可执行的计算的实例包括指数、平方、平方根、恒等式、二元步、双极步、s形(sigmoidal)和斜坡(ramp),以及其它实例。
[0223]
在一些实施方案中,加速器702可以包含池化引擎718。池化是对处理引擎阵列710的列的输出的组合。组合可包含例如计算最大值、最小值、平均值、中值、总和、乘法或另一
逻辑或数学组合。在各种实例中,池化引擎718可以包含多个执行通道,所述执行通道可以对来自处理引擎阵列710的对应列的值进行操作。在这些示例中,池化引擎718能够执行1个与n个之间的并行计算,其中n等于处理引擎阵列710中的列的数目。在各种实例中,池化引擎718的执行通道可以并行和/或同时操作。在一些实例中,可以绕过池化引擎718。
[0224]
本文中,激活引擎716和池化引擎718可以统称为执行引擎。处理引擎阵列710是执行引擎的另一实例。执行引擎的另一实例是可位于加速器702外部的直接存储器存取(dma)引擎。
[0225]
输入数据750可以到达通信结构720。通信结构720可以将加速器702连接到处理器的其它组件,例如可以从输入/输出(i/o)装置获得输入数据750的dma引擎、存储驱动器或网络接口。输入数据750可以是例如一维数据,例如字符串或数字序列,或可以是二维数据,例如用于图像的像素值的阵列或用于音频信号的随时间推移的频率和幅值。在一些实例中,输入数据750可以是三维的,例如对于自动驾驶汽车所使用的情境信息或虚拟现实数据来说可以是这种情况。在一些实施方案中,存储器子系统704可以包含用于输入数据750的单独的缓冲器。在一些实施方案中,当加速器702接收输入数据750时,输入数据750可以存储在存储器存储体714中。
[0226]
在一些实例中,加速器702可以实施神经网络处理引擎。加速器702可执行神经网络以执行所述神经网络针对输入数据750的集合训练的任务,例如执行推断任务。加速器702也可执行训练过程的各种操作,例如向前传播操作、向后传播操作、权重更新操作等,以更新用于神经网络的权重。举例来说,可以控制处理引擎阵列710由根据等式1执行向前传播计算以支持推断任务,且基于等式1执行向前传播计算和向后传播计算以支持训练过程。
[0227]
神经网络的权重可以连同神经网络将对其进行操作的输入数据750一起存储在存储器子系统704中。存储器子系统704中的权重和输入数据750的地址可基于或映射到分别在权重数据阵列和输入数据阵列中的权重和输入数据750的坐标,这允许基于从其坐标导出的地址而检索权重和输入数据。神经网络还可包含指令,所述指令可由控制器722执行以控制处理引擎阵列710以对权重和输入数据执行各种计算以支持推断任务或训练过程。指令可由编译器产生,并且还可存储在存储器子系统704中、存储器存储体714中或单独的指令缓冲器中。处理引擎阵列710可以输出中间结果,所述中间结果表示神经网络的各个层的输出。在一些情况下,激活引擎716和/或池化引擎718可针对由神经网络的特定层调用的计算而启用。加速器702可以将中间结果存储在存储器子系统704中,以输入到处理引擎阵列710中以计算神经网络的下一层的结果。处理引擎阵列710可以进一步从神经网络的最后一层输出最终结果。最终结果可以存储在存储器子系统704中,接着被复制到主机处理器存储器或另一位置。
[0228]
图8包含示出其中可以使用加速引擎860的主机系统800的实例的框图。图8的加速引擎860是可以包含例如图7中所说明的一个或多个加速器的装置的实例。主机系统800可被配置为工作者节点并且可为图4a的计算系统402。图8的实例主机系统800包含加速引擎860、主机处理器872、dram 830或处理器存储器、i/o装置832,和支持系统874。在各种实施方案中,主机系统800可以包含此处未说明的其它硬件。
[0229]
主机处理器872是能够执行程序指令的通用集成电路。在一些实例中,主机处理器872可以包含多个处理核心。多核处理器可包含同一处理器内的多个处理单元。在一些实例
中,主机系统800可以包含多于一个主机处理器872。在一些实例中,主机处理器872和加速引擎860可以是一个芯片,例如相同封装内的一个或多个集成电路。
[0230]
在各种实例中,主机处理器872可以通过一个或多个通信通道与主机系统800中的其它组件通信。例如,主机系统800可以包含主机处理器总线,主机处理器872可以使用所述主机处理器总线与例如dram 830通信。作为另一实例,主机系统800可以包含i/o总线,例如基于pci的总线,主机处理器872可以通过所述i/o总线与例如加速引擎860和/或i/o装置832通信。在各种实例中,替代地或另外,主机系统800可以包含其它通信通道或总线,例如串行总线、电源管理总线、存储装置总线等。
[0231]
在一些实例中,在主机处理器872上执行的软件程序可以接收或生成输入以由加速引擎860处理。在一些实例中,对于给定输入,程序可以选择合适的神经网络来执行。例如,程序可以用于语言翻译,并且可以选择能够进行语音辨识和/或机器翻译的一个或多个神经网络。在这些和其它实例中,程序可以通过要执行的神经网络配置加速引擎860,和/或可以选择加速引擎860上的神经网络处理引擎,所述神经网络处理引擎先前已被配置成执行所需神经网络。在一些实例中,一旦加速引擎860已开始对输入数据进行推断,主机处理器872就可以管理数据(例如,权重、指令、中间结果、条件层的结果,和/或最终结果)进或出加速引擎860的移动。
[0232]
在一些实例中,使用加速引擎860进行推断的软件程序可以从来自加速引擎860的条件层和/或从例如dram 830中的存储位置读取结果。在这些实例中,程序可以确定神经网络接下来应该采取什么行动。例如,程序可以确定终止推断。作为另一实例,程序可以确定改变推断方向,这可以由较低级别代码和/或神经网络处理器转换到下一层来执行。在这些和其它实例中,神经网络的执行流程可以通过软件协调。
[0233]
dram 830是主机处理器872用于存储主机处理器872正执行的程序代码以及正进行操作的值的存储器。在一些实例中,神经网络的数据(例如,权重值、指令和其它数据)可以完全地或部分地存储在dram 830中。dram是用于处理器存储器的共同数据,并且尽管dram是易失性存储器,但是处理器存储器可以是易失性的和/或非易失性的。尽管此处未说明,但是主机系统800可以包含用于其它目的的其它易失性和非易失性存储器。举例来说,主机系统800可包含存储用于在通电时启动主机系统800的启动代码和/或基本输入/输出系统(bios)代码的只读存储器(rom)。
[0234]
尽管此处未说明,但是dram 830可以存储用于各种程序的指令,所述指令可以加载到主机处理器872中且由所述主机处理器执行。例如,dram 830可以存储用于操作系统、一个或多个数据存储区、一个或多个应用程序、一个或多个驱动器,和/或用于实施本文所公开的特征的服务的指令。
[0235]
操作系统可管理和安排主机系统800的总体操作,例如调度任务、执行应用程序和/或控制器外围装置,以及其它操作。在一些实例中,主机系统800可以托管一个或多个虚拟机。在这些实例中,每个虚拟机可以被配置成执行其自身的操作系统。操作系统的实例包含unix、linux、windows、mac os、ios、android等等。替代地或另外,操作系统可以是专有操作系统。
[0236]
数据存储区可包含由操作系统、应用程序或驱动器使用和/或操作的永久或暂时性数据。此类数据的实例包含网页、视频数据、音频数据、图像、用户数据等。在一些实例中,
数据存储区中的信息可以通过网络提供到用户装置。在一些情况下,数据存储区可以另外或替代地包含存储的应用程序和/或驱动器。替代地或另外,数据存储区可存储标准和/或专有软件库,和/或标准和/或专有应用程序用户接口(api)库。存储在数据存储区中的信息可以是机器可读目标代码、源代码、解译代码或中间代码。
[0237]
驱动器可以包含提供主机系统800中的组件之间的通信的程序。例如,一些驱动器可以提供操作系统与外围装置或i/o装置832之间的通信。替代地或另外,一些驱动器可以提供应用程序与操作系统、和/或应用程序与可由主机系统800访问的外围装置之间的通信。在许多情况下,驱动器可以包含提供易于理解的功能性的驱动器(例如,打印机驱动器、显示器驱动器、硬盘驱动器、固态装置驱动器等)。在其它情况下,驱动器可以提供专有或专用功能。
[0238]
i/o装置832可包含用于连接到用户输入和输出装置的硬件,例如键盘、鼠标、触控笔、平板计算机、语音输入装置、触摸输入装置、显示器或监视器、扬声器和打印机,以及其它装置。i/o装置832还可包含存储驱动器和/或用于连接到网络880的网络接口。举例来说,主机系统800可使用网络接口与存储装置、用户终端、其它计算装置或服务器和/或其它网络以及各种实例进行通信。
[0239]
在各种实例中,i/o装置832中的一个或多个可以是存储装置。在这些实例中,存储装置包含非易失性存储器并且可以存储程序指令和/或数据。存储装置的实例包含磁性存储装置、光盘、固态磁盘、快闪存储器和/或磁带存储装置等等。存储装置可以与主机系统800容纳在同一机箱中,或可以在外部壳体中。存储装置可以是固定的(例如,通过螺钉附接)或可装卸式的(例如,具有物理释放机构且可能具有热插拔机构)。
[0240]
主机系统800中的存储装置、dram 830和任何其它存储器组件是计算机可读存储介质的实例。计算机可读存储介质是能够以可以由例如主机处理器872的装置读取的格式存储数据的物理介质。计算机可读存储介质可以是非暂时性的。当没有将电力施加到介质时,非暂时性计算机可读介质可以保留存储于其上的数据。非暂时性计算机可读介质的实例包含rom装置、磁盘、磁带、光盘、快闪装置和固态驱动器等等。如本文所使用,计算机可读存储介质不包含计算机可读通信介质。
[0241]
在各种实例中,存储在计算机可读存储介质上的数据可包含程序指令、数据结构、程序模块、库、其它软件程序组件,和/或可在例如载波或其它传输等数据信号内传输的其它数据。另外或替代地,计算机可读存储介质可以包含文档、图像、视频、音频,以及可以通过使用软件程序操作或控制的其它数据。
[0242]
图9包含实例网络900的图式,所述网络可包含一个或多个主机系统,例如图8所示的主机系统。例如,图9的实例网络900包含多个节点902a-902h,其中的一个或多个节点可以是例如在图8中示出的主机系统。节点902a-902h中的其它节点可以是其它计算装置,其中的每个节点至少包含用于存储程序指令的存储器、用于执行指令的处理器,以及用于连接到网络900的网络接口。
[0243]
在各种实例中,网络900可用于处理数据。例如,可在节点902a-902h中的一个处或从网络900可与之通信的其它网络908接收输入数据。在此实例中,输入数据可被引导到网络900中包含加速引擎的节点,以供加速引擎操作并产生结果。所述结果可随后传送到所述节点或从中接收输入数据的其它网络。在各种实例中,输入数据可从各种源累积,所述源包
含节点902a-902h中的一个或多个和/或位于其它网络908中的计算装置,并且累积的输入数据可被引导到网络900中的一个或多个主机系统。来自主机系统的结果随后可分布回到从中收集所述输入数据的源。
[0244]
在各种实例中,节点902a-902h中的一个或多个可负责操作,例如累积输入数据以供主机系统操作、跟踪哪些主机系统忙碌以及哪些主机系统可接受更多工作、确定主机系统是否正确地和/或最高效地操作、监视网络安全和/或其它管理操作。
[0245]
在图9的实例中,节点902a-902h使用具有点对点链路的交换架构彼此连接。所述交换架构包含多个交换机904a-904d,所述交换机可布置在例如clos网络之类的多层网络中。在局域网(lan)段之间筛选和转发包的网络装置可被称作交换机。交换机通常在数据链路层(层2)处操作,且有时在开放系统互连(open system interconnect;osi)参考模型的网络层(层3)处操作,并且可支持若干包协议。图9的交换机904a-904d可以连接到节点902a-902h且提供任何两个节点之间的多个路径。
[0246]
网络900还可包含用于与其它网络908连接的一个或多个网络装置,例如路由器906。路由器使用标头和转发表来确定转发包的最佳路径,并使用例如互联网控制消息协议(internet control message protocol;icmp)的协议彼此通信并配置任何两个装置之间的最佳路由。图9的路由器906可用于连接到其它网络908,例如子网、lan、广域网(wan)和/或互联网。
[0247]
在一些实例中,网络900可包含许多不同类型的网络中的任一种或组合,例如电缆网络、互联网、无线网络、蜂窝网络和其它私有和/或公共网络。互连交换机904a-904d和路由器906(如果存在的话)可称作交换机结构910、结构、网络结构或简称为网络。在计算机网络的上下文中,术语“结构”和“网络”在本文中可互换使用。
[0248]
节点902a-902h可以是表示用户装置、服务提供商计算机或第三方计算机的主机系统、处理器节点、存储子系统和i/o机箱的任何组合。
[0249]
用户装置可包含访问应用程序932(例如网络浏览器或移动装置应用程序)的计算装置。在一些方面中,应用程序932可由计算资源服务或服务提供商托管、管理和/或提供。应用程序932可允许用户与服务提供商计算机交互以例如访问网络内容(例如,网页、音乐、视频等)。用户装置可以是计算装置,例如移动电话、智能电话、个人数字助理(pda)、笔记本电脑、上网本计算机、台式计算机、精简客户端装置、平板计算机、电子图书(电子书)阅读器、游戏控制台等。在一些实例中,用户装置可经由另一网络908与服务提供商计算机通信。另外,用户装置可以是分布式系统的部分,所述分布式系统由服务提供商计算机管理、控制或另外是服务提供商计算机的一部分(例如,与服务提供商计算机集成的控制台装置)。
[0250]
图9的节点还可表示一个或多个服务提供商计算机。一个或多个服务提供商计算机可提供本机应用程序,其被配置成在可与用户交互的用户装置上运行。服务提供商计算机可在一些实例中提供计算资源,所述计算资源例如但不限于客户端实体、低时延数据存储装置、耐久的数据存储装置、数据访问、管理、虚拟化、基于云的软件解决方案、电子内容性能管理等等。服务提供商计算机还可用于向用户提供网页寄存、数据库化、计算机应用程序开发和/或实施平台、前述内容的组合等。在一些实例中,服务提供商计算机可被提供为在托管计算环境中实施的一个或多个虚拟机。托管计算环境可包含一个或多个快速预配和释放的计算资源。这些计算资源可包含计算、网络连接和/或存储装置。托管计算环境还可
以被称为云计算环境。服务提供商计算机可包含一个或多个服务器,其可能布置在集群中,布置为服务器集群,或者作为彼此不相关联的个别服务器,并且可托管应用程序932和/或基于云的软件服务。这些服务器可以被配置为集成的分布式计算环境的一部分。在一些方面中,服务提供商计算机可另外或替代地包含计算装置,例如移动电话、智能电话、个人数字助理(pda)、笔记本电脑、台式计算机、上网本计算机、服务器计算机、精简客户端装置、平板计算机、游戏控制台等等。在一些情况下,服务提供商计算机可与一个或多个第三方计算机通信。
[0251]
在一个实例配置中,节点902a-902h可以包含至少一个存储器918和一个或多个处理单元(或处理器920)。处理器920可以硬件、计算机可执行指令、固件或其组合实施。处理器920的计算机可执行指令或固件实施方案可包含以任何合适的编程语言编写的用于执行所描述的各种功能的计算机可执行或机器可执行指令。
[0252]
在一些情况下,硬件处理器920可以是单核处理器或多核处理器。多核处理器可包含同一处理器内的多个处理单元。在一些实例中,多核处理器可共享某些资源,例如总线和第二级或第三级高速缓存。在一些情况下,单核或多核处理器中的每个核心还可包括多个执行逻辑处理器(或执行线程)。在此类核心(例如,具有多个逻辑处理器的核心)中,也可共享执行管线的若干阶段以及较低级别的高速缓存。
[0253]
存储器918可存储可在处理器920上加载和执行的程序指令,以及在执行这些程序期间产生的数据。取决于节点902a-902h的配置和类型,存储器918可以是易失性(例如ram)和/或非易失性(例如rom、快闪存储器等)。存储器918可包含操作系统928、一个或多个数据存储区930、一个或多个应用程序932、一个或多个驱动器934和/或用于实施本文中所公开的特征的服务。
[0254]
操作系统928可支持节点902a-902h基本功能,例如调度任务、执行应用程序,和/或控制器外围装置。在一些实施方案中,服务提供商计算机可托管一个或多个虚拟机。在这些实施方案中,每一虚拟机可被配置成执行其自身的操作系统。操作系统的实例包含unix、linux、windows、mac os、ios、android等等。操作系统928也可以是专有操作系统。
[0255]
数据存储区930可包含由操作系统928、应用程序932或驱动器934使用和/或在其上操作的永久性或暂时性数据。此类数据的实例包含网页、视频数据、音频数据、图像、用户数据等。数据存储区930中的信息可在一些实施方案中通过网络908提供到用户装置。在一些情况下,数据存储区930可另外或替代地包含存储的应用程序和/或驱动器。替代地或另外,数据存储区930可存储标准和/或专有软件库,和/或标准和/或专有应用程序用户接口(api)库。存储在数据存储区930中的信息可以是机器可读目标代码、源码、解译代码或中间代码。
[0256]
驱动器934包含可提供节点中的组件之间的通信的程序。举例来说,一些驱动器934可提供操作系统928与额外存储装置922、网络装置924和/或i/o装置926之间的通信。替代地或另外,一些驱动器934可提供应用程序932与操作系统928、和/或应用程序932及可由服务提供商计算机访问的外围装置之间的通信。在许多状况下,驱动器934可包含提供易于理解的功能性的驱动器(例如,打印机驱动器、显示器驱动器、硬盘驱动器、固态装置驱动器)。在其它状况下,驱动器934可提供专有或专用功能性。
[0257]
服务提供商计算机或服务器还可包含额外存储装置922,其可包含可装卸式存储
装置和/或不可装卸式存储装置。额外的存储装置922可包含磁性存储装置、光盘、固态盘、闪存器和/或磁带存储装置。额外存储装置922可与节点902a-902h容纳在同一机箱中,或可在外部壳体中。存储器918和/或额外存储装置922以及其相关联的计算机可读介质可为计算装置提供计算机可读指令、数据结构、程序模块和其它数据的非易失性存储。在一些实施方案中,存储器918可包含多种不同类型的存储器,例如sram、dram或rom。
[0258]
可装卸式和非可装卸式的存储器918和额外存储装置922是计算机可读存储介质的实例。举例来说,计算机可读存储介质可包含以用于存储信息的方法或技术实施的易失性或非易失性、可装卸式或不可装卸式的介质,所述信息包含例如计算机可读指令、数据结构、程序模块或其它数据。存储器918和额外存储装置922是计算机存储介质的实例。可存在于节点902a-902h中的额外类型的计算机存储介质可包含但不限于pram、sram、dram、ram、rom、eeprom、快闪存储器或其它存储器技术、cd-rom、dvd或其它光学存储装置、盒式磁带、磁带、磁盘存储装置或其它磁性存储装置、固态驱动器或一些其它媒体,其可用于存储所要信息并可由节点902a-902h存取。计算机可读介质还包含任何上述介质类型的组合,包含一个介质类型的多个单元。
[0259]
替代地或另外,计算机可读通信介质可包含计算机可读指令、程序模块或在例如载波或其它传输等数据信号内传输的其它数据。然而,如本文中所使用,计算机可读存储介质不包含计算机可读通信介质。
[0260]
节点902a-902h还可以包含i/o装置926,例如键盘、鼠标、触控笔、语音输入装置、触摸输入装置、显示器、扬声器、打印机及类似物。节点902a-902h还可包含一个或多个通信通道936。通信通道936可提供介质,节点902a-902h的各种组件可通过所述介质通信。通信通道936可呈总线、环、交换结构或网络的形式。
[0261]
节点902a-902h还可以含有网络装置924,其允许节点902a-902h与存储的数据库、另一计算装置或服务器、用户终端和/或网络900上的其它装置通信。
[0262]
本文中所描述的模块可以是软件模块、硬件模块或其合适的组合。如果模块是软件模块,则模块可体现在非暂时性计算机可读介质上,并且由本文所描述的任何计算机系统中的处理器处理。应注意,所描述的过程和架构可在任何用户交互之前实时或以异步模式执行。可按前文图中推荐的方式来配置模块,和/或本文所描述的功能可由作为单独模块存在的一个或多个模块提供,和/或本文所描述的模块功能可分散在多个模块上。
[0263]
因此,本说明书和附图应在说明性意义上而非限制性意义上考虑。然而,显而易见的是,可在不脱离权利要求中所阐述的本公开的更广泛精神和范围的情况下对其进行各种修改和改变。
[0264]
其它变型在本公开的精神内。因此,虽然所公开的技术可接受各种修改和替代构造,但其某些说明的示例已在图中示出且已在上文详细描述。然而,应理解,无意将本公开限于所公开的具体形式,相反,意在涵盖落入所附权利要求书中所限定的本公开的精神和范围内的所有修改、替代构造和等效物。
[0265]
除非本文另有说明或与上下文明显矛盾,否则在描述所公开实例的上下文中(尤其在所附权利要求书的上下文中)使用词语“一(a/an)”和“所述”以及类似指示物应理解为涵盖单数和复数。除非另有说明,否则术语“包括(comprising)”、“具有”、“包含”和“含有”应理解为开放式术语(即,意指“包含但不限于”)。术语“连接”应理解为部分或全部地包含
在内、附接到或接合在一起,即使是在存在中间物的情况下也是如此。除非本文中另有说明,否则本文中对值的范围的引述仅旨在用作个别地提及属于所述范围内的每个单独值的简写方法,并且每个单独值并入本说明书中,如同其在本文中个别地引用一样。除非本文中另外指明或明显与上下文相矛盾,否则本文所述的所有方法均可以以任何合适的顺序执行。除非另有主张,否则本文中提供的任何和所有实例或示例性语言(例如,“例如”)的使用仅旨在更好地阐明本公开的实例,而不构成对本公开的范围的限制。本说明书中的任何语言都不应理解为指示任何未请求保护的要素对于实践本公开是必需的。
[0266]
除非另有具体陈述,否则例如词组“x、y或z中的至少一者”等分离性语言在所使用的上下文内希望理解为一般呈现项目、术语等可为x、y或z,或其任何组合(例如x、y和/或z)。因此,此类分离性语言一般无意且不应暗示某些实例要求x中的至少一个、y中的至少一个或z中的至少一个各自都存在。
[0267]
本文中描述本公开的各种实例,包括本发明人已知的用于执行本公开的最佳模式。在阅读上述描述之后,本领域的技术人员将清楚那些实例的变化。本发明人期望所属领域的技术人员在适当时使用此类变化,并且本发明人打算以与本文中具体描述的方式不同的方式来实践本公开。因此,本发明包含适用法律所允许的在此随附的权利要求书中所述的主题的所有修改和等效物。此外,除非本文另外指示或另外明显与上下文相矛盾,否则本公开涵盖上文所描述的要素以其所有可能变化形式的任何组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1