一种基于程序分析的Java函数注释自动生成方法与流程
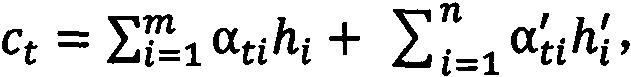
一种基于程序分析的java函数注释自动生成方法
技术领域
[0001]
本发明属于计算机技术领域,尤其是软件技术领域。本发明提出了一种基于程序分析的java函数注释自动生成方法,能够通过构建循环神经网络模型自动为函数生成注释。有效解决了当前项目中现有函数注释的稀缺性、不规范性、不一致性等问题,从而提高代码可读性和可维护性。
背景技术:
[0002]
随着互联网技术的高速发展以及软件产业日新月异的变化,越来越多的项目开始使用分布式协作开发模式。开发者们通常会建立自己的分支,在自己的分支上进行开发,随后将分支合并到主分支上。这样能最大程度地利用分布式开发的特点,大大提高开发效率。与此同时,分布式协作开发过程中的常见问题有:开发者在开发或审查代码时,往往会花费较多的时间去理解其他开发者写的代码。为了解决这个问题,一个直观的解决方法是开发者在开发时留下适当的注释,用自然语言描述开发者的意图或代码的功能。良好的注释对代码审查、软件维护起着至关重要的作用。
[0003]
然而,由于开发者的开发习惯不同,现有项目中往往会出现注释稀缺、注释不规范、注释与代码意图不一致等问题。针对这些问题的一个解决思路是信息检索技术(information retrieval)。对于待生成注释代码段,在数据集中根据代码相似性计算找到与之匹配的最相似的代码段,并使用其注释作为生成注释。但随着软件演化的速度日益加快,这种方法对数据集的要求也随之增高。随着近年来深度学习(deep learning)的持续火热,另一解决思路受翻译工作的启发,函数和注释本质上相当于两种源语言,可以通过深度翻译模型来构建特殊映射。在大量数据的训练下不断优化模型,最终将函数输入到训练好的模型并输出所生成的自然语言注释。
[0004]
先前已经有相关工作使用上述思路对函数与注释进行建模并自动生成注释。但是先前的工作并未充分利用项目中所包含的对注释生成有利的信息和深度学习的优势,导致生成的注释在准确性、可理解性和流畅性上有一定的缺陷。
[0005]
因此,本发明的主要目标是基于程序分析并充分利用项目中所有对注释生成有利的信息(包括函数的基本信息和传递其所调用函数的注释),随后基于深度学习领域的循环神经网络来构建模型并生成函数注释,从而提高所生成注释的质量,使得代码具备更好的可读性和可维护性。
技术实现要素:
[0006]
本发明的主要工作是提出一种基于程序分析的java函数注释自动生成方法,使用到深度学习领域的循环神经网络技术。首先,本发明关注的是java函数。java是软件开发中最受欢迎的语言之一,其语言特点有着丰富的结构、类型信息。此外,目前针对java语言的程序分析技术较为成熟且广泛使用,能够比较方便地提取到生成注释所需要的基本信息。其次,本发明关注如何使用程序分析的结果进行模型训练,并使用训练好的深度学习模型
进行注释生成。最后,本发明会对生成结果进行机器指标和人工指标评估,并和现有方法进行比较,力求生成质量更高的注释。
[0007]
针对以上问题,本发明的工作和贡献如下:
[0008]
1.构建基于jdt和soot的java函数信息提取器:使用github api对github上使用java为主语言并以stars数作为排序指标得到的前2000个java项目,clone至本地并筛选出其中使用maven作为管理工具的项目后进行编译。对编译成功的727个项目,使用jdt和soot两个主流java程序分析工具对项目中的源文件(.java)和编译文件(.class)进行数据提取。
[0009]
在超过65万个java文件中分析了超过578万个java方法,包括每个函数的词法和语法结构。随后针对其是否有注释进行过滤,最后得到了包含176万个函数的函数信息表和包含1073万个函数调用关系的调用关系表。
[0010]
为提取精确的调用关系,使用soot对编译过程文件字节码进行抽取,从jvm指令层面区分invokeinterface(调用接口方法)、invokevirtual(调用对象实例方法)、invokestatic(调用类静态方法)、invokespecial(调用特殊处理的实例方法)四种函数调用类型,解决了单纯使用正则表达式或其他静态分析工具获取调用关系精度不准确的问题。
[0011]
每个函数信息表表项为<序号,类名,函数名,函数修饰符,函数体,函数参数,函数参数类型,函数返回值,函数返回值类型,函数抽象语法结构(ast),函数注释(javadoc)>,每个函数调用关系表表项为<序号,调用函数类名,调用函数修饰符,调用函数函数名,调用函数参数,调用函数返回值,被调用函数callee类名,被调用函数修饰符,被调用函数函数名,被调用函数参数,被调用函数返回值,调用类型>。
[0012]
2.构建基于映射和注释分类注释传递器:针对函数信息表和函数调用关系表,使用函数名、函数修饰符、函数参数等信息确定同一函数,并将被调用函数的注释进行分类,将分类结果为how型(描述函数如何实现的注释)、what型(描述函数功能的注释)和why型(描述函数为何如此设计的注释)注释传递到调用函数处,作为调用函数的基本信息,提供指示性信息,以丰富函数信息表,并作为后续模型训练的数据集。
[0013]
3.构建基于循环神经网络的深度学习翻译模型。将有传递注释的超过17万个java函数划分训练集和测试集。为了解决长期记忆和方向传播中的梯度等问题,使用循环神经网络的变种双向gru对训练集数据进行训练,得到一个序列-序列(seq2seq)翻译模型,源语言编程java语言,目标语言为函数注释。模型输入为两个编码器和一个解码器。其中一个编码器接收函数体token流,用于学习函数的编程语言特性,其由函数信息表中函数体按照一个或多个空格、标点符号、换行符以及驼峰法则等分割。另一个编码器接收传递注释token流,用于学习项目中已经包含的自然语言特性,通过传递注释1-n加特殊分割符
‘
##’拼接而成,即单行数据为<传递注释1##传递注释2##...>。
[0014]
给定一个代码片段x=x1,x2...,x
t
,...x
m
,对于单个输入词x
t
,双向gru会将输入编码器成前向和后向两个隐藏状态均由当前token和前一个隐藏状态通过函数关系得到,如所示最终隐藏状态由前向和后向两个隐藏状态拼接而成,即
[0015]
同理,给定一个传递代码片段x
′
,编码器也能得到其在模型中的隐藏状态为了解决长序列向定长向量变换过程中信息丢失的瓶颈问题,引入注意力机制(attention mechanism)。在注意力机制下,两个编码器得到一个上下文向量其中α
ti
和h
i
为接收函数体token的编码器注意力分布和隐藏状态,而α
′
ti
和h
′
i
为接收传递注释的编码器的注意力分布和隐藏状态。解码器被设计用来生成目标注释序列y=y1,y2...,y
t
,...y
m
。每个生成词y
t
由其前面的所有生成词y1到y
t-1
和输入x的条件概率决定,即其中是上下文向量c
t
和解码器中隐藏状态s
t
拼接而成,即训练阶段之后,得到最终模型m(x|x
′
),m(x|x
′
)可预测任意给定一个代码片段x和一个传递代码片段x
′
,输出前一个单词为y
t-1
的情况下输出每一个位置单词为y
t
的概率值p(y
t
|x,x
′
,y
t-1
)。
[0016]
为了增强结果的普适性和说服力,复现了当前现有的最好工作并在相同实验环境下进行了十则交叉验证。结果显示,本发明的合成bleu指标和人工精度指标显著高于现有工作。
附图说明
[0017]
图1为本发明基于jdt和soot的java函数信息提取示意图
[0018]
图2为本发明基于映射和注释分类的注释传递示意图
[0019]
图3为本发明基于双向循环神经网络gru训练示意图
具体实施方式
[0020]
本发明具体包括以下步骤:
[0021]
1)首先使用github api对java项目stars数进行排序,得到前2000个java项目,并使用静态分析工具jdt,提取项目中的函数信息,遍历每个java类下每个函数中的每个语句,提取词法和语法特征,形成函数信息表。
[0022]
2)进入项目目录执行[mvn package-dskiptests],编译项目并过滤掉其中的所有单元测试,随后为每个java文件生成编译过程.class文件,并基于静态分析工具soot遍历java类所有方法及其调用关系字节码,提取其中的函数间调用关系及调用类型,形成函数调用关系表。
[0023]
3)根据函数修饰符、函数名、函数所在类名、参数类型等信息唯一确定函数,并且建立信息表和函数调用关系表映射,将被调用函数的注释进行分类,随后将指定类别的注释传递到调用函数处,作为调用函数的基本信息,丰富函数信息表,并用于后续训练。
[0024]
4)将步骤3)得到的含有传递注释的函数信息表按照9∶1的比例随机划分训练集和测试集,基于深度学习模型循环神经网络的变种双向gru对训练集数据进行训练,结合注意力机制(attention mechanism),得到一个序列-序列(seq2seq)翻译模型,将函数体token流和传递注释token流作为编码器输入,函数注释token流作为解码器输入。为提高训练效率,使用gpu进行训练。训练结束后使用测试数据中函数体token和传递注释token输入模型测试,自动生成注释。
[0025]
5)将步骤4)中剩下的10%测试函数按照训练输入格式切分,输入训练好模型,按照模型参数下条件概率顺序地预测出每一个位置概率最大的单词向量,最后形成完整语句,作为生成注释。
[0026]
步骤1)中提取函数信息并形成信息表如附图图1所示,具体流程如下:使用github api对java项目stars数进行排序,得到前2000个java项目,clone至本地并筛选出其中使用maven作为管理工具的项目。随后使用静态分析工具jdt提取每个java函数的基本信息,形成函数信息表,每个表项为<序号,类名,函数名,函数修饰符,函数体,函数参数,函数参数类型,函数返回值,函数返回值类型,函数抽象语法结构(ast),函数注释(javadoc)>。
[0027]
步骤2)对步骤1)中用maven管理的java项目进行筛选,然后进入项目目录执行[mvn package-dskiptests],编译项目并过滤掉其中的所有单元测试。处理4种java常见调用方法类型,即invokeinterface(调用接口方法)、invokevirtual(调用对象实例方法)、invokestatic(调用类静态方法)、invokespecial(调用特殊处理的实例方法,例如构造函数)。为了区分调用类型,获取函数的正确路径从而获得高精度的调用关系,对编译后.class文件使用静态分析工具soot进行分析,提取字节码中关键字invokeinterface、invokevirtual、invokestatic、invokespecial,并在字节码层次抽取函数调用关系,形成函数间调用关系表。每个表项为<序号,调用函数类名,调用函数修饰符,调用函数函数名,调用函数参数,调用函数返回值,被调用函数callee类名,被调用函数修饰符,被调用函数函数名,被调用函数参数,被调用函数返回值,调用类型>。
[0028]
步骤3)基于步骤1)和步骤2)中得到的函数信息表和函数调用关系表,构建映射,基于函数修饰符、类名、函数名、参数和返回值唯一确定同一函数,将被调用函数的函数注释进行分类,将how型、what型和why型注释传递到调用函数处。最后结果作为后续步骤的训练数据。每个数据项包含<序号,函数信息,传递注释1,传递注释2,...,传递注释n>,其中函数信息包含步骤1)中函数信息表中所有内容,传递注释1-n为进行传递后传递至该函数的注释,附图图2展示注释传递过程。
[0029]
步骤4)基于步骤3)得到的含有传递注释的函数信息表按照9∶1比例随机划分训练集和测试集,其中90%数据用于训练。如附图图3所示,训练基于循环神经网络rnn的变种双向gru,是一个典型的序列-序列(seq2seq)模型。模型输入为两个编码器和一个解码器。其中一个编码器接收函数体token流,用于学习函数的编程语言特性,由函数信息表中函数体按照一个或多个空格、标点符号、换行符以及驼峰法则等分割。另一个编码器接收传递注释token流,用于学习项目中已经包含的自然语言特性,其由步骤3)中传递注释1-n加特殊分割符
‘
##’拼接而成,即单行数据为<传递注释1##传递注释2##...>。
[0030]
给定一个代码片段x=x1,x2...,x
t
,...x
m
。对于单个输入词x
t
,双向gru会将输入编码器成前向和后向两个隐藏状态均由当前token和前一个隐藏状态通过函数关系得到,如所示最终隐藏状态由前向和后向两个隐藏状态拼接而成,即最终隐藏状态由前向和后向两个隐藏状态拼接而成,即
[0031]
同理,给定一个传递代码片段x
′
,编码器也能得到其在模型中的隐藏状态为了解决长序列向定长向量变换过程中信息丢失的瓶颈问题,引入注意力机
制(attention mechanism)。在注意力机制下,两个编码器得到一个上下文向量其中α
ti
和h
i
为接收函数体token的编码器注意力分布和隐藏状态,而α
′
ti
和h
′
i
为接收传递注释的编码器的注意力分布和隐藏状态。解码器被设计用来生成目标注释序列y=y1,y2...,y
t
,...y
m
。每个生成词y
t
由其前面的所有生成词y1到y
t-1
和输入x的条件概率决定,即其中是上下文向量c
t
和解码器中隐藏状态s
t
拼接而成,即训练阶段之后,得到最终模型m(x|x
′
),m(x|x
′
)可预测任意给定一个代码片段x和一个传递代码片段x
′
,之前输出的所有单词为y
<t
的情况下输出每一个位置单词为y
t
的概率值p(y
t
|x,x
′
,y
<t
)。
[0032]
步骤5)基于步骤4)中剩余的10%的测试集函数信息,均处理成步骤4)得到模型m(x|x
′
)中编码器所接收的输入,即函数体token流和传递注释token流,在每个位置t上预测得到所有可能生成单词的概率p并按照从大到小进行排序,选出概率p最大的词汇y
t
,最后将所有位置上生成单词向量转化成单词,并拼接形成注释。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1