一种基于三目的无标记点视觉运动捕捉方法
1.本发明属于计算机视觉领域,特别是基于三目的无标记点视觉运动捕捉方法。
背景技术:
2.运动捕捉在影视动画制作等领域有着广泛的需求,通常利用惯性运动传感器和视觉传感器来实现。其中利用惯性运动传感器进行运动捕捉精度较低,利用光学传感器进行运动捕捉精度高。以vicon为代表的光学运动捕捉系统采用4路或6路以上的高速红外摄像机采集贴在人体关节点上的被动发光标记点,利用视觉测量的方法构建人体关节运动三维数据,已经在行业内得到了成熟的应用。为了获得准确完整的人体关节点信息,使用vicon系统必须在人体表面贴上反光球,且必须安装4路以上的高速红外摄像机。安装的红外相机越多,重建的人体运动越准确,受遮挡影响也越小,但成本也越高。除了利用红外摄像机捕捉人体运动,还有诸多方法利用深度传感器来实现人体运动重建。例如已有授权专利“一种基于单个kinect的简易高效三维人体重建方法”(201610502690x)利用单个的kinect rgbd传感器实现人体运动捕捉,公开专利“基于骨架跟踪的动态实时三维人体重建方法及系统”(2017114088488),“一种基于合成深度数据的三维人体重建方法”(2019105400408)均是利用采集的深度图来实现。
技术实现要素:
3.本发明的目的在于提出一种利用3路相机深度生成人体形状,捕捉人体运动的方法。与已有的vicon系统相比,提出的方法只需要3个视觉相机捕捉视频序列,仅需测试者穿上紧身的衣裤,无需在人体上贴反光标记;获得人体运动不只是关节点的运动,而是整个人体形状的运动。
4.本发明技术方案为一种基于三目的无标记点视觉运动捕捉方法,该方法包括:
5.步骤1:从水平的三个方向采集目标视频,这三个方向两两之间夹角相等;
6.步骤2:从视频图像中提取每一帧中目标的轮廓;
7.步骤3:建立深度神经网络预测人体形状与姿态;
8.建立的神经网络结构包括两部分,分别为:轮廓特征提取和人体smpl模型参数预测;其中轮廓特征提取采用深度残差网络、或u形网络、或叠层沙漏网络;人体smpl参数模型,该参数模型中人体形状表示为10个形状参数和72个姿态参数,smpl模型参数预测采用多层感知机或误差迭代网络;轮廓特征提取采用叠加的双层沙漏网络与深度残差网络的组合,人体smpl模型参数预测采用误差迭代网络;叠加的双层沙漏网络中输出2d关节点分别为p0,p1,采用p
gt
作为中间监督信息,人体参数预测输出为人体体型参数向量人体姿态参数人体相对于三相机视野中心偏移量
9.步骤4:训练深度神经网络;
10.训练的目标函数如下:
[0011][0012][0013]
其中,λ
reg
,λ
p
,λ
β
,λ
θ
分别为2d关节点误差权重,骨架反投影误差权重,smpl体型参数误差权重和smpl姿态参数误差权重;表示三维关节点集合,表示3d关键点个数,γ(
·
)表示人体的smpl模型关键点映射函数;p0,p1分别是网络中间部分预测的2d关节点,p
gt
为2d关节点的真值,i表示第i个关节点,由于存在三个视角这里将三个视角的向量,合并后p
gt
长度为长度为表示由smpl参数模型生成的人体网格;c表示相机的编号,π
c
表示相机编号为c的相机投影函数;
[0014]
步骤5:利用步骤4训练的人体形状生成网络针对单帧进行人体形状计算,再对计算得到的单帧人体形状进行防穿模计算;在时间序列下多帧连续处理过程中采用如下优化函数进行优化;
[0015][0016]
设相机的帧率fps≥f,f为阈值,视人体在帧与帧之间的运动为匀速运动,针对位于滑动窗口中的帧,滑动窗口大小为2n+1;优化函数中,d
c
为编号为c相机下二值轮廓图像,t
j
表示第j时刻,为t
j
时刻编号为c相机下二值轮廓图像;π
c
为编号为c的相机投影模型,投影后结果为二值轮廓图像;为t
j
时刻smpl的姿态参数,为t
j
时刻相对于时三相机中心位置的偏移量;代表t
j
时刻位于第p个关节点的球体半径;n(k)为第k关键点的邻接关键点集合;d(
·
)为距离函数。
[0017]
与现有技术相比,本发明所具有的优点和有益效果,性能的提高、可靠性的提高、成本的降低、工艺的简化、节能环保等。本发明的技术需要的硬件设备相机更少;现有技术通常捕获的动作为3维的点,而本发明捕获的为3d的网格,包含人体的体型和姿态。
[0018]
步骤4的目标函数主要有以下三点优势:
[0019]
1.本方法对人体的体型姿态参数进行监督,使得网络可以学习到人体的形状信息,而并非传统方法的多个标记点。该优势的主要原因为本方法中使用人体形状模型,该模型拥有人体形状的先验知识。
[0020]
2.本方法中同时将轮廓作为输入信息与监督信息,输入信息更少分布更单一网络训练时间更短。同时因为输入为轮廓信息与场景无关,训练数据可以通过生成大量获得。
[0021]
3.本方法中使用三相机同时对人体进行捕捉,相比传统姿态捕捉系统的相机数量更少,同时本方法也不需要在人体表面贴状标记点,只需要人体的服装紧身即可。传统方法在人体全身安装标记点,为了获得准确标记点的位置每个标记点需要至少被两台相机所观
测到故需要多台相机同时工作,本方法由于在训练过程中有人体形状的真值对相机的个数需求并不高,只需要三台相机消除轮廓信息所带来的不确定性即可。
[0022]
步骤5的优化函数主要有以下三点优势:
[0023]
1.能够减小由深度神经网络带来的误差。由于本方法的输入信息为轮廓,理想情况下生成的人体形状与输入信息应保持一致,通过输入信息直接对结果进行监督可以进一步优化深度神经网络生成的人体形状的误差。
[0024]
2.能够减少自穿模不合理情况发生。使用轮廓信息作为输入轮廓内部细节不明确,容易导致自穿模现象的发生,通过在人体形状内部添加防碰撞球体能够减少人体形状的自碰撞情况。
[0025]
3.能够利用连续时间信息进一步对减少误差。人体在运动过程中形状的变化应该是连续的,通过对人体的速度变化进行约束优化时间上连续性,能够减小中间帧输出结果突变的情况,进一步减小重构结果误差。
附图说明
[0026]
图1为本发明硬件系统示意图。
[0027]
图2为本发明输入图像的实例。
[0028]
图3为方碰撞球体添加示意图。
[0029]
图4为3d人体形状序列重建方法流程图。
[0030]
图5为单帧轮廓重构结果图。
[0031]
图6为连续16帧轮廓重建图。
[0032]
图7为连续10帧“跳”的动作轮廓重建图。
[0033]
图8为连续10帧“走0”的动作轮廓重建图。
[0034]
图9为连续10帧“走1”的动作轮廓重建图。
[0035]
图10为连续10帧“跑0”的动作轮廓重建图。
[0036]
图11为连续10帧“跑1”的动作轮廓重建图。
具体实施方式
[0037]
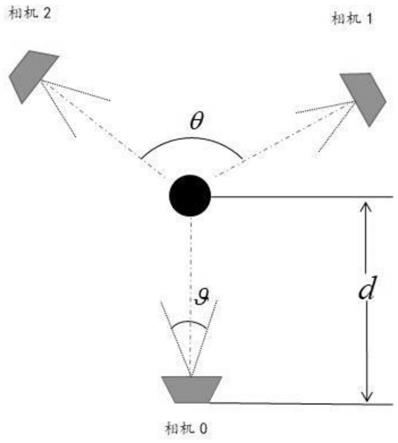
1.本发明硬件系统由三个相机组成,相机之间的夹角为θ,高度为h,相机距离人体距离为d,相机视野范围为人体在三相机视野公共范围内运动。采集环境背景需要设置为单一背景,比如绿色,待重建对象着紧身的衣物,且衣物颜色与背景色差距较大,以便于人体轮廓提取。三个相机需要在捕获数据前进行校正获得各自的相机内参矩阵k0,k1,k2用以矫正其后2d、3d关节点坐标。
[0038]
2.轮廓提取。轮廓提取采用现有图像分割技术进行,由于背景颜色与人体颜色不同,可以直接将人体从背景中直接分割出来,形成人体轮廓,作为第3步的输入。
[0039]
3.建立深度神经网络预测人体形状与姿态。神经网络结构分为两部分,轮廓特征提取与人体smpl模型参数预测。其中轮廓特征提取可使用现有各种深度神经网络结构,例如深度残差网络,u形网络,叠层沙漏网络等等;专利采用人体smpl参数模型,该参数模型将人体形状表示成10个形状参数和72个姿态参数,smpl模型参数预测可采用多层感知机,误差迭代网络等等。本专利中深度神经网络采用特征提取采用叠层沙漏网络与深度残差网络
的组合,人体参数预测采用误差迭代网络;叠加的双层沙漏网络中输出2d关节点分别为p0,p1采用p
gt
作为中间监督信息,人体参数预测输出人体体型参数向量人体姿态参数人体相对于三相机视野中心偏移量
[0040]
4.训练深度神经网络。深度神经网络训练期间采用人体轮廓数据作为输入,数据采用mosh数据集(包含不同人体形状不同姿态序列的数据集)作为人体形状的真实值,并使用渲染器(pyrender)设置与硬件系统一致的三个虚拟相机,渲染出在三个视角下的人体轮廓作为输入,渲染结果示意图如图2所示。训练的目标函数如下:
[0041][0042][0043]
其中λ
reg
,λ
p
,λ
β
,λ
θ
分别为2d关节点误差权重,骨架反投影误差权重,smpl体型参数误差权重和smpl姿态参数误差权重。表示三维关节点集合,表示3d关键点个数,γ(
·
)表示人体的smpl模型关键点映射函数。p0,p1分别是网络中间部分预测的2d关节点,p
gt
为2d关节点的真值,i表示第i个关节点,由于存在三个视角这里将三个视角的向量,合并后p
gt
长度为度为表示由smpl参数模型生成的人体网格。c表示相机的编号,π
c
表示相机编号为c的相机投影函数。
[0044]
5.利用步骤4训练的人体形状生成网络针对单帧进行人体形状预测,再优化人体形状重建序列,同时考虑穿模情况。在人体形状关节点上添加球体,球体添加的情况如图4所示。在图4中灰色圆点代表人体网格所组成的点,其中黑色叉状点代表着添加球体的中心部位,在人体左膝盖灰色球体为添加球体在模型内的示意情况。
[0045]
对时间序列进行处理的过程中,假设相机的帧率fps≥f,f为阈值,视人体在帧与帧之间的运动为匀速运动,针对位于滑动窗口中的帧(滑动窗口大小为2n+1),建立如下优化函数:
[0046][0047]
其中d
c
为编号为c相机下二值轮廓图像,t
j
表示第j时刻,为t
j
时刻编号为c相机下二值轮廓图像;π
c
为编号为c的相机投影模型,投影后结果为二值轮廓图像;为t
j
时刻smpl的姿态参数,为t
j
时刻相对于时三相机中心位置的偏移量;代表t
j
时刻位于第p个关节点的球体半径;n(k)为第k关键点的邻接关键点集合。d(
·
)为距离函数。
[0048]
对于产品发明应描述产品构成、电路构成或者化学成分、各部分之间的相互关系、
工作过程或操作步骤;对于方法发明应写明步骤、参数、工艺条件等,可提供多个具体实施方式。
[0049]
在实验中,相机间夹角均设置约为θ=120
°
,相机视野范围约若相机视野范围大于该角度则通过图像裁剪获得该范围的图像。相机高度约h=0.8m,相机距离人体约t=4m。帧率阈值f=120,窗口大小2n+1=5。
[0050]
为进一步评定专利的有效性,进行定量误差分析实验。实验中采用mosh数据集中未被训练部分作为真实值,并采用步骤4中的策略生成三视角轮廓信息作为输入,对神经网络输出和最终结果进行误差分析。实验中采用平均网格点误差与平均关节点误差作为评判标准,其中平均网格点误差为网格上点与点之间的欧式距离平均值,平均关节点位置误差为关节点的欧式距离误差平均值。
[0051]
表1.序列定量分析,重建误差(单位:cm)
[0052]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1