一种基于双向循环卷积生成对抗网络的视频模糊去除方法
1.本发明涉及一种基于双向循环卷积生成对抗网络(btsrnn
‑
wgan)的视频模糊去除方法,属于数字视频处理、模式识别和计算机视觉领域,主要涉及视频和图像复原技术。在各类基于图像和视频的应用系统中有广阔的应用前景。
背景技术:
2.图像复原技术是指利用单张或多张退化图像及关于退化过程的先验知识得到退化前理想图像的技术。导致图像或视频发生退化的主要原因包括外部成像环境的影响和内部成像设备的影响,退化的主要表现形式为:图像模糊、畸变、噪声等。图像或视频的退化除降低其视觉效果外,还会严重影响相关高级视觉任务,如目标检测、目标跟踪、三维重建等,因此图像复原技术是计算机视觉领域一项重要的预处理技术。在对动态场景进行视频画面的捕捉时,最常见的退化现象是视频图像出现模糊,视频模糊产生的原因包括相机对焦不准产生的失焦模糊,但更常见的是目标和相机在曝光时间内发生相对运动而产生的运动模糊。在暗光环境下拍摄视频时,不得不通过增大曝光时间来拍摄足够亮度的视频,就更容易发生视频运动模糊。此问题是动态场景下视频或图像序列拍摄的常见问题,对所拍摄视频的质量有严重影响。由于视频模糊因素的时空可变性,由模糊视频重建清晰视频仍是一项具有挑战性和研究价值的任务。
3.一些早期的视频去除模糊的方法基于所谓“幸运帧(lucky frames)”方法,他们认为在一段长曝光视频中,会存在一些相对清晰的帧,借此可以对其他帧进行配准进而重建整个清晰视频。如matsushita y等人使用基于图像数据统计的方式找出“幸运帧”并进行视频图像的配准,然后在相邻帧之间进行锐利像素的转移和插值,实现视频模糊去除(参见文献:松下等,带有运动修复的全帧视频稳定.美国电气与电子工程师协会模式分析与机器智能学报,2006,1150
‑
1163.(matsushita y,ofek e,ge w,et al.full
‑
frame video stabilization with motion inpainting[j].ieee transactions on pattern analysis and machine intelligence,2006,28(7):1150
‑
1163.))。后来,基于反卷积的视频去模糊技术被广泛研究,这些研究大多是通过视频的帧间关系估计出模糊核,再通过反卷积技术来实现视频去模糊。如wulff j等人将图像分割为不同层,再使用不同模糊核对它们进行反卷积,目的是处理随空间变化的模糊参数,使模糊估计更加准确(参见文献:沃尔夫等,模糊视频的多层建模.欧洲计算机视觉学会,2014.(wulff j,black m j.modeling blurred video with layers[c]//european conference on computer vision.springer,cham,2014:236
‑
252.))。ren等人采用了像素级分割(参见文献:任文琦等,基于语义分割和像素非线性核的视频去模糊.美国电气与电子工程师学会国际计算机视觉学会.2017,1077
‑
1085.(ren w,pan j,cao x,et al.video deblurring via semantic segmentation and pixel
‑
wise non
‑
linear kernel[c]//proceedings of the ieee international conference on computer vision.2017:1077
‑
1085.))。然而,以上这些基于样本的方法具有较大的局限性,计算成本较高,处理速度也较慢,对样本有较高要求,当找不到有效“幸运
帧”,或模糊核的估计不准确时,很难得到理想复原结果。
[0004]
近年来,随着深度学习技术飞速发展,一些基于深度学习的方法也被用在了视频模糊去除领域。sim h等人设计了一个模糊核学习网络,学习像素级模糊核参数,再通过滤波和线性组合等方式重建清晰视频(参见文献:西姆等,基于单像素自适应核的深度运动去模糊网络.美国电气与电子工程师学会计算机视觉和模式识别学会,2019,0
‑
0.(sim h,kim m.a deep motion deblurring network based on per
‑
pixel adaptive kernels with residual down
‑
up and up
‑
down modules[c]//proceedings of the ieee conference on computer vision and pattern recognition workshops.2019:0
‑
0.));su s等人提出了一种利用卷积神经网络(cnn)进行视频去模糊的方法,他们的网络输入5个连续视频帧,输出一帧重建清晰图像,为了处理严重模糊,他们使用光流法来对齐输入的5帧视频(参见文献:苏等,对于手持相机的深度视频去模糊.美国电气与电子工程师学会计算机视觉和模式识别学会,2017.(su s,delbracio m,wang j,et al.deep video deblurring for hand
‑
held cameras[c]//proceedings of the ieee conference on computer vision and pattern recognition.2017:1279
‑
1288.))。另一方面,一些研究者注意到了循环神经网络(rnn)在处理序列信号时的优越性,尝试使用基于rnn的方法来进行视频模糊去除。kim t h等人通过rnn重用过去时刻提取出视频帧的隐藏特征,并设计一个动态时间混合网络(dynamic temporal blending network),使得网络输出具有更好的时间一致性(参见文献:吉米等,基于动态时间混合网络的在线视频去模糊,美国电气与电子工程师学会国际计算机视觉学会,2017.(hyun kim t,mu lee k,scholkopf b,et al.online video deblurring via dynamic temporal blending network[c]//proceedings of the ieee international conference on computer vision.2017:4038
‑
4047.));nah s等人在提取图像的特征图时采用帧内迭代的方法更新从过去帧获得的隐藏状态,在不增加网络复杂度的基础上提高网络的性能(参见文献:南等,用于视频去模糊的帧内迭代循环神经网络,美国电气与电子工程师学会计算机视觉和模式识别学会,2019.(nah s,son s,lee k m.recurrent neural networks with intra
‑
frame iterations for video deblurring[c]//proceedings of the ieee conference on computer vision and pattern recognition.2019:8102
‑
8111.));最近,zhong z等人在使用rnn提取图像特征的基础上,设计了一个全局时空注意模块(global spatio
‑
temporal attention module),对多帧图像特征图进行融合,进而重建出一帧清晰图像(参见文献:钟志航等,用于视频去模糊的高效时空循环神经网络,欧洲计算机视觉学会,2020,191
‑
207.(zhong z,gao y,zheng y,et al.efficient spatio
‑
temporal recurrent neural network for video deblurring[c]//european conference on computer vision.springer,cham,2020:191
‑
207.))。
[0005]
然而,目前基于rnn的视频去模糊方法大多只考虑来自过去的信息,即只用了正向传递的rnn序列,对未来信息利用不够或基本没有利用,导致重建视频清晰度不够。本发明认为未来信息同样具有利用价值,代表当前时刻视频图像可能的变化趋势,因此也可为当前时刻视频图像的重建提供信息。基于此,本发明提出了一种新型视频模糊去除方法:基于双向循环卷积生成对抗网络(btsrnn
‑
wgan)的视频模糊去除方法。在本发明中,使用正反双路rnn序列,使得来自过去和未来的信息得到同等程度重视,并用于当前时刻视频图像的重建,可有效提升复原视频质量。
技术实现要素:
[0006]
针对上述问题,本发明目的在于提供一种基于双向循环卷积生成对抗网络(btsrnn
‑
wgan)的视频模糊去除方法,为了更充分地利用视频序列在时间域上的信息,使用两条传播方向相反的rnn序列,再结合基于时空域注意力的融合重建模块,可有效提升视频复原质量和稳定性。
[0007]
为了实现这个目的,本发明的技术方案整体思路是采用生成对抗网络架构,利用以双向循环神经网络为主体的清晰视频生成网络产生高质量复原清晰视频,再利用判别网络对复原视频和参考清晰视频进行判别,两个网络相互对抗,使清晰视频生成网络的性能不断得到提升。本发明的算法技术思路主要体现在以下四个方面:
[0008]
1)设计双向循环神经网络模型,充分利用视频序列的时序关系,有效利用过去和未来信息,重建高质量清晰视频。
[0009]
2)设计融合重建模块,融合当前帧和其相邻帧有效信息,提高当前帧重建质量。
[0010]
3)使用全局残差连接,提高网络表达能力和收敛速度。
[0011]
4)使用生成对抗网络架构,利用对抗损失提高网络对视频细节和纹理的复原效果。
[0012]
本发明涉及一种基于双向循环卷积生成对抗网络的视频模糊去除方法,该方法具体步骤如下:
[0013]
步骤一:利用清晰视频生成网络产生高质量去除模糊的复原视频。首先使用双向rnn序列对输入视频进行特征提取;再使用时空注意模块提取当前帧和其相邻帧的有效特征并进行融合;随后通过重建模块从融合结果恢复与原输入大小相同的图像;最后通过全局残差连接将当前帧与重建模块的输出相加,得到当前帧的复原结果;将每一帧的复原结果串联起来,得到复原视频。
[0014]
步骤二:利用判别网络对复原视频和参考清晰视频进行分类判别。判别网络以深度卷积网络提取复原视频和参考清晰视频的特征谱,采用wasserstein距离衡量对抗损失,提高判别网络的判别性能和稳定性;在判别网络中使用多层实例归一化和修正线性整流激活单元提升网络的判别性能;本步骤中得到的特征谱图将在求取均值之后可在步骤三中进行损失函数中对抗损失的计算。
[0015]
步骤三:构造损失函数对清晰视频生成网络和判别网络两个网络进行训练。
[0016]
输出:用训练好的清晰视频生成网络处理模糊视频。在使用训练数据对清晰视频生成网络和判别网络进行充分迭代训练之后,得到训练好的清晰视频生成网络用于去除待处理视频中的模糊退化。
[0017]
其中,所述步骤一具体如下:
[0018]
1.1:通过双向rnn序列提取每帧图像的特征图。rnn序列由rnn单元组成,rnn单元的输入是当前帧图像和上一个rnn单元输出的隐藏状态,rnn单元的输出是当前帧的特征图和隐藏状态,特征图用于重建清晰图像,隐藏状态则传向下一个rnn单元,通过隐藏状态在rnn序列中的传递,视频的时序信息得以保留。一般前向传递的rnn序列可以使当前帧特征图中包含过去帧信息,然而本发明认为未来帧信息同样具有利用价值,因此设计了两条rnn序列,分别向前和向后传播,融合它们的输出结果得到当前帧的特征图;
[0019]
1.2:使用融合重建模块对特征图进行融合和重建。首先利用时空注意模块对特征
图进行加权处理,有效保留每张特征图中与当前帧相似的信息,再经过多尺度卷积核对特征进行处理,将得到的结果融合在一起送入重建模块,经2次转置卷积得到与输入相同大小的结果;
[0020]
1.3:通过全局残差连接得到复原结果。考虑到视频模糊的复杂性,本发明引入全局残差连接帮助重建:将融合重建模块的输出结果与输入的当前帧相加作为最终复原结果,目的是提升网络学习效率和表达能力。将每一帧的复原结果串联起来,得到复原视频。将复原视频和参考清晰视频送入判别网络进行判别。
[0021]
其中,所述步骤三具体如下:
[0022]
3.1:清晰视频生成网络的损失函数由两部分组成:复原视频和参考清晰视频之间的均方误差(mse)构成的内容损失;以及将复原视频输入判别网络计算得到的对抗损失。清晰视频生成网络损失函数的表达式为:l
g
=α1l
adversarial
+α2l
content
,其中l
adversarial
代表对抗损失,l
content
代表内容损失,α1和α2是它们对应的加权系数,在本发明中分别取0.01和1。内容损失l
content
的表达式为:其中代表真实数据分布,代表模型数据分布,f,c,w和h分别表示视频序列的帧数、视频图像的通道数、宽度和高度,y
t
和表示参考清晰视频和清晰视频生成网络输出的复原视频;对抗损失l
adversarial
的表达式是其中d(
·
)代表判别网络的输出。内容损失的作用是从像素级别对视频进行复原,对抗损失的作用是从更高级别的视频细节和纹理特征等对视频进行复原。清晰视频生成网络在这两项损失函数的共同作用下产生高质量的模糊去除视频;
[0023]
3.2:判别网络的对抗损失的表达式是:为了优化判别网络的数值分布以提升其判别性能,引入梯度惩罚项对判别网络进行约束,加上了梯度惩罚项之后的判别网络的损失函数的表达式是:其中λ是梯度惩罚项的系数,在本发明中取值为10;
[0024]
3.3:本发明采用adam优化器进行优化,清晰视频生成网络和判别网络的初始学习率均为10
‑4,每过200个训练周期减半,通过梯度反向传播调整网络参数降低相应的损失函数。为了提高判别网络的性能,使之更好地指导生成网络,本发明采用1∶5的更新策略,即每更新一次生成网络参数,就进行5次判别网络参数更新。
[0025]
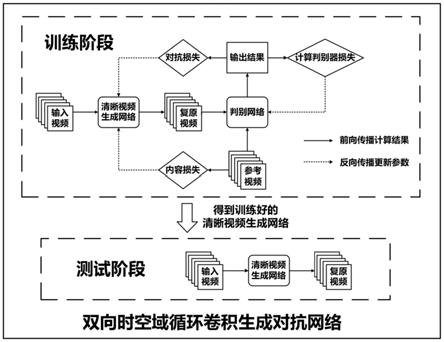
一种基于双向循环卷积生成对抗网络的视频模糊去除系统,其基本结构框架和工作流程如图1所示,其特征在于,包括:
[0026]
清晰视频生成网络模块,用于产生高质量去除模糊的复原视频。所述的清晰视频生成网络模块进一步包括:
[0027]
双向rnn序列,用于提取输入视频每一帧的特征图;
[0028]
融合重建模块,所述的融合重建模块具体包括时空注意模块及重建模块;所述的时空注意模块用于提取当前帧和其相邻帧特征图的有效信息,处理结果经拼接可得到融合结果;重建模块用于从融合结果恢复与原输入大小相同的图像;
[0029]
所述的清晰视频生成网络模块,通过全局残差连接将当前帧与重建模块的输出相
加,得到当前帧的复原结果;将每一帧的复原结果串联起来,得到复原视频;
[0030]
判别网络模块,用于判别清晰视频生成网络产生的复原视频和参考清晰视频;
[0031]
损失函数计算模块,用于计算清晰视频生成网络和判别网络的损失函数;
[0032]
网络训练模块,用于对清晰视频生成网络和判别网络进行充分迭代训练,得到训练好的清晰视频生成网络用于去除待处理视频中的模糊退化。
[0033]
本发明提出一种基于双向循环卷积生成对抗网络的视频模糊去除方法,以生成对抗网络为基本框架,通过两路沿不同方向传递信息的循环神经网络序列,充分地利用蕴含在视频序列中的时序关系;通过引入基于时空域注意力的融合重建模块,结合相邻帧的有用信息更好地重建当前帧,并利用全局残差连接提高网络表达能力和收敛速度;通过内容损失和对抗损失对网络进行训练,在提高复原视频与参考清晰视频相似度的同时,更好地恢复视频的细节特征。本发明可以与各类基于图像和视频的应用系统相结合,帮助提升所拍摄视频的质量,具有广阔市场前景与应用价值。
附图说明
[0034]
图1是本发明提出的双向循环卷积生成对抗网络(btsrnn
‑
wgan)的基本结构框架和工作流程。
[0035]
图2是清晰视频生成网络的基本结构。
[0036]
图3是rnn单元的基本结构。
[0037]
图4是融合重建模块的基本结构。
[0038]
图5是判别网络的基本结构。
[0039]
图6a
‑
f展示了本发明在不同场景下的视频模糊去除效果,其中6a、6c、6e为输入的模糊视频中的某一帧,6b、6d、6f为输出的复原视频中的对应帧。
具体实施方式
[0040]
为了更好地理解本发明的技术方案,以下结合附图对本发明的实施方式作进一步描述。
[0041]
本发明是一种基于双向循环卷积生成对抗网络的视频模糊去除方法,其算法框架与网络结构如图1所示,各部分具体实施步骤如下:
[0042]
步骤一:利用清晰视频生成网络产生高质量去除模糊的复原视频,清晰视频生成网络的基本结构如图2所示;
[0043]
步骤二:利用判别网络对复原视频和参考清晰视频进行分类判别,判别网络的基本结构如图5所示;
[0044]
步骤三:构造损失函数对清晰视频生成网络和判别网络两个网络进行训练;
[0045]
输出:用训练好的清晰视频生成网络处理模糊视频。在使用训练数据对清晰视频生成网络和判别网络进行充分迭代训练之后,得到训练好的清晰视频生成网络用于去除待处理视频中的模糊退化;
[0046]
其中,所述步骤一具体如下:
[0047]
1.1:通过双向rnn序列提取每帧图像的特征图。rnn序列由rnn单元组成,rnn单元的输入是当前帧图像和上一个rnn单元输出的隐藏状态,rnn单元的输出是当前帧的特征图
和隐藏状态,特征图用于重建清晰图像,隐藏状态则传向下一个rnn单元,通过隐藏状态在rnn序列中的传递,视频的时序信息得以保留。rnn单元以残差块为基本结构组成,输入图像首先经过一个卷积核大小为5
×
5,步长为1的卷积层,接着通过2次卷积核大小为3
×
3的残差块和卷积核大小为5
×
5,步长为2的卷积层相组合,目的是对图像进行下采样,得到的结果与来自上一帧的隐藏状态合并,经过9个卷积核大小为3
×
3的残差块提取特征,得到该帧特征图。同时该帧特征图通过卷积核大小为3
×
3的2个卷积层和1个残差块减少通道数,得到当前帧的隐藏状态,送入下一个rnn单元。rnn单元的结构如图3所示;
[0048]
1.2:使用融合重建模块对特征图进行融合和重建。在时空注意模块中,每一个特征图首先与当前帧的特征图相乘,再将其结果通过卷积核大小为7
×
7的卷积层和softmax函数得到该特征图的权重矩阵,将该特征图与权重矩阵相乘的结果与该特征图相加,目的是保留它的有效信息,将经过权重处理的特征图与当前帧特征图拼接后,通过1个3
×
3卷积核、3个1
×
1卷积核的卷积层对特征图进行进一步处理。将处理结果拼接在一起,得到融合结果。融合结果经过重建模块的2个3
×
3卷积核,步长为2的转置卷积层和2个卷积核大小为3
×
3的残差块,再通过卷积核大小5
×
5的卷积层调整通道数,得到与原始图像相同大小的重建输出。融合重建模块的基本结构如图4所示;
[0049]
1.3:通过全局残差连接得到复原结果。将融合重建模块的输出结果与输入的原始目标帧相加作为最终的复原结果,有效抑制梯度消失等现象,提高网络表达能力和收敛速度,提升复原结果的质量。将每一帧的复原结果串联起来,得到复原视频。将复原视频和参考清晰视频送入判别网络进行判别。
[0050]
其中,所述步骤二具体如下:
[0051]
2.1:将复原视频和参考清晰视频整体输入到判别网络中。传统wasserstein生成对抗网络判别器的输入是单幅图像,本发明为提高判别网络的判别性能,直接输入复原视频和参考清晰视频,通过时域信息辅助判别复原视频和参考清晰视频。
[0052]
2.2:由判别网络得到判别结果。判别网络由10层含有不同尺度卷积核的卷积层组成,提取输入视频的多尺度特征图谱;卷积层之间穿插实例归一化和线性整流激活层提升网络判别性能。本步骤中得到的特征谱图将在求取均值之后可在步骤三中进行损失函数中对抗损失的计算。
[0053]
其中,所述步骤三具体如下:
[0054]
3.1:清晰视频生成网络的损失函数由两部分组成:复原视频和参考清晰视频之间的均方误差(mse)构成的内容损失;以及将复原视频输入判别网络计算得到的对抗损失。清晰视频生成网络损失函数的表达式为:l
g
=α1l
adversarial
+α2l
content
,其中l
adversarial
代表对抗损失,l
content
代表内容损失,α1和α2是它们对应的加权系数,在本发明中分别取0.01和1。内容损失l
content
的表达式为:其中代表真实数据分布,代表模型数据分布,f,c,w和h分别表示视频序列的帧数、视频图像的通道数、宽度和高度,y
t
和表示参考清晰视频和清晰视频生成网络输出的复原视频;对抗损失l
adversarial
的表达式是其中d(
·
)代表判别网络的输出。内容损失的作用是从像素级别对视频进行复原,对抗损失的作用是从更高级别的视频细节和纹理特征等对视频进
行复原。清晰视频生成网络在这两项损失函数的共同作用下产生高质量的模糊去除视频;
[0055]
3.2:判别网络的对抗损失的表达式是:为了优化判别网络的数值分布以提升其判别性能,引入梯度惩罚项对判别网络进行约束,加上了梯度惩罚项之后的判别网络的损失函数的表达式是:其中λ是梯度惩罚项的系数,在本发明中取值为10;
[0056]
3.3:本发明采用adam优化器进行优化,清晰视频生成网络和判别网络的初始学习率均为10
‑4,每过200个训练周期减半,通过梯度反向传播调整网络参数降低相应的损失函数。为了提高判别网络的性能,使之更好地指导生成网络,本发明采用1∶5的更新策略,即每更新一次生成网络参数,就进行5次判别网络参数更新。
[0057]
为了从直观上展示本发明的效果,图6a
‑
f展示了本发明在不同场景下的视频模糊去除效果,其中6a、6c、6e为输入的模糊视频中的某一帧,6b、6d、6f为输出的复原视频中的对应帧。从图中可以看出本发明输出的复原图像对输入图像的模糊退化有了十分明显的抑制和缓解效果,图像的清晰度得到显著提高。本发明以生成对抗网络为基本架构,利用双向rnn序列充分利用视频的时序信息,结合基于时空域注意力的融合重建模块和全局残差连接,实现高质量的视频模糊去除,可有效提升各种场景下所拍摄视频的质量,可应用在各类基于图像和视频的应用系统中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1