一种面向增量式数据集的知识发现方法与发现装置
1.本发明涉及一种知识发现方法,特别涉及一种在增量式数据集上的知识发现方法与发现装置。
背景技术:
2.物联网、社交网络和internet每时每刻不断产生新的数据,这些数据需要及时分析以挖掘其具有时效性的价值。随着数据量的指数级增长,其稀疏性也越来越显著,新出现的知识和事件信息往往被淹没在大量的数据中。如何从中抽取有价值的信息,发现事物之间各种隐藏的潜在关联关系,包括因果关系、协同变化关系、共存关系等,是知识发现相关研究的难点问题。
3.许多研究者针对不断增长的数据,采用增量式计算实现数据的分析和挖掘。
4.一类算法为基于树形数据结构的增量式计算方法,主要应用树形结构对新旧数据的频繁模式进行存储、挖掘频繁模式之间的关联关系,如fup和fup2算法。在新数据到来时,通过对新旧数据集的频繁模式树进行调整,从而改变新旧数据集的频繁模式,该算法通过构建事务数据集,记录每一种数据事务的出现次数等信息,在得到新增数据集后,通过对新旧数据集中的频繁事务项进行计算,得到新的频繁模式,再对新的频繁模式进行关联性分析;cantree
‑
gtree算法,基于滑动窗口发现来自实时事务的完整频繁项集,该算法使用两种树形数据结构:cantree和gtree。一种是cantree,通过扫描滑动窗口中的所有事务,将其用作基础树。一种称为gtree(组树)的新型数据结构用作每个数据项的投影树,通过使用自上而下的树遍历方法遍历每个节点来构建投影树。但是,基于树形数据结构的增量式计算方法每次对频繁模式的确定都需扫描一次全体数据,由于新增数据相对于全体数据往往是小数据量,难以用基于树形结构的增量式计算方法发现新的频繁模式。
5.另一类为基于增量学习的计算方法,多采用机器学习与深度学习的方法进行增量学习,不断从新样本中学习新知识,并能保存大部分以前已学习的知识。此类方法包括:并行增量wesvm(加权极限支持向量机),此方法用以合并输入数据与原数据集并进行学习训练,该模型可以通过简单的矩阵加法来合并来自训练数据子集的知识,使其能够通过合并每个增量阶段的数据切片的知识来进行并行增量学习;集成学习方法dtel(基于多样性和迁移的集成学习方法),该方法将每个保存的历史模型用作初始模型,并通过迁移学习将其与新数据一起进行训练。但是,基于增量学习的计算方法在大数据量的模型训练中需要花费较长时间,并且新数据若具有新特征,需要对模型进行重新训练,因此其模型构建、计算成本普遍较高,且对数据质量的要求也较高,需要较大的时间复杂度与空间复杂度。
6.因此为了适应数据量不断扩大的应用场景,解决增量式数据计算所面临的高时间复杂度、高空间复杂度问题,本发明提出了一种面向增量式数据集的知识发现方法与发现装置,设计了可以随数据量不断扩大而进行演化的树形数据结构以及记录新增频繁模式的增量窗口,对新增数据集中的频繁事务项进行维护,保持增量式数据计算的时效性。在数据增量过程中,本发明通过对原始数据频繁模式树、新增频繁模式树与增量滑动窗口对新增
频繁模式进行实时调整,及时对原数据集与新数据集之间事务项的关联关系进行挖掘。同时,本发明解决了基于树形数据结构的增量式算法在调整频繁模式需不断扫描原始数据的问题,极大降低了时间复杂度。
技术实现要素:
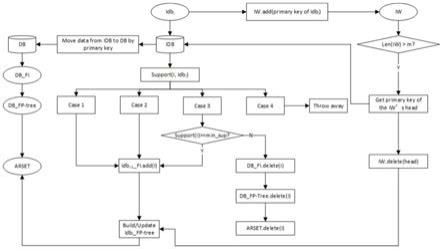
7.为了解决在数据量不断增加的场景下,新知识难以被及时准确发现的问题,本发明提供了面向增量式数据集的知识发现方法,该方法使用efpt
‑
ikd算法,设计了一种可以随数据量不断增长而不断演化的树形数据结构—频繁模式树,设置增量窗口(iw)发现新增频繁事务项,频繁模式树主要用于对数据集中的频繁模式信息进行存储,通过增量窗口与新发现的频繁模式,挖掘增量数据集中的新知识,并将新增频繁模式动态更新到原有频繁模式树中,使频繁模式树随着数据集增加不断演化。
8.本发明所采用的技术方案如下:
9.一种面向增量式数据集的知识发现方法与发现装置,包括以下步骤:
10.a.基于原始数据集db中数据频繁事务项集合db_fi构建原始数据集频繁模式树db_fp
‑
tree,并根据最小支持度min_conf计算db中的关联规则集合ar(db_fp
‑
tree),令总关联规则集arset=ar(db_fp
‑
tree),设置增量窗口长度上限为m,并初始化增量滑动窗口iw为空,同时初始化增量频繁模式树idb0_fp
‑
tree。
11.b.当第i次增量数据集idb
i
的数据到来时,将本次数据增量数据集idb
i
存储在增量数据库idb中,初始化增量数据集的频繁事务集idb
i
_fi,扫描idb
i
中的数据,计算idb
i
中每一个数据项i的支持度,并根据在原始数据以及增量数据中按照频繁程度分为4种情况进行不同操作。
12.c.在增量滑动窗口iw内的队列末尾追加本次增量数据的主键信息(表中的一个或多个字段,它的值用于唯一地标识表中的某一条记录),此时增量滑动窗口iw内的队列长度len(iw)加1,若len(iw)<=m(增量窗口上限m),则动态更新频繁模式树idb
i
‑1_fp
‑
tree,若len(iw)>m(增量窗口上限m),则读取增量滑动窗口iw内的队首信息,根据主键信息将增量数据库idb中的数据转移至原始数据库db中,删除iw的队首节点,同时将这些数据的信息更新到原始数据的频繁模式树db_fp
‑
tree中,并更新idb
i
_fp
‑
tree中涉及到的节点信息。
13.d.步骤b完成后,根据最终得到的增量频繁事务集idb
i
_fi更新增量频繁模式树idb
i
‑1_fp
‑
tree,在更新时,将idb
i
_fi中的事务按照支持度降序排序,并再次扫描本次增量数据集idb
i
,并将idb
i
_fi中的事务信息按照构建频繁模式树的方法更新到idb
i
‑1_fp
‑
tree中,此时idb
i
‑1_fp
‑
tree被更新为idb
i
_fp
‑
tree。
14.e.基于增量频繁模式树idb
i
_fp
‑
tree与最小支持度min_conf计算第i次数据增量后的关联关系集合ar(idb
i
_fp
‑
tree),并令总关联关系集合arset=arset∪ar(idb
i
_fp
‑
tree)。
15.步骤a中,原始数据集频繁模式树db_fp
‑
tree是用以对原数据集中的频繁模式信息进行存储;总关联关系集合arset开始存放原始数据的关联规则,当每次增量数据发生后都要动态调整arset(取并集);增量窗口iw(incremental window)的窗口上限m由具体情况下的增量数据集决定;增量频繁模式树idb0_fp
‑
tree初始化为一个根节点。
16.步骤b中,原始数据(db)中数据和新增数据(idb)中的事务项在数据集增量演化过
程中按支持度分为4种情况并进行相关操作:
17.i.事务项i在原始数据集db和新增数据集idb
i
中依然是频繁的,将该事务项i加入到增量频繁事务集idb
i
_fi中。
18.ii.事务项i在db中不频繁,但在idb
i
中是频繁的,因此可以视为是新出现的频繁事务项,将该事务项i加入到idb
i
_fi中。
19.iii.事务项i在db中频繁,在idb
i
中不频繁,因此要分情况讨论,计算i的全局支持度:
[0020][0021]
其中count(i,db)表示事务项i在原数据集db中出现的次数,通过查找db_fp
‑
tree得到,count(i,idb)表示事务项i在增量数据库idb中出现的次数,通过扫描增量频繁模式树idb
i
_fp
‑
tree得到,len(db)与len(idb)分别表示数据集db与idb的长度。若事务项i的支持度support(i)>=min_sup,则将该事务i加入到idb
i
_fi中;否则在db_fi中丢弃i,并删除db_fp
‑
tree中对应的节点,将节点的父节点与子节点直连,同时对arset中包含事务项i的关联规则记录进行处理,删除事务项i的信息。
[0022]
iv.事务项i在db以及idb
i
中都是不频繁的,对这样的事务进行丢弃。
[0023]
步骤c中,当len(iw)<=m(增量窗口上限m),将增量频繁事务集idb
i
_fi中的事务按照支持度降序排序,并再次扫描本次增量数据集idb
i
,并将idb
i
_fi中的事务信息按照构建频繁模式树的方法更新到idb
i
‑1_fp
‑
tree中;当len(iw)>m,更新频繁模式树idb
i
_fp
‑
tree的具体操作为将计数信息减去相应的值,若计数减为0,则删除节点,将该节点的父节点与子节点相连。
[0024]
步骤d中,当第一次增量发生时,需要对初始化增量频繁模式树idb0_fp
‑
tree进行更新,增加其叶子节点;当第i(i>1)次增量发生时,需对idb
i
‑1_fp
‑
tree进行调整,将频繁事务集idb
i
_fi中的事务按照支持度降序排序,并再次扫描本次增量数据集idb
i
,并将idb
i
_fi中的事务信息更新到idb
i
‑1_fp
‑
tree中。
附图说明
[0025]
为了更清楚的说明本发明中的技术方案,下面将对发明内容和实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0026]
图1为增量数据的四种情况图。
[0027]
图2为知识发现方法的流程图。
具体实施方式
[0028]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
[0029]
我们使用中国某省的诉求热线数据进行测试。实验数据为2016年7月11日到2018年9月20日的诉求热线数据,涉及64个大问题类别,共177835条数据。
[0030]
我们将全体数据按照时间先后取前30000条数据作为原始数据集db,该省的诉求热线数据平均每日为3000条(即增量数据),其中已知后续的增量数据包含一个突发事件发生、发展、爆发、销匿的过程。实验中设置最小支持度min_sup=5%,最小置信度min_conf=20%。
[0031]
步骤1,我们将文本数据进行预处理,基于python中的jieba库对文本进行断句分词,然后使用tf
‑
idf算法计算每个词汇的权重,将每条数据内的关键词的权重按照从大到小的顺序排列,基于每条文本数据的平均长度,取前30个词作为本条数据的关键词,在全体数据中,每个关键词作为一个事务项,目的在于挖掘事务项之间的关联关系。
[0032]
步骤2,基于db中的数据,我们可以做出关联关系示意图,图中每一个节点表示一个事务项,节点之间的连线表示两个事务项具有满足最小支持度min_sup与最小置信度min_conf的关联关系。
[0033]
步骤3,在之后的每一次数据增量过程中,我们使用efpt
‑
ikd算法进行事务项之间的关联性挖掘,并记录关联规则集合的演变。efpt
‑
ikd算法首先基于db数据构建db_fp
‑
tree,然后每次增量时,判断新数据集中每个事务,将其分为四种情况,针对每种情况进行算法中相应的操作,并记录idb_fp
‑
tree的演化过程,并根据idb_fp
‑
tree与iw中的事务记录对频繁事务项之间的关联关系进行挖掘。
[0034]
使用efpt
‑
ikd算法所得结果中空心节点表示数据增量前的频繁事务项,实心节点表示本次数据增量过程中新出现的频繁事务项,节点之间的连线表示两个频繁事务项之间具有满足最小支持度min_sup与最小置信度min_conf的关联关系。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1