基于知识图嵌入的涉案领域的半监督方面级情感分析方法
1.本发明涉及基于知识图嵌入的涉案领域的半监督方面级情感分析(semi
‑
etekgs)方法,属于自然语言处理技术领域。
背景技术:
2.随着自媒体时代的到来、我国新媒体的蓬勃发展和网络舆情的深入,部分法院所审理的焦点案件在网络上迅速发酵,引发社会的广泛争议,司法部门通过实时有效的掌握并正确引导网络舆情有助于确保法院依法独立行使审判权,维护社会公平正义。而微博作为社会大众自由评论的社交媒体之一,其用户量庞大,发展较快,其中不少司法相关的案件会在微博中引起激烈讨论。因此,为了避免网络舆情对法院判决的影响,实时掌握用户对某一涉案热点事件的观点意见至关重要。该任务可以被视为是自然语言处理(nlp)中的子任务:涉案领域的方面级情感分析(absa),旨在从文本中挖掘用户的情感或者观点。
3.方面级情感分析是观点挖掘的一个子任务,旨在发现用户对于特定目标的极性判断。其研究方法主要包括有监督的方法和半监督的方法。由于每天成千上万的评论在社交媒体上被产出,将这些评论都进行人工标注是不可能的事情。因此,一种常见的半监督方法(ssl)能够充分利用好少量标注数据集,从而估计在分类器上训练参数。半监督方法已经被证明在很多任务和领域中都取得了不错的效果。其中bert等为半监督方法提出了一种自监督的方法mixmatch,同时在此基础上在分布的排列和扩增的锚点上改进了模型。
技术实现要素:
4.本发明提供了基于知识图嵌入的涉案领域的半监督方面级情感分析方法,以用于解决目前涉案微博评论涉案领域知识不能很好的融入到模型和涉案领域中缺乏标记的训练语料的问题,本发明取得较好的情感分类效果。
5.本发明的技术方案是:基于知识图嵌入的涉案领域的半监督方面级情感分析方法,包括:
6.从涉案微博事件中爬取涉案领域的微博评论,首先利用标记数据进行数据增强,通过预训练得到涉案领域的bert词嵌入和涉案领域的知识图词嵌入,然后将两种词嵌入按照比例拼接放入下游任务中,从而对特定方面的涉案微博评论进行极性的分类。
7.作为本发明的进一步方案,所述基于知识图嵌入的涉案领域的半监督方面级情感分析方法的具体步骤如下:
8.step1、收集用于涉案微博评论的方面级情感分析方法的涉案微博正文和微博评论,根据微博正文所涉及的案件,对收集的微博评论设置该案件的案件要素,同时根据案件要素对微博评论进行去重、筛选,去除与案件无关的微博评论,同时标记涉案微博评论的评价对象、所对应的评价观点词和涉案微博评论的情感极性;
9.step2、利用标记的数据集进行同义词替换,随机插入和随机交换方法的数据增强,利用构建的数据集基于bert模型和transgate模型构建预训练涉案领域的词嵌入网络,
从而获得bert的词向量和涉案领域的transkgs词嵌入;
10.step3、对于未标记的数据集进行标签的预测,并将得到的涉案微博bert词嵌入和transkgs词嵌入根据超参数的设置按照权重进行加权融合,获得带有涉案领域知识的词嵌入;
11.step4、将获得的具有涉案领域知识特征的词向量放入下游任务中,以此实现涉案领域微博评论的方面级情感分类。
12.作为本发明的进一步方案,所述步骤step1中,构建的涉案微博正文和微博评论的数据集,是使用scrapy作为爬取工具,模仿用户操作,登录微博,获取涉案微博正文和微博评论,包含8个案例及其的276个热点话题的微博评论。
13.作为本发明的进一步方案,所述步骤step1中,对根据微博正文所涉及的案件,对收集的微博评论设置该案件的案件要素,同时标记涉案微博评论的评价对象、所对应的评价观点词和涉案微博评论的情感极性包括:
14.step1.1、设置的涉案微博评论的评价对象的标注体系采用了json格式的标记文本,首先根据涉案微博评论所涉及的案件,将案件的要素根据要素定义制定出来,主要包括每个案件的事发地点、人物案件要素,并标注出涉案微博评论的评价对象,分别标注评价对象,评价观点词和对应的情感极性。
15.作为本发明的进一步方案,所述步骤step2的具体步骤:
16.step2.1、利用三种数据增强方式,包括同义词替换,随机交换和随机插入,对标记的数据集进行语料的数据增强;
17.step2.2、基于bert语言模型构建涉案领域的预训练网络,从而通过数据增强后的数据集获得涉案领域的预训练词嵌入;
18.step2.3、将数据增强后的数据集利用trans
‑
gate模型构建预训练网络,从而获得涉案领域的词嵌入,其中一条数据集包括多个三元组,包含头实体h和尾实体t,r是h和t之间的关系;给定一个三元组h,r,t,利用一个有全连接层的基础门控分别表示两个实体之间的关系,在经过门控函数σ后,得到新的特定关系的词嵌入向量,记为:
[0019][0020][0021]
其中w
h
,w
t
,b
h
和b
t
是需学习的参数,
⊙
表示hadamard乘积,值得注意的是,为了减少参数的计算量,用两个权向量代替了门控中的矩阵,之后,分数函数被定义为:
[0022]
f
r
(h,t)=||h
r
+r
‑
t
r
||
ꢀꢀꢀ
(3)
[0023]
在预训练涉案知识图后,将得到涉案知识的trans
‑
kgs词嵌入,预训练的损失函数记为:
[0024][0025]
其中,s'是词和关系的集合,由随机替换的实体或关系组成的训练三元组。
[0026]
作为本发明的进一步方案,所述步骤step3的具体步骤:
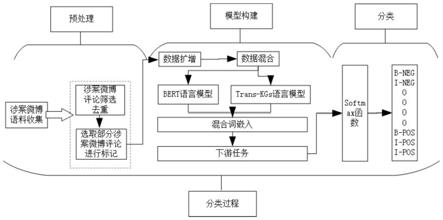
[0027]
step3.1、对于未标记的数据,先预测未标记数据的标签,其中和表示标记的扩增数据和未标记的
扩增数据;然后,基于mixmatch的思想对标记数据和未标记数据进行插值,通过三个步骤得到最终的混合数据:
[0028]
(a)首先,定义了一个微调修改版的mixmatch适应损失函数,其中α是beta样本分布的超参数;
[0029]
λ~beta(α,α)
ꢀꢀꢀꢀꢀ
(5)
[0030]
λ'=max(λ,1
‑
λ)
ꢀꢀꢀ
(6)
[0031]
(b)通过公式(7)和公式(8)得到最终的样本数据集,其中(x1,p1)和(x2,p2)是两个带有预测标签的样本,λ'为了设置标记数据和未标记数据的比例阈值,根据
[0032]
公式(6)确保混合数据集更趋近原始数据集;
[0033]
x'=λ'(bert(x1))+(1
‑
λ')(bert(x2))
ꢀꢀꢀꢀ
(7)
[0034]
p'=λ'(bert(p1))+(1
‑
λ')(bert(p2))
ꢀꢀꢀꢀꢀ
(8)
[0035]
(c)最后,为了更好的训练,将得到的混合数据进行随机洗牌。
[0036]
step3.2、对于标记的数据集和扩增的数据集,直接按照权重将两种词嵌入进行混合,利用β超参数来决定trans
‑
kgs嵌入和bert嵌入的比重;然后就能得到混合层中每个字符的嵌入记为:
[0037][0038]
其中,表示通过知识图训练得到的涉案领域字符嵌入,表示bert预训练后的字符嵌入。
[0039]
作为本发明的进一步方案,所述步骤step4的具体步骤:
[0040]
step4.1、将融合后的词嵌入经过softmax线性模型进行分类;
[0041]
step4.2、将融合后的词嵌入经过卷积神经网络cnn模型,进行卷积操作,包括一层卷积层,一层池化层和一层全连接层,最终加入一层softmax函数进行分类;
[0042]
step4.3、将融合的词嵌入基于循环神经网络rnn的模型gru模型编码,最后通过softmax函数进行分类;
[0043][0044][0045][0046][0047]
其中,f是sigmoid激活函数,r
t
,z
t
,分别表示重置门,更新门和隐向量;w
z
,w
r
和w是gru模型的参数,然后加入softmax函数作为最后一层,从而计算预测的概率,记为:
[0048]
p(y
n
|x
n
)=softmax(w
o
hi
t
+b
o
)
ꢀꢀꢀꢀꢀ
(14)
[0049]
step4.4、将融合的词嵌入作为crf模型的特征向量进行分类,以此得到全局最优的情感标签分类;
[0050][0051]
p(y
n
|x
n
)=softmax(s(x,y))
ꢀꢀꢀ
(16)
[0052]
其中m
a
用于建模的随机初始化的转换矩阵,同时使用softmax函数来获得最终的输出。
[0053]
本发明的有益效果是:
[0054]
1、本发明的基于知识图嵌入的面向涉案领域的半监督方面级情感分析(semi
‑
etekgs)方法,利用案件要素与涉案微博评论中的评价对象的相关性,解决在涉案微博评论中,针对特定的评价对象进行情感极性分类的问题;
[0055]
2、本发明的基于知识图嵌入的面向涉案领域的半监督方面级情感分析(semi
‑
etekgs)方法,使用数据增强的技术和未标记数据的标签预测,解决了涉案领域中训练数据集缺乏的问题。
[0056]
3、本发明的基于知识图嵌入的面向涉案领域的半监督方面级情感分析(semi
‑
etekgs)方法,预训练了通用领域的bert语言模型,并利用关系抽取任务中的关系对涉案领域的知识数据库进行训练了涉案领域的知识词嵌入,缓解了通用的absa(方面级情感分析)在涉案领域任务中未考虑涉案知识的问题。
[0057]
4、本发明的基于知识图嵌入的面向涉案领域的半监督方面级情感分析(semi
‑
etekgs)方法,解决了涉案微博的微博评论中对于评价对象的情感极性分类任务。
附图说明
[0058]
图1为本发明提出的semi
‑
etekgs模型的方面级情感极性分类任务的架构图;
[0059]
图2为本发明提出的semi
‑
etekgs模型整体框架图。
具体实施方式
[0060]
实施例1:如图1
‑
2所示,基于知识图嵌入的涉案领域的半监督方面级情感分析方法,包括:
[0061]
从涉案微博事件中爬取涉案领域的微博评论,首先利用标记数据进行数据增强,通过预训练得到涉案领域的bert词嵌入和涉案领域的知识图词嵌入,然后将两种词嵌入按照比例拼接放入下游任务中,从而对特定方面的涉案微博评论进行极性的分类。
[0062]
作为本发明的进一步方案,所述基于知识图嵌入的涉案领域的半监督方面级情感分析方法的具体步骤如下:
[0063]
step1、收集用于涉案微博评论的方面级情感分析方法的涉案微博正文和微博评论,根据微博正文所涉及的案件,对收集的微博评论设置该案件的案件要素,同时根据案件要素对微博评论进行去重、筛选,去除与案件无关的微博评论,同时标记涉案微博评论的评价对象、所对应的评价观点词和涉案微博评论的情感极性;
[0064]
作为本发明的进一步方案,所述步骤step1中,构建的涉案微博正文和微博评论的数据集,是使用scrapy作为爬取工具,模仿用户操作,登录微博,获取涉案微博正文和微博评论,包含8个案例及其的276个热点话题的微博评论。并从每一个涉案的案例中随机选取出了500条数据集进行标记根据微博正文所涉及的案件,对收集的微博评论定制该案件的
案件要素,并对于每一句评论进行标记涉及的涉案要素,以及涉案的微博评价对象,涉案评价的观点词和对于每一个评价对象进行情感极性的标注;
[0065]
作为本发明的进一步方案,所述步骤step1中,对根据微博正文所涉及的案件,对收集的微博评论设置该案件的案件要素,同时标记涉案微博评论的评价对象、所对应的评价观点词和涉案微博评论的情感极性包括:
[0066]
step1.1、设置的涉案微博评论的评价对象的标注体系采用了json格式的标记文本,首先根据涉案微博评论所涉及的案件,将案件的要素根据要素定义制定出来,主要包括每个案件的事发地点、人物案件要素,并标注出涉案微博评论的评价对象,分别标注评价对象,评价观点词和对应的情感极性。
[0067]
作为本发明的优选方案,所述step1中,使用scrapy作为爬取工具,模仿用户登录操作,登录微博网页版,爬取涉案微博的微博正文和涉案微博评论,根据微博正文涉及的案件以及案件要素的定义,为8个案件指定对应的案件要素,并根据案件要素,匹配出评论中与案件相关的微博评论,去除一些与评论中与该案件不相关的评论,并从这些评论中标记出评价对象,评价对象所对应的评价观点词和情感倾向性。
[0068]
此优选方案设计是本发明的重要组成部分,主要为本发明收集语料过程,为本发明抽取微博评论中的方面级情感分类任务提供了数据支撑。
[0069]
作为本发明的优选方案,所述步骤step1中包括:
[0070]
定制的涉案领域的方面级情感分析的标注体系采用了json格式的标记文本,通过json格式的文件,对涉案微博的每一句评论的词进行b(begin)、i(inside)和o(outside)序列标注,其中b(begin)表示评价对象的起始位置,i(inside)表示评价对象的内容,o(outside)表示微博评论中的其他部分,以及neg(负向情感)、pos(正向情感)和neu(中立情感),故对于每一个词而言,可能出现的标记情况包括:b
‑
pos、b
‑
neg、b
‑
neu、i
‑
pos、i
‑
neg、i
‑
neu和o七种情况,并保存成json格式的文件;
[0071]
step2、利用标记的数据集进行同义词替换,随机插入和随机交换方法的数据增强,利用构建的数据集基于bert模型和transgate模型构建预训练涉案领域的词嵌入网络,从而获得bert的词向量和涉案领域的transkgs词嵌入;
[0072]
作为本发明的进一步方案,所述步骤step2的具体步骤:
[0073]
step2.1、利用三种数据增强方式,包括同义词替换,随机交换和随机插入,对标记的数据集进行语料的数据增强;其中对于通用的英文数据集采用nltk工具中的同义词,而对于中文的数据集采用中文停止词列表进行数据增强;
[0074]
step2.2、将涉案领域的数据增强的数据集基于bert语言模型进行预训练从而获得涉案领域的涉案bert词嵌入,将每一句话中词作为bert模型的输入,随机mask词后进行预训练;
[0075]
step2.3、根据标记的数据集案件要素所构建的涉案知识语料库,采用三元组的形式来表征涉案知识;将数据增强后的数据集利用trans
‑
gate模型构建预训练网络,从而获得涉案领域的词嵌入,其中一条数据集包括多个三元组,包含头实体h和尾实体t,r是h和t之间的关系;如图2所示,h和t分别是一个三元组的头实体和尾实体,r是h和t之间的关系。例如,(滴滴司机,判决,死刑)表示滴滴司机被判处死刑,而(犯罪成本,negative,太低)表示对于犯罪成本的情感极性是消极的。给定一个三元组h,r,t,利用一个有全连接层的基础
门控分别表示两个实体之间的关系,在经过门控函数σ后,得到新的特定关系的词嵌入向量,记为:
[0076][0077][0078]
其中w
h
,w
rh
,w
t
,b
h
和b
t
是需学习的参数,
⊙
表示hadamard乘积,值得注意的是,为了减少参数的计算量,用两个权向量代替了门控中的矩阵,之后,分数函数被定义为:
[0079]
f
r
(h,t)=||h
r
+r
‑
t
r
||
ꢀꢀꢀꢀ
(3)
[0080]
在预训练涉案知识图后,将得到涉案知识的trans
‑
kgs词嵌入,预训练的损失函数记为:
[0081][0082]
其中,s'是词和关系的集合,由随机替换的实体或关系组成的训练三元组。
[0083]
此优选方案设计是本发明的重要组成部分,主要为本发明提供向量编码的过程,为结合预训练的词向量,进而提升模型的性能而提供了涉案领域词嵌入的有力支持。
[0084]
step3、对于未标记的数据集进行标签的预测,并将得到的涉案微博bert词嵌入和transkgs词嵌入根据超参数的设置按照权重进行加权融合,获得带有涉案领域知识的词嵌入;
[0085]
作为本发明的进一步方案,所述步骤step3的具体步骤:
[0086]
step3.1、对于未标记的数据,先预测未标记数据的标签,其中和表示标记的扩增数据和未标记的扩增数据;然后,基于mixmatch的思想对标记数据和未标记数据进行插值,通过三个步骤得到最终的混合数据:
[0087]
(a)首先,定义了一个微调修改版的mixmatch适应损失函数,其中α是beta样本分布的超参数;
[0088]
λ~beta(α,α)
ꢀꢀꢀ
(5)
[0089]
λ'=max(λ,1
‑
λ)
ꢀꢀꢀ
(6)
[0090]
(b)通过公式(7)和公式(8)得到最终的样本数据集,其中(x1,p1)和(x2,p2)是两个带有预测标签的样本,λ'为了设置标记数据和未标记数据的比例阈值,根据公式(6)确保混合数据集更趋近原始数据集;
[0091]
x'=λ'(bert(x1))+(1
‑
λ')(bert(x2))
ꢀꢀꢀ
(7)
[0092]
p'=λ'(bert(p1))+(1
‑
λ')(bert(p2))
ꢀꢀꢀ
(8)
[0093]
(c)最后,为了更好的训练,将得到的混合数据进行随机洗牌。
[0094]
其中预测标签的步骤如下:
[0095]
在k次数据增强后,使用模型当前预测的平均值作为猜测标签,由标签词汇表计算。因此,我们可以得到每个未标记数据的软标签,记为:
[0096]
[0097]
其中,是标签的输出分布模型,是经过次数据增强后的数据集。另外,sharpen函数用于预测分布从而减少标签分布的熵根据mixmatch可以得到q
b
中每一个预测的标签p,记为:
[0098][0099]
其中,t是区间[0,1]之间的超参数,v是词表大小。我们生成每一个而不是常规的数据增加(da)来获得进一步的性能改进,并设置k=2表示扩增的次数。
[0100]
step3.2、对于标记的数据集和扩增的数据集,直接按照权重将两种词嵌入进行混合,利用β超参数来决定trans
‑
kgs嵌入和bert嵌入的比重;然后就能得到混合层中每个字符的嵌入记为:
[0101][0102]
其中,表示通过知识图训练得到的涉案领域字符嵌入,表示bert预训练后的字符嵌入。
[0103]
step4、将获得的具有涉案领域知识特征的词向量放入下游任务中,以此实现涉案领域微博评论的方面级情感分类。
[0104]
作为本发明的进一步方案,所述步骤step4的具体步骤:
[0105]
step4.1、将融合后的词嵌入经过softmax线性模型进行分类;
[0106]
直接通过softmax激活函数计算概率从而进行预测,因此我们将混合嵌入层的输出作为线性模型的输入。定义为:
[0107][0108]
其中,w
o
和b
o
是线性模型的训练参数,是混合嵌入层的输出。
[0109]
step4.2、将融合后的词嵌入经过卷积神经网络cnn模型,进行卷积操作,包括一层卷积层,一层池化层和一层全连接层,最终加入一层softmax函数进行分类;
[0110]
卷积神经网络(convolutional neural network,cnn)用来提取网络的特征并应用到一些nlp任务中,它包含三个主要的模型层,分别是卷积层,池化层和全连接层。在卷积层中,会有一个或多个滤波器进行卷积来提取输入层的特征。然后,池化层用于减少数据大小。之后,一个完全连接的层用于在一个行维度上的扩展生成的特征图,并连接成一个向量。最后,cnn的输出定义为:
[0111][0112]
其中conv2表示卷积操作,是混合层的输出作为cnn的输入。
[0113]
step4.3、将融合的词嵌入基于循环神经网络rnn的模型gru模型编码,最后通过softmax函数进行分类;
[0114]
递归神经网络(rnn)被提出后,有很多任务用其来解决nlp问题,并证明了其良好的性能。因此,我们对涉案领域中的e2e
‑
absa任务中也使用基于rnn的gru进行了研究。故可以得到在t
‑
th的隐向量hi
t
:
[0115][0116][0117][0118][0119]
其中,f是sigmoid激活函数,r
t
,z
t
,分别表示重置门,更新门和隐向量;w
z
,w
r
和w是gru模型的参数,然后加入softmax函数作为最后一层,从而计算预测的概率,记为:
[0120]
p(y
n
|x
n
)=softmax(w
o
hi
t
+b
o
)
ꢀꢀꢀ
(18)
[0121]
step4.4、将融合的词嵌入作为crf模型的特征向量进行分类,以此得到全局最优的情感标签分类;条件随机场(crf)被有效应用于序列建模中以解决nlp任务中序列分类问题;
[0122][0123]
p(y
n
|x
n
)=softmax(s(x,y))
ꢀꢀꢀ
(20)
[0124]
其中m
a
用于建模的随机初始化的转换矩阵,同时使用softmax函数来获得最终的输出。
[0125]
为了探究本文发明的涉案微博评论的评价对象方法的有效性,在半监督semi
‑
etekgs模型中,由于餐厅和笔记本电脑领域不存在任何涉案要素,因此无法利用涉案要素构建涉案知识图,故表1的最后一行不能得到模型的效果。另外,我们将bert模型扩展为一些下游模型,如linear,cnn,gru和crf。f1值(f1_score)作为评价指标进行对比实验。实验结果如表1所示。
[0126]
表1不同方法的实验结果
[0127]
方法restaurantlaptopcase
‑
relatedbert
‑
linear73.22*60.43*65.22bert
‑
cnn73.1160.4065.00bert
‑
gru74.8762.1266.61bert
‑
crf74.0661.7866.30bert
‑
pt76.9062.0368.40bert
‑
fd78.98*69.17*69.30semi
‑
etekgs
‑‑‑‑
72.43
[0128]
从表1中可以看出,bert
‑
pt和bert
‑
fd模型的性能要优于基于bert模型的性能,而semi
‑
etekgs模型在与案例相关的数据中的性能也更好。具体来说,bert
‑
cnn的结果不如其他基于bert的模型好,我们认为cnn忽略了全局特征提取,因此它不能考虑距离特定目标遥远的观点词。相反,bert
‑
gru可以捕获上下文表示并克服了长距离依赖的问题,因此在所有数据集中基于bert的模型能获得最佳性能。其次,由于采用了新的数据增强技术,bert
‑
fd模型在笔记本电脑和餐厅领域优于其他模型,其性能分别提高了2.22%和2.08%。但并不适用于涉案领域,而添加涉案领域的词嵌入后,semi
‑
etekgs的结果比基线模型提高了
3.1%,主要原因可能是微博评论中的涉案评价对象之间存在关系,故它们的词嵌入在涉案领的向量空间中更接近。同时为了验证文本所提出的两层模型,本发明也分别做了各层的有效性实验,具体实验结果如表2所示,其中mha
‑
表示将多头注意力机制层去掉后的实验结果,同理,ce
‑
表示将案件知识融入层去掉的实验结果。
[0129]
表2模型各层有效性实验结果
[0130]
方法restaurantlaptopcase
‑
relatedbert
‑
fd78.98*67.30*69.30semi
‑
etekgs
‑
da
‑
‑‑‑‑
71.40semi
‑
etekgs
‑
trans
‑
kgs
‑
79.4569.5070.50semi
‑
etekgs
‑‑‑‑
72.43
[0131]
从表2可以看出,semi
‑
etekgs模型在涉案领域数据集的性能提高了3.1%,同时在每一层都是有效的,分别提高了2.1%和1.2%。此外,在餐厅和笔记本电脑领域的数据增强策略也得到了应用,分别提高了0.47和2.2%。在没有其他两个数据集的法律特征的情况下,semi
‑
etekgs的结果无法进行,但是在方面级抽取任务中已经证明了领域词嵌入的有效性,所以相信在商品数据集中加入领域的特征词嵌入也是有效的。
[0132]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1