运算装置与数据处理方法与流程
本发明有关于数据处理,尤指一种通过至少一辅助处理器与至少一特殊应用处理器来将数据处理工作的至少一部分从至少一通用处理器卸载出来的数据处理方法与相关的运算装置。
背景技术:
根据传统的计算机架构,储存装置可通过总线来跟中央处理器进行数据传送与数据接收,举例来说,固态硬盘(solid-statedrive,ssd)可连接至pcie(peripheralcomponentinterconnectexpress)总线或sata(serialadvancedtechnologyattachment)总线,如此一来,主机端的中央处理器可通过pcie总线/sata总线来将数据写入主机端的固态硬盘,而主机端的固态硬盘也可通过pcie总线/sata总线来将储存数据传送至主机端的中央处理器。此外,随着网络技术的发展,储存装置也可设置于远程,并通过网络而连接至主机端,如此一来,主机端的中央处理器可通过网络来将数据写入远程的储存装置,而远程的储存装置也可通过网络来将储存数据传送至主机端的中央处理器。
无论是安装于主机端的储存装置或是设置于远程的储存装置,中央处理器上所执行的应用程序会基于传统的计算机架构而需要从储存装置读取数据来进行处理,由于通过中央处理器来进行数据搬移会耗费大量时间,为了加速数据处理的效率,亟需一种创新的数据处理方法与相关的运算装置。
技术实现要素:
因此,本发明的目的之一在于提出一种通过至少一辅助处理器与至少一特殊应用处理器来将数据处理工作的至少一部分从至少一通用处理器卸载出来的数据处理方法与相关的运算装置。
在本发明的一个实施例中,揭示一种运算装置。该运算装置包含至少一通用处理器、至少一辅助处理器以及至少一特殊应用处理器。该至少一通用处理器用于执行一应用程序,其中一数据处理工作的至少一部分的数据处理会从该至少一通用处理器被卸载出来。该至少一辅助处理器用于在无需该至少一通用处理器上所执行的该应用程序的介入之下,处理该数据处理的一控制流。该至少一特殊应用处理器用于在无需该至少一通用处理器上所执行的该应用程序的介入之下,处理该数据处理的一数据流。
在本发明的另一个实施例中,揭示一种数据处理方法。该数据处理方法包含:通过至少一通用处理器来执行一应用程序,其中一数据处理工作的至少一部分的数据处理会从该至少一通用处理器被卸载出来;以及在无需该至少一通用处理器上所执行的该应用程序的介入之下,通过至少一辅助处理器来处理该数据处理的一控制流并通过至少一特殊应用处理器来处理该数据处理的一数据流。
本发明运算装置可具备网络子系统来链接至网络且可针对对象储存来执行相关数据处理,因此具有极高的可扩展性,在一应用中,本发明运算装置可兼容于现有的对象储存服务(例如amazons3或其它云端储存服务),因而可基于来自网络的对象储存指令(例如amazons3select)来针对运算装置所连接的对象储存装置进行数据获取的相关数据处理,在另一应用中,本发明运算装置可从网络接收nvme/tcp指令,并基于nvme/tcp指令来对运算装置所连接的储存装置进行相关的数据处理操作,假如运算装置所连接的储存装置是分布式储存系统中的一部分(例如键值数据库的一部分),则从网络所接收nvme/tcp指令可包含键值指令,本发明运算装置便可基于键值指令来对储存装置进行相关的键值数据库数据处理操作。此外,数据可在移动过程中便经由硬件加速电路完成处理,过程中无需执行应用程序的通用处理器介入数据搬移以及软件与硬件之间的通信,因此可实现网络内部运算和/或储存内部运算,进而节省功耗、减少延迟并降低通用处理器的负荷;再者,本发明运算装置可采用多重处理系统芯片来实现,例如多重处理系统芯片可包含现场可编程逻辑门阵列以及采用arm架构的通用处理器核心,因此具有很高的设计弹性,设计人员可根据需求来自行设计通用处理器核心所要执行的应用程序/程序代码以及现场可编程逻辑门阵列所要具备的硬件数据处理加速功能,例如可将本发明运算装置应用于数据中心,可通过定制化来支持各种数据类型与单元格式并得到最佳效能,由于单一多重处理系统芯片便可取代高阶服务器,因此采用本发明运算装置的数据中心可具有较低的建置成本。
附图说明
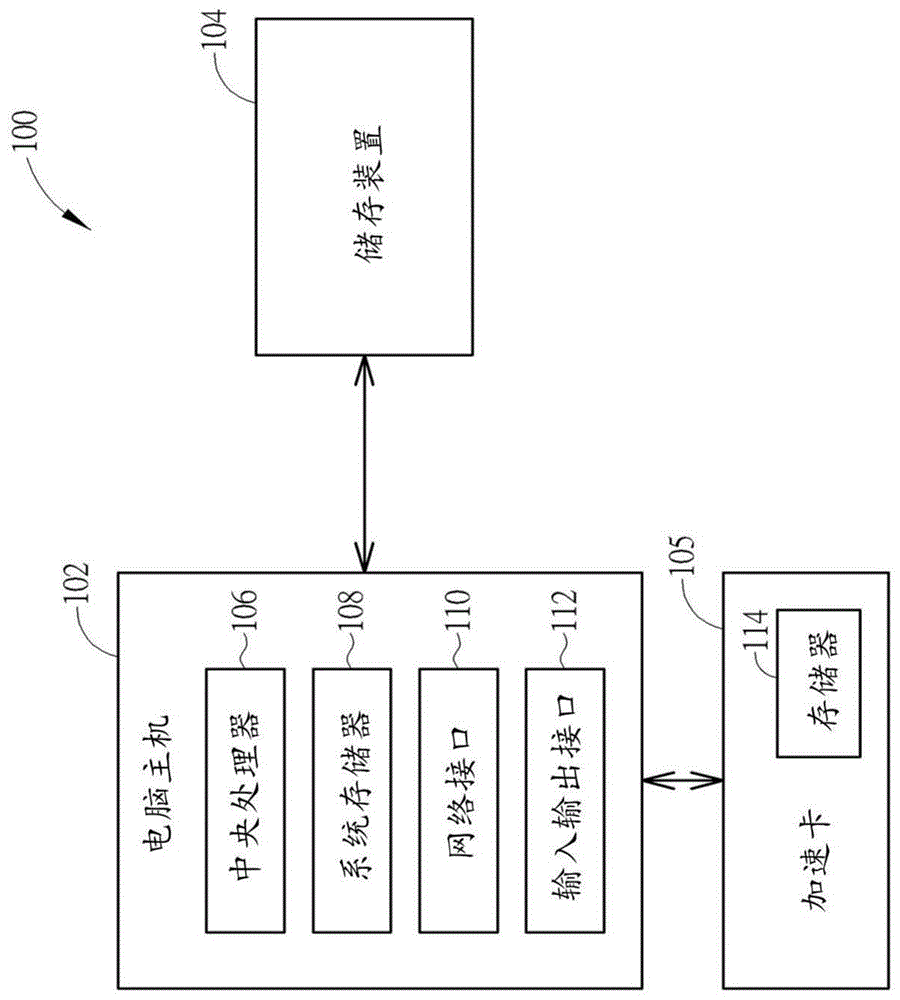
图1为采用加速卡的计算机系统的示意图。
图2为根据本发明一实施例的运算装置的示意图。
图3为本发明运算装置与采用加速卡的计算机系统之间的功能对应关系的示意图。
图4为依据本发明一实施例的采用虚拟储存存储器技术来进行对象数据处理的运算装置的示意图。
图5为依据本发明一实施例的可编程电路的示意图。
图6为依据本发明另一实施例的可编程电路的示意图。
具体实施方式
图1为采用加速卡的计算机系统的示意图。计算机系统100包含计算机主机102、储存装置104以及加速卡105。计算机主机102包含中央处理器106、系统存储器108、网络接口110、输入/输出接口112与其它组件(未显示)。储存装置104可通过网络接口110或者输入/输出接口112而连接至计算机主机102。加速卡105可通过输入/输出接口112而连接至计算机主机102。举例来说,网络接口110可提供有线网络存取或无线网络存取,而输入/输出接口112可以是pcie接口。本示例中,加速卡105为pcie适配卡,可安装于输入/输出接口112的插槽上,例如,加速卡105可以是基于现场可编程逻辑门阵列(fieldprogrammablegatearray,fpga)的适配卡,可用于数据处理的加速与其它应用,相比于通过中央处理器106来进行运算,加速卡105具有较大数据吞吐量、较低处理延迟与较低功耗等优点。当计算机系统100运行时,中央处理器106会先将储存装置104中待处理的储存数据搬移至系统存储器108,接着,再将系统存储器108中待处理的储存数据搬移至加速卡105中的存储器114,然后,加速卡105便会读取存储器114中的数据来进行运算,并将运算结果回传至中央处理器106。另外,中央处理器106有可能需要先对储存装置104中待处理的储存数据进行格式转换,再将符合加速卡105所需数据格式的数据搬移至加速卡105上的存储器114。虽然加速卡105可提供较大数据吞吐量、较低处理延迟与较低功耗,然而加速卡105是连接于计算机主机102的输入/输出接口112(例如pcie接口),因此,中央处理器106仍需要介入储存装置104与加速卡105之间的数据搬移和/或数据格式转换,例如,根据传统的计算机架构,中央处理器106需要针对输入/输出堆栈(input/outputstack)的复数层(layer)进行处理,且基于冯诺伊曼架构(vonneumannarchitecture),中央处理器106需要执行频繁的加载/储存(load/store)操作,如此一来,即便计算机系统100额外安装有加速卡105,仍然会因为这些因素影响而使得计算机系统100的整体数据处理效能无法受惠于加速卡105而有所大幅提升。再者,加速卡105是直接连接于计算机主机102的输入/输出接口112(例如pcie接口),故加速卡105本身会缺乏可扩展性(scalability)。
为了改善上述采用加速卡105的计算机系统100的各项缺点,本发明便提出新的硬件加速架构。图2为根据本发明一实施例的运算装置的示意图。运算装置200包含至少一通用处理器(generalpurposeprocessor)202、至少一辅助处理器(coprocessor)204以及至少一特殊应用处理器(applicationspecificprocessor)206。为了简洁起见,图2仅绘示一个通用处理器202、一个辅助处理器204以及一个特殊应用处理器206,然而,实际应用时,通用处理器202、辅助处理器204以及特殊应用处理器206的个数可依据需求而定,本发明并不以此为限。在本实施例中,通用处理器202、辅助处理器204与特殊应用处理器206均设置于同一芯片201中,例如,芯片201可以是多重处理系统芯片(multiprocessorsystemonachip,mpsoc),然而,本发明并不以此为限。此外,通用处理器202包含至少一通用处理器核心(未显示),辅助处理器204包含至少一通用处理器核心212与一部分的可编程电路208,以及特殊应用处理器206则包含另一部分的可编程电路208,举例来说,通用处理器核心可采用x86架构或arm(advancedriscmachine)架构,以及可编程电路208可以是现场可编程逻辑门阵列,本实施例中,通用处理器202(仅由通用处理器核心所构成)与辅助处理器204(由通用处理器核心与现场可编程逻辑门阵列所构成)为异质处理器(heterogeneousprocessors),通用处理器202负责执行应用程序app,而有关输入/输出堆栈的处理与数据搬移则完全交由辅助处理器204来负责。此外,由于特殊应用处理器206采用现场可编程逻辑门阵列来实现,故相比于通过通用处理器202来进行数据处理,特殊应用处理器206可提供较大数据吞吐量、较低处理延迟与较低功耗等优点,举例来说,特殊应用处理器206可跳脱冯诺伊曼架构,因此可采用管线(pipeline)、数据流(dataflow)等其它架构来提供数据平行处理的功能,进而具备较佳的数据处理效能。
在采用多重处理系统芯片来实现运算装置200的应用中,通用处理器202的处理器核心可以是采用armcotex-a53来实现的应用处理器单元(applicationprocessorunit,apu),通用处理器核心212则可以是采用armcotex-r5来实现的实时处理器单元(real-timeprocessorunit,rpu),以及可编程电路208为现场可编程逻辑门阵列。图3为本发明运算装置与采用加速卡的计算机系统之间的功能对应关系的示意图。计算机系统300可以是传统的服务器,可通过中央处理器(未显示)来执行应用程序302、操作系统核心(operationsystemkernel)304、文件系统(filesystem)306与驱动程序(driver)308,另外,计算机系统300设置网络接口310来提供网络存取功能,可利用储存装置312来提供大容量的数据存取,以及可通过加速卡314(例如pcie适配卡)来提供数据处理加速功能。运算装置200可采用多重处理系统芯片320来实现,基于图2所示的架构,多重处理系统芯片320可包含应用处理器单元324、实时处理器单元326与现场可编程逻辑门阵列328,其中网络子系统330、储存子系统332与加速电路334均由现场可编程逻辑门阵列328所实现。如图3所示,应用处理器单元324的功能会对应至应用程序302,网络子系统330、实时处理器单元326、储存子系统332与储存装置322的组合的功能会对应至网络接口310、操作系统核心304、文件系统306、驱动程序308与储存装置312的组合,以及加速电路334的功能会对应至加速卡314。不同于计算机系统300,多重处理系统芯片320可通过实时处理器单元326与现场可编程逻辑门阵列328(尤其是加速电路334)来将数据处理工作的至少一部分从应用处理器单元324卸载出来,如此一来,可避免应用处理器单元324耗费大量时间来处理数据搬移。本发明运算电路200的细节进一步说明如下。
请参照图2,通用处理器202用于执行应用程序app,其中一数据处理工作的至少一部分(亦即部分或全部)的数据处理会从通用处理器202被卸载出来,换句话说,通用处理器202无需介入该数据处理工作的至少一部分的该数据处理,如此一来,针对该数据处理的流程,通用处理器202便不用针对输入/输出堆栈的复数层进行任何处理。辅助处理器204用于在无需通用处理器202上所执行的应用程序app的介入之下,处理该数据处理的一控制流(controlflow),另外,特殊应用处理器206则是用于在无需通用处理器202上所执行的应用程序app的介入之下,处理该数据处理的一数据流(dataflow)。本实施例中,通用处理器202上所执行的应用程序app可通过调用应用程序编程接口(applicationprogramminginterface,api)函数api_f来将该数据处理工作的至少一部分的该数据处理卸载至辅助处理器204与特殊应用处理器206。
辅助处理器204的通用处理器核心212可加载并执行程序代码sw来执行与控制输入/输出堆栈的复数层的处理,进一步来说,通用处理器核心212会与可编程电路208进行通信来让整个数据流的处理能在无需通用处理器202介入的前提之下顺利完成。此外,辅助处理器204还包含利用可编程电路208所实现的网络子系统(networksubsystem)214、储存子系统(storagesubsystem)216与复数个数据转换电路(dataconverter)234、236。网络子系统214包含传输控制协议/因特网协议(transmissioncontrolprotocol/internetprotocol,tcp/ip)卸载引擎(offloadengine)222与网络处理电路(networkhandler)224。tcp/ip卸载引擎222用于处理网络处理电路224与网络挂载装置(network-attacheddevice)10之间的tcp/ip堆栈(tcp/ipstack),例如,网络挂载装置10可以是分布式对象储存系统中的客户端或者对象储存装置,并通过网络30连接至运算装置200,因此,分布式对象储存系统的指令或数据可通过网络30而传送至运算装置200,由于tcp/ip卸载引擎222负责网络层的处理,因此通用处理器核心212也无需介入tcp/ip堆栈的处理。网络处理电路224用于与通用处理器核心212进行通信并控制网络流(networkflow)。
本实施例中,特殊应用处理器206是由可编程电路208所实现并包含至少一加速电路(accelerator)232,为了简洁起见,图2仅绘示一个加速电路232,然而,实际应用时,加速电路232的个数可依据需求而定,例如每个加速电路232被设计来执行一个核心函数(kernelfunction),因此特殊应用处理器206可设置复数个加速电路232来分别执行不同的核心函数,请注意,核心函数本身并不针对输入/输出堆栈的复数层进行任何处理。
加速电路232是设计来提供硬件数据处理加速功能,可从网络处理电路224接收一数据输入,以及根据该数据输入来处理该数据处理工作的至少一部分的该数据处理的该数据流。假如得自该网络流的负载数据(payload)的数据格式不同于加速电路232所要求的预定数据格式,则数据转换电路234会用于处理网络处理电路224与加速电路232之间的数据转换,举例来说,网络处理电路224从该网络流所得到并输出的负载数据会包含一笔完整数据,而加速电路232所要执行的核心函数仅需处理该笔完整数据中的特定字段,因此数据转换电路234会从该笔完整数据中获取出特定字段并传送至加速电路232。此外,假如网络挂载装置10为分布式对象储存系统中的一部分,并通过网络30连接至运算装置200,则网络处理电路224可用于控制加速电路232与网络挂载装置10之间的该网络流。
储存子系统216包含储存处理电路(storagehandler)226与储存控制器(storagecontroller)228。储存处理电路226用于与通用处理器核心212进行通信并控制储存装置20的数据存取,例如,储存处理电路226可响应于有关数据存取的应用程序编程接口函数来进行信息传递、同步处理与数据流控制。储存控制器228则用于对储存装置20进行实际数据储存,例如,储存装置20可以是通过输入/输出接口40(例如pcie接口或sata接口)而连接至运算装置200的固态硬盘,而储存控制器228会输出写入指令、写入地址与写入数据至储存装置20来进行数据写入,以及会输出读取指令与读取地址至储存装置20来进行数据读取。
加速电路232设计来提供硬件数据处理加速功能,加速电路232可从储存处理电路226接收一数据输入,以及根据该数据输入来处理该数据处理工作的至少一部分的该数据处理的该数据流。假如得自储存处理电路226的数据的数据格式不同于加速电路232所要求的预定数据格式,则数据转换电路236会用于处理储存处理电路226与加速电路232之间的数据转换,举例来说,储存处理电路226所得到并输出的数据会包含一笔完整数据,而加速电路232所要执行的核心函数仅需处理该笔完整数据中的特定字段,因此数据转换电路236会从该笔完整数据中获取出特定字段并传送至加速电路232。
为了简洁起见,在图2中,加速电路232与网络处理电路224之间仅绘示一个数据处理电路234以及在加速电路232与数据处理电路226之间仅绘示一个数据处理电路236,然而,实际应用时,数据处理电路234、236的个数可依据需求而定,例如,在另一实施例中,特殊应用处理器206可以包含复数个加速电路232,分别执行不同的核心函数,由于不同的核心函数会有不同的数据格式需求,因此特殊应用处理器206与网络处理电路224之间可设置复数个数据处理电路234来分别进行不同的数据格式转换,以及特殊应用处理器206与数据处理电路226之间可设置复数个数据处理电路236来分别进行不同的数据格式转换。
如上所述,通用处理器202可将该数据处理工作的至少一部分的该数据处理卸载至辅助处理器204与特殊应用处理器206,其中辅助处理器204负责该数据处理的控制流(至少包含输入/输出堆栈的复数层的处理),而特殊应用处理器206则是负责该数据处理的数据流,本实施例中,运算装置200还包含控制信道218,耦接于特殊应用处理器206(尤其是加速电路232)的接脚与辅助处理器204(尤其是通用处理器核心212)的接脚之间,控制信道218可用于在特殊应用处理器206(尤其是加速电路232)与辅助处理器204(尤其是通用处理器核心212)之间传送控制信息。
在一应用中,加速电路232可从网络处理电路224接收一数据输入,并通过网络处理电路224来传送加速电路232的一数据输出,亦即来自网络挂载装置10的数据经由加速电路232处理后再写回网络挂载装置10,由于数据在网络挂载装置10与加速电路232的路径中完成处理而无需经过通用处理器202,因此可实现网络内部运算(in-networkcomputation)。在另一应用中,加速电路232可从网络处理电路224接收一数据输入,并通过储存处理电路226来传送加速电路232的一数据输出,亦即来自网络挂载装置10的数据经由加速电路232处理后会写入储存装置20,由于数据在网络挂载装置10、加速电路232与储存装置20的路径中完成处理而无需经过通用处理器202,因此可实现网络内部运算。在另一应用中,加速电路232可从储存处理电路226接收一数据输入,并通过网络处理电路224来传送加速电路232的一数据输出,亦即来自储存装置20的数据经由加速电路232处理后会写入网络挂载装置10,由于数据在储存装置20、加速电路232与网络挂载装置10的路径中完成处理而无需经过通用处理器202,因此可实现储存内部运算(in-storagecomputation)。在另一应用中,加速电路232可从储存处理电路226接收一数据输入,并通过储存处理电路226来传送加速电路232的一数据输出,亦即来自储存装置20的数据经由加速电路232处理后会再写回储存装置20,由于数据在储存装置20与加速电路232的路径中完成处理而无需经过通用处理器202,因此可实现储存内部运算。
不同于文件储存(filestorage),对象储存(objectstorage)是一种无阶层数据储存方法,并不使用目录树,而离散的数据单元(对象)存在于储存区中的相同层次,且每个对象都有唯一的标识符,以供应用程序获取对象。对象储存广泛应用于云端储存,本发明所揭示的运算装置200也可应用于对象储存装置的数据处理。
在一对象储存应用中,通用处理器202上所执行的应用程序app可通过调用应用程序编程接口函数api_f来将该数据处理工作的至少一部分的该数据处理卸载至辅助处理器204与特殊应用处理器206,举例来说,特殊应用处理器206是设计来处理具有一核心标识符(kernelidentifier)的一核心函数,该数据处理是用于处理位于一对象储存装置(objectstorage)中且具有一对象标识符(objectidentifier)的一对象,而应用程序编程接口函数api_f的参数可包含该核心标识符与该对象标识符,其中该对象储存装置可以是储存装置20或网络挂载装置10。举例来说,储存装置20为固态硬盘并通过pcie接口连接至运算装置200,因此,运算装置200与储存装置20可整体视为运算型储存装置(computationalstoragedevice,csd),此外,此运算型储存装置可作为分布式对象储存系统的一部分,因此,储存装置20可用于储存复数个对象,且每个对象有自己的对象标识符,通用处理器202上所执行的应用程序app可调用应用程序编程接口函数api_f,以便将对象数据处理的操作卸载至辅助处理器204与特殊应用处理器206,举例来说,应用程序编程接口函数api_f可包含csd_stscsd_put(object_id,object_data,buf_len)、csd_stscsd_put_acc(object_id,object_data,acc_id,buf_len)、csd_stscsd_get(object_id,object_data,buf_len)与csd_stscsd_get_acc(object_id,object_data,acc_id,buf_len),其中csd_stscsd_put(object_id,object_data,buf_len)用于将具备对象标识符object_id的对象数据object_data写入至储存装置20,csd_stscsd_put_acc(object_id,object_data,acc_id,buf_len)用于利用具备核心标识符acc_id的加速电路232来处理具备对象标识符object_id的对象数据object_data并将相对应的运算结果写入至储存装置20,csd_stscsd_get(object_id,object_data,buf_len)用于将具备对象标识符object_id的对象数据object_data从储存装置20读取出来,以及csd_stscsd_get_acc(object_id,object_data,acc_id,buf_len)用于将从储存装置20所读取的具备对象标识符object_id的对象数据object_data送至具备核心标识符acc_id的加速电路232进行处理,并将相对应的运算结果传送出去。
举例来说,csd_stscsd_put(object_id,object_data,buf_len)的操作可用以下的虚拟程序代码(pseudocode)来简单表示:
structnvme_cmdio;
io.opcode=nvme_sdcs;
io.object_id=object_id;
io.object_data=&object_data;
io.xfterlen=buf_len;
returnioctl(fd,nvme_ioctl_submit_io,&io)
另外,csd_stscsd_get_acc(object_id,object_data,acc_id,buf_len)的操作可用以下的虚拟程序代码来简单表示:
structnvme_cmdio;
io.opcode=nvme_sdcs;
io.object_id=object_id;
io.object_data=&object_data;
io.acc_id=acc_id;
io.xfterlen=buf_len;
returnioctl(fd,nvme_ioctl_submit_io,&io)
请注意,上述虚拟程序代码仅作为示例说明之用,本发明并不以此为限,此外,运算装置200所实际采用的应用程序编程接口函数api_f也可依实际设计需求而定。
在另一对象储存应用中,网络挂载装置10可以是分布式对象储存系统中的客户端,并通过网络30连接至运算装置200,此外,储存装置20可以是分布式储存系统中的一部分(例如键值数据库(key-valuestore)的一部分)。加速电路232是设计来执行具有一核心标识符的一核心函数,以及储存装置20中储存具有一对象标识符的一对象。网络挂载装置10可通过网络30发送一特定应用程序编程接口函数,其参数包含该核心标识符以及该对象标识符,因此,运算装置200中的网络子系统214会从网络30接收该特定应用程序编程接口函数(其参数包含该核心标识符以及该对象标识符),接着,通用处理器核心212会从网络子系统214取得该核心标识符以及该对象标识符,并触发具有该核心标识符的该核心函数(亦即加速电路232)来处理位于一对象储存装置(亦即储存装置20)且具有该对象标识符的该对象,其中特殊应用处理器206中的加速电路232对该对象进行处理时,无需通用处理器202上所执行的应用程序app的介入。
如上所述,特殊应用处理器206采用现场可编程逻辑门阵列来实现,由于现场可编程逻辑门阵列中的内部存储器容量很小,因此,特殊应用处理器206(尤其是加速电路232)所能使用的存储器容量有限,然而,假如运算装置200应用于对象储存装置的数据处理,则运算装置200还可采用本发明的虚拟储存存储器(virtualstoragememory)技术,使得特殊应用处理器206(尤其是加速电路232)所使用的片上存储器(on-chipmemory)/嵌入式存储器(例如blockram(bram)或ultraram(uram))可等效视为具有像储存装置一样的大容量,进一步来说,通用处理器核心212根据核心标识符以及对象标识符,触发具有该核心标识符的核心函数(亦即加速电路232)来处理位于一对象储存装置(亦即储存装置20)且具有该对象标识符的对象,基于对象储存的特性,可以根据特殊应用处理器206(尤其是加速电路232)所使用的片上存储器/嵌入式存储器的容量,通过数据流方式来不断读取具有该对象标识符的该对象的连续数据至特殊应用处理器206(尤其是加速电路232)所使用的片上存储器/嵌入式存储器,以供特殊应用处理器206(尤其是加速电路232)进行处理,直到完成具有该对象标识符的该对象的数据处理为止,此外,在对象数据处理过程中,储存装置20与特殊应用处理器206(尤其是加速电路232)所使用的嵌入式存储器之间的数据搬移以及核心函数与应用程序app之间的同步会由辅助处理器204的通用处理器核心212负责,因此通用处理器202所执行的应用程序app完全无需介入储存装置20与特殊应用处理器206(尤其是加速电路232)所使用的片上存储器/嵌入式存储器之间的数据搬移以及核心函数与应用程序app之间的同步。
图4为依据本发明一实施例的采用虚拟储存存储器技术来进行对象数据处理的运算装置的示意图。假设运算装置200采用多重处理系统芯片来实现,且连接至运算装置200的储存装置为对象储存装置412。多重处理系统芯片可划分为处理系统(processingsystem,ps)400以及可编程逻辑模块(programmablelogic,pl)401,其中处理系统400包含应用处理器单元402(用于实现图2所示的通用处理器202)以及实时处理器单元404(用于实现图2所示的通用处理器核心212),而可编程逻辑模块401则包含加速电路406(用于实现图2所示的加速电路232)、片上存储器408(例如bram或uram)以及储存控制器410(用于实现图2所示的储存控制器228)。请注意,为了简洁起见,图4仅绘示一部分的组件,实际上,多重处理系统芯片可包含运算装置200的其它组件。
一开始时,应用处理器单元402会发送指令(例如应用程序编程接口函数)至实时处理器单元404,其中指令(例如应用程序编程接口函数)可包含核心标识符与对象标识符,此外,指令(例如应用程序编程接口函数)还可包含可编程逻辑模块401的一些参数。接着,实时处理器单元404决定具有该对象标识符的对象414的储存位置,并根据片上存储器408的容量大小(buffersize)来发送指令至储存控制器410,因此,储存控制器410会从对象储存装置412读取对象414中具有片上存储器408的容量大小的一笔数据并写入至片上存储器408。接着,实时处理器单元404会发送指令至加速电路406来触发具有该核心标识符的核心函数,因此,加速电路406会从片上存储器408读取对象数据并执行具有该核心标识符的核心函数来对对象数据进行处理。在完成片上存储器408所储存的对象数据的处理之后,加速电路406会传送信息告知实时处理器单元404。接着,实时处理器单元404会判断针对对象414的数据处理是否全部完成,若针对对象414的数据处理尚未全部完成,则实时处理器单元404会再根据片上存储器408的容量大小来发送指令至储存控制器410,因此,储存控制器410会从对象储存装置412读取对象414中具有片上存储器408的容量大小的下一笔数据并写入至片上存储器408。接着,实时处理器单元404会发送指令至加速电路406来触发具有该核心标识符的核心函数,因此,加速电路406会从片上存储器408读取对象数据并执行具有该核心标识符的核心函数来对对象数据进行处理。上述步骤会不断重复执行,直到实时处理器单元404判断针对对象414的数据处理已全部完成为止,此外,当针对对象414的数据处理已全部完成时,实时处理器单元404会传送信息来告知应用处理器单元402。
在图2所示的实施例中,可编程电路208同时包含网络子系统214与储存子系统216,然而,这仅作为示例说明,本发明并不以此为限,任何利用辅助处理器与特殊应用处理器来从通用处理器卸载数据处理的电路架构均落入本发明的范畴。
图5为依据本发明一实施例的可编程电路的示意图。图2所示的运算装置200可修改而采用图5所示的可编程电路500,亦即可编程电路500可取代图2所示的可编程电路208,相比于可编程电路208,可编程电路500并未包含网络子系统214与数据转换电路234,因此,针对无需通过网络30来连接至网络挂载装置10的应用,本发明运算装置中的可编程电路便可采用图5所示的设计。
图6为依据本发明另一实施例的可编程电路的示意图。图2所示的运算装置200可修改为采用图6所示的可编程电路600,亦即可编程电路600可取代图2所示的可编程电路208,相比于可编程电路208,可编程电路600并未包含储存子系统216与数据转换电路236,因此,针对无需通过输入/输出接口40来连接至储存装置20的应用,本发明运算装置中的可编程电路便可采用图6所示的设计。
请注意,图2、图5与图6中的数据转换电路234、236可以是选择性(optional)组件,也就是说,可根据不同的设计需求来决定可编程电路208、500、600是否需要数据转换电路234、236,举例来说,假如加速电路232所要求的预定数据格式可涵盖得自网络流的负载数据的数据格式,便可省略数据转换电路234,同理,假如加速电路232所要求的预定数据格式可涵盖得自储存处理电路226的数据的数据格式,便可省略数据转换电路236。这些设计上的变化均属本发明的涵盖范围。
综上所述,本发明运算装置可具备网络子系统来链接至网络且可针对对象储存来执行相关数据处理,因此具有极高的可扩展性,在一应用中,本发明运算装置可兼容于现有的对象储存服务(例如amazons3或其它云端储存服务),因而可基于来自网络的对象储存指令(例如amazons3select)来针对运算装置所连接的对象储存装置进行数据获取的相关数据处理,在另一应用中,本发明运算装置可从网络接收nvme/tcp指令,并基于nvme/tcp指令来对运算装置所连接的储存装置进行相关的数据处理操作,假如运算装置所连接的储存装置是分布式储存系统中的一部分(例如键值数据库的一部分),则从网络所接收nvme/tcp指令可包含键值指令,本发明运算装置便可基于键值指令来对储存装置进行相关的键值数据库数据处理操作。此外,数据可在移动过程中便经由硬件加速电路完成处理,过程中无需执行应用程序的通用处理器介入数据搬移以及软件与硬件之间的通信,因此可实现网络内部运算和/或储存内部运算,进而节省功耗、减少延迟并降低通用处理器的负荷;再者,本发明运算装置可采用多重处理系统芯片来实现,例如多重处理系统芯片可包含现场可编程逻辑门阵列以及采用arm架构的通用处理器核心,因此具有很高的设计弹性,设计人员可根据需求来自行设计通用处理器核心所要执行的应用程序/程序代码以及现场可编程逻辑门阵列所要具备的硬件数据处理加速功能,例如可将本发明运算装置应用于数据中心(datacenter),可通过定制化来支持各种数据类型与单元格式并得到最佳效能,由于单一多重处理系统芯片便可取代高阶服务器,因此采用本发明运算装置的数据中心可具有较低的建置成本。
以上所述仅为本发明的较佳实施例,凡依本发明权利要求所做的均等变化与修饰,皆应属本发明的涵盖范围。
[符号说明]
10:网络挂载装置
20,104,312,322:储存装置
30:网络
40,112:输入/输出接口
100,300:计算机系统
102:计算机主机
105,314:加速卡
106:中央处理器
108:系统存储器
110,310:网络接口
114:存储器
200:运算装置
201:芯片
202:通用处理器
204:辅助处理器
206:特殊应用处理器
208,500,600:可编程电路
212:通用处理器核心
214,330:网络子系统
216,332:储存子系统
222:tcp/ip卸载引擎
224:网络处理电路
226:储存处理电路
228,410:储存控制器
232,334,406:加速电路
234,236:数据转换电路
302:应用程序
304:操作系统核心
306:文件系统
308:驱动程序
320:多重处理系统芯片
324,402:应用处理器单元
326,404:实时处理器单元
328:现场可编程逻辑门阵列
400:处理系统
401:可编程逻辑模块
408:片上存储器
412:对象储存装置
414:对象
app:应用程序
api_f:应用程序编程接口函数
sw:程序代码
- 还没有人留言评论。精彩留言会获得点赞!