一种动力系统的低维流形故障定位方法
1.本发明涉及动力系统的故障检测建模技术领域,尤其涉及一种动力系统的低维流形故障定位方法。
背景技术:
2.对动力装置运行过程的准确描述是分析其工作状态与行为特征的关键。系统的运行过程通过其行为表现出来,而系统的行为则是通过安装在系统上的所有传感器获得的。动力装置是由成百上千的零部件组合而成,各部件通过相互作用共同完成其设计功能,因此安装在动力装置上的传感器所测量的参数并不是相互独立的,可以说这些传感器通过彼此之间的约束关系共同描述了系统复杂而有序的行为。
3.对于动力装置这样复杂的机械动力系统,其行为特征可以从两方面表现,一是支撑其功能的机械结构,常通过振动信号来表现,二是其功能结构,常通过工质在系统结构中的状态来表现。无论哪个方面,各个传感器之间的约束关系都表现为很强的非线性映射关系。因此,根据传感器的约束关系对动力系统进行建模具有很强的实用性与现实意义,为检测设备运行工况,诊断故障打下基础。
4.传统的异常检测方法在建立动力装置的动力学模型方面遇到了很大的困难,首先机械部件之间的耦合关系极为复杂,此外在信号处理方面,由于部件的运动方式受到外界的干扰,并且部件耦合导致的信号混叠使得通过测量的信号很难获得单一部件的行为模式,信号之间以及信号和噪声之间的分解异常困难。
技术实现要素:
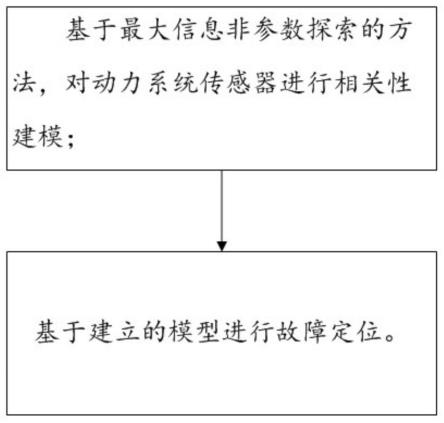
5.本技术提供了一种动力系统的低维流形故障定位方法。
6.本发明提供的一种动力系统的低维流形故障定位方法,
7.包括如下步骤:
8.步骤s1:基于最大信息非参数探索的方法,对动力系统传感器进行相关性建模;
9.步骤s2:基于步骤s1建立的模型进行故障定位。
10.其中,
11.所述步骤s1,包括如下步骤:
12.步骤s11,将待建模系统的多维传感器数据进行预处理;
13.步骤s12,对各传感器数据进行相关性建模;
14.步骤s13,根据所建模数据,进行建模可视化。
15.其中,
16.所述最大信息非参数探索的方法是一种基于互信息的相关性评价方法,该方法在互信息的基础上定义了一个评价两个变量之间相关性的指标mic:
17.mic被定义为两个变量组成的所有二维栅格中能够使样本点分辨率最高的划分的归一化互信息,这些互信息将构成一个矩阵,而mic就是矩阵中的最大值。
18.其中,
19.在计算mic时,所述x和y通过基于动态规划思想的算法计算。
20.与现有技术相比,本发明的有益效果为,
21.本发明提出了一种动力系统的低维流形故障定位方法,在方法中公开了一种基于最大信息非参数探索的高效的相关性评价指标,对x动力装置传感器进行相关性建模的方法,有效对动力系统的模型进行了描述,通过对传感器之间相关性的变化的描述系统的行为,既解决了燃机在模型建立上的问题,也克服了单一传感器信号处理过程中由于信息不完备造成的分析困难问题。
附图说明
22.图1为本技术的方法流程图;
23.图2为本技术的平均互信息几何意义示意图;
24.图3为数据集1-6工况的转速曲线图;
25.图4为数据集6-1工况的转速曲线图;
26.图5为数据集1-3-6工况的转速曲线图;
27.图6为数据集6-3-1工况的转速曲线图;
28.图7为数据集nf1t6稳态_mic_聚类粒度0.9_权值过滤阈值0.95995846条件下的各个传感器测点之间的关联关系图;
29.图8为数据集nf1t6瞬态-mic_聚类粒度0.9_权值过滤阈值0.99354691条件下的各个传感器测点之间的关联关系图;
30.图9为数据集nf1t6稳态-mic_聚类粒度0.9_权值过滤阈值0.94476776条件下的各个传感器测点之间的关联关系图;
31.图10为数据集nf6t1稳态-mic-聚类粒度0.9-权值过滤阈值0.93316456条件下的各个传感器测点之间的关联关系图;
32.图11为数据集nf6t1瞬态-mic-聚类粒度0.9-权值过滤阈值0.94721188条件下的各个传感器测点之间的关联关系图;
33.图12为数据集nf6t1稳态-mic-聚类粒度0.9-权值过滤阈值0.94218716条件下的各个传感器测点之间的关联关系图。
具体实施方式
34.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
35.以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
36.如图1所示,本发明实施例提供的一种动力系统的低维流形故障定位方法的具体方案,包括如下步骤:
37.步骤s1:基于最大信息非参数探索的方法,对动力系统传感器进行相关性建模;
38.需要说明的是,上述的基于最大信息非参数探索的x动力系统传感器相关性建模方法,用于动力系统的故障检测建模,可用于对高维系统(多传感器系统)进行建模,并非局
限于动力系统,包括如下步骤:
39.步骤s11,将待建模系统的多维传感器数据进行预处理;
40.步骤s12,对各传感器数据按后文所述方法进行相关性建模;
41.需要说明的是,比起现有技术,对比多种相关性计算方法,使用最适用于动力系统的mic指标方法,因此更准确、更高效。
42.步骤s13,根据所建模数据,进行建模可视化,可直观观察建模效果。
43.以下是该方法所使用的理论以及算法伪代码。
44.设有两个动力系统传感器变量x、y,
45.cov(x,y)=e(x-e(x))(y-e(y))为它们的协方差系数,则x、y的相关系数为
[0046][0047]
互信息是信息论中有一种相关性评价方法,度量两个事件集合之间的相关性。平均互信息量定义为:
[0048][0049]
互信息还可以通过离散的联合概率分布进行定义:
[0050][0051]
互信息量i(xi;yj)在联合概率空间p(xy)中的统计平均值。平均互信息i(x;y)克服了互信息量i(xi;yj)的随机性,成为一个确定的量。平均互信息量的几何含义可以通过图2进行描述。
[0052]
从图中可以得到如下关系:
[0053]
i(x;y)=h(x)-h(x|y)
[0054]
i(x;y)=h(y)-h(y|x)
[0055]
i(x;y)=h(x)+h(y)-h(xy)
[0056]
需要说明的是,最大信息非参数探索的方法是一种基于互信息的相关性评价方法。该方法在互信息的基础上定义了一个评价两个变量之间相关性的指标mic(the maximal information coefficient):
[0057][0058]
这也是本发明所使用并优化的方法。在该方法中,mic被定义为两个变量组成的所有二维栅格中能够使样本点分辨率最高的划分的归一化互信息。这些互信息将构成一个矩阵,而mic就是矩阵中的最大值。
[0059]
在计算mic时,一个基于动态规划思想的算法被用于确定合理的x和y(x和y分别是待计算相关性的两传感器数据),其算法伪代码过程如下:
[0060][0061]
其中maxmi函数用来获得最大的互信息。该算法首先确定预划分的网格数量并依此确定网格的分辨率,然后通过maxmi函数计算改分辨率下的最大互信息。当获得了各种分辨率情况下的最大互信息后便可以形成一个矩阵,其行、列分别描述网格行列划分数量。此时矩阵中最大的互信息将作为这两个变量的互信息,用来描述它们之间的相关程度。
[0062]
在实际过程中,使用基于动态规划的approxmaxmi算法计算maxmi,而approxmaxmi算法中的一个关键的过程是获得优化的x轴划分的函数optimizexaxis。给定一个y轴的划分,optimizexaxis函数可以找到能够使得网格内互信息最大的一个x轴划分。
[0063]
给定一个x轴上由数据集d中m个节点构成的划分p,设h(p)为这m个节点在p上各列的熵的分布,同样的,h(q)为y轴上和划分q相关的熵的分布。那么h(p,q)为由p和q构成的网格的单元中熵的分布。
[0064]
根据信息熵的定义有i(x;y)=h(x)+h(y)-h(x,y),可以定义为:
[0065]
i(p;q)=h(p)+h(q)-h(p,q),由于q的划分是固定的,所以optimizexaxis函数只需要使得h(q)-h(p,q)是最大的。
[0066]
在计算最大的h(q)-h(p,q)时,可以根据如下假设进行,即对于一个固定的y轴划分和一个大小为n的数据集d,对每一个属于n的m和l,可以定义一个以m为初值一直到l的过程中的f(m,l)使得h(p)-h(p,q)最大。这里l>1,1<m≤n。f(m,l)的递归定义为:
[0067][0068]
上述的递归定义是一个典型的动态规划过程,它构造了f的一张表,并返回一个f(n,l),这里l即为想要得到的划分尺寸。在计算optimizexaxis的过程中,x轴的划分是被限制在同一个y轴划分中两簇连续的样本点之间的,这样的做法增加了计算的效率,因为无论一个连续的散点簇被如何的划分到一些列中,这些列对h(p)-h(p,q)的贡献都是0,在optimizexaxis算法中的例程getclumpspartition便是用于寻找这些节点簇的函数,它得到的是能够把这些簇划分开来的最小划分。
[0069]
基于上面的分析,可以得到optimizexaxis的算法过程如下:
[0070][0071][0072]
approxmaxmi算法中的另一个关键的过程是优化相关性计算的时间,提高计算的效率。为了实现这个目的,需要将一个轴的划分进行固定。当然,使用两个轴共同进行选择将会获得一个优化的网格,但是在效率上是不可行的,因此这里的做法是将y轴进行固定,同时保证每一行中包含同样多的样本点。而为了得到合理的互信息计算结果,approxmaxmi算法将被执行两次,不同的是两次的x轴和y轴是互换的。
[0073]
用来均分y轴的算法是equipartitionyaxis函数,其算法如下所示:
[0074][0075]
另一个改善计算效率的方法是限制节点簇的函数。如果在数据集d中y轴的划分q有p个,这些划分产生的节点簇为k个,则optimizexaxis(d;q;x)算法的时间复杂度为o(k2xy)。显然对于大的样本集来说这是不能被接受的。因此需要另一个参数用来限制节点簇的数量。当时,真实的样本簇将被合并为超集簇,并且这些超级簇中的节点数量近似相等。参数将是计算效率与优化的折中。
[0076]
通过调用上面这些关键过程,便可以实现approxmaxmi算法,其过程如下:
[0077][0078]
而algorithm1也将进行重新改写,将针对每一个具体的y轴划分数量得到一个优化的x轴划分。算法的具体过程如下所示。
[0079][0080]
该建模所使用数据集由大量的发电系统运行加密数据组成。该动力系统实验装置由反应堆、主冷却剂泵、稳压器、蒸汽发生器、给水泵、给水加热器、冷凝水泵、海水泵、分离器、再热器等组成。电厂系统模拟器对正常和故障数据进行了模拟,该模拟器为主系统和次系统提供了121个传感器响应输出。为了获得正常的数据,我们进行了六次不同作战环境的模拟。在模拟过程中采样频率为4hz,这将导致收集处于健康状态的76632个样本。在故障数据生成过程中,核电厂在每次模拟中都从正常状态开始,然后将故障设定在运行过程中的某一点发生。
[0081]
动力系统在运行时共有六个工况。
[0082]
在数据实验中,对所拥有的六种数据集进行了划分,分为稳态工况和瞬态工况两部分。
[0083]
如图3和图4所示,1-6指的是从1工况变到6工况。6-1就是反过来的工况6-工况1,下面相关描述也是一样。1-3-6与6-3-1分为五部分:如图5和图6所示。
[0084]
利用mic指标计算得到的数据集nf1t6中各个传感器测点之间的关联关系如图7、8、9所示;数据集nf6t1中各个传感器测点之间的关联关系如图10、11、12所示。
[0085]
步骤s2:基于上述建立的模型进行故障定位。
[0086]
需要说明的是,本技术中未详述的技术方案,采用公知技术。
[0087]
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1