一种基于差分隐私的在线分类方法与流程
本发明属于分类方法领域,具体涉及一种基于差分隐私的在线分类方法。
背景技术:
在线分类问题已受到广泛关注,形成了一系列围绕求解在线问题的快速算法,包括在线梯度下降法,在线牛顿方法等。其中在线梯度下降法是在借鉴传统的梯度信息的基础上,借助批次梯度代替整体梯度,使得算法的时间消耗和计算成本有效降低。在在线梯度下降法的基础上涌现出大量二分类的快速求解问题的研究结果,包括模型,理论等各个方面。但现有方法很少涉及到算法的隐私保护问题。
市场化的今天,高效运行的方法是符合主流需求的算法,但是在处理大量流式数据时,可能会涉及到个人的敏感数据,这同样制约着数据要素的高效配置。因此,在保证个体隐私不被泄露的条件下学习高效的在线分类算法将加速提升数据要素价值。如何实现现有的在线梯度下降法既可用于分析包含隐私敏感信息的数据,又能保证算法运行效率是个亟待解决的问题。
为使得在线梯度下降法可以高效的分析包含敏感信息的数据,本申请在隐私保护的新范式——差分隐私框架下给出在线logistic回归新的求解算法,提出一种基于差分隐私的在线分类方法。
技术实现要素:
为了克服上述现有技术存在的不足,本发明提供了一种基于差分隐私的在线分类方法。
为了实现上述目的,本发明提供如下技术方案:
一种基于差分隐私的在线分类方法,包括以下步骤:
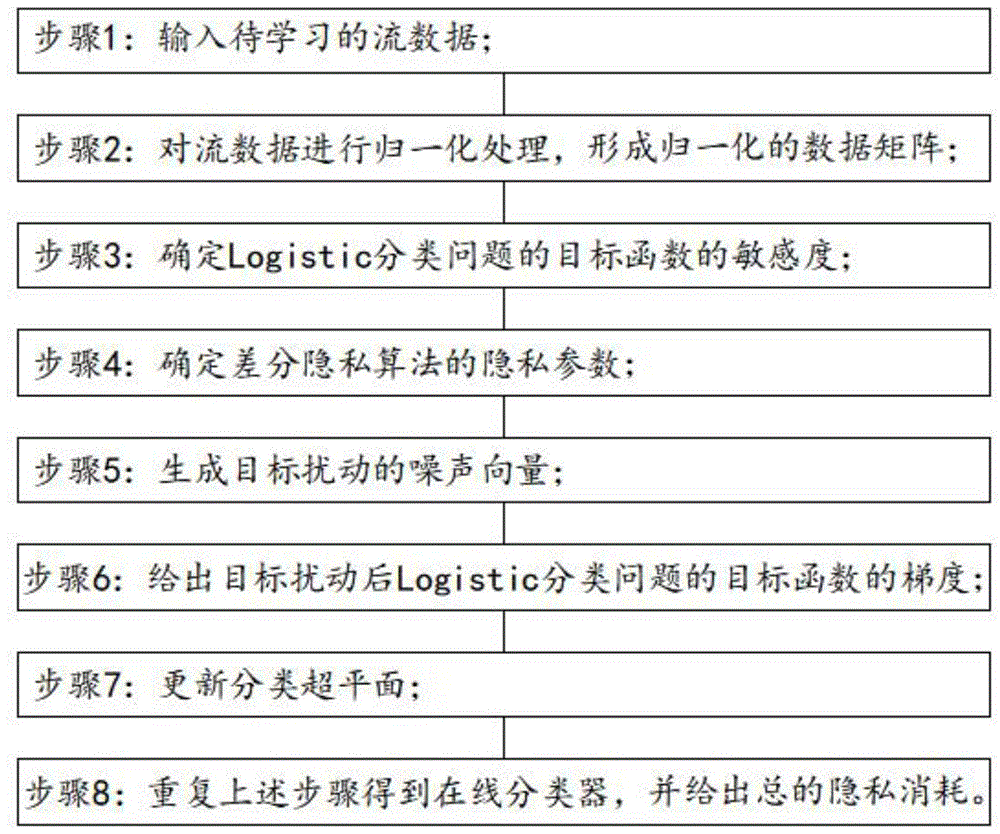
步骤1:输入待学习的流数据;
步骤2:对流数据进行归一化处理,形成归一化的数据矩阵;
步骤3:确定logistic分类问题的目标函数的敏感度;
步骤4:确定差分隐私算法的隐私参数;
根据对隐私保护程度的具体要求给定第t批数据学习过程中的隐私参数εt,εt可取大于0的任何数,εt取值越小代表隐私保护程度越强,反之εt取值越大代表隐私保护程度越弱;
步骤5:生成目标扰动的噪声向量;
步骤6:给出目标扰动后logistic分类问题的目标函数的梯度;
步骤7:更新分类超平面;
步骤8:重复上述步骤得到在线分类器,并给出总的隐私消耗。
优选地,所述步骤1中:
通过一批一批的记录累积得到流数据,将最新一批数据作为输入,记第t批数据为pt(zt,yt),其中zt为属性数据矩阵,yt为类标签数据向量,要求yt中元素的值属于{-1,+1},给出pt的样本量nt和zt的维度p。
优选地,所述步骤2中:
对于nt×p的属性数据矩阵zt,计算每行数据向量的二范数,记其中最大值为max,令xt=zt/max为归一化的属性数据矩阵,dt=(xt,yt)为归一化的数据矩阵。
优选地,所述步骤3中:
对于分类指标属于{-1,+1}的分类问题,具有罚项的logistic分类模型的目标函数为:
其中,样本点(xi,yi)为数据集dt=(xt,yt)中的个体,nt为样本量,ωt为待估计的分类超平面,λ为惩罚参数,惩罚参数需预先给定;
对于经过步骤2预处理的归一化数据矩阵dt=(xt,yt),logistic分类问题的目标函数的l2敏感度为:
这里dt′为dt的邻接矩阵,即数据矩阵dt′与dt只有一行数据(一个样本)不相同。
优选地,所述步骤5中:
基于步骤3给出的敏感度与步骤4给出的隐私参数生产噪声向量bt,具体的:
bt=b·n
这里b为p维单位球球面的一个随机点,n为抽取自伽马分布
优选地,所述步骤6中:
基于步骤5生成的噪声向量bt,基于目标扰动方法的logistic分类问题的目标函数为:
其梯度向量为:
优选地,所述步骤7中:
基于第t步(对应第t-1批数据)的更新结果ωt和步骤6给出的
这里ηt为学习率。
优选地,所述步骤8中:
流数据分批获取,对于每批数据均需要执行步骤1到步骤7,得到的分类超平面即可用来更新分类超平面,又可作为分类器来对目标数据进行分类,经过t批数据的在线学习了,总的隐私消耗为
本发明提供的基于差分隐私的在线分类方法具有以下有益效果:
本发明通过各步骤学习的在线分类器满足差分隐私,即具有隐私保护的能力,流数据中个体的隐私不会被泄漏。在保护隐私的同时,分类器还具有较高的可用性,可以判断出目标数据的具体类别。
通过在线logistic回归模型学习分类器是在线学习中广泛使用的模型,本发明解决了该模型差分隐私求解问题,保证分类器的学习过程不泄漏数据中个体的隐私。
附图说明
为了更清楚地说明本发明实施例及其设计方案,下面将对本实施例所需的附图作简单地介绍。下面描述中的附图仅仅是本发明的部分实施例,对于本领域普通技术人员来说,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例1的基于差分隐私的在线分类方法的流程图。
具体实施方式
为了使本领域技术人员更好的理解本发明的技术方案并能予以实施,下面结合附图和具体实施例对本发明进行详细说明。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”、“轴向”、“径向”、“周向”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明的技术方案和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
此外,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。在本发明的描述中,需要说明的是,除非另有明确的规定或限定,术语“相连”、“连接”应作广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体式连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以是通过中间媒介间接相连。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上,在此不再详述。
实施例1
本发明提供了一种基于差分隐私的在线分类方法,具体如图1所示,包括包括以下步骤:
步骤1:输入待学习的流数据;
现实中大量可用数据并非一次获取,而是通过一批一批的记录累积得到流数据,如购物平台每分钟都会收集到新的浏览记录,银行每天会收集到新的信用卡使用记录,在每获得一批新数据后都需要更新学习结果。
在线学习任务的目标数据集无法一次获取,而是通过一批一批的记录累积得到,将最新一批数据作为输入,记第t批数据为pt=(zt,yt),其中zt为属性数据矩阵,yt为类标签数据向量,要求yt中元素的值属于{-1,+1},给出pt的样本量nt和zt的维度p。
步骤2:对流数据进行归一化处理,形成归一化的数据矩阵;
为给出步骤3中logistic分类问题的目标函数的敏感度,需要对属性数据矩阵zt进行归一化处理,要求每个样本的欧几里德范数不大于1,即属性数据矩阵zt的每一行的欧几里德范数不大于1。
对于nt×p的属性数据矩阵zt,计算每行数据向量的二范数,记其中最大值为max,令xt=zt/max为归一化的属性数据矩阵,dt=(xt,yt)为归一化的数据矩阵;
步骤3:确定logistic分类问题的目标函数的敏感度;
为给出步骤5中的噪声,需要确定logistic分类问题的目标函数的敏感度。对于分类指标属于{-1,+1}的分类问题,具有罚项的logistic分类模型的目标函数为:
其中,样本点(xi,yi)为数据集dt=(xt,yt)中的个体,nt为样本量,ωt为待估计的分类超平面,λ为惩罚参数,惩罚参数需预先给定;
对于经过步骤2预处理的归一化数据矩阵dt=(xt,yt),logistic分类问题的目标函数的l2敏感度为:
这里dt′为dt的邻接矩阵,即数据矩阵dt′与dt只有一行数据(一个样本)不相同;
步骤4:确定差分隐私算法的隐私参数;
流数据中可能包含个人敏感信息,典型的如购物平台的浏览数据中会包括用户的购物习惯和私密购物行为,信用卡数据中会包括个人的金融信息。在在线学习的过程中需要保护数据中个体的隐私,本技术方案通过差分隐私技术来实现隐私保护的功能。在差分隐私框架中,隐私参数ε精确度量隐私保护的程度,因此要根据数据集所包含隐私信息的重要程度和数据拥有者可接受的隐私泄漏程度等预先给定隐私参数ε。在在线学习中,每批数据中都可能包含新的敏感信息,因此在每批数据的学习中都要设置隐私参数。
根据对隐私保护程度的具体要求给定第t批数据学习过程中的隐私参数εt,εt可取大于0的任何数,εt取值越小代表隐私保护程度越强,反之εt取值越大代表隐私保护程度越弱;
步骤5:生成目标扰动的噪声向量
基于步骤3给出的敏感度与步骤4给出的隐私参数生产噪声向量bt,具体的:
bt=b·n
这里b为p维单位球球面的一个随机点,n为抽取自伽马分布
步骤6:给出目标扰动后logistic分类问题的目标函数的梯度;
基于步骤5生成的噪声向量bt,基于目标扰动方法的logistic分类问题的目标函数为:
其梯度向量为:
步骤7:更新分类超平面;
基于第t步(对应第t-1批数据)的更新结果ωt和步骤6给出的
这里ηt为学习率;
步骤8:重复上述步骤得到在线分类器,并给出总的隐私消耗;
流数据分批获取,对于每批数据均需要执行步骤1到步骤7,得到的分类超平面即可用来更新分类超平面,又可作为分类器来对目标数据进行分类,经过t批数据的在线学习了,总的隐私消耗为
下面,以信用卡数据为例,对上述基于差分隐私的在线分类方法作进一步的举例说明,具体包括以下步骤:
步骤1:以信用卡数据做为输入
该数据集为银行客户的信用卡使用信息。每批数据包含200个样本,每个样本包含14个属性和1个分类标签,属性中包括人口统计因素,信用数据,付款历史和账单信息等,分类标签为是否设置下月默认还款,标签值为1表示用户开启了下月默认还款,标签值为-1表示用户未开启下月默认还款。
步骤2:对流数据进行归一化处理,形成归一化的数据矩阵
为给出步骤3中logistic分类问题的目标函数的敏感度,需要对属性数据矩阵进行归一化处理,要求每个样本的欧几里德范数不大于1,对于该流数据即要求每个个体的属性向量(14个属性)的欧几里德范数不大于1。
步骤3:确定logistic分类问题的目标函数的敏感度
为给出步骤5中的噪声,需要确定logistic分类问题的目标函数的敏感度。给定惩罚参数λ=0.15,对于经过步骤2预处理的归一化数据,logistic分类问题的目标函数的l2敏感度为1/15。在该实施例中每批数据的样本量均为200,故对于不同批次数据l2敏感度保持不变。
步骤4:确定差分隐私算法的隐私参数
信用卡数据中包含个人的金融信息这一重要隐私,在训练分类器时需保护数据中个体的隐私。为说明本技术方案的效用,分别给定隐私参数εt=0,1/240,1/120,5/120,其中ε=0表示非隐私保护。
步骤5:生成目标扰动的噪声向量
针对步骤4中4种不同的隐私参数设置,分别生成噪声向量bt=b·n。当εt=0时,噪声向量为空向量,对于非零的隐私参数设置,b的生成方式为首先生成一个[-1,1]上的14维随机向量
步骤6:给出目标扰动后logistic分类问题的目标函数的梯度
基于步骤5生成的噪声向量bt,求出基于目标扰动方法的logistic分类问题的目标函数的梯度向量
步骤7:更新分类超平面
基于第t步(对应第t-1批数据)的更新结果ωt和步骤6给出的梯度向量
步骤8:重复上述步骤学习出分类器,并给出总的隐私消耗
在线学习了t批数据后,总的隐私消耗分别为ε=0,0.5,1,5。针对不同参数设定下的学习结果,在目标数据下测试分类器的准确率可得如下结果。
对比不同参数设置下的准确率(accuracy)可发现,随着隐私参数的变大准确率逐步提高,符合本技术方案的噪声生成机制。对于合适的学习率,在差分隐私约束下所学习的分类器的分类效果非常接近非隐私分类器,说明本技术方案在保护个体隐私的同时还具有较高的可用性。
以上所述实施例仅为本发明较佳的具体实施方式,本发明的保护范围不限于此,任何熟悉本领域的技术人员在本发明披露的技术范围内,可显而易见地得到的技术方案的简单变化或等效替换,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!