动态场景下基于全卷积神经网络的视觉SLAM方法及系统
动态场景下基于全卷积神经网络的视觉slam方法及系统
技术领域
1.本发明涉及计算机视觉技术领域,具体地,涉及一种动态场景下基于全卷积神经网络的视觉slam方法和一种动态场景下基于全卷积神经网络的视觉slam系统。
背景技术:
2.同时定位与地图构建(simultaneous localization and mapping,slam),指机器人在陌生环境中通过自身携带的传感器估计自身位姿与构建环境地图的过程,它是很多机器人应用场景的先决条件,如路径规划、无碰撞导航、环境感知等。视觉slam指利用视觉信息进行摄像机的自身位姿估计与环境三维地图构建的感知。
3.现有技术中,可以根据输入图像的相邻两帧间特征点匹配来估计该两帧相对位移,从而计算出摄像机的实际位移,但是场景中缓慢移动的动态物体能够导致摄像机位姿计算出现偏差从而致使整个视觉slam系统定位失准。
技术实现要素:
4.针对现有技术中缓慢移动的动态物体导致摄像机位姿计算出现偏差从而致使整个视觉slam系统定位失准的技术问题,本发明提供了一种动态场景下基于全卷积神经网络的视觉slam方法和一种动态场景下基于全卷积神经网络的视觉slam系统,采用该方法能够有效的提高摄像机跟踪的准确性和鲁棒性,提高视觉slam在动态场景中定位与建图精度。
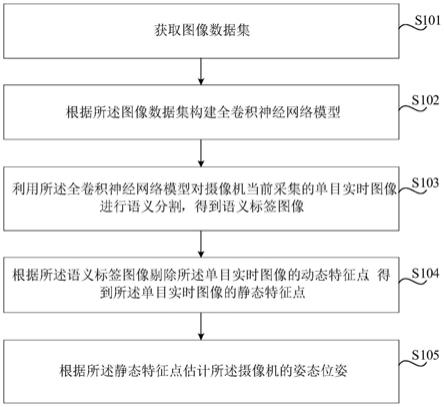
5.为实现上述目的,本发明一方面提供的一种动态场景下基于全卷积神经网络的视觉slam方法,该方法包括以下步骤:获取图像数据集;根据所述图像数据集构建全卷积神经网络模型;利用所述全卷积神经网络模型对摄像机当前采集的单目实时图像进行语义分割,得到语义标签图像;根据所述语义标签图像剔除所述单目实时图像的动态特征点,得到所述单目实时图像的静态特征点;根据所述静态特征点估计所述摄像机的位姿。
6.进一步地,所述利用所述全卷积神经网络模型对摄像机当前采集的单目实时图像进行语义分割,得到语义标签图像,包括:利用所述全卷积神经网络模型中与vgg16网络的全连接层输入数据尺寸相同的卷积核将所述vgg16网络的全连接层转化为卷积层,得到fcn
‑
vgg16网络;对所述fcn
‑
vgg16网络进行优化;利用优化后的fcn
‑
vgg16网络对所述单目实时图像进行动态目标与背景的二分类操作,得到所述语义标签图像。
7.进一步地,所述方法还包括:在所述fcn
‑
vgg16网络中每一次卷积计算后,使用线性整流函数作为激励函数对前一卷积层进行稀疏性处理;对所述fcn
‑
vgg16网络中每一池化层进行池化操作。
8.进一步地,所述对所述fcn
‑
vgg16网络进行优化,包括:引入跳跃结构对所述fcn
‑
vgg16网络中的每一池化层进行上采样操作和融合,得到所述优化后的fcn
‑
vgg16网络。
9.进一步地,所述利用优化后的fcn
‑
vgg16网络对所述单目实时图像进行动态目标与背景的二分类操作,得到所述语义标签图像,包括:确定所述优化后的fcn
‑
vgg16网络的热图的类别个数;确定所述单目实时图像属于目标类别的预测概率;根据所述热图的类别
个数和所述预测概率识别所述单目实时图像的动态目标;根据识别出的动态目标对所述单目实时图像进行语义分割,得到所述语义标签图像。
10.进一步地,根据所述热图的类别个数和所述预测概率通过以下方式识别所述单目实时图像的动态目标:
[0011][0012]
其中,m为所述热图的类别个数,c为所述单目实时图像的目标类别,y
ic
为虚拟参数,p
ic
为所述单目实时图像属于目标类别c的预测概率,l为损失值;根据所述损失值的大小识别所述单目实时图像的动态目标。
[0013]
进一步地,所述根据语义分割结果剔除所述单目实时图像的动态特征点,得到所述单目实时图像的静态特征点,包括:以第一缩放因子对所述单目实时图像进行图像金字塔分层,得到多层第一缩放图像;以第二缩放因子对所述语义标签图像进行图像金字塔分层,得到多层第二缩放图像;依次剔除每一第一缩放图像中的动态特征点:对所述每一第一缩放图像进行orb特征提取,得到每一第一缩放图像的orb特征点;对所述每一第二缩放图像中的动态区域的像素点输出像坐标值形成集合u
i
,其中,i为第二缩放图像的层数,所述动态区域为所述动态目标所在的区域;将每一第一缩放图像的orb特征点的坐标值与对应的集合u
i
中的坐标值进行匹配;在每一第一缩放图像中剔除坐标值与所述集合u
i
中的坐标值匹配的orb特征点;将每一第一缩放图像中保留下的orb特征点形成静态特征点集合m;所述根据所述静态特征点估计所述摄像机的位姿,包括:根据所述静态特征点集合m估计所述摄像机的位姿。
[0014]
进一步地,所述第一缩放因子与所述第二缩放因子相同。
[0015]
进一步地,将所述orb特征点的坐标值与所述集合u
i
中的坐标值进行匹配之前,还包括:存储所述orb特征点。
[0016]
本发明另一方面提供一种动态场景下基于全卷积神经网络的视觉slam系统,所述系统被配置为采用上文所述的动态场景下基于全卷积神经网络的视觉slam方法来估计摄像机的位姿。
[0017]
通过本发明提供的技术方案,本发明至少具有如下技术效果:
[0018]
本发明的动态场景下基于全卷积神经网络的视觉slam方法,以orb_slam2开源视觉slam系统为框架,构建全卷积神经网络模型,利用全卷积神经网络模型识别摄像机当前采集的单目实时图像中的动态目标,并对单目实时图像图进行语义分割,对图像中的动态目进行标记,最后利用坐标点映射剔除单目实时图像的动态特征点,保留单目实时图像中的静态特征点,根据静态特征点估计摄像机的位姿。通过本发明提供的方法能够准确识别动态目标并完成语义分割,有效的提高摄像机跟踪的准确性和鲁棒性,提高视觉slam在动态场景中的定位与建图精度。
[0019]
本发明的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
[0020]
图1为本发明实施例提供的动态场景下基于全卷积神经网络的视觉slam方法的流
程图;
[0021]
图2为本发明实施例提供的动态场景下基于全卷积神经网络的视觉slam方法中fcn
‑
vgg16网络的示意图;
[0022]
图3为本发明实施例提供的动态场景下基于全卷积神经网络的视觉slam方法中上采样操作的示意图;
[0023]
图4为本发明实施例提供的动态场景下基于全卷积神经网络的视觉slam方法中双线性插值的示意图;
[0024]
图5为本发明实施例提供的动态场景下基于全卷积神经网络的视觉slam方法中对fcn
‑
vgg16网络进行优化的示意图。
具体实施方式
[0025]
以下结合附图对本发明实施例的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施例,并不用于限制本发明实施例。
[0026]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0027]
在本发明中,在未作相反说明的情况下,使用的方位词如“上、下、顶、底”通常是针对附图所示的方向而言的或者是针对竖直、垂直或重力方向上而言的各部件相互位置关系描述用词。
[0028]
下面将参考附图并结合实施例来详细说明本发明。
[0029]
请参考图1,本发明实施例提供一种动态场景下基于全卷积神经网络的视觉slam方法,该方法包括以下步骤:s101:获取图像数据集;s102:根据所述图像数据集构建全卷积神经网络模型;s103:利用所述全卷积神经网络模型对摄像机当前采集的单目实时图像进行语义分割,得到语义标签图像;s104:根据所述语义标签图像剔除所述单目实时图像的动态特征点,得到所述单目实时图像的静态特征点;s105:根据所述静态特征点估计所述摄像机的位姿。
[0030]
具体地,本发明实施方式中,以orb_slam2开源视觉slam系统为框架,对卷积神经网络进行改进,构建全卷积神经网络,通过图像数据集对所构建的全卷积神经网络进行模型训练,输出训练完的全卷积神经网络模型。利用全卷积神经网络模型识别摄像机当前采集的单目实时图像中的动态目标,并对摄像机当前采集的单目实时图像进行语义分割,得到语义标签图像,再根据语义标签图像剔除单目实时图像的动态特征点,得到所述单目实时图像的静态特征点,利用静态特征点估计摄像机的位姿。
[0031]
根据本发明提供的方法,能够准确识别动态目标并完成语义分割,有效的提高摄像机跟踪的准确性和鲁棒性,提高视觉slam在动态场景的定位与建图精度。
[0032]
进一步地,所述利用所述全卷积神经网络模型对摄像机当前采集的单目实时图像进行语义分割,得到语义标签图像,包括:利用所述全卷积神经网络模型中与vgg16网络的全连接层输入数据尺寸相同的卷积核将所述vgg16网络的全连接层转化为卷积层,得到fcn
‑
vgg16网络;对所述fcn
‑
vgg16网络进行优化;利用优化后的fcn
‑
vgg16网络对所述单目实时图像进行动态目标与背景的二分类操作,得到所述语义标签图像。
[0033]
具体地,本发明实施方式中,vgg16网络由13层卷积层、5层池化层和3层全连接层
[0045][0046]
请参考图5,以fcn
‑
vgg16网络为基础,先对conv16层进行双线性插值得到两倍上采样的结果,接着将该结果与pool4层特征融合得到fuse
‑
pool4层,最后对fuse
‑
pool4层进行16倍反卷积并输出,得到fcn
‑
16s
‑
vgg16网络。相同的,在fcn
‑
16s
‑
vgg16网络的基础上,对fuse
‑
pool4层进行双线性插值后与pool3层进行融合特征得到fuse
‑
pool3层,将fuse
‑
pool3层特征图结果进行8倍反卷积并输出,得到fcn
‑
8s
‑
vgg16网络,即优化后的fcn
‑
vgg16网络。
[0047]
进一步地,所述利用优化后的fcn
‑
vgg16网络对所述单目实时图像进行动态目标与背景的二分类操作,得到所述语义标签图像,包括:确定所述优化后的fcn
‑
vgg16网络的热图的类别个数;确定所述单目实时图像属于目标类别的预测概率;根据所述热图的类别个数和所述预测概率识别所述单目实时图像的动态目标;根据识别出的动态目标对所述单目实时图像进行语义分割,得到所述语义标签图像。
[0048]
具体地,本发明实施方式中,根据优化后的fcn
‑
vgg16网络热图的个数确定热图的类别个数,确定单目实时图像属于目标类别的预测概率,根据热图的类别个数和预测概率过以下方式识别单目实时图像的动态目标:
[0049][0050]
其中,m为热图的类别个数,c为单目实时图像的目标类别,y
ic
为虚拟参数,p
ic
为单目实时图像属于目标类别c的预测概率,l为损失值,然后根据损失值的大小识别单目实时图像的动态目标。根据识别出的动态目标对单目实时图像进行语义分割,得到语义标签图像。
[0051]
进一步地,所述根据语义分割结果剔除所述单目实时图像的动态特征点,得到所述单目实时图像的静态特征点,包括:以第一缩放因子对所述单目实时图像进行图像金字塔分层,得到多个第一缩放图像;以第二缩放因子对所述语义标签图像进行图像金字塔分层,得到多个第二缩放图像;依次剔除每一第一缩放图像中的动态特征点:对所述每一第一缩放图像进行orb特征提取,得到每一第一缩放图像的orb特征点;对所述每一第二缩放图像中的动态区域的像素点输出像坐标值形成集合u
i
,其中,i为第二缩放图像的层数,所述动态区域为所述动态目标所在的区域;将每一第一缩放图像的orb特征点的坐标值与对应的集合u
i
中的坐标值进行匹配;在每一第一缩放图像中剔除坐标值与所述集合u
i
中的坐标值匹配的orb特征点;将每一第一缩放图像中保留下的orb特征点形成静态特征点集合m;所述根据所述静态特征点估计所述摄像机的位姿,包括:根据所述静态特征点集合m估计所述摄像机的位姿。
[0052]
具体地,本发明实施方式中,通过全卷积神经网络得到了动态目标与背景两分类的语义标签图像,利用基于图像金字塔的坐标映射法处理动态区域的特征点剔除,利用二
分类的语义标签图像限制动态区域,其具体操作如下:
[0053]
以第一缩放因子对单目实时图像进行图像金字塔分层,得到多层第一缩放图像,以第二缩放因子对语义标签图像进行图像金字塔分层,得到多层第二缩放图像。进一步地,第一缩放因子与第二缩放因子相同。然后依次剔除每一第一缩放图像中的动态特征点:对第二缩放图像的动态区域的像素点输出像坐标值形成集合u
i
,对与第二缩放图像相同层数的第一缩放图像进行orb特征提取,得到orb特征点。遍历所有提取到的orb特征点,将orb特征点的坐标值与对应的集合u
i
中的坐标值进行匹配:对于任意orb特征点p,如果对应的集合u
i
中存在一点p
′
,
[0054]
p
x
=p
′
x
∪p
y
=p
′
y
[0055]
则认为orb特征点p为动态特征点,将其剔除。在完成单层动态特征点的剔除后,继续对下一层进行剔除。然后将每一第一缩放图像中保留下的orb特征点形成静态特征点集合m,根据静态特征点集合m估计摄像机的位姿。
[0056]
进一步地,将所述orb特征点的坐标值与所述集合u
i
中的坐标值进行匹配之前,还包括:存储所述orb特征点。
[0057]
具体地,本发明实施方式中,由于提取orb特征点时存在四叉树机制,坐标匹配需要在orb特征点储存完毕转换为单层图像坐标值后进行,否则会由于剔除了动态特征点,而导致静态特征点丢失。
[0058]
本发明另一方面提供一种动态场景下基于全卷积神经网络的视觉slam系统,所述系统被配置为采用上文所述的动态场景下基于全卷积神经网络的视觉slam方法来估计摄像机的位姿。下文以orb_slam2
‑
fcn系统表示。
[0059]
通过本发明提供的方法和系统,能够准确识别动态目标并完成语义分割,有效的提高摄像机跟踪的准确性和鲁棒性,提高视觉slam在动态场景中的定位与建图精度。
[0060]
以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
[0061]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
[0062]
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1