一种基于知识图谱偏好传播的协同推荐模型构建方法
本发明涉及知识图谱、机器学习、个性化推荐等领域,具体给出了一种基于知识图谱偏好传播的协同推荐模型构建方法。
背景技术:
互联网技术的快速发展为人们的工作和生活带来很多便利,但同时也带来了信息过载的问题。推荐技术能够为用户提供个性化服务,通过联系用户和物品,解决信息过载的问题。
传统推荐技术主要分为基于内容的推荐技术、基于协同过滤的推荐技术和混合推荐技术。基于内容的推荐技术利用历史行为内容,通过分析已购买、已评价过的物品的离散特征为用户推荐类似的对象。协同过滤推荐技术则根据相似用户的相似决策建立模型,但过于稀疏的矩阵建模会极大的增加算法的过拟合风险,同时对于新加入的用户或物品系统因为没有历史交互信息,也无法进行建模和推荐。矩阵分解算法、因子分解机模型、循环神经网络模型等混合推荐技术在解决数据稀疏问题方面有了比较理想的改进,但往往可解释性不好。本发明尝试将先验知识作为辅助信息引入推荐系统,利用知识图谱辅助推荐,在解决数据稀疏和冷启动问题的同时增加推荐结果的可解释性。
知识图谱(knowledgegraph,kg)是google在2012年提出的,它本质是一种语义网络,以结构化三元组的形式存储现实世界中的实体和关系,能够融合语义、上下文和异构特征信息,天然具有可解释性。基于知识图谱进行推荐能够充分利用用户和物品更丰富的先验信息,从而有效的提高推荐的准确性,利用知识图谱的多维度远距离关联可解决推荐结果不可解释的问题。
知识图谱辅助推荐的方法大致可归纳为三类:基于知识表示的方法,基于路径的方法,混合的方法。基于知识表示的方法是先将知识图谱的节点和关系通过kge(knowledgegraphembedding)的方式映射到低维的向量空间,得到向量表示,然后再融合到推荐模型中。zhangf等人提出的cke(acmsigkddconferenceonknowledgediscoveryanddatamining,2016)模型将知识图谱的结构信息、文本信息和图片信息融合到贝叶斯框架中来获得物品的语义表示,采用transr来得到实体的向量特征,然后再融合到协同过滤模型中进行推荐。wang等人提出的新闻推荐模型dkn(thewebconference,2018)将新闻标题的词向量、实体向量(通过知识图谱表示算法学习得到)和实体上下文向量作为多个通道(类似于图像中的红绿蓝三通道),然后通过卷积神经网络进行融合,以获得新闻标题的最终表示,从而进行新闻推荐。
基于路径的方法通常利用用户或者物品的连接相似性来增强推荐,通过预先定义元路径或者自动挖掘连接模式来发现项的路径级相似性,通常可解释性较好。per(acminternationalconferenceonwebsearchanddatamining,2014)以及基于元图(meta-graph)的推荐模型meta-graphbasedrecommendationfusionoverheterogeneousinformationnetworks(acmsigkddinternationalconferenceonknowledgediscoveryanddatamining,2017)将知识图谱视作异质信息网络,通过提取基于元路径或者元图的潜在特征的方式来表示不同种类关系路线或者关系图连接模式下的用户-物品之间的连接关系。知识感知路径递归网络kprn(aaaitechnicaltrack:machinelearning,2019)模型通过组合实体和关系的语义来生成路径表示,通过利用路径中的顺序依赖关系,推断用户项交互的基本原理。此外,提出了一个端对端的神经网络模型来学习路径的语义表示,并将其融入商品推荐中。
而混合的方法结合了以上两种方法的优势,基于嵌入传播的思想,以连接结构为指导,对实体表示进行细化。基于注意力知识图谱嵌入的推荐系统akge(arxiv,2019)可以同时关注知识图谱对应的语义信息和拓扑信息,作为端到端训练的神经网络,首先提取包含语义信息的,连接item和user的高阶关系的子图,再利用注意力机制,基于子图学习用户偏好。类似地,wangh等人提出的kgcn(thewebconference,2019)将基于嵌入的方式和基于路径的方式结合,在计算kg中某一个给定的entity的表示时,利用图卷积神经网络将邻居信息与偏差一并结合进来。
基于知识表示的方法可以得到实体和关系在低维向量空间的向量表示,但是忽略了知识图谱中信息的联通模式,推荐结果缺乏可解释性。将基于知识表示的方法和基于路径的方法相结合,充分利用双方的优势是当前的研究趋势。
技术实现要素:
为了克服传统推荐算法数据稀疏和冷启动的问题,本发明将知识图谱引入推荐,提出一种基于知识图谱偏好传播的协同推荐模型构建方法,该模型的创新点是将知识图谱的偏好传播模型和基于物品的协同过滤模型融合。其中,偏好传播模型将基于知识表示和基于路径的方法结合,不仅利用了知识图谱的知识表示信息,而且利用了知识图谱的网络结构信息,在辅助推荐的同时,能有效提高推荐结果的可解释性。
为了解决上述技术问题本发明提供如下的技术方案:
一种基于知识图谱偏好传播的协同推荐模型构建方法,包括以下步骤:
1)构建领域知识图谱,过程如下:
(1.1)知识建模:利用本体建模工具利用本体建模工具protégé进行知识建模,给出业务知识表示框架,获得一个用owl表示的知识表示文件,包括实体定义、关系定义、属性定义;
(1.2)数据采集和预处理:源数据按照数据的结构化程度来分,可以分为结构化数据、半结构化数据和非结构化数据,根据数据的不同结构化形式,采用不同的方式,初步将数据转换为三元组形式;
(1.3)知识图谱构建:通过实体对齐技术,具体包括实体消歧和共指消解技术,将(1.2)得到的三元组数据和知识模式进行融合,得到最终的知识图谱g={(h,r,t)|h∈e,r∈r,t∈e},e是实体的集合,r表示关系的集合;
2)获取用户偏好的向量表示,过程如下:(2.1)将实体和关系映射到低维向量空间:使用transe模型将提前构建好的知识图谱中的实体和关系映射到低维向量空间,同时保持知识图谱中原有的结构和语义信息,知识图谱中的实体不但包含要推荐的项目items,还包含用于辅助推荐的其他实体non-items,transe是将三元组中的关系看作是从头实体向量到尾实体向量的翻译,假设h+r≈t,式中,h是头实体的向量表示,r是关系的向量表示,t是尾实体的向量表示;具体地,损失函数为:
式中,s表示知识图谱中正样本的集合,s′(h,r,t)表示(h,r,t)的负样本,在训练过程中三元组(h,r,t)通过随机替换头实体h和尾实体t得到;[x]+表示max(0,x),γ表示表示损失函数中的间隔,是一个需要设置的大于零的超参;transe的训练目标是最小化损失函数l,通过梯度下降的算法优化求解,直至训练收敛,得到实体和关系的向量表示;
(2.2)遍历用户的历史偏好:对于给定的用户u,构建用户的历史操作物品种子集合seeds,具体地,根据用户-物品交互矩阵在构建地专业知识图谱上搜索用户历史操作过的物品item,以用户u的历史点击的item作为种子集合seeds,表示用户u的已有偏好;
(2.3)获取用户的多层偏好表示:以用户u的种子实体节点为起始点,沿着出度方向,取第一跳节点hop1构建用户u的第一次偏好传播的rippleset
对于集合中的每一个(h,r,t),用(h*r)与itemv相乘得到itemv与
计算itemv与第一层rippleset上的(h,r)的归一化相似度pi,根据相似度对rippleset的(t)进行加权求和,得到的结果
重复第一层的过程,将第一层的rippleset的尾节点tail作为第二层的头节点head,先取出第二层的rippleset,然后用用第二层的rippleset跟item的相似度及加权表示作为输出
(2.4)根据用户的多层偏好表示得到用户偏好的向量表示
把三次的偏好表示输出的o累加作为最终的用户向量表示u:
这里只计算三层偏好集,为了避免弱关系干扰推荐结果,因为实体间隔跳数越大,相关性越弱;
3)将用户偏好与基于物品的协同推荐模型融合,过程如下:(3.1)学习物品的向量表示:获取用户-物品交互数据集,并构建用户-物品倒排表,采用item2vec算法通过物品items间的共现关系,学习物品item的隐向量表示;
(3.2)用户和物品的匹配计算:最后,基于(2.4)得到的目标用户的用户偏好向量表示矩阵以及(3.1)得到的物品的向量表示,模型采用计算向量点积的方式来预测用户对物品的点击概率,公式表示为:
式中,u是用户的偏好矩阵,v是物品的向量表示矩阵,σ是sigmod函数;
4)获得推荐列表,过程如下:
根据点击概率将一部分物品召回,只将用户感兴趣的物品召回用于排序;将召回结果跟用户交互列表对比,排除用户操作过的物品后做降序排序,将结果打散后推荐给用户。
进一步,所述(3.1)的过程如下:
a)将用户的行为序列item_set视为一个集合,item_set={w1,w2,…,wk},k是集合的个数;
b)基于极大似然,定义模型的目标函数是最大化item_set中两两之间的条件概率,公式如下:
式中,u是target,v是context,目的是最大化和u有关联的v,最小化和u没有关联的v,σ是sigmod函数;
c)采用负采样优化算法性能,当词库数量在10万-100万的量级下,计算p(wj|wi)的代价非常大,这里采用负采样的做法来优化,取item间的共现为正样本,target设为1,随机抽取没有交互的物品item作为负样本,target设为0;
d)为提高算法的置信度,按概率丢弃一些热门物品,对物品w,出现的频率越高,丢弃的概率越大,丢弃概率公式如下:
式中,ρ是一个先验参数,取为10-5,f(w)是w在语料中出现的频率;
e)最后,利用sgd优化方法训练得到的参数矩阵就是物品的向量表示。
本发明的有益效果是:本发明将先验知识引入推荐,创造性地将偏好传播模型与基于物品的协同过滤模型融合,在利用好知识图谱知识信息的同时,更充分利用了知识图谱路径结构信息,从用户历史点击数据出发,自动挖掘用户的潜在偏好,提高了推荐结果的可解释性和多样性。
附图说明
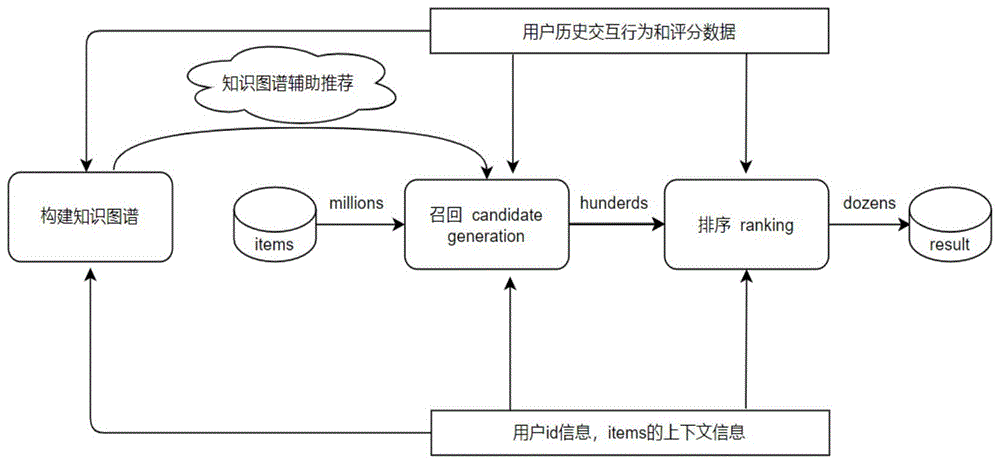
图1是本发明的推荐模型架构图。
图2是部分知识图谱示例图。
图3是召回阶段框架图。
图4是偏好传播模型的水波集树状图。
图5是用户-物品倒排表。
具体实施方式
下面结合movielens-1m数据集以及本发明中提供的附图,对本发明的技术方案进行清楚、完整地描述。
本发明提出的模型结构如图1所示,召回模块如图3所示,具体地,参照图2、图4和图5,一种知识图谱辅助的协同推荐模型构建方法,包括以下步骤:
1)构建领域知识图谱,过程如下:
(1.1)知识建模:利用本体建模工具protégé进行知识建模,给出业务知识表示框架,获得一个用owl表示的知识表示文件,包括实体定义、关系定义、属性定义。具体地创建了movie(电影)、person(演员)、director(导演)、language(语言)、genre(类型)、country(国家)六个节点标签,title(电影标题)、writer(电影编剧)、rating(电影评分)、duration(上映时间)、playtime(电影片长)五个实体属性和主演、导演、类型、语言、国家五个实体间的关系;
(1.2)数据采集和预处理:原始的数据,按照数据的结构化程度来分,可以分为结构化数据、半结构化数据和非结构化数据,根据数据的不同结构化形式,采用不同的方式,初步将数据转换为三元组形式;结构化数据一般就是企业现有的业务数据;半结构化数据如网页数据,可采用爬虫技术+包装器+正则表达式技术进行数据抽取;非结构化数据可能是一段文字或者是一张图片,这些数据的抽取可以通过命名实体识别的技术,本发明通过爬虫技术爬取了豆瓣电影网站的json数据用于构建知识图谱,通过正则表达式预处理数据后转换为三元组数据保存为csv文件;
(1.3)知识图谱构建:通过实体对齐技术,具体包括实体消歧和共指消解技术,将(1.2)得到的三元组数据和知识模式进行融合,得到最终的知识图谱g={(h,r,t)|h∈e,r∈r,t∈e},e是实体的集合,r表示关系的集合,具体地,本发明采用官方指定的neo4j-aminimport方式来导入csv,保存在图数据库neo4j中,如图2所示的部分电影图谱的示例图,图谱中的实体既包含用于推荐的物品items,也包含其它的实体节点non-items;
2)获取用户偏好的向量表示,过程如下:
用户偏好建模,如图4所示,把用户的历史操作items作为种子节点集合seeds,用户的偏好沿种子节点向外扩散,每一层的rippleset都代表了用户潜在的层级兴趣,实现步骤如下:(2.1)将实体和关系映射到低维向量空间:使用transe模型将提前构建好的电影知识图谱中的实体和关系映射到低维向量空间,同时保持知识图谱中原有的结构和语义信息;transe是将三元组中的关系看作是从头实体向量到尾实体向量的翻译;transe的训练目标是最小化损失函数,通过梯度下降的算法优化求解,直至训练收敛,得到实体和关系的向量表示;
(2.2)遍历用户的历史偏好:根据用户-物品交互矩阵(使用的是movielens-1m数据集的评分数据)在电影知识图谱上遍历搜索用户历史操作过的物品items,以用户u的历史点击的物品items作为种子seeds集合,表示用户u的已有偏好,其中seeds中的item为训练数据的正例,随机挑选没有交互的item作为负例;
(2.3)获取用户的多层偏好表示:以用户u的种子实体节点为起始点,沿着出度方向,取第一跳节点hop1构建用户u的第一次偏好传播的rippleset
重复第一层的过程,将第一层的rippleset的尾节点tail作为第二层的头节点head,先取出第二层的rippleset,然后用用第二层的rippleset跟item的相似度及加权表示作为输出
(2.4)根据用户的多层偏好表示得到用户偏好的向量表示:把三次的偏好表示输出的o累加作为最终的用户向量表示:
3)将用户偏好与基于物品的协同推荐模型融合,过程如下:(3.1)学习物品的向量表示:获取用户-物品交互数据集,并构建用户-物品倒排表,如图5所示,本文使用movielens-1m数据集作为模型的训练及测试数据;该数据集共包含了来自6,040个用户对3,900个物品的1,000,209个评分;每个评分都是1到5之间的一个正整数,因为是评分数据,而我们的问题是点击预测问题,所以将评分数据转化为0-1数据,采用的方法是,评分数据属于[1,3]时,值为0;评分数据属于[4,5]时,值为1;这里的用户-物品交互矩阵,是由用户-物品评分矩阵替代的;然后采用item2vec算法通过物品items间的共现关系,学习物品item的隐向量表示;如图3的左侧部分,过程实现如下:
a)将用户的行为序列视为一个集合,用户的行为序列itemset={w1,w2,…,wk};
b)因为每个物品都决定了相邻物品,基于极大似然,模型的优化是最大化itemset中两两之间的条件概率,item2vec算法基于word2vec的skip-gram模型;
c)采用负采样优化算法性能,取item间的共现为正样本,target设为1,随机抽取没有交互的物品item作为负样本,target设为0;对每个正样本,根据3/4指数分布采样n个负样本,这个采样比例是在实验中效果较为显著的;
d)为提高算法的置信度,按概率丢弃一些热门物品,对物品w,出现的频率越高,丢弃的概率越大;
e)最后,利用sgd优化方法训练得到的参数矩阵就是物品itemv的向量表示;
(3.2)用户和物品的匹配计算:基于(2.4)得到的目标用户的用户偏好向量表示矩阵以及(3.1)得到的物品的向量表示,模型采用计算向量点积的方式来预测用户对物品的点击概率;
4)生成推荐列表,过程如下:
根据点击概率将一部分物品召回,只将用户感兴趣的物品召回用于排序,将召回结果跟用户交互列表对比,排除用户操作过的物品后做降序排序,取排序前20个结果,最终将结果打散后推荐给用户。
本说明书的实施例所述的内容仅仅是对发明构思的实现形式的列举,仅作说明用途。本发明的保护范围不应当被视为仅限于本实施例所陈述的具体形式,本发明的保护范围也及于本领域的普通技术人员根据本发明构思所能想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!