智慧场景分割技术
本发明涉及机器学习领域,具体涉及是一种基于深度神经网络的智慧场景分割技术及其处理方法。
背景技术:
机器学习是一门专注于研究计算机怎么样模拟或实现人类的学习能力,以获得新的知识或技能,重新组织已有的知识结构使其不断改善自身性能的学科。深度神经网络属于机器学习的一个分支,起初为了模仿人类的大脑结构所提出的方法,由于深度神经网络的强大特征表示能力,使其在许多高级计算机视觉任务中快速发展,例如图像分类、目标检测和语义分割。
智慧场景分割技术的核心是语义分割技术,能够依靠所给的大量数据训练出一个语义分割模型,该模型能够自动分割所给场景材料并且不需要人类的干预。在早期的语义分割方法中,不仅处理时间长,而且处理的效果也不好。在基于深度神经网络的语义分割方法出现之后,不仅分割场景的效果好、时间短,而且能够真正应用到现实生活当中。
智慧场景分割技术是一种耗时短、实时性、易嵌入、高效率的语义分割技术,且场景分割装置简单、操作简单、制造简单,易于与其它的高级计算机视觉任务相结合,因此能应用在很多领域,如汽车的无人驾驶系统、室内的场景分割、医疗影像系统和地理信息系统。
技术实现要素:
本发明目的在于提供一种智慧场景分割技术及其处理方法,使用effnet语义分割模型代替传统的语义分割方法,能够保证场景分割的实时性和高效率。
本发明的目的可以通过以下技术方案实现:
一种智慧场景分割技术,其特征在于:所述智慧场景分割技术由提取场景模块和场景分割设备组合而成;所述提取场景模块为高清海康威视c6记录仪。
进一步的,所述场景分割设备由effnet语义分割模型和小型超级算力设备组成;所述的小型超级算力设备由英特尔corei9-9900k@3.60ghz八核处理器、技嘉c246-wu4-cf(c246芯片组)主板、威刚ddr42666mhz(32gb)内存、智能高清显示器和nvidiageforcertx3080显卡组成。
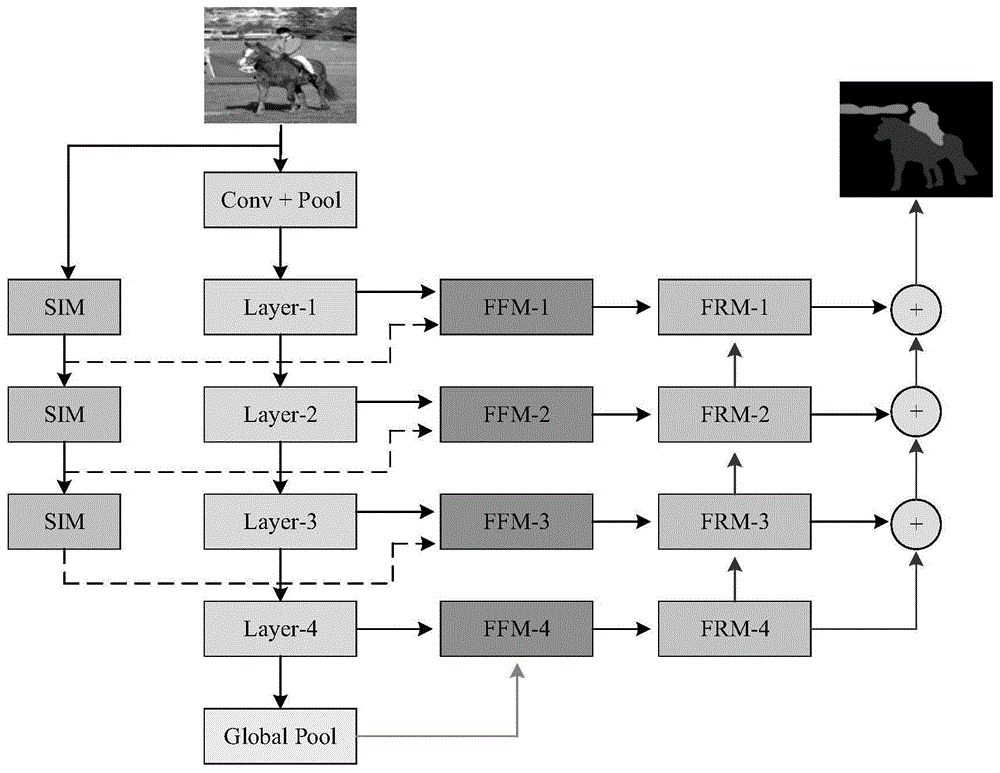
进一步的,所述effnet语义分割模型由resnet编码器网络、特征重用模块、特征融合模块、全局池化模块和空间信息模块组成;所述resnet编码器网络为resnet50。
进一步的,所述特征重用模块由两个输入变量、一个特征图拼接操作、一个1×1卷积层、两个3×3卷积层、两个激活函数和一个逐元素相加操作组成,在上采样阶段为模型补充高层语义信息。
进一步的,所述特征融合模块由两个输入变量、二个1×1卷积层、一个特征图拼接操作、一个3×3卷积层组成、一个注意力机制模块、三个激活函数和一个逐元素相加操作组成,能够高效融合不同阶段的高层语义信息和空间信息;所述注意力机制模块由一个输入变量、一个全局池化层、两个全连接层、两个激化函数、一个尺度缩放操作和一个逐元素相乘操作组成,能使特征融合模块学习到带有区分力的特征图。
进一步的,所述全局池化模块由一个输入变量、一个自适应全局池化层、一个1×1卷积层和一个尺度缩放操作组成,为模型补充全局信息。
进一步的,所述空间信息模块由一个输入变量、一个3×3卷积层、一个平均池化层、一个激化函数和一个特征图拼接操作组成,在上采样阶段为模型补充语义类别信息。
一种智慧场景分割技术的处理方法,包括如下步骤:
1)提取场景模块实时录取所需场景分割的视频;
2)视频传送到场景分割设备中,通过处理器将视频分解成多张图像;
3)effnet语义分割模型实时处理多张图像,得到多张语义图像;
4)处理器将多张语义图像压缩并恢复视频格式,再传输到智能高清显示器;
5)智能高清显示器动态显示场景分割。
进一步的,所述effnet语义分割模型在语义分割数据集上训练模型参数,之后将训练所得到的参数载入到模型中。
本发明的有益效果:
1、本发明提供的一种智慧场景分割技术,采用effnet语义分割模型作为核心技术,解决了传统语义分割方法实时性、效率低的问题,effnet语义分割模型嵌入到智慧场景分割当中,能够快速稳定地分割所给场景的语义分割图,避免效率低、实时性差、性能不稳定的问题。
2、本发明基于effnet语义分割模型的智慧场景分割技术的制备工艺简单、易于操作、也可进行大规模生产;制备出的设备容易嵌入在多种高级计算机视觉任务当中,相比较传统的场景分割方法,本发明的可移植性更加好,同时能够降低保存和运输的成本。
附图说明
下面结合附图对本发明作进一步的说明:
图1是本发明实例1的智慧场景分割技术的处理流程图;
图2是本发明实例1的effnet语义分割模型的网络架构图;
图3是本发明实例1的effnet语义分割模型中的特征融合模块图;
图4是本发明实例1的effnet语义分割模型中的注意力机制模块图;
图5是本发明实例1的effnet语义分割模型中的特征融合模块图;
图6是本发明实例1的effnet语义分割模型中的空间信息模块图;
图7是本发明实例1的effnet语义分割模型中网络参数配置图;
图8是本发明实例1的智慧场景分割技术的效果图;
图9是本发明实例2的智慧场景分割技术的效果图;
图10是本发明实例4的智慧场景分割技术的效果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例1:
一种智慧场景分割技术的处理方法,操作步骤如下:
(1)、高清海康威视c6记录仪实时录取汽车道路场景的视频片段,通过数据线传输到场景分割设备当中;
(2)、场景设备中的英特尔corei9-9900k@3.60ghz八核处理器将视频处理成一帧一帧的图像,通过接口将处理过后的图像传输到effnet语义分割模型中;
(3)、effnet语义分割模型接收处理过后的汽车道路场景图像,图像经过多种处理转变成向量形式,之后进入模型中提取特征,经过一系列的图像下采样、卷积、池化、逐元素相乘、逐元素相加、上采样等操作,得到一张张具有多种分类的语义分割图,分类数依据所训练的道路场景分割数据集而变化,此时的多张图像均已标注出不同的种类,比如有人、自行车、小汽车、公交车、汽车行驶车道、红绿灯、斑马线、树木、建筑、栏杆等其它类别;
(4)处理器实时处理将语义分割图,先恢复图像格式再对图像组合成视频格式,之后压缩视频,以减少内存的消耗;
(5)智能高清显示器实时显示汽车道路场景的语义分割视频,在汽车行驶,显示器一直显示effnet语义分割模型处理后视频,在视频中,人、小汽车、人行道、公交车、自行车等都有了不同颜色的标记。
测试结果:在晴天、通信良好的环境下,测试该智慧场景分割技术的处理准确度为73.13%,每秒处理帧数为25。
实施例2:
一种智慧场景分割技术的处理方法,操作步骤如下:
(1)、高清海康威视c6记录仪实时录取室外场景的视频片段,通过数据线传输到场景分割设备当中;
(2)、场景设备中的英特尔corei9-9900k@3.60ghz八核处理器将视频处理成一帧一帧的图像,通过接口将处理过后的图像传输到effnet语义分割模型中;
(3)、effnet语义分割模型接收处理过后的室外场景图像,图像经过多种处理转变成向量形式,之后进入模型中提取特征,经过一系列的图像下采样、卷积、池化、逐元素相乘、逐元素相加、上采样等操作,得到一张张具有多种分类的语义分割图,分类数依据所训练的室外场景分割数据集而变化,此时的多张图像均已标注出不同的种类,比如有人、自行车、小汽车、公交车、鸟类、马、羊、熊、猫、狗、树木、建筑物等其它类别;
(4)处理器实时处理将语义分割图,先恢复图像格式再对图像组合成视频格式,之后压缩视频,以减少内存的消耗;
(5)智能高清显示器实时显示室外场景的语义分割视频,在整个过程中,显示器一直显示effnet语义分割模型处理后视频,在视频中,人、自行车、小汽车、公交车、鸟类、马、羊、熊、猫、狗、树木、建筑物等都有了不同颜色的标记。
测试结果:在晴天、通信良好的环境下,测试该智慧场景分割技术的处理准确度为75.22%,每秒处理帧数为31。
实施例3:
一种智慧场景分割技术的处理方法,操作步骤如下:
(1)、高清海康威视c6记录仪实时录取室内场景的视频片段,通过数据线传输到场景分割设备当中;
(2)、场景设备中的英特尔corei9-9900k@3.60ghz八核处理器将视频处理成一帧一帧的图像,通过接口将处理过后的图像传输到effnet语义分割模型中;
(3)、effnet语义分割模型接收处理过后的室内场景图像,图像经过多种处理转变成向量形式,之后进入模型中提取特征,经过一系列的图像下采样、卷积、池化、逐元素相乘、逐元素相加、上采样等操作,得到一张张具有多种分类的语义分割图,分类数依据所训练的室内场景分割数据集而变化,此时的多张图像均已标注出不同的种类,比如有桌子、床、枕头、柜子、沙发、电脑等其它类别;
(4)处理器实时处理将语义分割图,先恢复图像格式再对图像组合成视频格式,之后压缩视频,以减少内存的消耗;
(5)智能高清显示器实时显示室内场景的语义分割视频,在整个过程中,显示器一直显示effnet语义分割模型处理后视频,在视频中,桌子、床、枕头、柜子、沙发、电脑等都有了不同颜色的标记。
测试结果:在光照良好的环境下,测试该智慧场景分割技术的处理准确度为65.46%,每秒处理帧数为18。
实施例4:
一种智慧场景分割技术的处理方法,操作步骤如下:
(1)、高清记录仪实时录取动物场景的视频片段,通过数据线传输到场景分割设备当中;
(2)、场景设备中的处理器将视频处理成一帧一帧的图像,通过接口将处理过后的图像传输到effnet语义分割模型中;
(3)、effnet语义分割模型接收处理过后的动物场景图像,图像经过多种处理转变成向量形式,之后进入模型中提取特征,经过一系列的图像下采样、卷积、池化、逐元素相乘、逐元素相加、上采样等操作,得到一张张具有多种分类的语义分割图,分类数依据所训练的动物场景分割数据集而变化,此时的多张图像均已标注出不同的种类,比如有猫、狗、羊、马等其它类别;
(4)处理器实时处理将语义分割图,先恢复图像格式再对图像组合成视频格式,之后压缩视频,以减少内存的消耗;
(5)高清显示器实时显示动物场景的语义分割视频,在整个过程中,显示器一直显示effnet语义分割模型处理后视频,在视频中,猫、狗、羊、马等都有了不同颜色的标记。
测试结果:在晴天的环境下,测试该智慧场景分割技术的处理准确度为86.5%,每秒处理帧数为32。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神和基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!