基于深度强化学习的多用户边缘计算优化调度方法
本发明涉及无线通信技术领域,尤其涉及一种基于深度强化学习的多用户边缘计算优化调度方法。
背景技术:
随着物联网的快速发展和智能终端的广泛普及,新型网络服务和应用不断涌现,用户对于网络服务质量、网络请求时延的要求越来越高,网络带宽和时延逐渐成为云计算的瓶颈,云计算模型已无法解决现有问题,移动边缘计算(mobileedgecomputing,mec)技术应运而生。尽管mec服务器具有强大的计算能力,然而其资源受限,当多个任务到达mec服务器时,会造成拥塞现象,产生不必要的延迟。因此对任务进行合理的调度,是很有必要的。
技术实现要素:
本发明针对上述背景技术中存在的问题,以任务计算延迟最小化为目标,同时考虑了任务合理的执行顺序,提出了一种于深度强化学习的多用户边缘计算优化调度方法。
基于深度强化学习的多用户边缘计算优化调度方法,适用于多用户多边缘服务器的边缘计算系统,基于最小化总延迟原则,并根据深度强化学习策略,设计了最优的任务执行顺序,其具体步骤如下:
步骤一,对于拥有多个用户和多个边缘服务器的边缘计算系统,通过用户的边缘服务器选择策略和用户的卸载策略,计算出用户任务的本地计算延迟和边缘计算延迟;
步骤二,根据本地计算延迟和边缘计算延迟建立计算任务卸载目标函数,将目标函数划分为两个子问题:任务调度;卸载决策和边缘服务器选择;
步骤三,利用任务调度算法获得任务调度的最优解,利用深度强化学习方法获得卸载决策和边缘服务器选择的最优解,结合两个子问题的最优解形成最优的多用户边缘计算调度方案。
进一步地,步骤一中,系统中共有m个移动用户,n个边缘服务器mec,n个mec服务器为m个用户提供计算服务;用n表示mec服务器的索引,m表示用户的索引;每个用户选择一个服务器进行任务卸载;用矩阵αm,t=[αm,1,t,αm,2,t,…,αm,n,t,…,αm,n,t]表示t时隙用户m的mec选择策略,其中αm,n,t=1表示t时隙用户m选择mec服务器n进行计算任务卸载,αm,n,t=0表示t时隙用户m未选择mec服务器n,
进一步地,步骤一中,用
其中,参数λm,t表示t时隙用户m的任务数据量;fm表示本地设备的处理能力,单位为cpu周期数/秒;ρ表示处理1bit数据所需的cpu周期数。
进一步地,步骤一中,用
用rm,n表示用户m向接收者mecn卸载任务的数据速率,按下式计算:
其中,参数bm表示分配给用户m的信道带宽,pm表示用户m的发射功率,hm,n表示用户m与mecn之间的信道增益,
用
若多个任务同时到达某一mec服务器,比如mec服务器n,会产生排队延迟,用mn,t表示t时隙将任务卸载到mec服务器n的用户集合,即mn,t={m|(1-βm,t)αm,n,t=1};用nn,t表示t时隙卸载到mec服务器n的任务总数,nn,t=∑m(1-βm,t)αm,n,t;用矩阵i(n,t)表示t时隙卸载到mec服务器n的任务的处理顺序,i(n,t)是一个nn,t×nn,t阶的矩阵,其中i(n,t)的元素
其中,m′是其他用户的索引;
其中ε表示时隙的长度;
用
其中fe表示边缘服务器的计算能力,单位为cpu周期数/秒;
基于上述得到的传输延迟、排队延迟、计算延迟,用户m在t时隙任务卸载到mecn的边缘计算延迟
进一步地,步骤二中,所述目标函数为本地计算延迟和边缘计算延迟的加权和,计算为:
因此,总的优化问题为:
优化变量包括三个:卸载决策,即β;边缘服务器选择,即α;任务调度,即
将上述优化问题划分为两个子问题:i)任务调度,ii)卸载决策和边缘服务器选择。
进一步地,步骤二中,任务调度子问题针对卸载至mec服务器的任务执行顺序进行排序,以最小化计算延迟为目标,建立边缘服务器中多个计算任务的调度优化问题:
进一步地,步骤二中,在已知任务调度子问题的最优解
上述优化问题映射为深度强化学习问题:令网络状态
经过上述映射,卸载决策和边缘服务器选择子问题等效为如下优化问题:
进一步地,在步骤三中,利用任务调度算法求解任务调度优化子问题,即按照计算时间由小到大顺序调度任务,具体步骤为:
步骤301,对于时隙t,统计选择卸载到边缘服务器的用户集合,即初始化集合m={m|λm,t≠0}以及每个边缘服务器的
步骤302,对集合m中的每个用户,当网络与环境交互时,网络首先依据公式(13)获得一个动作at,根据at得出其选择的边缘服务器n(m)={n|αm,n,t=1},根据公式(7)计算各个用户的边缘计算处理时延,遍历循环结束后,执行步骤303;
步骤303,找出边缘计算延迟最小的用户m*,m*是用户索引,用
进一步地,步骤三中,采用ddpg深度强化学习算法求解卸载决策和边缘服务器选择子问题,该算法涉及两个网络:评估网络和目标网络,其中每个网络又包括价值网络、动作网络;基于ddpg算法求解具体步骤为:
步骤3a,初始化深度强化学习算法评估网络中价值网络权重θq、动作网络权重θμ,并将其权重复制到目标网络中θq′=θq,θμ′=θμ,θq′是目标网络中价值网络的权重,θμ′是目标网络中动作网络的权重。初始化一个随机向量
步骤3b,获得时隙t所有用户的状态
得到动作at,at=[βt,αt];μ(st|θμ)表示评估网络在状态st下采取的动作,
步骤3c,从经验池r中随机取出m个样本(si,ai,ri,si+1)进行训练;评估网络中价值网络损失函数l,计算为:
评估网络中动作网络的损失函数
其中q(si,ai|θq)为评估网络中价值网络的输出,yi为目标网络中价值网络的输出,μ(si|θμ)表示评估网络在状态si下采取的动作;根据l更新评估网络中价值网络权重θq,根据
θq′=τθq+(1-τ),θμ′=τθμ+(1-τ)θμ′(16)
τ为学习效率,更新目标网络的权重。
步骤3d,重复步骤3b,且t=t+1,直至t=t;迭代结束后评估网络中动作网络权重θμ为最优,此时动作网络输出最优动作a*,即可获得最优卸载决策β*和最优边缘服务器选择策略α*。
进一步地,结合两个子问题的解,获得最优调度方案为
本发明采用以上技术方案与现有技术相比,具有以下有益效果:
(1)本方法考虑了多边缘服务器的选择问题,基于深度强化学习方法,在动态环境中能快速、准确给出每个用户任务边缘卸载时,最佳的接收服务器。
(2)本方法基于卸载决策和服务器选择策略,给出了最佳的任务执行顺序。本方法能适应大量任务的卸载,相比于传统的方法,具有更高的实用价值。
附图说明
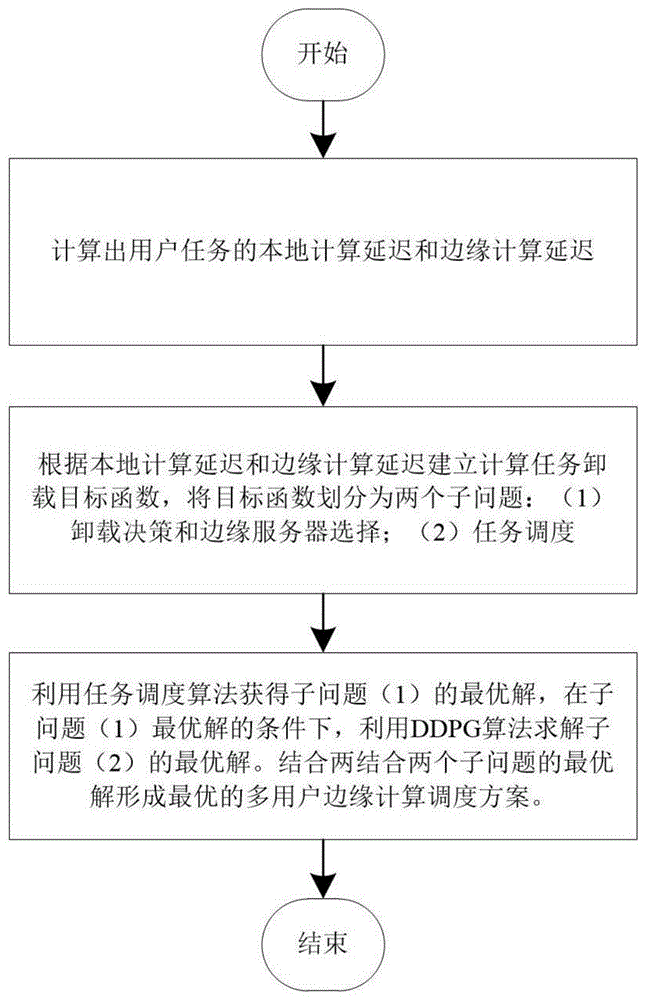
图1为本发明实施例中所述的基于深度强化学习的多用户边缘计算优化调度方法的流程图。
图2为本发明实施例中子问题(1)的求解算法流程图。
图3为本发明实施例中深度强化学习算法的网络结构图。
图4为本发明实施例中子问题(2)的求解算法流程图。
具体实施方式
下面结合说明书附图对本发明的技术方案做进一步的详细说明。
如图1所示,基于深度强化学习的多用户边缘计算优化调度方法流程图,该方法包括以下步骤:
步骤一中,系统中共有m个移动用户,n个边缘服务器mec,n个mec服务器为m个用户提供计算服务;用n表示mec服务器的索引,m表示用户的索引;每个用户选择一个服务器进行任务卸载;用向量αm,t=[αm,1,t,αm,2,t,…,αm,n,t,…,αm,n,t]表示t时隙用户m的mec选择策略,其中αm,n,t=1表示t时隙用户m选择mec服务器n进行计算任务卸载,αm,n,t=0表示t时隙用户m未选择mec服务器n,
用
其中,参数λm,t表示t时隙用户m的任务数据量;fm表示本地设备的处理能力,单位为cpu周期数/秒;ρ表示处理1bit数据所需的cpu周期数。
用
其中,参数bm表示分配给用户m的信道带宽,pm表示用户m的发射功率,hm,n表示用户m与mecn之间的信道增益,
用
若多个任务同时到达某一mec服务器,比如mecn,会产生排队延迟,用mn,t表示t时隙将任务卸载到mecn的用户集合,即mn,t={m|(1-βm,t)αm,n,t=1};用nn,t表示t时隙卸载到mecn的任务总数,nn,t=∑m(1-βm,t)αm,n,t;用矩阵i(n,t)表示t时隙卸载到mecn的任务的处理顺序,i(n,t)是一个nn,t×nn,t阶的矩阵,其中i(n,t)的元素
其中,m′是其他用户的索引;
其中ε表示时隙的长度。
用
其中fe表示边缘服务器的计算能力,单位为cpu周期数/秒。
给定传输延迟、排队延迟、计算延迟,用户m在t时隙任务卸载到mecn的边缘计算延迟
步骤二中,所述目标函数为本地计算延迟和边缘计算延迟的加权和,计算为
因此,总的优化问题为:
优化变量包括三个:卸载决策,即β;边缘服务器选择,即α;任务调度,即
将上述优化问题划分为两个子问题:(1)任务调度,(2)卸载决策和边缘服务器选择。
(1)任务调度子问题
任务调度子问题针对卸载至mec服务器的任务执行顺序进行排序。网络与环境交互时,网络会依据公式(13)给出动作即给定卸载决策和边缘服务器选择策略{α,β};当任务卸载至mec服务器时,β的取值为0,因此本地计算延迟为0,只需考虑优化边缘计算延迟。以最小化延迟为目标,建立边缘服务器中多个计算任务的调度优化问题:
(2)卸载决策和边缘服务器选择子问题
在已知子问题(1)的最优解
上述优化问题可以映射为深度强化学习问题:令网络状态
采用深度强化学习算法求解式(12)。
步骤三中,利用图2的任务调度算法求解任务调度优化子问题(1),即按照计算时间由小到大顺序调度任务,具体实施步骤为:
步骤301,对于时隙t,统计选择卸载到边缘服务器的用户集合,即初始化集合m={m1λm,t≠0)以及每个边缘服务器的
步骤302,对集合m中的每个用户,当网络与环境交互时,网络首先依据公式(13)获得一个动作at,根据at得出其选择的边缘服务器n(m)={n|αm,n,t=1},根据公式(7)计算各个用户的边缘计算处理时延,遍历循环结束后,执行步骤303。
步骤303,找出边缘计算延迟最小的用户m*,m*是用户索引,用
求解卸载决策和边缘服务器选择子问题(2),采用ddpg深度强化学习算法求解,该算法涉及两个网络:评估网络和目标网络,其中每个网络又包括价值网络、动作网络。如图3所示。基于ddpg算法求解子问题2的算法如图4所示,具体实施步骤为:
步骤3a,初始化深度强化学习算法评估网络中价值网络权重θq、动作网络权重θμ,并将其权重复制到目标网络中θq′=θq,θμ′=θμ,θq′是目标网络中价值网络的权重,θμ′是目标网络中动作网络的权重。初始化一个随机向量
步骤3b,获得时隙t所有用户的状态
得到动作at,at=[βt,αt];μ(st|θμ)表示评估网络在状态st下采取的动作,
步骤3c,从经验池r中随机取出m个样本(si,ai,ri,si+1)进行训练。评估网络中价值网络损失函数l,可计算为:
评估网络中动作网络的损失函数
其中q(si,ai|θq)为评估网络中价值网络的输出,yi为目标网络中价值网络的输出,μ(si|θμ)表示评估网络在状态si下采取的动作;根据l更新评估网络中价值网络权重θq,根据
θq′=τθq+(1-τ),θμ′=τθμ+(1-τ)θμ′(16)
τ为学习效率,更新目标网络的权重。
步骤3d,重复步骤3b,且t=t+1。直至t=t。迭代结束后评估网络中动作网络权重θμ为最优,此时动作网络输出最优动作a*,即可获得最优卸载决策β*和最优边缘服务器选择策略α*。
结合两个子问题的解,获得最优调度方案为α*,β*,i*(n,t),
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!