一种共享交通工具故障预测方法及系统
本发明涉及交通工具故障预测技术领域,特别是涉及一种共享交通工具故障预测方法及系统。
背景技术:
在建设交通强国的时代背景下,随着我国技术进步与国民消费观念的提升,为了缓解城市的交通拥堵、安全、能耗、尾气排放等问题,在城市交通中具有重要地位的共享交通在我国各大城市得到了逐步推广并应用。久而久之,出现了共享交通工具零部件丢失、报废率高,私加车锁等现象和“维护难、成本高昂”等问题。共享交通作为国民绿色出行的重要途径,促进了我国共享经济与新能源行业的健康发展,已然成为我国交通建设中不可或缺的环节。因此,如何解决共享交通“维护难、成本高昂”成为迫切需要解决的问题。
目前共享交通工具运维效率低下,主要依靠运维人员逐个检查产品,手动输入故障情况然后上传管理系统后台,一个产品从被检测故障到完成维修,通常需要耗费相当长的时间周期,伴随着人力、时间成本高昂等问题。企业在行业竞争中为了扩大市场份额,普遍致力于提升产品质量而赢取竞争力,在产品成本日益上升的趋势下,运维成本过高将会拖慢企业的发展速度,发展越来越吃力。
中国发明专利cn110706517a(公开日为2020年01月17日)公开了一种交通工具的智能安全预警方法、装置、系统及存储介质,该方法包括:行前预警步骤,基于交通工具在待行驶路径的环境信息及环境实时交通路况信息,建立第一数据模型,发送第一预警信息;行中预警步骤,基于交通工具实时位置信息和所在环境信息、交通工具状况信息,建立第二数据模型预测风险,发送第二预警信息。本发明的交通工具的智能安全预警方法、装置、系统及存储介质具有可以客观反映驾驶水平,并结合实时的路况信息和天气情况以及车辆实时数据进行安全风险预警,减少了交通事故的发生率。该专利的第一数据模型和第二数据模型的建立都是通过(1)整合包括环境信息和环境实时交通路况信息在内的数据源数据;(2)将数据源数据分区,分别分入训练集、验证集和测试集中;(3)分别对训练集、验证集、测试集中的数据变量进行处理,生成符合第一预设条件待输入候选预测模型的特征变量;(4)在各候选预测模型中按照训练、验证、测试数据顺序依次运行各自的特征变量获得各候选模型下的准确率和预测结果;(5)从各所述候选预测模型中选取最优预测模型。因此,该专利需要对多个模型进行训练,运算复杂,效率低,且作为候选模型的决策树模型、神经网络模型以及回归模型的预测准确性不高。
技术实现要素:
本发明的目的是提供一种可靠、高效的共享交通工具故障预测方法及系统。
为了实现上述目的,本发明提供了一种共享交通工具故障预测方法,包括如下步骤:
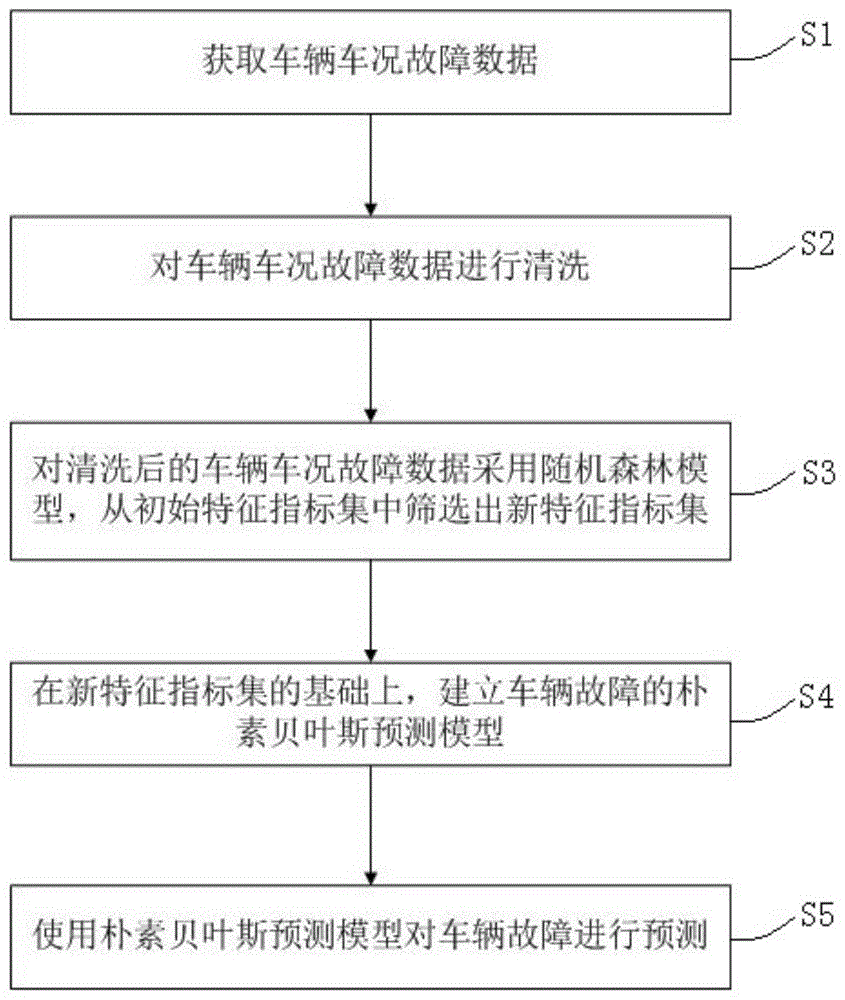
s1、获取车辆车况故障数据;
s2、对车辆车况故障数据进行清洗;
s3、对清洗后的车辆车况故障数据采用随机森林模型,从初始特征指标集中筛选出新特征指标集;
s4、在新特征指标集的基础上,建立车辆故障的朴素贝叶斯预测模型;
s5、使用朴素贝叶斯预测模型对车辆故障进行预测。
作为优选方案,在步骤1中,获取运维人员和用户保留在本地服务器日志文件中的车辆车况故障数据。
作为优选方案,通过apacheflume读取本地服务器的日志文件数据。
作为优选方案,在步骤s1中,获取的车辆车况故障数据保存在hadoop中的hdfs文件系统。
作为优选方案,在步骤s2中,将清洗后的车辆车况故障数据存储在mongodb中,步骤s5通过朴素贝叶斯预测模型预测的车辆故障情况数据写回mongodb中。
作为优选方案,步骤s2包括:
s2.1、缺失数据的清洗,根据缺失字段的重要性程度决定删除字段或补全字段;
s2.2、格式内容的清洗,整理、统一化数据格式,整理内容与字段应有内容的数据;
s2.3、逻辑错误数据的清洗,去除不合理的数据,修正逻辑矛盾的数据;
s2.4、非需求数据的清洗,去除不需要的数据;
s2.5、数据加工,计算新字段。
8、根据权利要求1所述的共享交通工具故障预测方法,其特征在于,步骤s2对获取的车辆车况故障数据清洗后所得的训练样本集
s={(x1,y1),(x2,y2),(x3,y3),…,(xn,yn)},
步骤s3包括:
s3.1、抽样,对s做k次抽样,生成k个自助样本集dk和k个袋外样本集00bk(k=1,2,…,k,其中dk与s大小相等);
s3.2、训练决策树模型,对k个自助样本集dk,分别训练k个决策树模型tk;
s3.3、对于ti∈tk(i=1,2,3,…,k),计算袋外数据误差err00b1i;
s3.4、随机地对袋外数据00b所有样本的特征x(j)加入噪声干扰
再次计算每个决策树模型tk的袋外数据误差err00b2i;
s3.5、计算每个特征x(j)的重要性,按降序排序
s3.6、筛选新的特征集,设定比例a,依据步骤s3.4所得的特征重要性排序,剔除相应比例的重要程度最低的特征集合n*a,得到一个新的特征集为n′=n-n*a;
s3.7、用新的特征集n'重复上述过程,直到剩下m个特征(m为根据数据实际情况提前设定的值);
s3.8、根据上述过程中得到的各个特征集和特征集对应的袋外误差率,选择袋外误差率最低的特征集作为新的特征指标集。
作为优选方案,在步骤s3.1中,对s抽样采用bootstrap抽样。
本发明还提供一种共享交通工具故障预测系统,包括:
数据获取模块,用于获取车辆车况故障数据;
数据清洗模块,用于对获取的车辆车况故障数据进行清洗;
预测模型建立模块,用于根据清洗后的车辆车况故障数据通过随机森林模型,从初始特征指标集中筛选出新特征指标集,在新特征指标集的基础上,建立车辆故障的朴素贝叶斯预测模型;
预测模块,用于根据预测模型对车辆进行故障预测。
作为优选方案,共享交通工具故障预测系统还包括数据采集与反馈模块,数据采集与反馈模块用于运维人员和用户上传车辆车况故障数据以及反馈预测模块的预测的车辆故障信息。
与现有技术相比,本发明的有益效果在于:
本发明根据收集的车辆车况故障数据通过随机森林模型筛选新特征指标集,再通过朴素贝叶斯模型进行预测,朴素贝叶斯模型学习效率高、所需估计的参数很少、对缺失数据不太敏感,与其他分类方法相比具有最小的误差率,因此,预测准确性高,但是朴素贝叶斯模型是基于“特征向量中一个特征的取值并不影响其他特征的取值”这个难以实现的假定的,从而导致单独应用朴素贝叶斯模型时预测不够准确,而本发明通过随机森林模型从初始特征指标集中筛选出新特征指标集,随机森林模型可以比较不同特征指标对分类的重要性,筛选出对分类类型更重要的新特征指标集,使特征指标之间更独立,进而使通过新特征指标集建立的朴素贝叶斯预测模型的分类更准确、可靠,且本发明通过两个模型依次训练得到最后的结果,保持了各个模型的独立和简单,效率高。
附图说明
图1是本发明实施例的共享交通工具故障预测方法的流程图。
图2是本发明实施例步骤s2的流程图。
图3是本发明实施例步骤s3的流程图。
图4是本发明实施例的共享交通工具故障预测系统的原理框图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
如图1所示,本发明优选实施例的一种共享交通工具故障预测方法,包括如下步骤:
s1、获取车辆车况故障数据;本实施例获取的车辆车况故障数据为运维人员和用户保留在本地服务器日志文件中的车辆车况故障数据,并且,通过apacheflume读取本地服务器的日志文件数据,上传到hadoop中的hdfs文件系统。
使用apacheflume将本地服务器的日志文件读入到hdfs中,一定程度地提升了数据读取的速度,充当了数据生产者和集中存储之间的中介,在两者之间提供稳定的数据流。
s2、对车辆车况故障数据进行清洗;并将清洗后的车辆车况故障数据存储在mongodb中。步骤s2包括:
s2.1、缺失数据的清洗,根据缺失字段的重要性程度决定删除字段或补全字段;
s2.2、格式内容的清洗,整理、统一化数据格式,整理内容与字段应有内容的数据;
s2.3、逻辑错误数据的清洗,去除不合理的数据,修正逻辑矛盾的数据;
s2.4、非需求数据的清洗,去除不需要的数据;
s2.5、数据加工,计算新字段。
海量的车辆车况故障数据经过清洗,更容易被系统所辨认,作为模型分析的坚实基础。
s3、对清洗后的车辆车况故障数据采用随机森林模型,从初始特征指标集中筛选出新特征指标集。本实施例使用spark对已经收集在mongodb中的数据采用随机森林模型。
步骤s2对获取的车辆车况故障数据清洗后所得的训练样本集
s={(x1,y1),(x2,y2),(x3,y3),…,(xn,yn)},
步骤s3包括:
s3.1、抽样,对s通过bootstrap抽样做k次抽样,生成k个自助样本集dk和k个袋外样本集00bk(k=1,2,…,k,其中dk与s大小相等);
s3.2、训练决策树模型,对k个自助样本集dk,分别训练k个决策树模型tk;
s3.3、对于ti∈tk(i=1,2,3,…,k),计算袋外数据误差err00b1i;
s3.4、随机地对袋外数据00b所有样本的特征x(j)加入噪声干扰
再次计算每个决策树模型tk的袋外数据误差err00b2i;
s3.5、计算每个特征x(j)的重要性,按降序排序
s3.6、筛选新的特征集,设定比例a,依据步骤s3.4所得的特征重要性排序,剔除相应比例的重要程度最低的特征集合n*a,得到一个新的特征集为n′=n-n*a;
s3.7、用新的特征集n'重复上述过程,直到剩下m个特征(m为根据数据实际情况提前设定的值);
s3.8、根据上述过程中得到的各个特征集和特征集对应的袋外误差率,选择袋外误差率最低的特征集作为新的特征指标集。
s4、在新特征指标集的基础上,建立车辆故障的朴素贝叶斯预测模型。
先通过随机森林模型预处理筛选掉冗余、不相关的特征,然后再通过朴素贝叶斯模型,高效、可靠地预测出产品故障状况,简化了朴素贝叶斯模型的结构,提升模型预测的正确率。
s5、使用朴素贝叶斯预测模型对车辆故障进行预测。本实施例将预测结果写回到mongodb里每辆车辆的数据文档中,实现对车辆故障的预测功能,后续向用户、维修部门反馈信息,从而预警下一位用车用户,提高维修部门的工作效率,进而向技术部门提供改进方向。
因此,本实施例收集运维人员、用户上传后保留在本地服务器日志文件中的车辆车况故障数据,并利用apacheflume读取日志文件数据,上传到hadoop中的hdfs文件系统,然后将存储在hdfs中的数据进行清洗,将清洗后的数据收集在mongodb中,再使用spark对已经收集在mongodb中的数据采用随机森林模型,从初始特征指标集中筛选出新特征指标集,在新特征指标集的基础上,建立车辆故障的朴素贝叶斯预测模型,将预测结果写回到mongodb里每辆车辆的数据文档中,实现对车辆故障的预测功能,后续向用户、维修部门反馈信息,从而预警下一位用车用户,提高维修部门的工作效率,进而向技术部门提供改进方向。
本实施例还提供了一种共享交通工具故障预测系统,包括数据采集与反馈模块、数据获取模块、数据清洗模块、预测模型建立模块和预测模块。
数据采集与反馈模块,用于运维人员和用户上传车辆车况故障数据以及反馈预测模块的预测的车辆故障信息;本实施例的数据采集与反馈模块为本地服务器,用户和运维人员通过数据采集与反馈模块上传车辆车况故障数据,车辆车况故障数据保存在本地服务器日志文件中。并且,车辆故障预测结果通过数据采集与反馈模块反馈给用户和运维人员。
数据获取模块,用于获取车辆车况故障数据;本实施例的数据获取模块通过apacheflume读取数据采集与反馈模块的日志文件数据并保存在hadoop中的hdfs文件系统。
数据清洗模块,用于对获取的车辆车况故障数据进行清洗;本实施例的数据清洗模块包括:缺失数据的清洗单元,用于根据缺失字段的重要性程度决定删除字段或补全字段;格式内容的清洗单元,用于整理、统一化数据格式,整理内容与字段应有内容的数据;逻辑错误数据的清洗单元,用于去除不合理的数据,修正逻辑矛盾的数据;非需求数据的清洗单元,用于去除不需要的数据;数据加工单元,用于计算新字段。
预测模型建立模块,用于根据清洗后的车辆车况故障数据通过随机森林模型,从初始特征指标集中筛选出新特征指标集,在新特征指标集的基础上,建立车辆故障的朴素贝叶斯预测模型。本实施例的预测模型建立模块包括随机森林模型单元和朴素贝叶斯预测模型单元。
预测模块,用于根据预测模型对车辆进行故障预测;并将预测结果发送到数据采集与反馈模块。
综上,本发明实施例提供一种共享交通工具故障预测方法,其根据收集的车辆车况故障数据通过随机森林模型筛选新特征指标集,再通过朴素贝叶斯模型进行预测,朴素贝叶斯模型学习效率高、所需估计的参数很少、对缺失数据不太敏感,与其他分类方法相比具有最小的误差率,因此,预测准确性高,但是朴素贝叶斯模型是基于“特征向量中一个特征的取值并不影响其他特征的取值”这个难以实现的假定的,从而导致单独应用朴素贝叶斯模型时预测不够准确,而本发明通过随机森林模型从初始特征指标集中筛选出新特征指标集,随机森林模型可以比较不同特征指标对分类的重要性,筛选出对分类类型更重要的新特征指标集,使特征指标之间更独立,进而使通过新特征指标集建立的朴素贝叶斯预测模型的分类更准确、可靠,且本发明通过两个模型依次训练得到最后的结果,保持了各个模型的独立和简单,效率高。另外,本发明还提供一种用于实现上述方法的共享交通工具故障预测系统。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和替换,这些改进和替换也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!