一种基于知识图谱的对话管理方法及对话系统与流程
本发明属于人机对话技术领域,更具体地,涉及一种基于知识图谱的对话管理方法及对话系统。
背景技术:
随着技术的发展,现有的人机对话系统如智能客服、智能个人助理等得到了广泛的应用。人机对话系统中最核心的部分就是对话管理模块,它决定了对话系统的对话策略及交互内容。
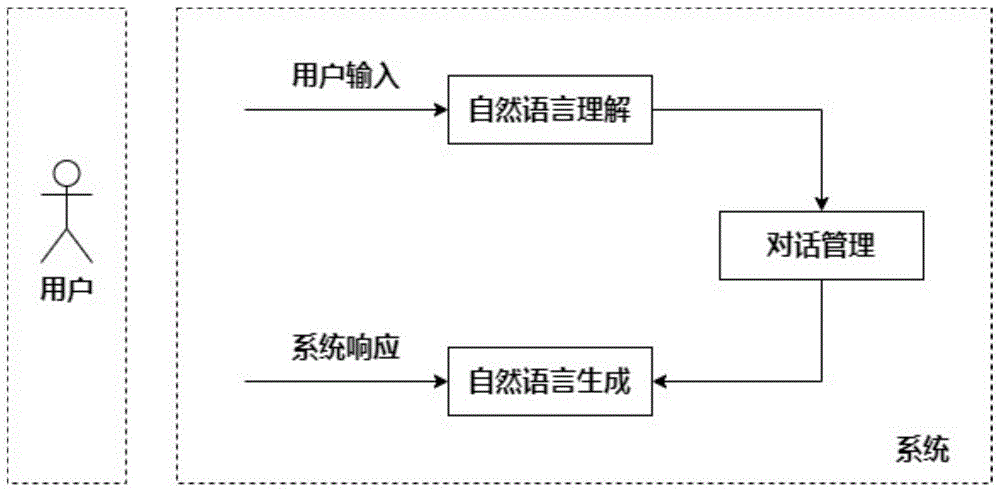
现有技术中,人机对话系统常常根据其有无任务目标分成闲聊型人机对话系统(比如微软小冰)和任务型人机对话系统(比如淘宝的小蜜、95588机器人客服)。本文提出的方法属于任务型人机对话系统的范畴。传统上,任务型人机对话系统常采用管道式的构建方法,一般分为三个模块:自然语言理解、对话管理和自然语言生成,如图1、2所示。
自然语言理解(naturallanguageunderstanding,nlu)模块,主要作用是对用户输入的句子进行理解,提取用户的对话意图以及与对话任务相关的信息,通常用语义槽表示,例如预定机票任务,包括语义槽“出发地”“目的地”“出发时间”“航班号”“乘机人”等信息。
对话管理(dialoguemanagement,dm)模块,主要作用是根据nlu得到的结果,结合对话历史信息,自动更新对话系统的内部状态,以此为基础选取系统下一步要进行的对话动作,例如“询问用户出发时间”“与用户确认目的地”等。
自然语言生成(naturallanguagegeneration,nlg)模块,主要作用是根据对话管理选择的对话动作,生成相应的自然语言回答,例如“请问您计划什么时候出发?”“请问您的目的地是北京吗?”。
传统的对话管理模块通常采用基于槽填充(slot-filling)的方法,将对话过程中需要表示为通过和用户的多轮交互不断获取槽值信息的过程。然而,上述基于槽填充的对话管理方法存在如下问题:
(1)在对话过程中槽的个数固定不变,槽和槽之间相对独立,使得对话系统难以处理复杂的对话任务。
(2)基于槽填充的任务型对话系统由于无法很好地处理状态动作空间过大的问题,所以可以设置的槽值数量有限,引入的领域知识信息不够丰富。
(3)由于槽的设置是针对各垂直领域的,所以进行领域迁移设计的改动将会非常复杂,成本很高。
技术实现要素:
为解决现有技术中存在的不足,本发明的目的在于,提供一种基于知识图谱的对话管理方法及对话系统。
本发明采用如下的技术方案。一种基于知识图谱的对话管理方法,包括以下步骤:
步骤1,用户输入内容,进行自然语言理解,输出对话意图和实体词;
步骤2,根据步骤1获得的实体词,如果其是知识图谱中的一个实体,则记该实体被提及,采用一个一维数组表示知识图谱中的每个实体在对话中的提及状态,记为全局状态数组g;
步骤3,将步骤2生成的全局状态数组g进行层级压缩,对于每个实体,采用另一个一维数组表示用户围绕该实体的对话意图,记为局部状态数组l;
步骤4,使用步骤3生成的局部状态数组l,通过q-learning进行训练得到q表,从而选择局部状态对应的q值最大的动作作为最优动作,进行自然语言生成,向用户输出应答。
优选地,步骤1中,输出的对话意图包括:询问、告知、肯定、否定、开始对话和结束对话;实体词包括:命名实体及与任务相关的领域实体。
优选地,步骤2中,以g[k]表示全局状态数组g中的元素,第k个元素代表知识图谱中id为k的实体,k∈[0,n-1],n为知识图谱中的实体个数,实体状态可能的取值集合为{0,1,2},
g[k]=0,则id为k的实体未被用户提到,g[k]初始化为0,
g[k]=1,则id为k的实体被用户提到且处于歧义状态,
g[k]=2,则id为k的实体被用户提到且处于非歧义状态。
优选地,步骤3中,局部状态数组l的长度对应系统动作,每一位的取值对应用户意图。
优选地,步骤3中,局部状态数组l的长度为3,即l[0],l[1]和l[2],对应于3个系统动作:向用户询问、和用户确认及终止对话,分别以“request”、“confirm”及“terminate”表示;
l[0]和l[1]的取值集合为{0,1,2,3,4},分别对应于用户的开始对话、肯定回答、否定回答、告知信息和询问信息,分别以“greet”、“yes”、“no”、“inform”和“query”表示;
l[2]的取值集合为{0,1},分别对应继续对话和结束对话,继续对话表示结束对话以外的其它5个意图。
优选地,步骤3包括:
步骤3.1,判断被用户提及的实体是否处于歧义状态,即g[k]==1是否为真,若为真,则系统动作设为“request”;反之,系统动作设为“confirm”;
步骤3.1,判断当前是否属于终止状态,终止状态包括:不可能状态、对话轮次超过40轮以及用户主动说再见,若属于终止状态,则系统动作设为“terminate”,同时令l[2]=1,执行步骤3.4;否则,令l[2]=0;
步骤3.2,若系统动作为“request”,如果用户意图为“inform”,则令l[0]=3,执行步骤3.5;反之,返回步骤3.1;
步骤3.3,若系统动作为“confirm”,如果用户意图为“yes”,则令l[1]=1,执行步骤3.5;反之,返回步骤3.1;
步骤3.4,若系统动作为“terminate”,如果用户意图为“end”,跳出并结束;反之,返回步骤3.1;
步骤3.5,判断被用户提及的实体是否处于歧义状态,即g[k]==1是否为真,若为真,则系统动作设为“request”;反之,系统动作设为“confirm”,返回步骤3.1。
优选地,步骤4中,q-learning训练步骤包括:
步骤4.1,随机初始化q表的值q(s,a);
步骤4.2,对于每个对话中的每一轮,采用ε-greedy策略,根据当前外部世界状态s选一个动作a;
步骤4.3,执行动作a,并更新:
q(s,a)←q(s,a)+α[r+γmaxa,q(s′,a′)-q(s,a)]
式中:
α表示学习率,
γ表示阻尼系数
s表示前外部世界状态,为全局数组g的非零位的取值和局部数组l下每一位的不同取值所张成的笛卡尔空间,s′表示下一步外部世界状态,
a表示系统动作,包括“request”、“confirm”和“terminate”,a′表示下一步的系统动作,
maxa′q(s′,a′)表示遍历所有的a′,以取得q(s′,a′)的最大值,
步骤4.4,重复4.2和4.3,直至算法收敛。
本发明还提供了一种基于知识图谱的人机对话系统,包括:自然语言理解模块、对话管理模块和自然语言生成模块,
所述自然语言理解模块用于用户输入内容,进行自然语言理解,输出对话意图和实体词;
对话管理模块接收所述自然语言理解模块输出的对话意图和实体词,生成表示知识图谱中的每个实体在对话中的提及状态的一个一维数组,即全局状态数组g,并层级压缩全局状态数组g获得一个一维数组,即局部状态数组l,使用该局部状态数组l,通过q-learning进行训练得到q表,从而选择局部状态对应的q值最大的动作作为最优动作,输出至自然语言生成模块,
所述自然语言生成模块用于接收对话策略选择单元输出的最优动作进行自然语言生成,向用户输出应答。
优选地,对话管理模块包括:对话状态追踪单元和对话策略选择单元,对话状态追踪单元接收所述自然语言理解模块输出的对话意图和实体词,生成全局状态数组g和局部状态数组l;
对话状态追踪单元中,以g[k]表示全局状态数组g中的元素,第k个元素代表知识图谱中id为k的实体,k∈[0,n-1],n为知识图谱中的实体个数,实体状态可能的取值集合为{0,1,2};g[k]=0,则id为k的实体未被用户提到,g[k]初始化为0;g[k]=1,则id为k的实体被用户提到且处于歧义状态,即在知识图谱中有不止一个父节点;g[k]=2,则id为k的实体被用户提到且处于非歧义状态,即在知识图谱中只有一个父节点。
优选地,对话状态追踪单元中,局部状态数组l的长度为3,即l[0],l[1]和l[2],对应于3个系统动作:向用户询问、和用户确认及终止对话,分别以“request”、“confirm”及“terminate”表示,l[0]和l[1]的取值集合为{0,1,2,3,4},分别对应于用户的开始对话、肯定回答、否定回答、告知信息和询问信息,分别以“greet”、“yes”、“no”、“inform”和“query”表示;l[2]的取值集合为{0,1},分别对应继续对话和结束对话,继续对话表示结束对话以外的其它5个意图。
优选地,对话策略选择单元使用对话状态追踪单元生成的局部状态数组l,通过q-learning进行训练得到q表,从而选择局部状态对应的q值最大的动作作为最优动作,输出至自然语言生成模块。
本发明的有益效果在于,与现有技术相比,本发明摒弃了基于槽填充的对话管理方法,采用知识图谱驱动的对话管理模型。先用一个长度为实体个数的一维数组表示知识图谱中的实体在对话中被提及的状态,被称为对话的全局状态,包括未提及、提及、提及并确认三个状态,考虑到状态空间过大的问题,再通过一定规则把长度为实体个数的一维数组,映射到长度为3的一维数组来表示对话的局部状态。接着,用q-learning训练得到的q表来进行对话策略选择。这样就解决了背景技术中所述基于槽填充的对话管理的问题。第一,用知识图谱来表示对话状态可以引入更丰富的领域知识,同时层级压缩的方法也解决了状态空间过大的问题,使得对话模型可以建模更复杂的对话任务。第二,在相似的领域内,易于进行领域迁移。
附图说明
图1为管道式方法结构图;
图2为现有技术中的对话管理流程图;
图3为本发明基于知识图谱的对话管理方法流程图。
具体实施方式
下面结合附图对本申请作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本申请的保护范围。
实施例1:一种基于知识图谱的对话管理方法
如图3所示,本发明提供了一种基于知识图谱的对话管理方法,包括以下步骤:
步骤1,用户输入内容,进行自然语言理解,输出对话意图和实体词,根据自然语言理解模块的结果,得到用户的对话意图,并将用户输入中包含的实体信息,映射到对应知识图谱上的实体。
自然语言理解的输入为用户所说的一句话(即句子文本),输出为用户的对话意图及输入中所包含的实体词。输出的对话意图包括:询问、告知、肯定、否定、开始对话和结束对话;实体词包括命名实体及与任务相关的领域实体,对应知识图谱中的具体实体。
值得注意的是,本实施例中列举的六类对话意图是一种优选但非限制性的实施方式,所属领域技术人员可以根据对话系统的用途等考量,设计更多或者更少的用户意图,或者是使用这六类以内或者六类以外的对话意图,替代性的实施方式均落入本发明的发明构思范围之内。
知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性值对,实体间通过关系相互联结,构成网状的知识结构。这里的知识图谱专门指对话任务相关联的业务流程知识,例如,办理电话入网需要根据用户类别为个人或团体,选择不同的办理流程。“用户类别-包括-个人”则为一个三元组。
步骤2,根据步骤1获得的实体词,如果其是知识图谱中的一个实体,则记该实体被提及,采用一个一维数组表示知识图谱中的每个实体在对话中的提及状态,记为全局状态数组g(即global的首字母)。更具体地,步骤2中,以g[k]表示全局状态数组g中的元素,第k个元素代表知识图谱中id为k的实体,k∈[0,n-1],n为知识图谱中的实体个数,实体状态可能的取值集合为{0,1,2};
g[k]=0,则id为k的实体未被用户提到,g[k]初始化为0;
g[k]=1,则id为k的实体被用户提到且处于歧义状态,即在知识图谱中有不止一个父节点;
g[k]=2,则id为k的实体被用户提到且处于非歧义状态,即在知识图谱中只有一个父节点。
步骤3,根据层级压缩方法,将步骤2生成的全局状态数组g进行层级压缩,对于每个实体,采用另一个一维数组表示用户围绕该实体的对话意图,记为局部状态数组l(即local的首字母)。具体地,步骤3中,局部状态数组l的长度对应系统动作,每一位的取值对应用户意图。
一个优选但非限制性的实施方式为,为不失一般性,步骤3中,局部状态数组l的长度为3,即l[0],l[1]和l[2],对应于3个系统动作:向用户询问、和用户确认及终止对话,分别以“request”、“confirm”及“terminate”表示。
l[0]和l[1]的取值集合为{0,1,2,3,4},分别对应于用户的开始对话、肯定回答、否定回答、告知信息和询问信息,分别以“greet”、“yes”、“no”、“inform”和“query”表示;
l[2]的取值集合为{0,1},分别对应继续对话和结束对话,继续对话表示结束对话以外的其它5个意图。如下表所示。
步骤3包括:
步骤3.1,判断被用户提及的实体是否处于歧义状态,即g[k]==1是否为真,若为真,则系统动作设为“request”;反之,系统动作设为“confirm”;
步骤3.1,判断当前是否属于终止状态,终止状态包括:不可能状态、对话轮次超过40轮以及用户主动说再见,若属于终止状态,则系统动作设为“terminate”,同时令l[2]=1,执行步骤3.4;否则,令l[2]=0;
步骤3.2,若系统动作为“request”,如果用户意图为“inform”,则令l[0]=3,执行步骤3.5;反之,返回步骤3.1;
步骤3.3,若系统动作为“confirm”,如果用户意图为“yes”,则令l[1]=1,执行步骤3.5;反之,返回步骤3.1;
步骤3.4,若系统动作为“terminate”,如果用户意图为“end”,跳出并结束;反之,返回步骤3.1;
步骤3.5,判断被用户提及的实体是否处于歧义状态,即g[k]==1是否为真,若为真,则系统动作设为“request”;反之,系统动作设为“confirm”,返回步骤3.1。
步骤4,使用步骤3生成的局部状态数组l,通过q-learning进行训练得到q表,从而选择局部状态对应的q值最大的动作作为最优动作,进行自然语言生成,向用户输出应答。具体地,
本发明的一个优选但非限制性的实施方式为,基于马尔可夫决策过程(markovdecisionprocess,mdp),使用q-learning算法进行对话策略选择。马尔可夫决策过程可以用一个四元组来描述<a,s,t,r>,其中,s是指外部世界状态的集合;a指的是智能体(本文中指对话系统)的动作集合;t指的是状态转移函数;r是指回报函数,给出智能体在特定状态下执行动作带来的立即回报。
q-learning的核心是q表,q表的行和列分别表示外部世界状态和智能体动作的值,q表的值q(s,a)衡量当前外部世界状态s采取动作a到底有多好。四要素设计完备后,就可以采用q-learning来进行训练得到q表,从而选择状态对应q值最大的作为最优动作。
步骤4中,q-learning训练步骤包括:
步骤4.1,随机初始化q表的值q(s,a);
步骤4.2,对于每个对话中的每一轮,采用ε-greedy策略,根据当前外部世界状态s选一个动作a;
步骤4.3,执行动作a,并更新:
q(s,a)←q(s,a)+α[r+γmaxa′q(s′,a′)-q(s,a)]
式中:
α表示学习率,可根据实验确定为一个较小的值,
γ表示阻尼系数,可根据实验确定为一个较小的值,
s表示当前外部世界状态,在本实施例中,状态s为全局状态数组g的非零位的取值和局部数组l下每一位的不同取值所张成的笛卡尔空间(2×5×5×2),s′表示下一步外部世界状态,
a表示系统动作,系统动作,包括“request”、“confirm”和“terminate”,a′表示下一步的系统动作,
maxa′q(s′,a′)表示遍历所有的a′,以取得q(s′,a′)的最大值,
步骤4.4,重复4.2和4.3,直至算法收敛。
训练得到的q表的横排是所有对话状态,纵列是系统的对话动作,这样对于每一个状态和每一个动作都有相应q值。每次接收到用户的对话后,根据对话状态追踪模块传来的轮次状态数组对应的状态s(s∈t),查找q表,选择qmax(s,a)对应的a作为最优动作,输出给自然语言生成模块。
实施例2:一种使用基于知识图谱的对话管理方法的对话系统
如图3所述,本发明还提供了一种使用基于知识图谱的对话管理方法的对话系统,包括:自然语言理解模块、对话管理模块和自然语言生成模块。
所述自然语言理解模块用于用户输入内容,进行自然语言理解,输出对话意图和实体词。
对话管理模块包括:对话状态追踪单元和对话策略选择单元。对话状态追踪单元接收所述自然语言理解模块输出的对话意图和实体词,生成全局状态数组g(即global的首字母)和局部状态数组l(即local的首字母)。
全局状态数组g为一个一维数组,表示知识图谱中的每个实体在对话中的提及状态。具体地,根据所述自然语言理解模块输出的实体词,如果其是知识图谱中的一个实体,则记该实体被提及。更具体地,对话状态追踪单元中,以g[k]表示全局状态数组g中的元素,第k个元素代表知识图谱中id为k的实体,k∈[0,n-1],n为知识图谱中的实体个数,实体状态可能的取值集合为{0,1,2};g[k]=0,则id为k的实体未被用户提到,g[k]初始化为0;g[k]=1,则id为k的实体被用户提到且处于歧义状态,即在知识图谱中有不止一个父节点;g[k]=2,则id为k的实体被用户提到且处于非歧义状态,即在知识图谱中只有一个父节点。
局部状态数组l为另一个一维数组,由全局状态数组g进行层级压缩获得,于每个实体,表示用户围绕该实体的对话意图,一个优选但非限制性的实施方式为,为不失一般性,对话状态追踪单元中,局部状态数组l的长度为3,即l[0],l[1]和l[2],对应于3个系统动作:向用户询问、和用户确认及终止对话,分别以“request”、“confirm”及“terminate”表示。l[0]和l[1]的取值集合为{0,1,2,3,4},分别对应于用户的开始对话、肯定回答、否定回答、告知信息和询问信息,分别以“greet”、“yes”、“no”、“inform”和“query”表示;l[2]的取值集合为{0,1},分别对应继续对话和结束对话,继续对话表示结束对话以外的其它5个意图。
对话策略选择单元使用对话状态追踪单元生成的局部状态数组l,通过q-learning进行训练得到q表,从而选择局部状态对应的q值最大的动作作为最优动作,输出至自然语言生成模块。
所述自然语言生成模块用于接收对话策略选择单元输出的最优动作进行自然语言生成,向用户输出应答。
本发明的有益效果在于,与现有技术相比,本发明摒弃了基于槽填充的对话状态表示,用知识图谱来表示对话状态。先用一个长度为实体个数的一维数组表示知识图谱中的实体状态(即对话状态),考虑到状态空间过大的问题,再通过一定规则把长度为实体个数的一维数组压缩成长度为三的一维数组来表示对话状态。接着,用q-learning训练得到的q表来进行对话策略选择。这样就解决了背景技术中所述基于槽值的对话管理的问题。第一,用知识图谱来表示对话状态可以引入更丰富的结构信息。同时层级压缩的方法也解决了状态空间过大的问题,使得对话模型可以建模更复杂的对话任务。第二,在相似的领域内,易于进行领域迁移。
本发明申请人结合说明书附图对本发明的实施示例做了详细的说明与描述,但是本领域技术人员应该理解,以上实施示例仅为本发明的优选实施方案,详尽的说明只是为了帮助读者更好地理解本发明精神,而并非对本发明保护范围的限制,相反,任何基于本发明的发明精神所作的任何改进或修饰都应当落在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!