融合指针生成网络的知识图谱智能问答方法
本发明属于基于人工智能的问答方法领域,尤其涉及基于知识图谱的问答方法和基于指针网络的生成式方法。
背景技术:
知识图谱(knowledgegraph)是一种将事实以结构化的形式进行表示的方法,它由实体、关系和语义描述组成。它是一种表示实体间相互关系的庞大的语义网络,以(头实体,关系,尾实体)的三元组形式来表示。当前,知识图谱技术得到了广大研究学者广泛关注,并将知识图谱应用到语义搜索、智能问答、个性化推荐中。这样可以将零散的知识体系化后准确快速的传递给用户。
目前,知识图谱问答主流的方法主要有基于语义分析的方法和基于信息检索的方法。传统的知识图谱问答系统返回的答案往往是知识库中存在的实体或者关系。若知识库中没有存储与该问句相关的三元组则无法返回正确答案。所以,为了解决以上问题,将知识图谱技术和生成式方法相结合。构建一种融合指针生成网络的知识图谱智能问答方法是很有研究价值的。
技术实现要素:
为了满足上述现有技术中的需求,本发明提供一种融合指针生成网络的知识图谱智能问答方法,该方法能够把知识图谱和指针生成网络进行结合,将文本中存在的知识库中没有的数据进行存储,还能解决单一文本中知识存储来不高的问题,提高问答准确率;并且能够以自然语言形式呈现给用户,提升用户的体验感。
技术方案如下:
一种融合指针生成网络的知识图谱智能问答方法,步骤如下:
步骤1:使用分词工具对webqa数据集中的原文和问句部分进行分词并检查;
步骤2:对正确分词后的数据使用bilstm-crf模型进行命名实体识别;
步骤3:在neo4j数据库中查询识别的实体对应的三元组;
步骤4:统计对应三元组中每一词出现的频率,查询到的三元组中的单词按照词频大小顺序存入知识词表;
步骤5:使用深度学习方法获取问句的词向量;
步骤6:构造生成式模型,返回答案。
进一步的,针对步骤1,使用jieba分词对数据集中的原文和问句进行分词,并去除停用词和标点符号。
进一步的,针对步骤3,对步骤2中识别出的实体使用cypher语句在neo4j图数据库中进行查询,返回查询的实体和关系;其中,使用的知识库为cn-dbpedia。
进一步的,针对步骤4,使用tf算法分别计算步骤3中每个单词在数据集中出现的频率,按照频率进行排序统一存入知识词表中。
进一步的,针对步骤5,使用预训练语言模型bert模型获取问句的词向量再和问句中实体的词频语义特征进行拼接,作为下一模型的输入序列。
进一步的,针对步骤6,使用指针生成网络模型来决定是从知识词表中生成词汇还是从问句中复制词汇作为答案返回。
进一步的,所述bilstm-crf模型包括:
(1)嵌入层:首先将输入的文本转化为计算机能够进行计算的向量形式;采用字符级别的分布式表示方法,采用word2vec中的cbow进行词向量的预训练,将字符向量序列作为模型的初始化输入;词向量的维度设置为300维,窗口大小设置为5;
(2)bilstm层:输入的句子序列经过字向量映射获取的字符向量序列作为双向lstm层各个时间步的初始输入;bilstm模型由前向lstm模型和后向lstm模型组成,用于获取句子双向的语义信息;lstm模型由三个用sigmoid作为激活函数的门结构及一个细胞状态组成,三个门结构分别为输入门,遗忘门和输出门;
每个门的输入以及计算公式如下:
遗忘门的计算:选择需要丢弃的内容,其输入为前一时间的隐藏状态ht-1和当前输入词xt,输出的结果为遗忘门的值ft;计算过程表示为:
ft=σ(wf·xt+vf·ht-1+bf)公式(1)
其中σ表示sigmoid激活函数,wf、vf表示线性关系的系数,bf表示线性关系的偏置;
输入门的计算:其输入为前一时间的隐层状态ht-1和当前输入词xt,输出为输入门的值it和临时单元状态
it=σ(wi·xt+vi·ht-1+bi)公式(2)
其中wi、vi表示权重矩阵,bi表示偏置,ht-1表示lstm模型的输入,wc、vc表示权重矩阵,bc表示训练得出的偏置;
当前记忆单元更新的计算:表示计算当前时刻的单元状态。其输入为遗忘门的值ft,输入门的值it,根据公式(4)得出的上一时刻的单元状态ct-1和临时单元状态
输出门和当前隐藏状态的计算:输出门的输入为前一时刻的隐藏状态ht-1,当前时刻输入词xt和当前时刻的单元状态ct,输出为输出门的值ot和隐层状态ht,计算过程表示为:
ot=σ(wo·xt+vo·ht-1+bo)公式(5)
其中wo、vo表示权重矩阵,bo表示偏置;
最后通过向量拼接得到最终的隐层表示
crf层:通过crf层进行句子级的序列标注,crf层通过从训练集中学习到的约束,来确保最终预测到的实体标签序列是有效的以解决基于神经网络方法的预测标签序列可能无效的问题。
进一步的,所述bert模型包括:
(1)transformer模型:采用位置嵌入的方式来添加时序信息,bert输入表示由词向量、句子嵌入和位置嵌入向量拼接,使得在一个标记序列中清楚地表示单个文本句子或一对文本句子;
(2)maskedlanguagemodel:通过随机遮蔽句子里某些单词,然后预测被遮蔽的单词;
(3)nextsentenceprediction:通过预训练一个二分类的模型,随机替换一些句子,再基于上一句进行预测,从而学习句子之间的关系;
最后,将问句获取的词向量和问句中出现的实体的词频语义特征进简单拼接,作为生成式模型的输入序列。
进一步的,步骤5返回的序列信息作为构造生成式模型的输入,然后输入到基于attention的encoder-decoder模型中;指针生成网络对于每个译码器的时间步计算一个生成概率以此来决定是从知识词表中生成单词还是从问句中复制单词,然后选择词汇构成答案。
进一步的,模型训练描述如下:
(1)基于attention的encoder-decoder模型:在模型的解码部分使用lstm模型,其具体流程描述如下:问句通过bert模型和词频语义特征拼接以后生成新的输入序列,再和word2vec训练知识图谱三元组得到的词向量一起作为输入将输入序列输入到bilstm编码器,然后经过单层bilstm后生成隐层状态hi,在t时刻lstm解码器接收到上一时刻生成的词向量,得到解码状态序列st;再将编码器与解码器的状态计算后得到注意力分布at,以此来确定该时间步需要关注的字符;其公式如下:
at=softmax(et)公式(8)
其中vt表示注意力机制的系数矩阵,wh、ws、wk表示通过训练得到的系数参数,kt表示当前问句中对应实体的排序最高的知识图谱三元组的选择向量;
得到的注意力权重和加权求和得到重要的上下文向量
其中
(2)指针网络:当该模型用作生成单词时,模型生成的单词是在知识词表中生成的;其概率分布由解码状态序列st和上下文向量
p(w)=pvocab(w)公式(11)
其中,式中的v'vbb'是通过学习获得的参数,p(w)表示在当前时刻生成单词是知识词表中单词w的概率;
当模型用作复制单词时,根据t时刻的注意力分布at来决定指向输入序列中单词w的概率,描述公式如下:
最后词汇分布的生成由输入词概率分布和知识词表概率分布通过生成概率pgen来决定是从问句中复制单词还是从知识词表中生成单词,描述公式如下:
其中向量
最后通过pgen对词汇分布和注意力分布加权平均,得到生成单词w最终的概率分布,描述公式如下:
p(w)=pgenpvocab(w)+(1-pgen)pa(w)公式(14)
由上式可知,当单词w不出现在知识词表上时pvocab(w)=0,当单词w不出现在问句中pa(w)=0;
(3)coveragemechanism:将之前时间步中的注意力权重累加得到覆盖向量ct;然后使用之前的注意力权重的值来解决当前注意力权重的决定,以此来避免在同一个位置产生重复,从而避免了重复生成的文本;ct的计算公式如下:
将其添加到注意力权重的计算过程,其计算公式如下:
同时,为coveragevector添加损失,其计算公式如下:
由于这样的coverageloss是一个有界的量
最终的loss计算公式如下:
最后通过上述操作决定生成或者复制单词用作答案返回。
本发明的有益效果是:
本发明通过使用上述的技术方案,使用深度学习技术对文本进行实体识别,使用知识图谱技术对知识进行快速的查询,结合生成式模型有效的解决了返回的答案生硬、单一和知识库中存储量不全的问题。具体来说,本发明对数据集中的原文去停用词后使用bilstm-crf对文本进行实体识别。然后将识别的实体使用cypher语句在知识图谱中进行查询。面对实体识别精度有误的问题,本发明在预处理部分将该词加入自定义词典中进行分词,有效解决了该问题。为了将传统的抽取式知识图谱问答改进为生成式的知识图谱问答,本发明创新性的采用知识图谱来构建知识词表作为指针生成网络的软链接。这样一来,可以有效的将原文中的数据和知识图谱中的三元组进行融合,进一步弥补未登录词的问题,并且能够有效的生成答案。本发明使用的方法节约了在互联网中查找海量数据来得到答案的时间,还能更充分的理解用户的意图,返回更符合用户阅读模式的答案。
附图说明
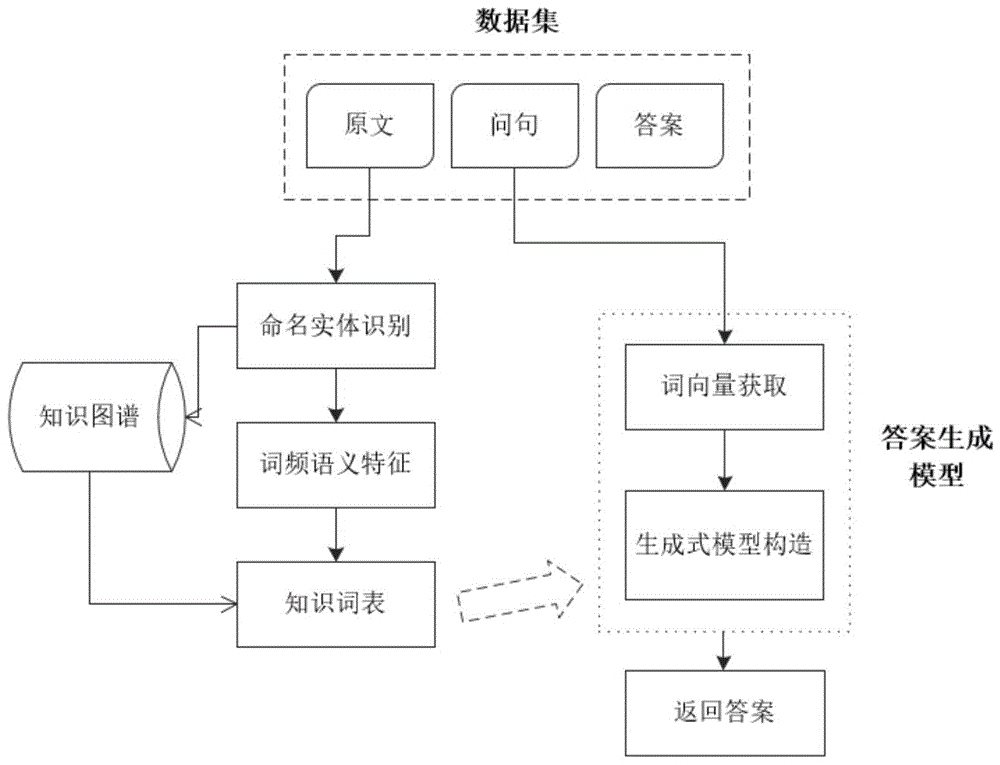
图1为本发明整体流程图;
图2为本发明中命名实体识别bilstm-crf网络结构图;
图3为本发明中预训练语言模型bert网络结构图;
图4为本发明中生成式模型bert-pgn网络结构图;
图5为本发明中数据库可视化效果图;
图6为本发明中网页可视化效果图。
具体实施方式
下面将参照附图1-6更详细地描述本发明一种融合指针生成网络的知识图谱智能问答构建方法的具体操作步骤。
实施例1
本发明的整体实现流程主要包括三部分,分别是知识词表构建模块、词向量获取模块、生成式模型构建模块。
本发明构建流程图如图1所示,下面将详细介绍每一步骤。
步骤1:对原始的webqa数据集中的原文和问句利用jieba分词工具进行分词,并去除标点符号和停用词,然后对处理后的数据进行检查,若出现没有正确进行分词的词,则进行人工分词并将其添加到自定义词典中;
步骤2:将数据进行预处理后,训练为词向量,然后使用bilstm-crf进行命名实体识别;
步骤3:然后使用cypher语句查询该实体在neo4j图数据库中所有的三元组信息;
步骤4:查询实体在neo4j图数据库中存在的所有三元组,若知识库中不存在该实体,则直接统计其词频后添加到知识词表中;若存在,则分别统计三元组中每个实体和关系在数据集的原文和问句中出现的频率,按照词频大小顺序存入知识词表;
步骤5:使用bert预训练语言模型获取问句的词向量,与问句中实体的词频特征进行拼接,作为生成式模型的输入;
步骤6:使用指针生成网络模型结合知识图谱进行答案生成;
实施例2
由图1所示,一种融合指针生成网络的知识图谱智能问答方法主要从四个方面进行构建。
步骤1:对数据集进行命名实体识别;
步骤2:在neo4j中检索实体并统计词频,将实体存入知识词表;
步骤3:词向量获取;
步骤4:构造与知识图谱结合的指针生成网络模型,返回答案;
下面将详细介绍每一步骤:
步骤1:使用jieba分词工具和预先根据数据集设置的自定义词典对数据进行分词、去停用词等,然后使用词嵌入技术将数据集中的原文和问句分别作为实体识别模型中bilstm层的输入。然后使用crf获得最优的预测序列。本发明中使用word2vec工具的cbow模型训练进行训练。bilstm-crf的模型结构图如图2所示。
模型训练描述如下:
1)嵌入层:首先需要将输入的文本转化为计算机能够进行计算的向量形式。本项目采用字符级别的分布式表示方法,采用word2vec中的cbow进行词向量的预训练,将字符向量序列作为模型的初始化输入。词向量的维度设置为300维,窗口大小设置为5。
2)bilstm层:输入的句子序列经过字向量映射获取的字符向量序列作为双向lstm层各个时间步的初始输入。bilstm模型由前向lstm模型和后向lstm模型组成,可以获得句子双向的语义信息。它有效解决了单向lstm模型只能编码从前到后的信息,不能编码从后到前的信息。lstm模型由三个用sigmoid作为激活函数的门结构及一个细胞状态组成,三个门结构分别为输入门,遗忘门和输出门。下面分别介绍每个门的输入以及计算公式:
遗忘门的计算:遗忘门就是选择需要丢弃的内容。它的输入为前一时间的隐藏状态ht-1和当前输入词xt输出的结果为遗忘门的值ft。计算过程可以表示为:
ft=σ(wf·xt+vf·ht-1+bf)公式(1)
其中σ表示sigmoid激活函数,wf、vf表示线性关系的系数,bf表示线性关系的偏置。
输入门的计算:它的输入为前一时间的隐层状态ht-1和当前输入词xt,输出为输入门的值it和临时单元状态
it=σ(wi·xt+vi·ht-1+bi)公式(2)
其中wi、vi表示权重矩阵,bi表示偏置,ht-1表示lstm模型的输入,wc、vc表示权重矩阵,bc表示训练得出的偏置。
当前记忆单元更新的计算:表示计算当前时刻的单元状态。其输入为遗忘门的值ft,输入门的值it,根据公式(4)得出的上一时刻的单元状态ct-1和临时单元状态
输出门和当前隐藏状态的计算:输出门的输入为前一时刻的隐藏状态ht-1,当前时刻输入词xt和当前时刻的单元状态ct,输出为输出门的值ot和隐层状态ht,计算过程可表示为:
ot=σ(wo·xt+vo·ht-1+bo)公式(5)
其中wo、vo表示权重矩阵,bo表示偏置。
最后通过向量拼接得到最终的隐层表示
1)crf层:通过crf层进行句子级的序列标注,这一步骤也可以解决从bilstm模块中输出的标签序列可能无效的问题。crf模块通过从训练集中学习到的一些约束,来确保最终预测到的实体标签序列是有效的,从而解决基于神经网络方法的预测标签序列可能无效的问题。
步骤2:根据步骤1中所得的实体信息,使用cypher语句查询neo4j图数据库,搜索知识库中含有识别出的实体的所有三元组。把这些三元组中的实体、关系与数据集进行对应,然后通过tf算法统计每个词汇的频率。最后按照词频的顺序从大到小依次存入知识词表中。若在neo4j中没有检索到该实体,则统计该实体在数据集中对应的词频,存入知识词表,以解决知识库中存储量的问题。
步骤3:一般情况下,通过传统的神经网络语言模型获取的词向量是单一固定的,存在无法表示字的多义性等问题。预训练语言模型很好地解决了这一问题,能够结合字的上下文内容来表示字。因此在词向量获取阶段主要使用预训练语言模型bert和词频语义特征进行拼接,用作后续的输入序列。加入词频语义特征可以有效的影响后续注意力权重的计算,通过词频语义特征有效的强调重要词汇的作用。
模型选择:当前,随着深度学习技术的发展,自然语言处理领域越来越重视词向量的获取工作。传统的word2vec、glove方法是基于单层神经网络,这种方法中的词向量与上下文无关,一个词只有一种表示方法。bert模型可以很好的解决传统机器学习方法种特征稀疏的问题,并且还能拓宽了词向量的泛化能力,能够充分学习字符级、词级、句子级甚至句间关系特征,增强字向量的语义表示。因此本发明使用bert模型来获取词向量。由于webqa数据集中存在20%的原文长度超过500,若直接粗暴的截断,可以会导致上下文信息缺失的问题。因此,本文使用滑窗法把文档分割成有部分重叠的短文本段落,然后把这些文本得出的向量拼接起来或者做均值池化操作。其结构图如图3所示。
模型训练描述如下:
a)transformer模型:它是文本序列网络的一种新架构,基于self-attention机制,任意单元都会交互,没有长度限制问题,能够更好捕获长距离上下文语义特征。bert模型采用了多层的双向transformer编码器结构,同时受到左右语境的制约,能够更好地包含丰富的上下文语义信息。另外,transformer模型针对self-attention机制无法抽取时序特征的问题,采用了位置嵌入的方式来添加时序信息,bert输入表示由词向量、句子嵌入和位置嵌入这3个向量拼接,能够在一个标记序列中清楚地表示单个文本句子或一对文本句子。
b)maskedlanguagemodel:maskedlanguagemodel是为了训练深度双向语言表示向量的模型,通过随机遮蔽句子里某些单词,然后预测被遮蔽的单词,类似于“完形填空”的学习模式。相比于传统标准语言模型只能从左至右或从右至左单向预测目标函数,maskedlanguagemodel可以从任意方向预测被掩盖的单词。
c)nextsentenceprediction:它是为了训练一个理解句子关系的模型,由于许多重要的自然语言处理下游任务,例如智能问答和自然语言推理,都是建立在理解两个文本句子之间的关系的基础上,而语言模型不能很好地直接产生这种理解,所以,该任务通过预训练一个二分类的模型(随机替换一些句子,再基于上一句进行预测),来学习句子之间的关系。
最后,本项目将问句获取的词向量和问句中出现的实体的词频语义特征进简单拼接,作为生成式模型的输入序列。在数据集中,70%以上问句含有两个及以上实体或关系,为强调实体的重要程度所以考虑将词频语义特征加入其中。例如,输入一个问句:轩辕剑的开发商是谁?识别的实体为:轩辕剑、开发商,在理解语义信息时,根据从原文中统计的实体出现词频可以着重考虑开发商的信息。
步骤4:将步骤3返回的序列信息作为构造生成式模型的输入,然后输入到基于attention的encoder-decoder模型中。指针生成网络对于每个译码器的时间步计算一个生成概率以此来决定是从知识词表中生成单词还是从问句中复制单词,然后选择词汇构成答案。
模型选择:传统的智能问答模型往往采用抽取式的方法,这样会导致生成答案不符合阅读逻辑、若知识库中没有该实体则无法返回正确答案。因此,本发明将生成式模型与抽取式方法相结合用于智能问答中。目前的生成式方法大多是采用seq2seq结构,但这种方法在完成生成的过程中存在无法处理词汇不足和倾向于重复自己的问题。根据调查发现,指针生成网络在传统序列到序列模型的基础上提出了两个改进思想:1.通过生成器生成新单词,2.通过coverage机制来跟踪已生成的内容,可以有效防止重复。并且通过借助知识图谱技术可以有效解决指针生成网络中存在的知识覆盖率不高的问题。因此本项目采用指针生成网络结合知识图谱的方法来构造生成式模型。与之前的方式不同的是,本发明把根据解码器状态信息生成的词表融入了知识图谱中的三元组信息,将其作为知识词表,然后考虑了输入问句中的词汇概率分布和知识词表中词汇概率的分布来得到最终输出词汇的概率分布。其模型如图4所示。
模型训练描述如下:
a.基于attention的encoder-decoder模型:本项目中模型的编码器部分使用bilstm模型。bilstm模型可以捕捉原文本的长距离依赖关系以及位置信息,因此可以更好的理解用户输入问句的意图。在模型的解码部分使用lstm模型。其具体流程描述如下:问句通过bert和词频语义特征拼接以后生成新的输入序列,再和word2vec训练知识图谱三元组得到的词向量一起作为输入将输入序列输入到bilstm编码器,然后经过单层bilstm后生成隐层状态hi,在t时刻lstm解码器接收到上一时刻生成的词向量,得到解码状态序列st。再将编码器与解码器的状态计算后得到注意力分布at,以此来确定该时间步需要关注的字符。其公式如下:
at=softmax(et)公式(8)
其中vt表示注意力机制的系数矩阵,wh、ws、wk表示通过训练得到的系数参数,kt表示当前问句中对应实体的排序最高的知识图谱三元组的选择向量;
得到的注意力权重和加权求和得到重要的上下文向量
其中
b.指针网络:当该模型用作生成单词时,模型生成的单词是在知识词表中生成的。其概率分布由解码状态序列st和上下文向量
p(w)=pvocab(w)公式(11)
其中,式中的v'vbb'是通过学习获得的参数,p(w)表示在当前时刻生成单词是知识词表中单词w的概率。
当模型用作复制单词时,它根据t时刻的注意力分布at来决定指向输入序列中单词w的概率,描述公式如下:
最后词汇分布的生成就由输入词概率分布和知识词表概率分布通过生成概率pgen来决定是从问句中复制单词还是从知识词表中生成单词,描述公式如下:
其中向量
最后通过pgen对词汇分布和注意力分布加权平均,得到生成单词w最终的概率分布,描述公式如下:
p(w)=pgenpvocab(w)+(1-pgen)pa(w)公式(14)
由上式可知,当单词w不出现在知识词表上时pvocab(w)=0,当单词w不出现在问句中pa(w)=0。
c.coveragemechanism:为了解决重复生成文本的问题,本项目引入了coveragemechanism。其实现过程如下:将之前时间步中的注意力权重累加得到覆盖向量ct。然后使用之前的注意力权重的值来解决当前注意力权重的决定,以此来避免在同一个位置产生重复,从而避免了重复生成的文本。ct的计算公式如下:
将其添加到注意力权重的计算过程,其计算公式如下:
同时,为coveragevector添加损失,其计算公式如下:
由于这样的coverageloss是一个有界的量
最后通过上述操作决定生成或者复制单词用作答案返回。
未经可视化的问答结果如下:
智能问答部分结果如下:
1、问句:17世纪法国古典主义最重要的喜剧作家是谁?
返回答案:17世纪法国古典主义喜剧作家是莫里哀。
2、问句:《挪威的森林》是哪位日本作家的著名小说作品?
返回答案:《挪威的森林》是村上春树的作品。
3、问句:万里长城西端终点在哪里?
返回答案:嘉峪关是万里长城西端终点。
最后经过可视化操作的结果图如图6所示。
实施例3
步骤1:使用jieba分词工具对webqa数据集(原文,问句,答案)中的原文和问句部分进行分词并检查;
步骤2:对正确分词后的数据使用bilstm-crf方法进行命名实体识别;
步骤3:在neo4j数据库中查询识别的实体对应的三元组;
步骤4:统计对应三元组中每一词出现的频率,查询到的三元组中的单词按照词频大小顺序存入知识词表;
步骤5:使用深度学习方法获取问句的词向量;
步骤6:构造生成式模型,返回答案。
进一步的,针对步骤1,使用jieba分词对数据集中的原文和问句进行分词,并去除停用词和标点符号。
进一步的,针对步骤2,命名实体识别方法是bilstm-crf。
进一步的,针对步骤3,对步骤2中识别出的实体使用cypher语句在neo4j图数据库中进行查询,返回查询的实体和关系。其中,使用的知识库为cn-dbpedia。
进一步的,针对步骤4,使用tf算法分别计算步骤3中每个单词在数据集中出现的频率,按照频率进行排序统一存入知识词表中。
进一步的,针对步骤5,使用预训练语言模型bert获取问句的词向量再和问句中实体的词频语义特征进行拼接,作为下一模型的输入序列。
进一步的,针对步骤6,使用指针生成网络模型来决定是从知识词表中生成词汇还是从问句中复制词汇作为答案返回。
应说明的是,以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!