基于多粒度过滤的日志数据收集方法及系统与流程
本公开涉及数据处理技术领域,具体涉及基于多粒度过滤的日志数据收集方法及系统。
背景技术:
用户终端在运作时都会产生一个叫log的事件记录;每一行日志都记载着日期、时间、使用者及动作等相关操作的描述,日志包括很多种类,如应用程序日志、安全日志、系统日志等等。用户在用户终端上进行操作时,这些日志文件通常会记录下用户操作的一些相关内容,这些内容对系统安全工作人员相当有用。举例来讲,有人对系统进行了ipc探测,系统就会在安全日志里迅速地记下探测者探测时所用的ip、时间、用户名等,用ftp探测后,就会在ftp日志中记下ip、时间、探测所用的用户名等。
现有的日志数据往往通过人工进行归类整理,这无疑是一个庞大的工作,需要大量的人力物力,甚至对于一些归类粒度复杂的日志来说,人工处理就更为麻烦了。
技术实现要素:
本公开提供基于多粒度过滤的日志数据收集方法及系统,以解决现有技术中所存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
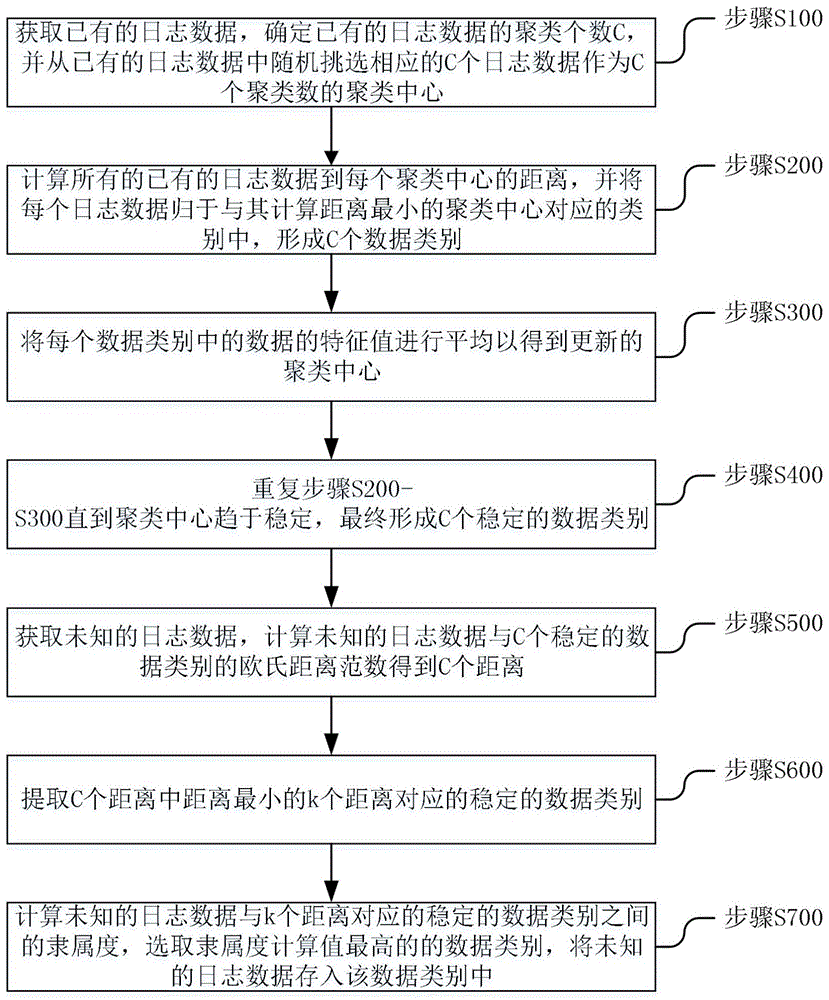
为了实现上述目的,根据本公开的一方面,提供基于多粒度过滤的日志数据收集方法,所述方法包括以下步骤:
s100,获取已有的日志数据,确定已有的日志数据的聚类个数c,并从已有的日志数据中随机挑选相应的c个日志数据作为c个聚类数的聚类中心vi,i∈[1,c];
s200,计算所有的已有的日志数据到每个聚类中心的距离dij,并将每个日志数据归于与其计算距离最小的聚类中心对应的类别中,形成c个数据类别;
s300,将每个数据类别中的数据的特征值进行平均以得到更新的聚类中心vi";
s400,重复步骤s200-s300直到聚类中心趋于稳定,最终形成c个稳定的数据类别;
s500,获取未知的日志数据,计算未知的日志数据与c个稳定的数据类别的欧氏距离范数得到c个距离dq,其中q∈[1,c];
s600,提取c个距离中距离最小的k个距离对应的稳定的数据类别;
s700,计算未知的日志数据与k个距离对应的稳定的数据类别之间的隶属度,选取隶属度计算值最高的的数据类别,将未知的日志数据存入该数据类别中。
进一步,上述步骤s300中计算得到更新的聚类中心vi"的方法具体包括以下,
将已有的日志数据设为数据集x={x1,x2,...,xn},其中每个数据对象xj具备s个属性,即xj={xj1,xj2,...,xjs},其中xjk是数据对象xj的第k维属性,k取[1,s];
每个特征值的计算公式如下,
已有的日志数据到每个聚类中心的距离为欧氏距离,具体通过计算欧式距离的相关公式计算得出。
进一步,上述步骤s400中对于聚类中心趋于稳定的判定条件为,
为每个数据类别设定目标函数j,
其中,dij为第i个聚类中心vi与第j个数据对象xj的欧式距离。
进一步,上述步骤s700中计算未知的日志数据与k个距离对应的稳定的数据类别之间的隶属度的相关计算公式具体包括以下,
其中wi为权重调节因子,其计算公式如下,
diu指的是稳定的数据类别之间距离;
其中m表示未知的日志数据最终确定的稳定的数据类别,c表示数据类别总数,b为调整参数,人为设定,b∈[0,1]。
本发明还提出基于多粒度过滤的日志数据收集系统,所述系统包括:存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序运行在以下系统的单元中:
已有的日志数据分类单元,用于获取已有的日志数据,确定已有的日志数据的聚类个数c,并从已有的日志数据中随机挑选相应的c个日志数据作为c个聚类数的聚类中心vi,i∈[1,c];
数据类别生成单元,用于计算所有的已有的日志数据到每个聚类中心的距离dij,并将每个日志数据归于与其计算距离最小的聚类中心对应的类别中,形成c个数据类别;
聚类中心更新单元,用于将每个数据类别中的数据的特征值进行平均以得到更新的聚类中心vi";
稳定的数据类别生成单元,用于重复执行数据类别生成单元以及聚类中心更新单元直到聚类中心趋于稳定,最终形成c个稳定的数据类别;
未知的日志数据获取单元,用于获取未知的日志数据,计算未知的日志数据与c个稳定的数据类别的欧氏距离范数得到c个距离dq,其中q∈[1,c];
提取单元,用于提取c个距离中距离最小的k个距离对应的稳定的数据类别;
未知的日志数据的分类单元,用于计算未知的日志数据与k个距离对应的稳定的数据类别之间的隶属度,选取隶属度计算值最高的的数据类别,将未知的日志数据存入该数据类别中。
本公开的有益效果为:本发明提供基于多粒度过滤的日志数据收集方法及系统,通过对已有的日志数据进行聚类算法的处理进行类别的确定,对于后续的未知的日志数据经过隶属度的计算归于已经确定的类别中,能够较佳的对复杂的日志数据进行归类,方便了日志数据的管理。
附图说明
通过对结合附图所示出的实施方式进行详细说明,本公开的上述以及其他特征将更加明显,本公开附图中相同的参考标号表示相同或相似的元素,显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,在附图中:
图1所示为基于多粒度过滤的日志数据收集方法的流程图。
具体实施方式
以下将结合实施例和附图对本公开的构思、具体结构及产生的技术效果进行清楚、完整的描述,以充分地理解本公开的目的、方案和效果。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
如图1所示为根据本公开的基于多粒度过滤的日志数据收集方法的流程图,下面结合图1来阐述根据本公开的实施方式的基于多粒度过滤的日志数据收集方法。
本公开提出基于多粒度过滤的日志数据收集方法,所述方法包括以下步骤:
s100,获取已有的日志数据,确定已有的日志数据的聚类个数c,并从已有的日志数据中随机挑选相应的c个日志数据作为c个聚类数的聚类中心vi,i∈[1,c];
s200,计算所有的已有的日志数据到每个聚类中心的距离dij,并将每个日志数据归于与其计算距离最小的聚类中心对应的类别中,形成c个数据类别;
s300,将每个数据类别中的数据的特征值进行平均以得到更新的聚类中心vi";
s400,重复步骤s200-s300直到聚类中心趋于稳定,最终形成c个稳定的数据类别;
s500,获取未知的日志数据,计算未知的日志数据与c个稳定的数据类别的欧氏距离范数得到c个距离dq,其中q∈[1,c];
s600,提取c个距离中距离最小的k个距离对应的稳定的数据类别;
s700,计算未知的日志数据与k个距离对应的稳定的数据类别之间的隶属度,选取隶属度计算值最高的的数据类别,将未知的日志数据存入该数据类别中。
本实施方式通过对已有的日志数据进行聚类算法的处理进行类别的确定,对于后续的未知的日志数据经过隶属度的计算归于已经确定的类别中,能够较佳的对复杂的日志数据进行归类,方便了日志数据的管理。
作为本发明的优选实施方式,上述步骤s300中计算得到更新的聚类中心vi"的方法具体包括以下,
将已有的日志数据设为数据集x={x1,x2,...,xn},其中每个数据对象xj具备s个属性,即xj={xj1,xj2,...,xjs},其中xjk是数据对象xj的第k维属性,k取[1,s];
每个特征值的计算公式如下,
已有的日志数据到每个聚类中心的距离为欧氏距离,具体通过计算欧式距离的相关公式计算得出。
作为本发明的优选实施方式,上述步骤s400中对于聚类中心趋于稳定的判定条件为,
为每个数据类别设定目标函数j,
其中,dij为第i个聚类中心vi与第j个数据对象xj的欧式距离。
作为本发明的优选实施方式,上述步骤s700中计算未知的日志数据与k个距离对应的稳定的数据类别之间的隶属度的相关计算公式具体包括以下,
其中wi为权重调节因子,其计算公式如下,
diu指的是稳定的数据类别之间距离;
其中m表示未知的日志数据最终确定的稳定的数据类别,c表示数据类别总数,b为调整参数,人为设定,b∈[0,1]。
本发明还提出基于多粒度过滤的日志数据收集系统,所述系统包括:存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序运行在以下系统的单元中:
已有的日志数据分类单元,用于获取已有的日志数据,确定已有的日志数据的聚类个数c,并从已有的日志数据中随机挑选相应的c个日志数据作为c个聚类数的聚类中心vi,i∈[1,c];
数据类别生成单元,用于计算所有的已有的日志数据到每个聚类中心的距离dij,并将每个日志数据归于与其计算距离最小的聚类中心对应的类别中,形成c个数据类别;
聚类中心更新单元,用于将每个数据类别中的数据的特征值进行平均以得到更新的聚类中心vi";
稳定的数据类别生成单元,用于重复执行数据类别生成单元以及聚类中心更新单元直到聚类中心趋于稳定,最终形成c个稳定的数据类别;
未知的日志数据获取单元,用于获取未知的日志数据,计算未知的日志数据与c个稳定的数据类别的欧氏距离范数得到c个距离dq,其中q∈[1,c];
提取单元,用于提取c个距离中距离最小的k个距离对应的稳定的数据类别;
未知的日志数据的分类单元,用于计算未知的日志数据与k个距离对应的稳定的数据类别之间的隶属度,选取隶属度计算值最高的的数据类别,将未知的日志数据存入该数据类别中。
在本实施方式中,因为应用了本发明的相关方法,通过对已有的日志数据进行聚类算法的处理进行类别的确定,对于后续的未知的日志数据经过隶属度的计算归于已经确定的类别中,能够较佳的对复杂的日志数据进行归类,方便了日志数据的管理。
所述基于多粒度过滤的日志数据收集系统可以运行于桌上型计算机、笔记本、掌上电脑及云端服务器等计算设备中。所述基于多粒度过滤的日志数据收集系统,可运行的系统可包括,但不仅限于,处理器、存储器。本领域技术人员可以理解,所述例子仅仅是基于多粒度过滤的日志数据收集系统的示例,并不构成对基于多粒度过滤的日志数据收集系统的限定,可以包括比例子更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述基于多粒度过滤的日志数据收集系统还可以包括输入输出设备、网络接入设备、总线等。
所称处理器可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等,所述处理器是所述基于多粒度过滤的日志数据收集系统运行系统的控制中心,利用各种接口和线路连接整个基于多粒度过滤的日志数据收集系统可运行系统的各个部分。
所述存储器可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现所述基于多粒度过滤的日志数据收集系统的各种功能。所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
尽管本公开的描述已经相当详尽且特别对几个所述实施例进行了描述,但其并非旨在局限于任何这些细节或实施例或任何特殊实施例,从而有效地涵盖本公开的预定范围。此外,上文以发明人可预见的实施例对本公开进行描述,其目的是为了提供有用的描述,而那些目前尚未预见的对本公开的非实质性改动仍可代表本公开的等效改动。
- 还没有人留言评论。精彩留言会获得点赞!