基于数据挖掘的蜗轮加工精度自愈模型及方法
本发明涉及机械自动加工技术领域,特别是一种基于数据挖掘的蜗轮加工精度自愈模型及方法。
背景技术:
蜗轮及齿轮的最终成形精度,直接影响传递运动准确性、平稳性及载荷分布的均匀性,其自身精度越高,传递运动精度越高,机械效率越高,承载能力越强,耐磨性越好,疲劳寿命越长,机械震动和噪声越小,传动系统功重比值越小。高精度的蜗轮及齿轮是大型、高速、重载、低噪音传动必需的基础件,要使汽车、机车车辆、农机、工程机械、矿山设备等装备性能得到大幅度提升,就必须依赖蜗轮及齿轮等传动件制造精度的提高和材料性能改善。为了提升蜗轮及齿轮加工精度,学者及加工工艺人员做了许多研究与尝试。
现有技术中往往是通过建立齿轮加工机床的误差模型来对加工精度进行理论分析。陶晓杰分析了六轴数控齿轮加工机床的各项运动,利用齐次坐标变换的方法建立了六轴数控齿轮加工机床的误差模型;黄强采用将多体系统理论与齿轮啮合原理相结合的方法建立了齿轮加工机床全误差模型,为提高误差模型在实际工程应用中的可操作性;赵江坤研究了齿轮加工机床传动部件制造装配误差对机床传动链误差的影响规律,从全局机电耦合的角度,建立了刀架传动链系统的机电耦合模型。加工及工艺人员往往通过积累的经验或查阅手册选择设备、确定切削参数等来制定工艺方案时,这样制定的工艺方案可能并不能达到质量要求,还需要不断通过试制进行验证调整,浪费大量时间和成本。
近年来随着数据挖掘技术的发展,一些学者利用数据挖掘的技术在试制或实际生产前对零件加工质量进行提前预测,帮助工艺人员选择更合理的设备、确定切削参数等,减少试制次数,在实际生产中有着重大应用价值。刘茂福学者采用优化的模糊推理系统预测磨削质量,并取得了良好的效果;zhou等学者构建了一种多输出支持向量机方法预测炼铁工艺的质量;novik等学者在布朗滤波器、人工神经网络和模糊推理系统的基础上,提供了预测平板玻璃生产质量的模型和方法。
因此,需要一种能基于海量零件加工数据的高精度的机械加工模型及其方法。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于数据挖掘的蜗轮加工精度自愈模型及方法,该模型及方法为高精度的机械加工质量预测和诊断提供依据。
为达到上述目的,本发明提供如下技术方案:
本发明提供的基于数据挖掘的蜗轮加工精度自愈模型,包括加工数据物理世界提取单元、加工质量数据仓库、加工质量规则生成单元和加工质量预测单元;
所述加工数据物理世界提取单元,所述加工数据提取单元用于获取加工件加工数据,所述加工数据包括静态数据和动态数据;
所述加工质量数据仓库,所述加工质量数据仓库用于存储加工件加工质量数据,所述加工质量数据包括加工件的加工工艺及制造参数;
所述加工质量规则生成单元,所述加工质量规则生成单元用于对加工质量数据进行聚类分析,计算数据仓库内所有工艺及制造参数与加工精度的相关性,筛选获取加工精度相关性参数;
所述加工质量预测单元,所述加工质量预测单元用于根据加工质量数据仓库中的加工质量数据和加工质量规则来建立加工件加工质量预测规则。
进一步,所述加工质量规则生成单元按照以下步骤进行:
对加工质量数据进行归一化处理;
对加工质量数据进行模糊聚类;
基于平均影响值分析方法获取加工质量参数与加工精度相关性排序。
进一步,所述对加工质量数据进行模糊聚类,具体按照以下步骤进行;
确定聚类类别数c和加权指标数m并按照以下公式计算判断参数:
(dik)2=||xk-vi||2=(xk-vi)ta(xk-vi);
dik表示第i个聚类中心与第k个数据点间的欧几里德距离;
xk表示第k个数据点数值;
vi表示第i组的中心位置数值;
a表示单位矩阵;
按照以下公式计算参数uik、参数vi;
其中,djk表示第j个聚类中心与第k个数据点间的欧几里德距离
1≤i≤c,1≤k≤n;
当||ul+1-ul||≤ε,迭代停止,获得加工质量数据聚类结果;
ul+1表示第l+1次迭代的uik值,ε表示预先设定可接受差值。
进一步,所述加工质量预测单元按照以下步骤建立:
建立广义回归神经网络grnn模型;
按照以下公式确定模型的核函数:
k(xi,xj)=exp{-g|xi-xj|2},(g>0)(10)
其中,g是核函数参数;
根据gwo确定模型中的光滑因子σ。
进一步,所述广义回归神经网络grnn模型是由多组训练集通过机器学习训练得出的,所述多组数据是从加工质量数据仓库中筛选出的加工质量敏感参数数据。
本发明提供的基于数据挖掘的蜗轮加工精度自愈方法,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以下步骤:
从加工数据物理世界获取加工件加工数据,所述加工数据包括静态数据和动态数据;
存储加工件加工质量数据构建加工质量数据仓库,所述加工质量数据包括加工件的加工工艺及制造参数;
对加工质量数据进行聚类分析构建加工质量规则生成单元,计算数据仓库内所有工艺及制造参数与加工精度的相关性,筛选获取加工精度相关性参数;
根据加工质量数据仓库中的加工质量数据和加工质量规则来建立加工件加工质量预测规则构建加工质量预测单元。
进一步,所述加工质量规则生成单元按照以下步骤进行:
对加工质量数据进行归一化处理;
对加工质量数据进行模糊聚类;
基于平均影响值分析方法获取加工质量参数与加工精度相关性排序。
进一步,所述对加工质量数据进行模糊聚类,具体按照以下步骤进行;
确定聚类类别数c和加权指标数m并按照以下公式计算判断参数:
(dik)2=||xk-vi||2=(xk-vi)ta(xk-vi);
dik表示第i个聚类中心与第k个数据点间的欧几里德距离;
xk表示第k个数据点数值;
vi表示第i组的中心位置数值;
a表示单位矩阵;
按照以下公式计算并根据参数uik更新参数vi;
其中,djk表示第j个聚类中心与第k个数据点间的欧几里德距离
1≤i≤c,1≤k≤n;
当||ul+1-ul||≤ε,迭代停止,获得加工质量数据聚类结果;
ul+1表示第l+1次迭代的uik值。
进一步,所述加工质量预测单元按照以下步骤建立:
建立广义回归神经网络grnn模型;
按照以下公式确定模型的核函数:
k(xi,xj)=exp{-g|xi-xj|2},(g>0)(10)
其中,g是核函数参数;
根据gwo确定模型中的核函数g和惩罚因子c。
进一步,所述广义回归神经网络grnn模型是由多组训练集通过机器学习训练得出的,所述多组数据是从加工质量数据仓库中筛选出的加工质量敏感参数数据。
本发明的有益效果在于:
本发明提供的基于数据挖掘的蜗轮加工精度自愈模型及方法,通过建立分析型蜗轮加工质量数据仓库,建立加工质量规则算法,实现蜗轮加工质量预测及自愈调整。该方法充分利用制造业企业积累的大量的零件加工数据,并从海量的数据中挖掘人机料法环测与质量之间的规则关系,利用挖掘出的规则知识,为产品的工艺制定、生产安排等环节提供决策支持,为质量预测及诊断提供依据。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
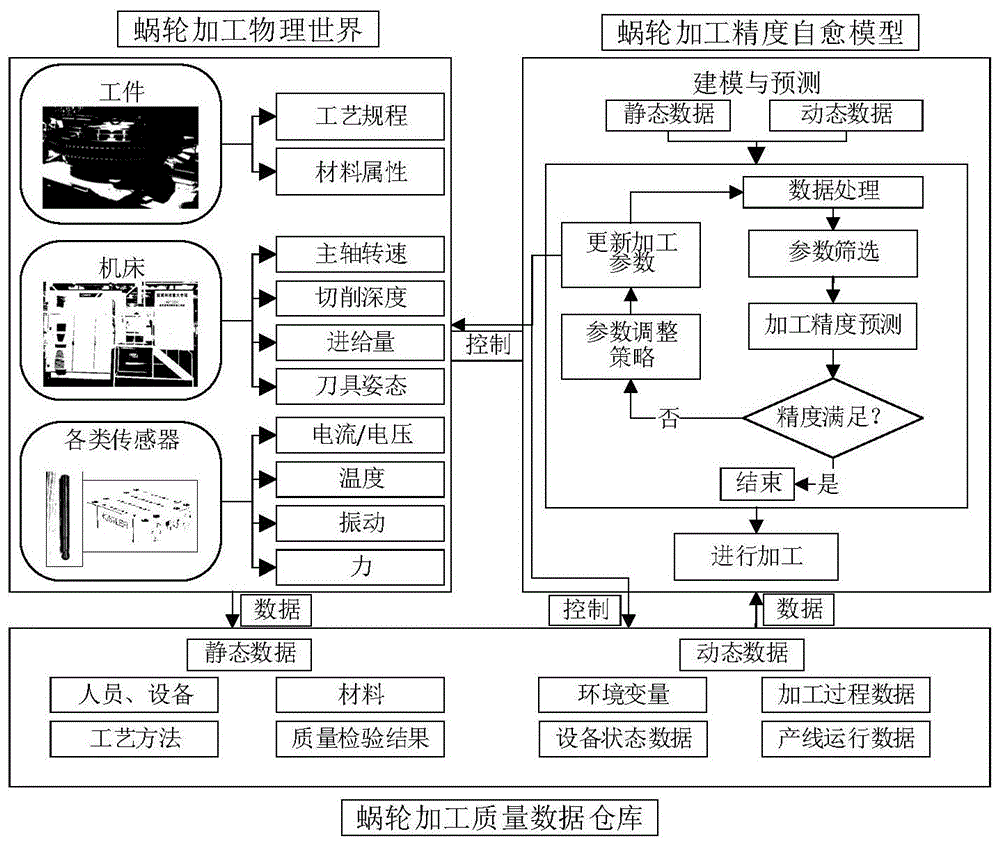
图1为基于数据挖掘的蜗轮加工精度自愈模型示意图。
图2为gwo优化广义回归神经网络grnn模型参数的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好的理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
实施例1
如图1所示,图1为基于数据挖掘的蜗轮加工精度自愈模型示意图,包括加工数据物理世界提取单元、加工质量数据仓库、加工质量规则生成单元和加工质量预测单元;
所述加工数据物理世界提取单元,所述加工数据提取单元用于获取加工件加工数据,所述加工数据包括静态数据和动态数据;
所述加工质量数据仓库,所述加工质量数据仓库用于存储加工件加工质量数据,所述加工质量数据包括加工件的加工工艺及制造参数;本步骤是从物理世界获得的静态动态数据;
所述加工质量规则生成单元,所述加工质量规则生成单元用于对加工质量数据进行聚类分析,计算数据仓库内所有工艺及制造参数与加工精度的相关性,筛选获取加工精度相关性参数;
所述加工质量预测单元,所述加工质量预测单元用于根据加工质量数据仓库中的加工质量数据和加工质量规则来建立加工件加工质量预测规则。
本实施例提供的加工质量规则生成单元按照以下步骤进行:
对加工质量数据进行归一化处理;
对加工质量数据进行模糊聚类;
基于平均影响值(meanimpactvalue,miv)分析方法获取加工质量参数与加工精度相关性排序。
本实施例提供的对加工质量数据进行模糊聚类,具体按照以下步骤进行;
确定聚类类别数c和加权指标数m并按照以下公式计算判断参数:
(dik)2=||xk-vi||2=(xk-vi)ta(xk-vi);
dik表示第i个聚类中心与第k个数据点间的欧几里德距离;
xk表示第k个数据点数值;
vi表示第i组的中心位置数值;
a表示单位矩阵;
按照以下公式计算参数uik、参数vi;
其中,
djk表示第j个聚类中心与第k个数据点间的欧几里德距离;1≤i≤c,1≤k≤n;
m表示聚类组总数;
n表示数据点总数;
当||ul+1-ul||≤ε,迭代停止,获得加工质量数据聚类结果;
ul+1表示第l+1次迭代的uik值;
ε表示表示预先设定可接受差值。
本实施例提供的所述加工质量预测单元按照以下步骤建立:
建立广义回归神经网络grnn模型;
按照以下公式确定模型的核函数:
k(xi,xj)=exp{-g|xi-xj|2},(g>0)
其中,g是核函数参数;
根据gwo确定模型中的光滑因子σ。
本实施例提供的所述广义回归神经网络grnn模型是由多组训练集通过机器学习训练得出的,所述多组数据是从加工质量数据仓库中筛选出的加工质量敏感参数数据。
实施例2
本实施例提供的基于数据挖掘的蜗轮加工精度自愈方法,包括以下步骤:
建立蜗轮加工质量数据仓库,将积累的海量工艺及制造数据按仓储规则导入其中,进行存储;
对参数数目较多的特定加工质量参数利用fcm进行聚类分析,并计算数据仓库内所有工艺及制造参数与加工精度的相关性,筛选获取加工精度高相关性参数;
并基于已有加工数据获取人机料法环测与蜗轮加工质量之间的预测规则关系;
当一批加工需求提出后,则可根据已建立的蜗轮加工质量规则获取当前加工条件下的预计加工精度,之后基于梯度下降法gd对可调整核心参数进行优化调整,实现加工精度自愈。
本实施例提供的加工件可以是蜗轮,利用蜗轮轮加工质量数据进行加工精度进行预测和诊断,也可以选用其他的加工件如齿轮、螺钉、螺母、螺栓、各种弹簧等,这里不多赘述。
构建加工质量规则,具体步骤如下:
筛选关键加工质量参数:蜗轮加工质量数据仓库中保存有大量与蜗轮加工精度相关的工艺参数及过程测量数据,加工质量数据包括静态数据和动态数据;这些数据与最终蜗轮加工精度存在强度不一的相关性,如果将这些数据全部输入蜗轮加工精度自愈模型中,必然会降低模型的准确性和效率,因而需要筛选出与蜗轮加工精度相关性更强的加工质量参数数据。
利用fcm进行大体量数据内部聚类筛选:模糊c均值聚类fcm是由e.ruspini提出的一种无监督的模糊聚类方法,是一种基于目标函数的模糊聚类算法,主要用于数据的聚类分析。理论成熟,应用广泛,是一种优秀的聚类算法。利用该方法,可以分辨哪些加工质量数据对最终蜗轮加工精度影响更大。
fcm的目标函数可表示为:
其中,
uik表示dik的隶属度,uik介于(0,1)之间,
j(u,v)表示,u为模糊分类矩阵;v为聚类中心合集;
m为加权指数;
n表示数据点数;
c表示聚类类别数;
k表示第k个数据点;
i表示第i个聚类中心;
(dik)2=||xk-vi||2=(xk-vi)ta(xk-vi)为第i个聚类中心与第k个数据点间的欧几里德距离;
xk表示第k个数据点数值;
vi表示第i组的中心位置数值;
a表示单位矩阵;
本实施例中的算法的目的即为使j(u,v)最小化;
利用拉格朗日乘数法优化该目标函数,并构造如下函数:
其中,l(a)表示构造的拉格朗日函数;a表示拉格朗日乘数法构造参数;
并将判断参数转换如下:
其中,djk表示第j个聚类中心与第k个数据点间的欧几里德距离;
1≤i≤c,1≤k≤n;
由上述两个必要条件可实现该目标函数最小化。
平均影响值(meanimpactvalue,miv)分析方法常被应用于神经网络问题中,是评估网络输入变量对输出变量影响的最佳工具之一,通过对输入变量取值进行调整,观察输出变量变化情况,从而得到输入变量与输出变量之间的相关性。本实施例采用miv方法选取模糊聚类后各类组中具有代表性的温度变量。具体步骤如下:
(1)初始化神经网络结构
(2)对于模型独立输入变量xi,在其原始值基础上分别增加和减小a%,生成新的输入变量xi1和xi2。
(3)保持其他输入变量不变,分别将变量xi1和xi2输入神经网络中,相应获得两个输出yi1和yi2。
(4)计算输出变量yi1和yi2的差值,该值即为输入xi的影响值(iv)。将计算得到的影响值iv除以xi1和xi2的差值,并取绝对值,获得xi的平均影响值(miv)。
(5)根据平均影响值绝对值,对输入变量与输出变量相关性进行排序,获取代表性输入变量。
筛选高相关性加工质量参数:数据仓库中的各类加工质量数据处于不同的数据维度,直接进行比较筛选无法表征其与加工精度的真实关系,同时影响计算效率,为了提高计算的准确性和效率,故需要对加工质量数据样本进行归一化处理,本实施例将训练集规范化为[0,1]。其计算公式如下:
式中,
x’i和xi分别为归一化前后的数据;
综上所述,则加工质量规则获取过程如下:
1.进行数据仓库加工质量数据归一化处理;
2.对数据条目规模较大的加工质量数据进行模糊聚类;
确定聚类类别数c和加权指标数m;
根据uik更新vi;
根据公式3更新uik;
当||ul+1-ul||≤ε,迭代停止,获得数据聚类结果。
ul+1表示第l+1次迭代的uik值
3.全范围筛选加工质量参数:基于平均影响值(meanimpactvalue,miv)分析方法获取加工质量参数与加工精度相关性排序,模糊聚类分组参数只选取组内“相关性”最高的参数作为代表参数。
本实施例提供的建立人机料法环测与蜗轮加工质量的预测规则,具体如下:
广义回归神经网络(grnn)具有很强的非线性映射能力,适用于求解线性和非线性回归问题。该算法对大样本和小样本数据都有较好的收敛速度。其求解公式可表示为
式中,
广义回归神经网络由四个层次结构组成,分别为输入层、模式层、求和层和输出层。在输入层,神经元接收输入向量,并将其传输到模式层。在模式层,传输来的向量将被进行非线性转换处理,然后存入模式层神经元。输入层神经元数和模式层神经元数分别等于输入向量的维数和学习样本的个数。所进行的非线性变换中使用的高斯函数表示为
式中,σ表示参数光滑因子;
在求和层中,求和单元sd为模式层中所有神经元输出的算术求和,连接权值为1。求和单元sn计算模式层中所有神经元输出的加权求和,连接权值为yi。故该层中传递函数可表示为
在输出层中,神经元的数目由输出向量
将数据仓库中筛选出的加工质量敏感参数数据作为该预测模型的输入,蜗轮加工精度作为该预测模型的输出,进行蜗轮加工精度的预测。其中,将加工质量敏感参数数据划分为训练集与测试集,训练集描述了影响蜗轮加工精度的因素,并建立了决策函数;测试集用于评估由训练集建立的决策函数的准确性。
广义回归神经网络模式层中高斯函数中的光滑因子是该算法中需要预先设置的参数,对算法的预测性能和泛化性能有明显影响。如果光滑因子过大,高斯函数会过于平滑,导致拟合结果较差,预测性能较差。如果平滑因子过小,高斯函数会变尖锐,算法会过拟合。因此,合适的平滑参数值对grnn的性能至关重要。高斯函数可表示为
式中,σ表示参数光滑因子;
基于灰狼算法gwo优化参数σ。灰狼优化算法是mirjalilis于2014年提出的一种基于智能种群的优化算法。与其他群智能搜索算法相比,gwo具有更快的收敛速度、更高的精度和稳定性。因此,本实施例用它来选择最佳的c和g。
在该算法中,灰狼种群个体所处的位置参数即为解的数值,种群内最优的三个解被命名为α、β和δ,其余灰狼个体被命名为ω;在灰狼算法中,灰狼个体的包围行为如下:
式中,
t代表当前迭代次数;
被命名为ω的灰狼个体会依据α、β和δ的位置信息更新自身的位置信息,数学表达式如下:此处公式做了改动
其中,
由gwo优化grnn模型参数的流程如图所示,首先确认模型输入输出,划分测试集和训练集,并选择模型预测精度作为适应度函数,将训练数据输入gwo算法,得到最优的g和c,用于构件蜗轮加工精度预测模型。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!