一种舆情事件中社交媒体用户角色分类方法
本发明涉及在线社交媒体中角色分类
技术领域:
,具体涉及一种舆情事件中社交媒体用户角色分类方法。
背景技术:
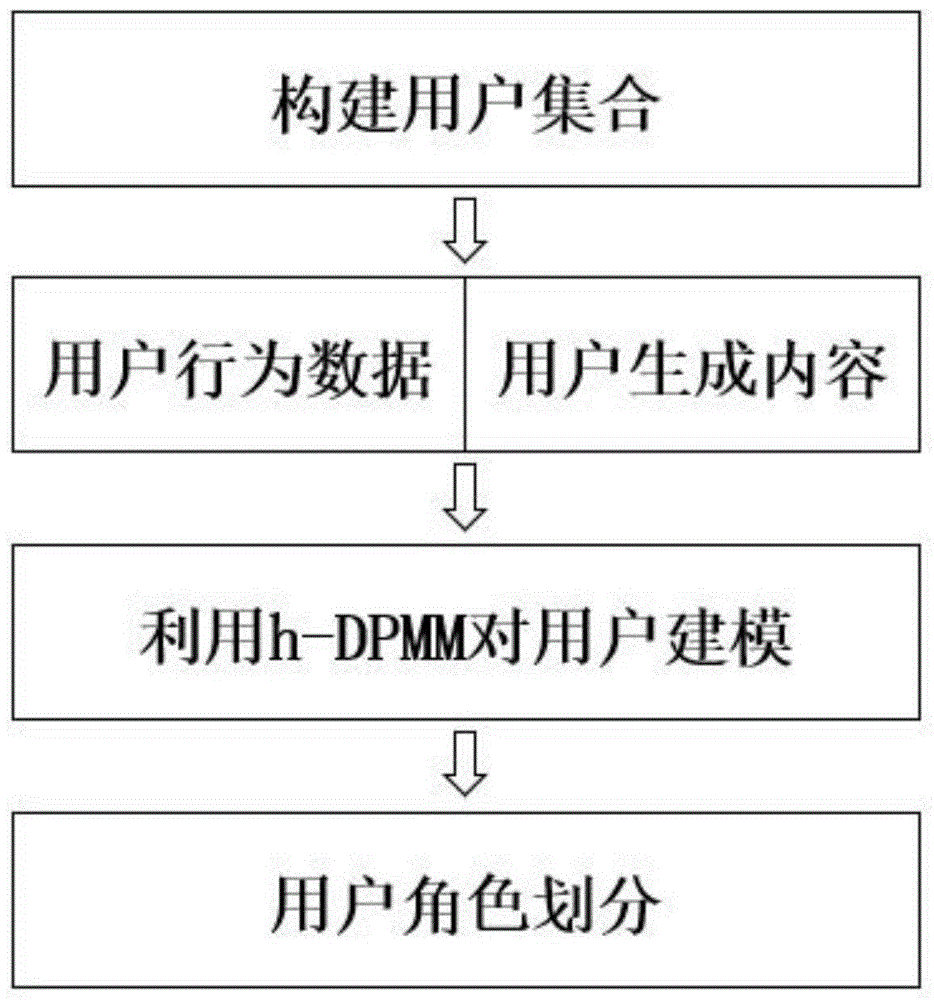
:在线社交媒体平台极大的丰富了人们产生、分享和消费知识与信息的方式,成为人们生产和传播信息的主要媒介。研究表明,用户生成内容是表达自身兴趣与态度等内在特质的重要手段。同时,用户产生内容也展示了用户自身的生活习惯与在整个社会化网络平台中的角色。对用户进行角色分类对社交网络中不同类型的用户进行分类具有重要意义。现有技术对在线媒体中用户进行角色分类时,大多依据用户的行为数据进行角色分类,忽略了用户的生成内容,没有综合利用用户生成内容以及用户行为数据这两种重要的反映用户角色的信息,导致角色类型划分不够准确;与此同时,现有的角色分类方法需要预定义角色的数量,但是随着社交网络的发展,预定义角色的数量为角色分类带来了很大的困难;此外,现有模型多将每个用户视为具有相同特征结构的单个数据点,其中每个用户的特征信息并不包含任何用户行为或其他属性的信息,因此它不足以分析社交媒体中大量的行为数据。技术实现要素:本发明为了克服现有技术存在的不足之处,提出一种舆情事件中社交媒体用户角色分类方法,以期能结合社交媒体中用户的生成内容和用户行为进行用户角色分类,从而能够自动确定社交网络中的真实角色数量,提高社交网络中用户分类的全面性、准确性和精确性。本发明为达到上述发明目的,采用如下技术方案:本发明一种舆情事件中社交媒体用户角色分类方法的特点是按如下步骤进行:步骤1、获取社交媒体中的用户信息:步骤1.1、构建用户集合u∈{1,2,...,u...,|u|},其中,u表示用户的序号,|u|表示社交媒体中用户的数量;步骤1.2、获取社交媒体中|u|个用户的行为数据,其中,所述用户集合u中第u个用户的行为数据包括:第u个用户关注的用户数量关注第u个用户的用户数量以及第u个用户发布的文本数量mu;步骤1.3、获取社交媒体中|u|个用户发布的文本信息,并去除所有停用词后,构成文本集合;其中,第u个用户去除停用词后所对应的文本信息,记为wu,n表示第u个用户的文本信息中第n个词,nu表示文本信息中的词总数;步骤2、基于社交媒体中用户的行为数据和文本信息,构建非参贝叶斯模型-混合狄利克雷过程混合模型h-dpmm:步骤2.1、对于社交媒体中的第u个用户,按照式(1)生成第u个用户对应的角色ru:ru~multinomial(π),π~dirichlet(α)(1)式(1)中,~表示服从,multinomial(·)表示多项式分布,dirichlet(·)表示狄利克雷分布,π表示多项式分布的超参数,α表示狄利克雷分布的超参数;步骤2.2、对于社交媒体中的第u个用户,按照式(2)生成第u个用户的主题分布θu:θu~multinomial(ρk),ρk~dirichlet(α1)(2)式(2)中,ρk表示第k个角色对应的主题分布,且k∈{1...k}表示角色索引,α1表示狄利克雷分布的超参数;步骤2.3、对于社交媒体中的第u个用户,按照式(3)生成第u个用户的行为特征vu:vu~guassian(ηk),ηk~inv-wishart(α2)(3)式(3)中,guassian(·)表示高斯分布,inv-wishart(·)表示逆威沙特分布,ηk表示第k个角色对应的行为分布,α2表示逆威沙特分布的超参数;步骤3、基于通过社交媒体中观察到的用户集合u,设计吉布斯采样,对用户的角色分布进行参数推断:步骤3.1、初始化u=1;步骤3.2、假设当前采样角色的用户为用户集合u中的第u个用户,并根据式(4)依次采样第u个用户的角色ru:式(4)中,r表示在当前采样过程之前已经出现的某个角色,表示当前采样过程之前未出现的一个新角色,cr表示第r个角色中的用户数量,表示除第u个用户的角色ru外的角色;δ(ru,r)为指示函数,如果ru是一个已经出现的角色r,则令δ(ru,r)=1,否则令δ(ru,r)=0;如果ru是一个新的角色则令否则令fexisting(u|ηk,ρk,ru=k)表示第u个用户分配到已经出现的第k个角色的条件概率,fnew(u|α,αt,αb)表示第u个用户分配到未出现的新角色的条件概率;步骤3.3、将u+1赋值给u,并返回步骤3.2执行,直到u=|u|为止;从而为每个用户分配角色并得到角色分类结果;步骤3.4、重复步骤3.1-步骤3.3的采样过程,从而更新每个用户所分配的角色,并更新第k个角色对应的行为分布ηk和第k个角色对应的主题分布ρk,当所有用户的角色不再变化,且角色分类结果不变时,输出最终的所有角色的行为分布和主题分布;其中,最终的第k个角色对应的行为分布记为最终的第k个角色对应的主题分布记为步骤4、根据最终的所有角色的行为分布和主题分布,对社交媒体中用户进行角色分类。与已有技术相比,本发明有益效果体现在:1、本发明考虑了在线社交媒体中的用户特点,发现用户生成内容是表达自身兴趣与态度等内在特质的重要手段,全面结合社交媒体中用户的行为数据和用户生成内容共同进行角色分类,将角色建模为高斯分布和多项式分布的联合分布,分别表示用户行为特征和产生的内容特征,从而能够自动确定社交网络中的真实角色数量,实现了对群体中角色类型全面快速且精准地分类。2、本发明提出狄利克雷过程混合模型的变体——混合狄利克雷过程混合模型,实现了对异构数据的成功融合,有效结合了用户行为数据和用户生成内容对用户进行建模,成功得到了用户的混合特征,从而能够全面地刻画用户的特征,解决了当前对社交媒体中用户角色分类不全面的问题。3、本发明采用吉布斯采样进行参数推断,适用于更精确的探索用户角色分类,更高效、更准确、更容易扩展到大数据,从而在应对大规模用户集合时能够更快速地进行角色分类,自动确定社交网络中的真实角色数量,进而提升了角色分类方法的效率。附图说明图1为本发明的实施流程图;图2为本发明提出的混合狄利克雷过程混合模型h-dpmm(hybriddirichletprocessmixturemodel)图;图3是本发明划分的角色在影响力特性上细化特征的对比统计图;图4是本发明划分的角色在社交互动性上细化特征的对比统计图;图5是本发明划分的角色在社交活动性上细化特征的对比统计图。具体实施方式本实施例中,一种舆情事件中社交媒体用户角色分类方法,是首先识别社交网络中每个用户的特征:其中包括基于动机理论的行为特征识别(社会影响力、社交互动、社交活动)和基于用户生成内容的主题偏好识别;然后利用混合狄利克雷过程混合模型,对异构数据进行融合,有效结合用户行为数据和用户生成内容对用户进行建模,从而得到用户的混合特征,最后实现社交媒体中用户角色的划分。具体的说,如图1所示,是按如下步骤进行:步骤1、获取社交媒体中的用户信息:步骤1.1、构建用户集合u∈{1,2,...,u...,|u|},其中,u表示用户的序号,|u|表示社交媒体中用户的数量;步骤1.2、获取社交媒体中|u|个用户的行为数据,其中,所述用户集合u中第u个用户的行为数据包括:第u个用户关注的用户数量关注第u个用户的用户数量以及第u个用户发布的文本数量mu;步骤1.3、获取社交媒体中|u|个用户发布的文本信息,并去除所有停用词后,构成文本集合;其中,第u个用户去除停用词后所对应的文本信息,记为wu,n表示第u个用户的文本信息中第n个词,nu表示文本信息中的词总数;本实施例一共爬取了微博中12553个用户以及35200179条文本信息,如表一所示为本实施例中微博数据集的用户统计信息:表一微博数据集的用户统计信息用户总数12553文本总数35200179平均每个用户关注的用户数量29517平均关注每个用户的用户数量5223平均每个用户发布的文本数量2635步骤2、基于社交媒体中用户的行为数据和文本信息,构建非参贝叶斯模型-混合狄利克雷过程混合模型h-dpmm,如图2所示:步骤2.1、对于社交媒体中的第u个用户,按照式(1)生成第u个用户对应的角色ru:ru~multinomial(π),π~dirichlet(α)(1)式(1)中,~表示服从,multinomial(·)表示多项式分布,dirichlet(·)表示狄利克雷分布,π表示多项式分布的超参数,α表示狄利克雷分布的超参数;社交网络上的角色包括有影响力的领导者、信息消费者、信息传播者、信息生产者以及潜伏者等;步骤2.2、对于社交媒体中的第u个用户,按照式(2)生成第u个用户的主题分布θu:θu~multinomial(ρk),ρk~dirichlet(α1)(2)式(2)中,ρk表示第k个角色对应的主题分布,且k∈{1...k}表示角色索引,α1表示狄利克雷分布的超参数;主题分布是指从用户生成的文本内容中发现的主题偏好,反映了用户的兴趣;步骤2.3、对于社交媒体中的第u个用户,按照式(3)生成第u个用户的行为特征vu:vu~guassian(ηk),ηk~inv-wishart(α2)(3)式(3)中,guassian(·)表示高斯分布,inv-wishart(·)表示逆威沙特分布,ηk表示第k个角色对应的行为分布,α2表示逆威沙特分布的超参数;本实施例中,基于动机理论,我们用社会影响力、社交互动以及社交活动这三个特征来度量一个用户的行为特征。其中,使用每条消息的平均评论的数量,每条消息的平均赞的数量和其关注者的数量这三个指标来衡量用户的社会影响力;使用用户发布的所有内容的平均评论数量、添加评论的时间以及关注该用户的用户数和该用户关注的用户数的比值来衡量社交互动特征;由于在在线社交网络中,信息生成和传播是两种不同的内容共享形式,因此,我们使用转发比率这一指标来衡量用户社交活动特征。步骤3、基于通过社交媒体中观察到的用户集合u,设计吉布斯采样,对用户的角色分布进行参数推断:步骤3.1、初始化u=1;步骤3.2、假设当前采样角色的用户为用户集合u中的第u个用户,并根据式(4)依次采样第u个用户的角色ru:式(4)中,r表示在当前采样过程之前已经出现的某个角色,表示当前采样过程之前未出现的一个新角色,cr表示第r个角色中的用户数量,表示除第u个用户的角色ru外的角色;δ(ru,r)为指示函数,如果ru是一个已经出现的角色r,(r到底是一个集合?还是一个角色)则令δ(ru,r)=1,否则令δ(ru,r)=0;如果ru是一个新的角色则令否则令fexisting(u|ηk,ρk,ru=k)表示第u个用户分配到已经出现的第k个角色的条件概率,fnew(u|α,αt,αb)表示第u个用户分配到未出现的新角色的条件概率;步骤3.3、将u+1赋值给u,并返回步骤3.2执行,直到u=|u|为止;从而为每个用户分配角色并得到角色分类结果;步骤3.4、重复步骤3.1-步骤3.3的采样过程,从而更新每个用户所分配的角色,并更新第k个角色对应的行为分布ηk和第k个角色对应的主题分布ρk,当所有用户的角色不再变化,且角色分类结果不变时,输出最终的所有角色的行为分布和主题分布;其中,最终的第k个角色对应的行为分布记为最终的第k个角色对应的主题分布记为步骤4、根据最终的所有角色的行为分布和主题分布,对社交媒体中用户进行角色分类。本实施例中,一共发现了25个主题,将主题的概率值从高到低排序,如下表二列出了被广泛讨论的前10个主题:表二top10主题情况设置的最大迭代次数为500,最后划分出微博用户中存在的47种不同的角色,此外删除了一些用户数少于100的角色,最后参与分析的角色编号分别为角色10、角色14、角色16、角色35、角色11、角色3、角色17、角色24、角色15、角色21、角色9、角色37、角色32、角色29;本实施例中,划分出的每个角色在体现角色影响力的三个因素:关注的用户数量、平均转发数量以及平均评论数量上的对比情况如图3所示;在体现角色互动性的三个因素:转发比率、粉丝数量以及提及其他数量上的对比情况如图4所示;在体现角色活动性的两个因素:用户水平以及微博数量上的对比情况如图5所示,其中用户水平由微博提供,是通过结合用户登录活动的频率和消息发布行为来衡量的;每种角色的用户对10个主题的关注情况如下表三所示:表三每种角色的主题关注度概率分布每种角色中用户的数量、特点以及类型如下表四所示:表四角色描述及定义表四中,展示了每种角色下的用户数量、网络行为特征描述以及角色类型定义。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1