一种基于成熟度技术的文献推荐系统及方法
本发明涉及一种改进了内容推荐算法的文献推荐系统,属于推荐算法领域。
背景技术:
随着大数据技术和机器学习科学的发展,推荐系统被越来越多的引入各大网站和应用程序中,推荐的物品也越来越多地包罗万象,比如商品,书籍,电影,音乐等。一个好的推荐系统可以精确地找到用户的兴趣点并推荐用户喜欢的物品,大大增加了系统的点击率和用户的满意度。目前在对物品进行推荐时,最常采用的方法为协同过滤的推荐方法和基于内容的推荐方法,除此之外还有准确率比较高的矩阵分解的方法和一些基于图神经网络的方法。
在众多推荐算法之中,基于内容的推荐算法是最为经典的推荐算法之一。基于内容的推荐算法主要包括以下四个步骤:
1.根据用户的浏览、购买、点击等行为计算用户特征。
2.根据物品的详细信息(如类别,型号等)计算物品特征。
3.使用用户特征和物品特征计算用户和不同物品之间的匹配度。
4.向用户推荐匹配度最高的物品。其中物品的特征统称为物品画像,人物的特征称为人物画像,物品画像和人物画像往往有几十甚至几百种,但是在不同的推荐系统中往往只会用到其中的几种。
在传统的基于内容的文献推荐系统中,系统往往会根据用户的喜好来推荐给用户他喜欢的主题下的文献。然而随着文献库的增大,同一主题下的文献数量激增,文献的难易程度不同。如果仅仅给用户推荐某个主题下的所有文献,则容易造成给初学者推荐了难度很大的前沿文献,或是给熟知该领域的专家用户推荐了过于浅显的文献的问题。
技术实现要素:
针对现有技术之不足,本发明系统设计了一种新的基于成熟度技术的文献推荐系统。本发明中文献是指可以帮助用户学习,理解,工作的论文,博客,说明书等。本文中的文献为各类以文字为载体的文本。
方法技术方案:
一种基于成熟度技术的文献推荐方法,特征是,采用了基于内容的推荐算法的基本框架;首先通过机器学习的方法分析出每篇文献的主题类别,再根据用户的浏览记录找到用户感兴趣的主题,给用户推荐他所感兴趣的主题下的文献;再在这个基础上考虑到用户在他感兴趣的领域的学习程度,根据用户的学习程度为用户设定等级;再计算出每篇文献在它所属的领域属于什么程度的文献,通过计算机的方法对文献设定等级;最后结合用户的等级和文献本身的等级为用户推荐适合他等级的文献。
系统技术方案:
一种基于成熟度技术的文献推荐系统,其特征在于,一共包括五个模块,分别是数据预处理模块、文献分类模块、计算文献等级模块、计算用户等级模块、生成各用户的推荐列表模块,模块数据交互图见附图2,其中:
计算文献等级模块和计算用户等级模块为本发明创新模块。
数据预处理模块主要得到的数据有三部分,分别是每个用户的文献阅读顺序、文献的详细内容、文献的发布时间和好评率。其中用户的文献阅读顺序提供给计算文献等级模块和计算用户等级模块;文献的详细内容提供给文献分类模块。
文献分类模块的输入是各种主题的技术文献详细内容,输出是所有文献和该文献的主题,将该输出提供给计算文献等级模块。在文献主题分类时使用了文本向量空间模型,这是一种词袋模式,不考虑词的先后顺序,然后使用tfidf统计加权技术对文献内的各个词语求权重,并且使用word2vec方法来对所有的词语进行分类。使用新的向量来表示词语。获得每篇文献的所有权重前k大的词语之后,文献之间可以两两求得相似度。使用knn的方法对文献进行聚类操作,把所有的文献一共分为k类,k的大小取决于文献库的体量,每个分类即一个主题。
计算文献等级模块的输入是各个文献及它们的主题以及用户的文献阅读顺序,输出是各个文献的等级信息,提供给计算用户等级模块。要对每个主题的文献进行等级划分,需要参考的重要特征有以下三个:
1.文献的发布时间,文献的发布时间是文献深度的重要参考,往往最新发布的文献是当前领域的比较前沿的研究。
2.文献在所有用户阅读列表中的顺序。综合各个用户在某一个主题下的阅读顺序,是最有效的给文献评级的方法,因为用户的阅读和学习顺序往往是一个由浅入深的过程,用户的阅读顺序是给文献评级的重要参考。
3.除此之外,鉴于文献的特殊属性,往往一篇好的文献是经得起时间打磨的,用户在一篇好的文献中可以收获很多,所以在给用户推荐时一篇文献的好评率也要作为参考标准。综上,本发明会首先根据每个用户阅读该主题下的文献的顺序对文献进行评级,并规整为1~10级。确定等级之后,还会根据文献的下载量和发布时间对文献进行排序,优先推荐排名高的文献给用户。
计算用户等级模块的输入是用户的阅读列表和各文献的等级信息。每个用户可能在阅读多个主题的文献,确定用户的等级时,考虑到了时间局部性的原则,即用户最近阅读的文献就是用户目前最感兴趣的主题和用户当前的等级。找到用户最近阅读的各个主题下的三篇文献,使用这三篇文献的等级平均值作为用户在当前主题下的等级。
生成各用户的推荐列表模块。该模块的输入是用户感兴趣的主题、在该主题下用户的等级和不同主题下各个文献的等级。输出是给用户的推荐列表。本推荐算法会给用户推荐一共十篇文献,其中五篇是和用户等级相同。另外五篇为等级略高一些的文献。
在有新用户加入系统时,此时系统对用户的主题和等级划分为空,可以根据用户接下来阅读的几篇文献对用户进行主题和等级的划分。而对那些新加入系统的文献,由于进入系统的时间比较晚,所以它们在用户的阅读列表中居后,所以在使用阅读顺序给这些文献划分等级会出现较大的误差。此时在确定文献的等级时,本系统选择记录阅读该文献的用户的等级。将前n个阅读该文献的用户的等级取平均值,作为文献的等级。
上述技术方案:
在考虑到技术资源内容的基础上,对技术资源进行分类并且划分主题,并将同主题的技术资源进行等级划分,等级的划分取决于该技术资源在当前分类中的“深度”,所谓深度即这篇文献的难度和适用人群的学习深度。根据用户的学习程度不同,向其推荐不同深度的学习资源。除此之外,本发明系统还充分考虑到了技术资源的发布时间问题,考虑到越是新发布的技术资源越是具有更大的参考价值和深度。最后,本发明还给出了解决冷启动问题。冷启动问题是推荐系统必须解决的问题,冷启动问题即如何向用户推荐刚加入系统的新物品并设置新物品的深度。
本文完成了对基于内容的推荐算法的改进。在原始基于内容的算法中,推荐系统致力于为每个物品找到对应的分类信息,后根据用户的访问列表生成用户的特征,并使用用户特征对应物品类别,给用户推荐符合特征的同一类别的其他物品。然而,文献有其特殊的特点,用户在学习的过程中往往伴随着一个由浅入深的过程,从基础知识开始学习逐渐深入到比较高深前沿的知识。原始的基于内容的推荐算法没有考虑到这个问题,本文在此方面做了改进。致力于找到符合用户当前学习状态的其他文献进行推荐。
除了根据用户当前的学习状态进行推荐之外,该推荐系统需要考虑文献的另一个特点,即发布时间,往往越是最近发布的文献越是当前领域里比较先进的技术。所以本文在推荐的过程中会考虑文献发布的时间信息。在确定好级别之后,给最近发布的文献更大的权重,以得到被推荐的机会。
与普通物品不同,文献的下载量也是考察当前文献是否应该被推荐的重要标准。一篇文献的下载量巨大就可以说明这篇文献的重要性。往往一篇基础类的文献是学习该方向必不可少的。所以本发明考虑了文献的下载量,给下载量更高的文献以更大的权重。
在确定用户的当前学习状态的过程中。可以使用用户在当前主题下最近阅读过得三篇文献来确定。因为用户在阅读过程中往往会发生一些噪音比较大的下载行为,比如有个基础的知识记不清,或者误下载了过于深入的文献,和当前学习状态不匹配。所以本发明中记录了用户在当前主题下下载过的最近三篇文献,除去最高值和最低值即用户目前的学习深度。
本发明对新加入的用户和物品做了特殊的处理,即能够解决推荐系统的冷启动问题,新用户和新的文献的相关信息比较少,如何精准的给这些用户和物品进行定位并且推荐是一个重要的问题。
附图说明
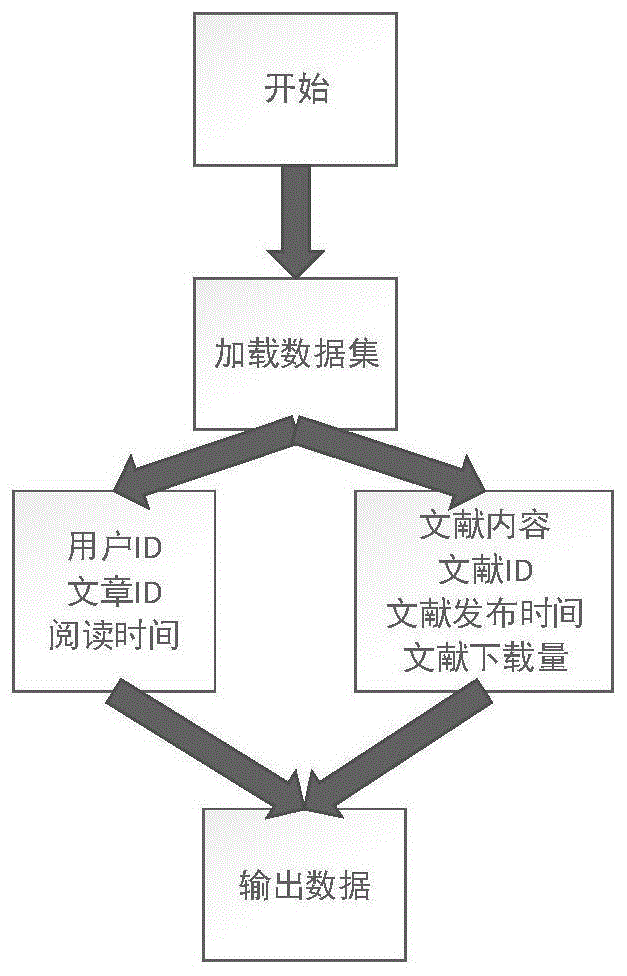
图1为基于内容的推荐算法流程图。
图2为一种新的基于成熟度技术的文献推荐算法模块交互图。
图3为本发明的数据交互计算图。
具体实施方式
本部分将根据附图对本发明作进一步阐释。
如图1所示,首先进行数据预处理模块,本发明中需要的数据有:
1.每个用户的阅读列表,该列表包含三个属性:用户id,文献id,阅读时间。
2.每篇文献的属性信息,包括文献内容,文献id,文献发布时间,文献下载量四个属性。
如图2所示,获得数据集之后,进入文献分类模块。需要首先将文献按主题分类,此处使用文本向量空间模型,对文献中的每个词使用tfi-df技术计算权值,将每篇文献的权重最高的前n个词作为这篇文献的标志词语。并且使用word2vec模型进行训练,求得所有文献之间的相似度,采用knn的方法对文献进行分类,分为k个主题的文献。在使用word2vec模型时,需要构建一个语料库,因为本系统中包含大量的文献,所以可以根据硬件机器的数量来决定一共将多少文献加入语料库进行训练。在进行文献的选取时要保证文献尽量覆盖到各个主题,这样才能保证训练出的word2vec模型的泛化性能优良。
如图2所示,获得文献分类信息之后,进入计算文献等级模块,该模块的输入是文献分类信息和用户阅读顺序列表。该模块的具体计算方法见附图3。具体分级方法为首先把每个用户的阅读列表进行清洗,根据不同的主题进行分类。得到每个用户在每个主题下的阅读顺序表pki,其中k为第k个用户,i为第i个主题。对每一个文献
其中,
其中
至此,已经获得了每个主题中每篇文献的等级信息,所有的文献为1~10级中的一个。下面进入计算用户等级模块。如图2所示,该模块的输入是用户的阅读列表和各个文献的等级信息,输出为用户的等级。用户在获取文献时一般是由浅入深的。然而因为用户在当前主题下可能阅读的文献等级具有随机性,可能会有一些误差,比如用户之前的某个知识点不熟悉又去下载了以前读过的等级比较低的文献,或者只是为了简单了解而下载了前沿知识的文献,所以用户的列表中,每个主题保存三篇文献,分别是用户读过的该主题下的上三篇文献,将平均值作为用户的等级。考虑到用户的兴趣和学习方向都会发生变化,所以对用户的所有看过的主题都保留一个时间戳,为用户最后一次浏览当前主题的时间。当时间超过阈值时,表示用户已经很长时间没有阅读过当前主题,可以从用户的信息中删除这个主题。
最后进入生成用户的推荐列表模块。该模块输入是得到用户信息和文献等级信息后,需要继续加入文献的发布时间和下载量的信息。在对用户进行推荐时,假设用户当前阅读过的最后一篇文献的等级为x,则给用户推荐与x同等级文献5篇,x+1等级的文献5篇。这五篇文献中,其中两篇为用户当前主题中适合用户等级的文献中下载量最多的两篇。其余三篇需要计算权值后推荐权值最高的三篇文献。权值的计算方法为:
其中
计算权重之后,从列表中选择权值最高的三篇文献。推荐给用户。综上,推荐给用户的文献中,每个主题的文献一共10篇,当前等级5篇,下一等级5篇。每个5篇中两篇为好评率高的文献,其余三篇为计算权值后权值最高的文献。
对于新用户的加入比较简单。用户只要进行了浏览文献的行为,就会出现浏览记录,根据用户的浏览记录可以正确地给用户划分等级。而对于新文献加入系统而言,用户对这些文献的浏览是比较靠后的,导致文献等级偏高,如何确定这些文献的具体等级呢:在推荐这些文献时,首先明确该文献的主题,并将该文献作为一个新的推荐部分即新品推荐给该主题下的用户。如果用户点击并下载了该文献,则说明该文献符合用户的当前等级的需求,为这篇文献记录下用户的等级,当这篇文献的记录数量达到一个阈值n时,将n个数值求平均值,设置为该文献的具体等级。
- 还没有人留言评论。精彩留言会获得点赞!