信息交互方法、装置、设备及存储介质与流程
1.本申请涉及人机交互技术领域,更具体的说,是涉及一种信息交互方法、装置、设备及存储介质。
背景技术:
2.随着语音识别和自然语言理解技术的进步,在车载、企业、医疗等多个场景下,人机交互终端已经从实验变成现实。
3.然而当前的交互系统都是基于单一场景单一语种的实现,即在不同交互场景,如车载、医疗等,都需要针对不同的场景分别设计一套交互系统。且针对不同国家的不同人群习惯,语音交互系统是不通用的,都需要针对特定语种特定人群特定场景单独的设计一套交互系统,系统开发量大难以部署。
技术实现要素:
4.鉴于上述问题,提出了本申请以便提供一种信息交互方法、装置、设备及存储介质,以支持跨语种、跨场景的情况下进行人机交互。具体方案如下:
5.一种信息交互方法,包括:
6.获取当前交互场景下的多模态数据,所述多模态数据包括人机交互过程的视频信息、音频信息和/或文本信息;
7.参考预配置的场景知识图谱库,基于预训练的回复生成模型处理所述多模态数据,输出用于进行交互的回复信息,所述场景知识图谱库中包含与各不同场景一一对应的场景知识图谱;
8.所述回复生成模型利用跨语种、跨场景的多模态训练数据及所述场景知识图谱库通过无监督的方式训练得到。
9.优选地,所述回复生成模型的训练过程,包括:
10.获取跨语种、跨场景的多模态训练数据,以及预配置的场景知识图谱库;
11.将所述多模态训练数据所包含的视频信息、音频信息和文本信息进行对齐;
12.以对齐后的多模态训练数据作为样本输入,参考所述场景知识图谱库,以预测所述多模态训练数据包含的文本信息中被遮挡的字符为目标,训练回复生成模型。
13.优选地,所述将所述多模态训练数据所包含的视频信息、音频信息和文本信息进行对齐,包括:
14.对所述视频信息中各视频帧进行特征提取,得到所述视频信息对应的视频特征向量;
15.对所述视频特征向量进行离散化表示,得到与所述文本信息中各字符一一对齐的视频特征向量;
16.对所述音频信息中各语音帧进行特征提取,得到所述音频信息对应的音频特征向量;
17.对所述音频特征向量进行离散化表示,得到与所述文本信息中各字符一一对齐的音频特征向量。
18.优选地,所述以对齐后的多模态训练数据作为样本输入,参考所述场景知识图谱库,以预测所述多模态训练数据包含的文本信息中被遮挡的字符为目标,训练回复生成模型,包括:
19.利用回复生成模型对输入的所述对齐后的多模态训练数据所包含的视频信息、音频信息和文本信息进行拼接,得到拼接特征;
20.基于所述拼接特征从所述场景知识图谱库中选择适配的场景知识图谱,并将选择的场景知识图谱表示为知识图谱向量特征;
21.利用回复生成模型,基于所述拼接特征及所述知识图谱向量特征,预测所述文本信息中被遮挡的字符;
22.以回复生成模型预测的被遮挡的字符趋近于所述文本信息中真实被遮挡的字符为目标,训练回复生成模型。
23.优选地,所述多模态训练数据还包括位置信息,所述利用回复生成模型对输入的所述对齐后的多模态训练数据所包含的视频信息、音频信息和文本信息进行拼接,得到拼接特征,包括:
24.利用回复生成模型对输入的所述对齐后的多模态训练数据所包含的视频信息、音频信息、文本信息及所述位置信息进行拼接,得到拼接特征。
25.优选地,所述参考预配置的场景知识图谱库,基于预训练的回复生成模型处理所述多模态数据,输出用于进行交互的回复信息,包括:
26.利用回复生成模型对所述多模态数据所包含的视频信息、音频信息和/或文本信息进行拼接,得到拼接特征;
27.基于所述拼接特征从所述场景知识图谱库中选择适配的场景知识图谱,并将选择的场景知识图谱表示为知识图谱向量特征;
28.利用回复生成模型,基于所述拼接特征及所述知识图谱向量特征,预测并输出用于进行交互的回复信息。
29.优选地,所述多模态数据还包括位置信息;
30.所述利用回复生成模型对所述多模态数据所包含的视频信息、音频信息和/或文本信息进行拼接,得到拼接特征,包括:
31.利用回复生成模型对所述多模态数据所包含的位置信息、视频信息、音频信息和/或文本信息进行拼接,得到拼接特征。
32.一种信息交互装置,包括:
33.多模态数据获取单元,用于获取当前交互场景下的多模态数据,所述多模态数据包括人机交互过程的视频信息、音频信息和/或文本信息;
34.回复信息生成单元,用于参考预配置的场景知识图谱库,基于预训练的回复生成模型处理所述多模态数据,输出用于进行交互的回复信息,所述场景知识图谱库中包含与各不同场景一一对应的场景知识图谱;
35.所述回复生成模型利用跨语种、跨场景的多模态训练数据及所述场景知识图谱库通过无监督的方式训练得到。
36.一种信息交互设备,包括:存储器和处理器;
37.所述存储器,用于存储程序;
38.所述处理器,用于执行所述程序,实现如上所述的信息交互方法的各个步骤。
39.一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上所述的信息交互方法的各个步骤。
40.借由上述技术方案,本申请的信息交互方法,预先利用跨语种、跨场景的多模态训练数据及场景知识图谱库,通过无监督的方式训练得到回复生成模型,进而在获取到当前交互场景下的多模态数据之后,可以参考场景知识图谱库,利用回复生成模型处理多模态数据,进而输出用于进行交互的回复信息,实现人机交互过程。由于本申请的回复生成模型利用跨语种、跨场景的多模态训练数据训练完成,因此回复生成模型可以适用于跨语种、跨场景的交互过程,无需针对不同语种、不同场景单独构建不同的交互系统,介绍了系统开发、部署难度。
41.同时,本申请进一步引入了场景知识图谱库,其中包含与各不同场景一一对应的场景知识图谱,回复生成模型训练过程进一步参考了该场景知识图谱库,能够自动根据输入的多模态数据来匹配与当前交互场景匹配的场景知识图谱,进而基于匹配的场景知识图谱来生成回复信息,使得生成的回复信息与当前人机交互场景更加适配,提升了人机交互的准确度。
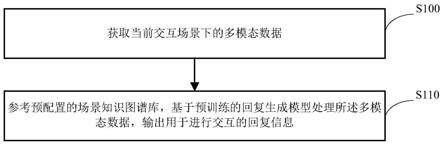
42.再进一步的,回复生成模型训练过程是以跨语种、跨场景的多模态训练数据通过无监督方式进行训练的,其不同于现有的有监督训练方式,能够天然的使用所有已有的多模态数据进行模型的训练,大大增加了训练数据量,且无需人工对训练数据进行打标签,进而也节省了人力成本。
附图说明
43.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本申请的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
44.图1为本申请实施例提供的信息交互方法的一流程示意图;
45.图2为本申请实施例提供的一种回复生成模型训练流程示意图;
46.图3示例了一种多模态预训练模型训练过程示意图;
47.图4示例了一种语言模型训练过程示意图;
48.图5为本申请实施例提供的一种回复生成模型生成回复信息的流程示意图;
49.图6为本申请实施例提供的一种信息交互装置结构示意图;
50.图7为本申请实施例提供的信息交互设备的结构示意图。
具体实施方式
51.下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
52.本申请提供了一种信息交互方案,可以适用于人机交互场景下机器生成用于进行交互的回复信息。其中,人机交互场景可以是多种不同的场景,如车载场景、企业场景、医疗场景等等。
53.本申请方案可以基于具备数据处理能力的终端实现,该终端可以是手机、电脑、服务器、云端等。
54.接下来,结合图1所述,本申请的信息交互方法可以包括如下步骤:
55.步骤s100、获取当前交互场景下的多模态数据。
56.其中,所述多模态数据可以包括人机交互过程的视频信息、音频信息和/或文本信息。
57.本申请可以使用感知设备收集人机交互过程的多模态数据,如使用摄像头收集视频信息,使用录音设备收集音频信息,使用输入设备收集文本信息。当然可以理解的是,对于文本信息也可以是通过对已收集的视频信息、音频信息进行字幕提取或语音识别,从而得到对应的文本信息。
58.其中,视频信息可以包括交互对象的特征信息,以及周围环境信息。交互对象的特征信息可以是交互对象的图像,以及根据图像分析出的交互对象的个人属性信息,如国别、职业、年龄、兴趣偏好等。以国别为例,通过收集交互对象的国别信息,能够辅助更加准确的确定当前的交互场景,示例如:通过视频信息能够拍摄到交互对象是印度人,且当前活动为正在吃饭,则可以确定当前交互场景为印度人吃饭场景,进一步便于后续在场景知识图谱库中找出印度人吃饭场景对应的场景知识图谱,从而对输出的交互内容进行优化。
59.上述音频信息包括交互对象的语音信息,如语音内容、音调、音色等。
60.文本信息可以包括交互对象在交互过程中输入的文本内容。
61.需要说明的是,本步骤中获取的当前交互场景下的多模态数据可以包括当前时刻的多模态数据以及历史多模态数据,如历史多轮交互的多模态数据。通过历史多模态数据可以辅助准确的生成回复信息。
62.步骤s110、参考预配置的场景知识图谱库,基于预训练的回复生成模型处理所述多模态数据,输出用于进行交互的回复信息。
63.其中,所述场景知识图谱库中包含与各不同场景一一对应的场景知识图谱。本申请预先收集汇总了人机交互所处的不同的场景,进而构建了与每一场景一一对应的场景知识图谱,场景知识图谱中包含了对应场景下的先验知识,用于辅助回复生成模型准确生成与场景匹配的回复信息,进而达到交互场景消歧的目的。
64.交互场景消歧是指,交互对象在不同的交互场景下说同样一句话,回复生成模型应该结合当前场景给出最佳的回答,而不是只反馈同一个交互结果。
65.例如,一个用户在车载的交互场景下说:“我要去打篮球”,那么交互结果应该结合当前的交互场景,给出的交互响应是帮助用户导航附近可以打球的篮球场。而如果用户是在家里说:“我要去打篮球”,语音交互结果应该先给出今天的天气情况,然后等待用户的回答反馈,如果天气差,而用户还执意要去打篮球,那么最终的语音交互结果为,为用户导航到室内的篮球场。
66.再比如,交互场景还包含了交互对象的国别,如不同国别的交互对象所处的交互场景也不同。
67.同一单词在不同的国家代表的含义可能是不同的,如“bump”这个单词,在英国代表的是“碰撞”,如撞车等。而在瑞典则代表“倒垃圾”的意思。若不考虑交互场景,仅考虑交互语音,则给出的交互结果可能会出现较大错误,如一个瑞典人手提一个垃圾袋准备去倒垃圾,其向人机交互系统提问:i want to bump,please tell me what kind of garbage batteries belong to?若人机交互系统未考虑这句话是瑞典人说的,那么很有可能按照bump的常规理解“碰撞”,认为用户“想要去撞车”,此时将无法给出正确的交互回应。而本申请方案通过使用多模态数据,拍摄到用户交互的视频、图像等,分析出当前用户为瑞典人且图像中包含垃圾袋,则可以确定出当前交互场景为瑞典人扔垃圾的场景,此时即可准确的将“bump”翻译为“倒垃圾”,进而能够给出正确的交互回应信息。
68.回复生成模型只有在不同交互场景下使用不同的场景知识图谱,才能够避免歧义的发生,使用场景知识图谱的目的也是为了避免歧义的发生,提高用户的交互体验。
69.本实施例中,回复生成模型利用跨语种、跨场景的多模态训练数据及所述场景知识图谱库通过无监督的方式训练得到。
70.互联网上存在的大量多模态数据,天然包含了多语种、多场景,这些多模态数据都是不带有标签的无监督的样本数据,本案直接使用这些数据进行无监督的训练。并且由于从互联网上获取的多模态数据中,视频、音频、文本信息都是对齐的,因而具备很强的信息量。本案通过引入多语种、多场景的多模态无标注训练数据,以无监督的方式将这些多模态训练数据融合进行无监督学习,以便更好的学习到不同国家、不同人群之间的差异性和共性。
71.本申请通过使用跨语种、跨场景的多模态训练数据及所述场景知识图谱库对回复生成模型进行训练,进而针对不同的交互场景、不同国家、不同人群均可以使用同一回复生成模型来生成用于交互的回复信息,极大的减少了开发的成本、方便模型部署。
72.同时,由于本申请回复生成模型训练时使用的是多模态训练数据,即同时拥有能够表示语音、图像、文字的相同语义空间,进而在回复信息生成阶段,通过输入当前交互场景下的多模态数据,可以生成更加准确的回复信息,提升人机交互体验。
73.当然,若实际情况下只能获取部分多模态数据,如缺少音频和视频信息,只有文本信息,回复生成模型拥有少部分信息源也能进行模型解码。而且回复生成模型是基于多模态寻路数据训练的,已经通过大量无监督多模态训练数据隐式地学习到了多模态的知识,尽管输入端缺少一些模态的数据,亦能保证生成的回复相对于现有的回复生成系统更加合理可靠。
74.在本申请的一个实施例中,介绍上述回复生成模型的训练过程。
75.本申请可以收集大量的跨语种、跨场景的多模态训练数据。多模态训练数据可以通过网络获取,互联网上存在大量的多模态数据,天然包含了多语种、多场景,多模态数据包含了音频、视频、文本中的至少一项或多项,这些数据都是不带有标签的无监督的样本数据,可以直接作为模型训练时的多模态训练数据。模型能够学习到各语种、各场景的通用信息。
76.为了更好的利用多模态训练数据训练回复生成模型,本申请可以对多模态训练数据进行对齐处理,也即将多模态训练数据所包含的视频信息、音频信息和文本信息进行对齐。
77.具体的,以从互联网上获取的视频流数据为例,可以从视频流中提取音频、视频和文本信息,进一步需要将音频、视频和文本信息进行对齐。
78.对于视频信息而言:
79.视频信息中包含有多帧视频。本申请可以对视频信息中各视频帧进行特征提取,由提取的特征组成视频信息对应的视频特征向量。示例如,针对每一视频帧,可以通过卷积神经网络cnn或其它方式进行特征提取,以得到每一视频帧对应的特征。
80.为了将视频信息与文本信息进行对齐,可以基于文本信息所包含的字符个数,对视频特征向量进行离散化表示,以得到与文本信息中各字符一一对齐的视频特征向量。其中,对视频特征向量进行离散化表示的过程,可以使用聚类的方式,也即以文本信息所包含的字符数量为聚类数,对连续的视频特征向量进行聚类,得到与文本信息中每一字符对齐的视频特征向量。
81.对于音频信息而言:
82.音频信息中包含有多帧语音。本申请可以对音频信息中各语音帧进行特征提取,由提取的特征组成音频信息对应的音频特征向量。示例如,针对每一语音帧,首先获取语音帧的波形图,进而可以通过循环神经网络rnn或其它方式对波形图进行特征提取,以得到每一语音帧对应的特征。
83.为了将语音信息与文本信息进行对齐,可以基于文本信息所包含的字符个数,对音频特征向量进行离散化表示,以得到与文本信息中各字符一一对齐的音频特征向量。其中,对音频特征向量进行离散化表示的过程,可以使用聚类的方式,也即以文本信息所包含的字符数量为聚类数,对连续的音频特征向量进行聚类,得到与文本信息中每一字符对齐的音频特征向量。
84.对于文本信息而言:
85.为了获取到文本信息,可以从视频流数据中提取出文本信息。如果视频流数据中本身存在字幕,则可以使用ocr技术将字幕提取出来,得到文本信息。如果视频流数据中本身不存在字幕,则可以使用语音识别技术,将视频流中的对话信息识别出来,以得到文本信息。
86.进一步的,为了使得回复生成模型生成回复信息时,能够综合考虑当前交互场景,以生成与当前交互场景所适配的回复信息,本申请实施例中还可以预先配置好场景知识图谱库。场景知识图谱库中包含有与各个不同交互场景一一对应的场景知识图谱。
87.在将多模态训练数据所包含的视频信息、音频信息和文本信息进行对齐之后,可以以对齐后的多模态训练数据作为样本输入,参考所述场景知识图谱库,以预测所述多模态训练数据包含的文本信息中被遮挡的字符为目标,训练回复生成模型。
88.参考图2,其示例了回复生成模型的训练过程,具体可以包括如下步骤:
89.步骤s200、利用回复生成模型对输入的所述对齐后的多模态训练数据所包含的视频信息、音频信息和文本信息进行拼接,得到拼接特征。
90.步骤s210、基于所述拼接特征从所述场景知识图谱库中选择适配的场景知识图谱,并将选择的场景知识图谱表示为知识图谱向量特征。
91.具体的,通过不断的迭代训练回复生成模型,以使得回复生成模型具备基于拼接特征从场景知识图谱库中选择与当前人机交互场景匹配的场景知识图谱的能力。也即,基
于拼接特征从所述场景知识图谱库中选择适配的场景知识图谱的过程不需要按照规则来实现,而是训练后的回复生成模型自身所固有的能力,相比于依据设定规则来选取适配的场景知识图谱的方式,避免了由于规则本身存在问题或不全面,导致选取的场景知识图谱与当前人机交互场景不匹配的问题。
92.步骤s220、利用回复生成模型,基于所述拼接特征及所述知识图谱向量特征,预测所述文本信息中被遮挡的字符。
93.步骤s230、以回复生成模型预测的被遮挡的字符趋近于所述文本信息中真实被遮挡的字符为目标,训练回复生成模型。
94.本实施例中通过参考场景知识图谱库来训练回复生成模型,保证回复生成模型具备各个场景下的所有常识,据此辅助进行最终的回复生成。例如,用户在电子商城的交互场景下说,我想要了解一下苹果,那么交互的返回结果应该是给用户推荐苹果手机的相关属性。如果用户在水果店的交互场景下说,我想要了解苹果,那么交互的返回结果应该是给用户推荐水果苹果的相关属性。只有在不同场景下使用不同的场景知识图谱,才能够避免歧义的发生,使用场景知识图谱的目的也是为了避免歧义的发生,提高用户的交互体验。
95.在本申请的一些实施例中,多模态训练数据除了可以包括上述的视频信息、音频信息及文本信息之外,还可以包括位置信息,也即人机交互时所处的位置信息。通过进一步引入位置信息,能够更加准确的辅助回复生成模型生成合适的回复信息。
96.在多模态训练数据还包括位置信息的基础上,上述步骤s210进行特征拼接的过程,具体可以包括:
97.利用回复生成模型对输入的所述对齐后的多模态训练数据所包含的视频信息、音频信息、文本信息及所述位置信息进行拼接,得到拼接特征。
98.具体的,可以首先将对齐的视频信息、音频信息和文本信息进行拼接,得到初步拼接特征。进一步的,将位置信息与所述初步拼接特征进行二次拼接,得到最终的拼接特征。
99.在得到最终的拼接特征之后,回复生成模型可以基于该最终的拼接特征来选择适配的场景知识图谱,以及预测文本信息中被遮挡的字符。
100.通过在多模态训练数据中进一步增加位置信息,可以提升回复生成模型所生成回复信息的准确度。
101.本申请一些实施例中,回复生成模型可以包括多模态预训练模型。多模态预训练模型类似于掩码语言模型,其输入包括视频信息、音频信息以及对齐的文本信息。当然,多模态预训练模型还可以进一步包括有位置信息。在多模态预训练模型训练阶段,对于文本信息,可以随机遮挡mask掉其中部分字符,然后模型结合输入的多模态训练数据,预测被mask掉的字符,如图3所示。
102.训练阶段,输入的多模态训练数据中文本信息为“今天的晚餐”,其中可以随机将“晚餐”两个字符mask掉,进一步将文本信息对齐的视频信息和音频信息一并输入模型,由模型预测被mask掉的字符。
103.需要说明的是,图3示例的多模态训练数据仅仅包括视频信息、音频信息和文本信息,除此之外,还可以包括位置信息。
104.由于多模态数据是跨语种的,对于所有语种,视频、音频和文本的神经网络均是共享,相比文本和音频而言,视频和语种关联性较弱,因此,如果一些视频比较相似,也会约束
学习到的对应音频表示、文本表示比较相似,模型因而具备刻画多语种语义的能力。
105.多模态预训练过程是无监督的,而且训练数据包含各个语种、各个场景,极大缓解了监督语料规模要求。以该多模态预训练模型作为回复生成模型,能够有效适应各个交互场景。
106.此外,人机交互过程中最重要的部分在于语言,尤其是在多语种交互过程中,语言部分更显重要。因此,本申请实施例中可以在回复生成模型中进一步增加语言模型,以单独对文本信息进行建模。本申请实施例中可以使用掩码语言模型,该模型基于transformer结构,遮挡住文本信息中的部分字符,利用其它未被遮挡的上下文信息,以预测被遮挡字符为目标进行模型训练。本申请获取的多模态训练数据中包含的文本信息存在不同语种单语语料,也存在混合语种语料,因而通过预训练的语言模型能够刻画多语种的语义。如图4所示,其示例了语言模型的训练过程。
107.训练阶段,输入数据仅包括文本信息,如对于文本信息“我要打篮球,导航到附近球场”,可以随机将“球场”两个字符mask掉,则输入到语言模型的文本信息为“我要打篮球,导航到附近maskmask”。由语言模型预测输入文本中被mask掉的字符,实现无监督训练过程。
108.当然,多模态训练数据中的文本还可以包括混合语种语料,例如“the translation of apple in chinese is苹果”,由于该种类型的语料同样会使用语言模型进行训练,因而使得语言模型能将不同语种刻画在同一语义空间里。基于此,训练好的语言模型可以针对不同语种的输入文本,生成合适的回复信息。
109.需要说明的是,在回复生成模型同时包括多模态预训练模型和语言模型时,可以基于多模态预训练模型和语言模型的输出结果,综合确定最终的回复信息。示例如,若当前交互场景下获取的多模态数据仅包含文本信息,则可以将文本信息输入语言模型,并将语言模型输出的回复信息作为最终结果。若当前交互场景下获取的多模态数据同时包括视频信息、音频信息和文本信息,则可以将多模态数据输入多模态预训练模型,以及将文本信息输入语言模型,并基于多模态预训练模型和语言模型的输出结果,确定最终的回复信息。
110.基于前述对回复生成模型的介绍,本申请实施例中对前述步骤s110,基于预训练的回复生成模型处理所述多模态数据及预配置的场景知识图谱库,输出用于进行交互的回复信息的过程进行说明。如图5所示,具体可以包括如下步骤:
111.步骤s300、利用回复生成模型对多模态数据所包含的视频信息、音频信息和/或文本信息进行拼接,得到拼接特征。
112.具体的,人机交互过程中获取的多模态数据可以同时包括视频信息、音频信息和文本信息,则可以直接将三者进行拼接,得到拼接特征。此外,若部分多模态数据无法获取,则可以将获取到的多模态数据进行拼接,如仅获取到音频信息和文本信息,则可以将二者进行拼接,或者是,仅获取到文本信息,则可以将文本信息直接作为拼接特征。
113.进一步的,多模态数据还可以包括位置信息,则本步骤中可以将位置信息、视频信息、音频信息和/或文本信息进行拼接,得到拼接特征。
114.步骤s310、基于所述拼接特征从所述场景知识图谱库中选择适配的场景知识图谱,并将选择的场景知识图谱表示为知识图谱向量特征。
115.具体的,回复生成模型在训练后已经具备基于拼接特征选择与当前人机交互场景
适配的场景知识图谱的能力,因此本步骤中可以直接基于拼接特征选择适配的场景知识图谱,且该过程属于模型内部数据处理过程,对用户而言是不可见的。
116.步骤s320、利用回复生成模型,基于所述拼接特征及所述知识图谱向量特征,预测并输出用于进行交互的回复信息。
117.具体的,回复生成模型预先已经使用跨语种、跨场景的多模态训练数据训练完毕,因此本实施例中可以针对当前交互场景下获取的任意语种、任意场景的多模态数据,输出用于进行交互的回复信息,从而实现一个回复生成模型适用于多语种、多场景的人机交互过程。
118.下面对本申请实施例提供的信息交互装置进行描述,下文描述的信息交互装置与上文描述的信息交互方法可相互对应参照。
119.参见图6,图6为本申请实施例公开的一种信息交互装置结构示意图。
120.如图6所示,该装置可以包括:
121.多模态数据获取单元11,用于获取当前交互场景下的多模态数据,所述多模态数据包括人机交互过程的视频信息、音频信息和/或文本信息;
122.回复信息生成单元12,用于预配置的场景知识图谱库,基于预训练的回复生成模型处理所述多模态数据,输出用于进行交互的回复信息,所述场景知识图谱库中包含与各不同场景一一对应的场景知识图谱;
123.所述回复生成模型利用跨语种、跨场景的多模态训练数据及所述场景知识图谱库通过无监督的方式训练得到。
124.可选的,本申请的信息交互装置还可以包括模型训练单元,用于训练得到回复生成模型,该训练过程可以包括:
125.获取跨语种、跨场景的多模态训练数据,以及预配置的场景知识图谱库;
126.将所述多模态训练数据所包含的视频信息、音频信息和文本信息进行对齐;
127.以对齐后的多模态训练数据作为样本输入,参考所述场景知识图谱库,以预测所述多模态训练数据包含的文本信息中被遮挡的字符为目标,训练回复生成模型。
128.可选的,上述模型训练单元将所述多模态训练数据所包含的视频信息、音频信息和文本信息进行对齐的过程,可以包括:
129.对所述视频信息中各视频帧进行特征提取,得到所述视频信息对应的视频特征向量;
130.对所述视频特征向量进行离散化表示,得到与所述文本信息中各字符一一对齐的视频特征向量;
131.对所述音频信息中各语音帧进行特征提取,得到所述音频信息对应的音频特征向量;
132.对所述音频特征向量进行离散化表示,得到与所述文本信息中各字符一一对齐的音频特征向量。
133.可选的,上述模型训练单元以对齐后的多模态训练数据作为样本输入,参考所述场景知识图谱库,以预测所述多模态训练数据包含的文本信息中被遮挡的字符为目标,训练回复生成模型的过程,可以包括:
134.利用回复生成模型对输入的所述对齐后的多模态训练数据所包含的视频信息、音
频信息和文本信息进行拼接,得到拼接特征;
135.基于所述拼接特征从所述场景知识图谱库中选择适配的场景知识图谱,并将选择的场景知识图谱表示为知识图谱向量特征;
136.利用回复生成模型,基于所述拼接特征及所述知识图谱向量特征,预测所述文本信息中被遮挡的字符;
137.以回复生成模型预测的被遮挡的字符趋近于所述文本信息中真实被遮挡的字符为目标,训练回复生成模型。
138.可选的,上述多模态训练数据还可以包括位置信息,则模型训练单元利用回复生成模型对输入的所述对齐后的多模态训练数据所包含的视频信息、音频信息和文本信息进行拼接,得到拼接特征的过程,可以包括:
139.利用回复生成模型对输入的所述对齐后的多模态训练数据所包含的视频信息、音频信息、文本信息及所述位置信息进行拼接,得到拼接特征。
140.可选的,上述回复信息生成单元基于预训练的回复生成模型处理所述多模态数据及预配置的场景知识图谱库,输出用于进行交互的回复信息的过程,可以包括:
141.利用回复生成模型对所述多模态数据所包含的视频信息、音频信息和/或文本信息进行拼接,得到拼接特征;
142.基于所述拼接特征从所述场景知识图谱库中选择适配的场景知识图谱,并将选择的场景知识图谱表示为知识图谱向量特征;
143.利用回复生成模型,基于所述拼接特征及所述知识图谱向量特征,预测并输出用于进行交互的回复信息。
144.可选的,上述多模态数据还可以包括位置信息,则上述回复信息生成单元利用回复生成模型对所述多模态数据所包含的视频信息、音频信息和/或文本信息进行拼接,得到拼接特征的过程,可以包括:
145.利用回复生成模型对所述多模态数据所包含的位置信息、视频信息、音频信息和/或文本信息进行拼接,得到拼接特征。
146.本申请实施例提供的信息交互装置可应用于信息交互设备,如终端:手机、电脑等。可选的,图7示出了信息交互设备的硬件结构框图,参照图7,信息交互设备的硬件结构可以包括:至少一个处理器1,至少一个通信接口2,至少一个存储器3和至少一个通信总线4;
147.在本申请实施例中,处理器1、通信接口2、存储器3、通信总线4的数量为至少一个,且处理器1、通信接口2、存储器3通过通信总线4完成相互间的通信;
148.处理器1可能是一个中央处理器cpu,或者是特定集成电路asic(application specific integrated circuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;
149.存储器3可能包含高速ram存储器,也可能还包括非易失性存储器(non
‑
volatile memory)等,例如至少一个磁盘存储器;
150.其中,存储器存储有程序,处理器可调用存储器存储的程序,所述程序用于:
151.获取当前交互场景下的多模态数据,所述多模态数据包括人机交互过程的视频信息、音频信息和/或文本信息;
152.预配置的场景知识图谱库,基于预训练的回复生成模型处理所述多模态数据,输出用于进行交互的回复信息,所述场景知识图谱库中包含与各不同场景一一对应的场景知识图谱;
153.所述回复生成模型利用跨语种、跨场景的多模态训练数据及所述场景知识图谱库通过无监督的方式训练得到。
154.可选的,所述程序的细化功能和扩展功能可参照上文描述。
155.本申请实施例还提供一种存储介质,该存储介质可存储有适于处理器执行的程序,所述程序用于:
156.获取当前交互场景下的多模态数据,所述多模态数据包括人机交互过程的视频信息、音频信息和/或文本信息;
157.预配置的场景知识图谱库,基于预训练的回复生成模型处理所述多模态数据,输出用于进行交互的回复信息,所述场景知识图谱库中包含与各不同场景一一对应的场景知识图谱;
158.所述回复生成模型利用跨语种、跨场景的多模态训练数据及所述场景知识图谱库通过无监督的方式训练得到。
159.可选的,所述程序的细化功能和扩展功能可参照上文描述。
160.最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
161.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间可以根据需要进行组合,且相同相似部分互相参见即可。
162.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1