基于机器学习的模型参数获取方法、系统及可读介质
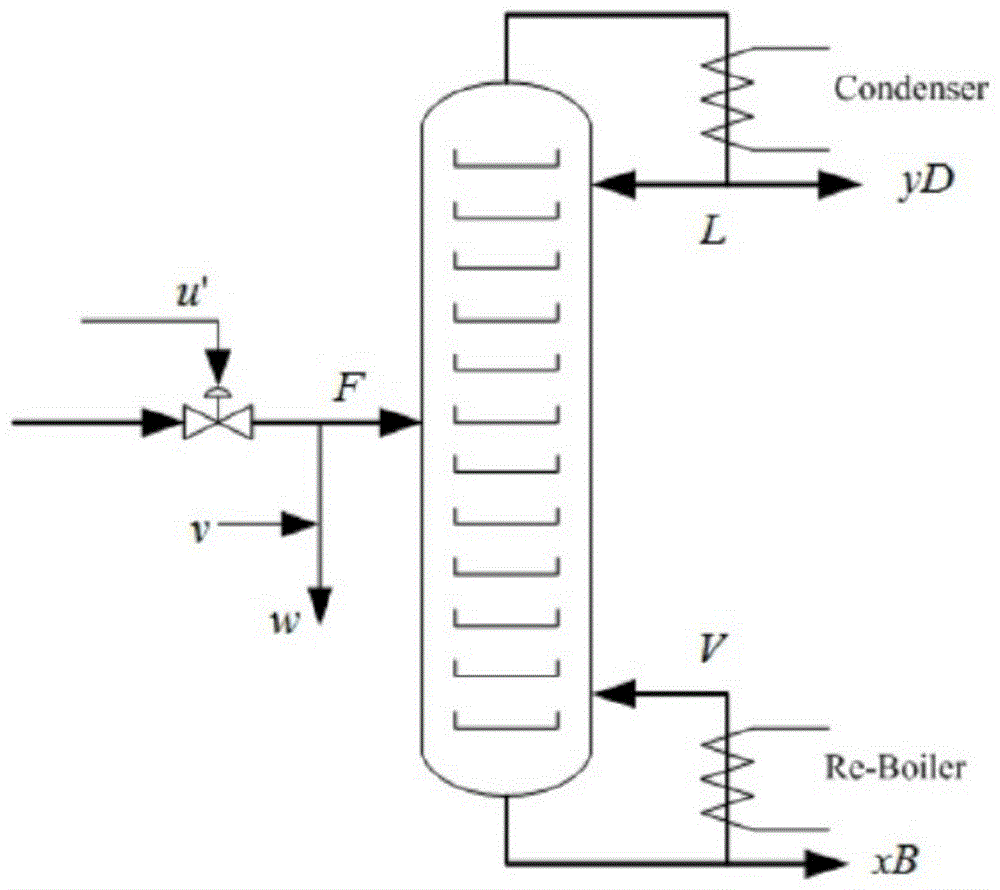
本发明涉及精馏塔系统的参数估计和时延辨识领域,属于复杂工业过程辨识和控制领域。
背景技术:
随着现代工业过程规模的不断扩大和复杂性的日益提高,建立有效的过程监控方法是确保生产安全、提高产品质量和保证经济效益的关键。对于复杂的工业过程来说,往往难以得到精确的数学模型对全过程进行能量和物料平衡关系的描述,而随着计算机技术的不断发展,控制装置对工业现场的信息采集、处理和加工能力显著加强,工业过程中采集和存储的过程数据越来越丰富,如何从海量数据中挖掘出有价值的过程信息,成为具有实际应用意义的研究课题。在这样的背景下,基于多元统计理论的统计过程监控方法应运而生,并在近年来取得了广泛的关注和应用。
多模态工业过程中,往往存在某些不可测变量(例如化工过程中的精馏塔产品组分浓度),这些不可测变量(也称作隐藏变量)往往用来描述这些过程的动态特性。由于物理条件或经济方面的约束,比如某些在线传感器价格特别昂贵,导致某些关键变量缺乏在线测量手段,或者只有稀少的滞后实验室化验值,难以有效地控制和提高生产效率,降低成本。对于这类复杂系统,传统的等周期采样数据计算机控制建模理论和辨识方法已不再适用,研究这类存在不可测变量的多模态系统建模及参数估计方法具有极为重要的意义。
技术实现要素:
1、本发明的目的
本发明要解决的技术问题是提供一种辨识算法来估计精馏塔时延系统以达到对系统参数辨识的高精度。
2、本发明所采用的技术方案
本发明提出了一种基于机器学习的模型参数获取方法,包括建立延迟状态空间模型,
其中,{xt}是精馏塔精馏过程中不可测量的状态;输入{ut,t=1,2,...,l}是精馏塔的回流流量和再沸器加热流量,并且在每个采样周期δt可测量;顶部产物的组成
建立全局模型,即每个局部模型的加权插值,采用指数加权函数来表示每个局部模型的权重;
通过机器学习算法即em算法确定参数估计,所述的延迟状态空间模型,引入一个隐藏变量表示在时间t生效的子模型,得到输出模型;
利用贝叶斯规则得出延迟的概率,使用卡尔曼滤波器对这些密度函数进行数值计算;用当前估计的参数θk评估q函数,在下一个最大化步骤中,通过最大化q函数获得新参数θk+1;为了最大化q函数,对每个参数执行微分运算;通过将导数等于零来计算每次迭代时系统参数的最佳估计。
优选的,建立延迟状态空间模型:
假设λi在0和q之间遵循均匀分布,
其中,q为正整数,由于操作条件的变化,单个模型不足以表示过程动力学;因此,使用全局模型,它是每个局部模型的加权插值,如下:
其中,xt和yt分别表示t时刻精馏过程的状态变量和输出变量,j和j为整数常数,αtj为权重,为常数;此处采用指数加权函数来表示每个局部模型的权重:
其中,ωtj为指数函数,ht为t时刻的操作变量,hj为j时刻的操作变量,t为时间,j为常数,σj表示每个局部模型的有效宽度,该宽度由σmin(σj,j=1:j)和σmax(σj,j=1:j)界定;归一化权重推导为α
其中,αtj为权重,ωij为指数函数。
优选的,通过em算法确定参数估计:
对于所提出的状态空间模型,引入一个隐藏变量it表示在时间t生效的子模型;数据集cobs为
其中,τik为延迟的概率,yti为精馏在ti时刻的输出,
其中,ht表示在时间t的调度变量的测量值,hj是第jth个工作点,σj表示第jth个局部模型的有效宽度;
使用移位算子的属性,状态方程改写为
xt=(zi-a)-1but+(zi-a)-1ωt
假设ωt=0,得到输出方程:
其中,α(z)是传递函数的分母,即系统的特征多项式,而β(z)是传递函数的分子,由下式定义
α(z):=z-ndet[zi-a]
=z-n(zn+α1zn-1+α2zn-2+…+αn)
=1+α1z-1+α2z-2+…+αnz-n,
β(z):=z-ncadj[zi-a]b
=β0+β1z-1+β2z-1+…+βnz-n
oe模型和fir模型的参数之间的关系描述为
f0=β0,
输出误差(oe)或传递函数模型已被广泛用于设计高级控制,一个多虑输出误差模型为
用来近似由下式给出的阶数nf的方程
定义信息向量
综上,得到输出模型:
优选的,利用贝叶斯规则得出延迟的概率为:
评估q函数,需要密度函数p(x1:t|cobs,θk)的值,使用卡尔曼滤波器对这些密度函数进行数值计算;在期望步骤中,使用当前估计的参数θk评估q函数,在下一个最大化步骤中,通过最大化q函数获得新参数θk+1;最大化q函数,对每个参数执行微分运算;因此,通过将导数等于零来计算每次迭代时系统参数的最佳估计
优选的,在精馏塔中,将回流流量和再沸器加热流量用作输入变量ut,以控制顶部产品和底部产品的组成。另外,将回流速度用作干扰变量ω,顶部产物的组成用作输出变量
本发明提出了一种基于参数估计的精馏塔时延系统,包括存储器和处理器,存储器存储有计算机程序,所述处理器执行所述计算机程序时实现所述的方法步骤。
本发明提出了一种计算机可读存储介质,其上存储有计算机程序,所述的计算机程序被处理器执行时实现所述的方法步骤。
3.本发明所采用的有益效果
(1)对于在不同工况下的整个工作范围内的动态过程辨识,很难通过单一过程模型来捕获过程动力学,本发明可以采用传统的辨识方法来进行参数估计。通过使用多个双速率状态空间模型来逼近具有不同工作条件的参数系统。
(2)本发明探索了一种em算法,以交互方式估计隐藏变量,参数变量,状态变量和时间变量,通过引入隐藏变量并组合卡尔曼平滑器来延迟。
(3)本发明研究了带迟延的状态空间模型的联合参数和状态估计问题。借助于卡尔曼滤波器和平滑器,获得了一种em识别方法来同时估计状态和参数。所提出的算法与递归最小二乘参数辨识方法不同,后者仅利用状态观测器来近似未知状态,而忽略了过程噪声和噪声在状态估计过程中的影响。
(4)本发明考虑了用于辨识具有迟延的状态空间系统的em算法,并提出了多模型来描述所考虑的系统。在借助em方法基于估计的状态对参数进行估计的同时,由kalman平滑器使用获取的系统参数更新状态。通过最大化所有状态延迟的联合后验概率来估计时间延迟,并且可以通过解决离散优化问题来实现。
(3)本发明具有延迟的状态空间系统的参数估计。基于卡尔曼滤波器和平滑器,以系统状态不可预测,时延不确定为隐藏变量,推导了迭代em算法。未知的系统状态和参数是交互式估算的。数值仿真和实验结果表明了em算法的优越性。本发明中使用的算法可以应用于具有延迟的非线性系统。仿真案例研究表明,所提出的算法/过程在设计和实现上是有效和高效的。
附图说明
图1为本发明的精馏塔示意图;
图2为本发明的不确定迟延估计;
图3为本发明的参数估计;
图4为本发明的测量值与预测值的比较;
图5为本发明的真实输出与估计输出的比较。
具体实施方式
下面结合本发明实例中的附图,对本发明实例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域技术人员在没有做创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
下面将结合附图对本发明实例作进一步地详细描述。
实施例
许多工业过程通常以某些“有序”的方式进行操作以满足不同的生产目标。这种有序的方式也称为操作轨迹,它由几个预先设计的操作点组成。使用“h”表示操作过程所依据的操作变量。考虑具有以下时间延迟的状态空间模型:
xt+1=axt+but+ωt,
其中,{xt}是精馏塔精馏过程中不可测量的状态;输入{ut,t=1,2,...,l}是精馏塔的回流流量和再沸器加热流量,并且在每个采样周期δt可测量;顶部产物的组成
其中,q为正整数,由于操作条件的变化,单个模型不足以表示过程动力学。因此,使用全局模型,它是每个局部模型的加权插值,如下所示:
其中,xt和yt分别表示t时刻精馏过程的状态变量和输出变量,j和j为整数常数,αtj为权重(常数)。此处采用指数加权函数来表示每个局部模型的权重
其中,ωtj为指数函数,ht为t时刻的操作变量,hj为j时刻的操作变量,t为时间,j为常数,σj表示每个局部模型的有效宽度,该宽度由σmin(σj,j=1:j)和σmax(σj,j=1:j)界定。归一化权重可以推导为α
其中,αtj为权重,ωtj为指数函数。下面将展示如何在em算法的方案下制定参数估计问题。
对于所提出的状态空间模型,引入一个隐藏变量it表示在时间t生效的子模型。数据集cobs为
其中,τik为延迟的概率,yti为精馏在ti时刻的输出,
其中,ht表示在时间t的调度变量的测量值,hj是第jth个工作点,σj表示第jth个局部模型的有效宽度。
使用移位算子的属性,状态方程可以改写为
xt=(zi-a)-1but+(zi-a)-1ωt,
假设ωt=0,得到输出方程:
其中,α(z)是传递函数的分母,即系统的特征多项式,而β(z)是传递函数的分子,它们由下式定义
α(z):=z-ndet[zi-a]
=z-n(zn+α1zn-1+α2zn-2+...+αn)
=1+α1z-1+α2z-2+...+αnz-n,
β(z):=z-ncadj[zi-a]b
=β0+β1z-1+β2z-1+...+βnz-n.
oe模型和fir模型的参数之间的关系描述为
f0=β0,
输出误差(oe)或传递函数模型已被广泛用于设计高级控制,一个多虑输出误差模型为
可以用来近似由下式给出的足够大的阶数nf的方程
定义信息向量
综上,可以得到输出模型:
为了评估q函数,需要密度函数p(x1:t|cobs,θk)的值,由于直接计算很困难,因此将使用卡尔曼滤波器对这些密度函数进行数值计算。在期望步骤中,使用当前估计的参数θk评估q函数,在下一个最大化步骤中,通过最大化q函数获得新参数θk+1。为了最大化q函数,对每个参数执行微分运算。因此,可以通过将导数等于零来计算每次迭代时系统参数的最佳估计
本发明中的模型可应用于精馏塔。精馏广泛用于许多生产过程,例如炼油和化学工业,并且是过程工业应用中最常见的单元之一。在精馏塔中,将回流流量和再沸器加热流量用作输入变量ut,以控制顶部产品和底部产品的组成。另外,将回流速度用作干扰变量ω,顶部产物的组成用作输出变量
参照附图的图2-图3,可以得出:提出的em算法具有良好的辨识性能,经过几次迭代后,可以将参数逼近为真实参数。测量值和预测值的比较结果,真实输出和估计输出的比较结果如图4-5所示。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!