一种基于异构信息网络表示学习的推荐方法
本发明涉及推荐技术领域,具体的说,是一种基于异构信息网络表示学习的推荐方法。
背景技术:
大数据时代,推荐系统凭借向用户提供即时准确的个性化服务的特性已成为各种线上应用不可或缺的工具。基于相似用户或项目预测用户偏好的协同过滤是推荐系统领域倍受欢迎和关注的推荐算法。传统的协同过滤算法专注于挖掘用户和项目的评分数据,因此其不可避免地存在许多影响推荐性能的问题。随着信息技术的飞速发展,推荐系统中包含用户社交关系、用户或项目元数据、用户或项目的位置以及项目评论等在内的额外数据变得易于获取,为缓解推荐系统中存在的数据稀疏性或冷启动问题,诸多工作试图将额外数据作为辅助信息融于推荐方法,分别生成基于社交关系、元数据、位置信息以及评论信息的推荐算法并利用大量实验验证额外数据对推荐性能的提升效益。然而,多数结合辅助信息的工作对不同的额外数据独立处理,并未考虑推荐可能是多方面共同助力的结果,由此造成推荐过程中跨越不同额外数据的信息损失,因此基于异构信息网络的推荐方法被提出。
现有技术中的基于异构信息网络的推荐方法多数利用基于元路径的网络分析方法提取信息并学习融合函数生成推荐,存在信息挖掘不充分、依赖显式可达路径、未考虑不同语义之间的协同信息即组合特征等问题,由此导致异构信息网络所建模的推荐异质信息无法得到有效探索和利用,影响推荐效果。
技术实现要素:
本发明的目的在于提供一种基于异构信息网络表示学习的推荐方法,用于解决现有技术中推荐方法存在挖掘不充分、未考虑组合特征导致影响推荐效果的问题。
本发明通过下述技术方案解决上述问题:
一种基于异构信息网络表示学习的推荐方法,包括:
步骤s100:提取信息,对异构信息网络中的节点进行表示学习,所述节点包括用户节点和项目节点,获取用户和项目的低维向量;
步骤s200:将用户和项目的低维向量直接与推荐任务对接,作为推荐的样本特征输入域感知因子分解机模型,并通过添加组lasso作为正则项进行特征选择,完成用户和项目之间的评分预测;
步骤s300:根据评分预测完成推荐。
所述步骤s100具体为:
步骤s110:根据元结构生成语义图;
步骤s120:在语义图上进行动态截断随机游走,获取同时蕴含语义信息和结构信息的节点序列r,将节点序列r作为skip-gram模型的输入,获得节点低维向量。
所述步骤s110中元结构包括含有非线性结构的复杂元结构和只建模线性关系的线性元结构,元结构的起始节点和目标节点的节点类型相同,元结构的起始节点和目标节点类型为用户节点类型或项目节点类型,生成语义图的具体过程为:
步骤s111:从yelp信息网络中抽取用户节点和评论节点,并在用户节点和评论节点之间建立链接,形成异构图hg;
步骤s112:从yelp信息网络中找出既针对同一用户又包含相同关键字的评论对,并放入集合w;
步骤s113:对集合w进行遍历,将存在于w中的评论对于异构图hg中建立链接,形成关系r-r,则异构图hg中的线性元结构具备元结构的语义;
步骤s114:当元结构为复杂元结构时,根据异构图hg中存在的节点和关系构建相应邻接矩阵;当元结构为线性元结构时,从原始异构信息网络生成邻接矩阵;
步骤s115:在异构图hg中沿着线性元结构进行矩阵运算,生成同构矩阵auu;
步骤s116:根据同构矩阵auu构建同构图sg,同构图sg即为相应的复杂元结构或线性原结构对应的语义图。
给定异构信息网络g={v,ε}、元结构
其中,v为节点集合,
所述步骤s120具体包括:
步骤s121:将语义图上的节点投射到异构信息网络中g={ν,ε},计算复杂元结构cs以及线性元结构ls的节点相似性矩阵;
构建用户节点与评论节点的邻接矩阵wur,构建评论节点和项目节点的邻接矩阵wrb和构建评论节点和关键字节点的邻接矩阵w′rk;
获取c1和c2的基本积,其中
用户在复杂元结构cs上的相似性矩阵
计算线性元结构ls的节点相似性矩阵:
其中,wur为用户节点和评论节点的邻接矩阵,wrk为评论节点和关键词节点的邻接矩阵;
步骤s122:对从每个节点开始随机游走的次数进行约束,设置从每个节点v开始进行随机游走的次数为l,l=max(h(v)×maxl,minl),其中,maxl为从节点开始进行随机游走的最大次数;minl为从节点开始进行随机游走的最小次数;h(v)为节点v在语义图上的重要性;
步骤s123:动态截断随机游走,具体为:
定义元结构s的语义图sgs={vsg,εsg),节点在元结构s上的相似性矩阵sims,每个节点的最大游走次数maxt,每个节点的最小游走次数mint,游走的最大长度wl,游走的停止概率pstop;
初始化用于存放节点序列的列表sequences;
计算节点的重要性h=pagerank(sgs);
a1:计算以节点v为起始节点的游走次数l;
a2:初始化用于存放本次节点序列的列表sequence、记录当前节点nnow=v、记录最大游走次数wl_t=wl;
根据游走路径到达节点x并记录转移概率ptrrans,游走路径为:
式中,nx为游走路径的当前节点;ni为游走路径的上一跳节点,是nx的一阶近邻;o(ni)为节点ni的度;
将节点x加入列表sequence,计算节点x的停止概率px-stop:
式中,pstop为预先指定的固定停止概率;sim(ni,nx)为上一跳节点ni和当前节点nx之间未经过归一化的相似性;当前节点与上一跳节点之间的相似性越高,则随机游走在当前节点的停止概率越低,便更有可能沿着当前节点获取更多相似程度高的节点,从而形成一条具备高相似性的节点序列,因此动态截断随机游走在某种意义上可以做到节点相似性的保留,而这在基于相似用户或相似项目的推荐方法中极为重要。
判断是否在节点x停止,如果是,结束本次游走,进入下一步,否则,更新游走步长wl_t←wl_t-1和当前节点nnow=x,判断游走次数是否达到l,如果是进入下一步,否则,返回a2;
a3:将本次游走序列加入列表sequences,判断是否所有节点都计算完毕,如果是,进入下一步,否则返回a1;
a4:输出节点序列的列表sequences;
步骤s124:表示学习,对输出的节点序列,通过一个长度固定的采用窗口对近邻进行采样,得到用户的近邻集合,并采用以下公式优化表示学习:
maxf∑u∈vlogp(nuf((u))
式中,
步骤s125:通过动态截断随机游走获取的节点序列r:
r=dynamictruncatedrandomwalk(sgs,sims,maxt,mint,wl,pstop)
将r作为skip-gram模型的输入,获得节点低维向量φ=skip-gram(d,winl,r)。
本发明通过设计2l条元结构实现对不同语义的捕获,其中以用户节点为起始类型以及以项目节点为起始类型的元结构各自有l条,是以对于每一个用户节点和项目节点而言,其将同时拥有多个不同的低维向量表示。
在yelp信息网络中,用户类型的节点除与其他类型节点拥有关系外,还可以与自身相连,即用户与用户之间存在朋友关系。若异构信息网络中用户与用户之间存在直接相连的关系,则还包括步骤s130:对不同元结构上生成的用户向量进行修正,具体包括:
步骤s131:指定用户集合
步骤s132:初始化训练数据集d;获取用户u在元结构s上的近邻集合nu、获取用户u的直接近邻集合dnu,获取用户u的间接近邻集合inu;
步骤s133:将由目标用户、直接近邻、间接近邻组成的三元组添加到训练数据集合;
步骤s134:根据梯度上升算法中的迭代公式更新参数:
步骤s135:直至用户向量矩阵ms收敛,输出经过修正的用户向量矩阵
若异构信息网络中用户与用户之间不存在直接相连的关系,则不对用户向量进行修正,而是直接将网络表示学习生成的用户向量作为用户特征。
所述步骤s200具体包括:
步骤s210:评分预测
通过在异构信息网络上设计2l条元结构,用户和项目将分别获得l组由不同语义生成的低维向量。对于这些来自不同元结构的向量,本发明并未学习融合函数,而是参考数据集中用户和项目之间的观测评分,对其进行拼接,并将拼接向量当作新的推荐样本xn:
式中,
步骤s220:对于推荐数据集中的每个评分,均可以将其转化为一组2l×d的特征向量,样本xn的评分利用ffm模型进行计算:
式中:w0为全局偏置、wi为第i个特征的相应权重以及
步骤s230:参数学习
对ffm模型计算公式中的参数,采用最小化均方误差学习,获取目标函数:
式中:yn为第n个样本的实际评分;n为样本数量;
在将异构信息网络表示学习的结果作用于ffm模型时,面临着以下两个问题:首先,由于在信息提取阶段使用的元结构是预先指定的,并非所有元结构均对推荐有益,因此如何挑选于推荐有用的元结构便是需要考虑的第一个问题;其次,由网络表示学习生成的用户和项目特征是稠密向量,因此输入到ffm模型的样本特征便不再稀疏,获取模型参数的计算成本势必不再能够与稀疏样本同日而语,因此降低计算消耗则是面临的第二个问题。针对上述两个问题,本文在目标函数中引入可以用于挑选特征的组lasso。组lasso在特征系数预先被分为多个组的基础上,将同属于一个组的系数视为单个变量并按照组内系数是否为0进行特征选择,对提高特征组间的稀疏性大有益处。具体如下:
在目标函数中引入可以用于挑选特征的组lasso,参数p的组lasso正则化具有如下表示:
式中,pg为所有属于第g组的参数,g=1,2,...,g;||·||2——l2范数;
将样本xn中由同一个元结构生成的特征归入同一个组,因此样本xn的特征将被分为2l个组,对于参数w以及v分别有以下正则化公式:
式中;wl为一个维度为d的向量;vl为第1个元结构的特征在所有域上的隐向量构成的矩阵;||·||f为矩阵的frobenius范数;
综合目标函数和正则化公式,优化目标可转换为:
采用非单调加速近端梯度算法nmapg进行模型的优化,输出/得到优化后的特征选择。
本发明与现有技术相比,具有以下优点及有益效果:
(1)本发明采用基于元结构和动态截断随机游走的异构信息网络表示学习方法,不但能够捕获简单线性语义,对复杂非线性结构的挖掘也能井然有序,有效弥补元路径因自身结构缺陷所导致的信息丢失问题。元结构用于语义挖掘,动态截断随机游走服务于结构获取,而通过在基于元结构的语义图上执行动态截断随机游走即可实现语义和结构的联合捕获,使得最后获得的节点低维向量同时具备结构和语义等两个层面的特性。
(2)本发明由不同元结构生成的特征直接对接于推荐模型,提出元结构语义下基于域感知因子分解机的推荐方法,以推荐任务为导向,未对同一节点的不同向量学习整体表示,而是将特征挑选和过滤的主动权交于推荐过程,从而避免信息融合阶段可能造成的不可逆信息损失。
(3)本发明提出动态截断随机游走模型,通过在随机游走中引入停止概率和节点重要性使得生成的节点序列与自然语言处理中的语句在长度分配上更为相似,并且符合幂律分布这一特殊规律;做到节点相似性的保留,而这在基于相似用户或相似项目的推荐方法中极为重要。
附图说明
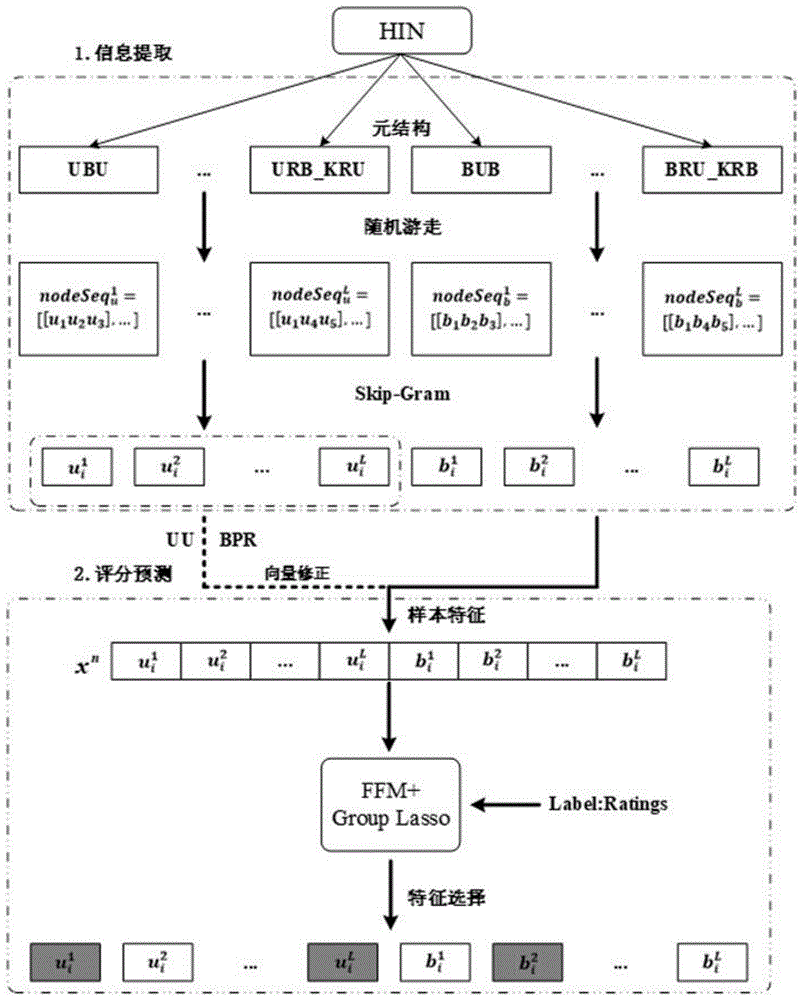
图1为本发明的流程图。
具体实施方式
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例:
结合附图1所示,一种基于异构信息网络表示学习的推荐方法,包括:
步骤s100:提取信息,对异构信息网络中的节点进行表示学习,所述节点包括用户节点和项目节点,获取用户和项目的低维向量;
步骤s200:将用户和项目的低维向量直接与推荐任务对接,作为推荐的样本特征输入域感知因子分解机模型,并通过添加组lasso作为正则项进行特征选择,完成用户和项目之间的评分预测;
步骤s300:根据评分预测完成推荐。
所述步骤s100具体为:
步骤s110:根据元结构生成语义图;
步骤s120:在语义图上进行动态截断随机游走,获取同时蕴含语义信息和结构信息的节点序列r,将节点序列r作为skip-gram模型的输入,获得节点低维向量。
所述步骤s110中元结构包括含有非线性结构的复杂元结构和只建模线性关系的线性元结构,元结构的起始节点和目标节点的节点类型相同,元结构的起始节点和目标节点类型为用户节点类型或项目节点类型,生成语义图的具体过程为:
步骤s111:从yelp信息网络中抽取用户节点和评论节点,并在用户节点和评论节点之间建立链接,形成异构图hg;
步骤s112:从yelp信息网络中找出既针对同一用户又包含相同关键字的评论对,并放入集合w;
步骤s113:对集合w进行遍历,将存在于w中的评论对于异构图hg中建立链接,形成关系r-r,则异构图hg中的线性元结构具备元结构的语义;
步骤s114:当元结构为复杂元结构时,根据异构图hg中存在的节点和关系构建相应邻接矩阵;当元结构为线性元结构时,从原始异构信息网络生成邻接矩阵;
步骤s115:在异构图hg中沿着线性元结构进行矩阵运算,生成同构矩阵auu;
步骤s116:根据同构矩阵auu构建同构图sg,同构图sg即为相应的复杂元结构或线性原结构对应的语义图。
给定异构信息网络g={v,ε}、元结构
其中,ν为节点集合,
所述步骤s120具体包括:
步骤s121:将语义图上的节点投射到异构信息网络中g={ν,ε},计算复杂元结构cs以及线性元结构ls的节点相似性矩阵;
构建用户节点与评论节点的邻接矩阵wir,构建评论节点和项目节点的邻接矩阵wrb和构建评论节点和关键字节点的邻接矩阵wrk;
获取c1和c2的基本积,其中
用户在复杂元结构cs上的相似性矩阵
计算线性元结构ls的节点相似性矩阵:
其中,wur为用户节点和评论节点的邻接矩阵,wrk为评论节点和关键词节点的邻接矩阵;
步骤s122:对从每个节点开始随机游走的次数进行约束,设置从每个节点v开始进行随机游走的次数为l,l=max(h(v)×maxl,minl),其中,maxl为从节点开始进行随机游走的最大次数;minl为从节点开始进行随机游走的最小次数;h(v)为节点v在语义图上的重要性;
步骤s123:动态截断随机游走,具体为:
定义元结构s的语义图sgs={vsg,εsg},节点在元结构s上的相似性矩阵sims,每个节点的最大游走次数maxt,每个节点的最小游走次数mint,游走的最大长度wl,游走的停止概率pstop;
初始化用于存放节点序列的列表sequences;
计算节点的重要性h=pagerank(sgs);
a1:计算以节点v为起始节点的游走次数l;
a2:初始化用于存放本次节点序列的列表sequence、记录当前节点nnow=v、记录最大游走次数wl_t=wl;
根据游走路径到达节点x并记录转移概率ptrans,游走路径为:
式中,nx为游走路径的当前节点;ni为游走路径的上一跳节点,是nx的一阶近邻;o(ni)为节点ni的度;
将节点x加入列表sequence,计算节点x的停止概率px-stop:
式中,pstop为预先指定的固定停止概率;sim(ni,nx)为上一跳节点ni和当前节点nx之间未经过归一化的相似性;
判断是否在节点x停止,如果是,结束本次游走,进入下一步,否则,更新游走步长wl_t←wl_t-1和当前节点nnow=x,判断游走次数是否达到l,如果是进入下一步,否则,返回a2;
a3:将本次游走序列加入列表sequences,判断是否所有节点都计算完毕,如果是,进入下一步,否则返回a1;
a4:输出节点序列的列表sequences;
步骤s124:表示学习,对输出的节点序列,通过一个长度固定的采用窗口对近邻进行采样,得到用户的近邻集合,并采用以下公式优化表示学习:
maxf∑u∈vlogp(nu|f(u))
式中,
步骤s125:通过动态截断随机游走获取的节点序列r:
r=dynamictruncatedrandomwalk(sgs,sims,maxt,mint,wl,pstop)
将r作为skip-gram模型的输入,获得节点低维向量φ=skip-gram(d,winl,r)。
若异构信息网络中用户与用户之间存在直接相连的关系,则还包括步骤s130:对用户向量进行修正,具体包括:
步骤s131:指定用户集合
步骤s132:初始化训练数据集d;获取用户u在元结构
步骤s133:将由目标用户、直接近邻、间接近邻组成的三元组添加到训练数据集合;
步骤s134:根据梯度上升算法中的迭代公式更新参数
本文可以通过最大化如下目标函数进行向量修正:
p(θ|>u)∝p(>u|θ)p(θ)(1)
式中:参数θ为用户在指定元结构上的低维向量。
从上式可以看出,优化目标共包含两个部分,其中第一部分与样本数据集有关,第二部分与样本数据集无关。将第一部分改写为如下形式:
并采用下式来代替概率p(ui>uuj|θ):
式中:σ(x)为sigmoid函数。
由于
式中:
式中:d为低维向量的维度,由网络表示学习算法决定;vuk为每一个维度上的向量因子。根据公式(3),本文进一步省略参数θ,将公式(2)简化为如下形式:
而对于第二部分,本文则参考了bpr的想法。因此,在对公式(1)取对数的情况下,整个目标函数最终被转化为如下形式:
本文采用梯度上升算法优化上述目标函数。因此,通过对参数θ求导,可得如下公式:
其中,由于
因此,得到下述梯度公式:
根据公式(10)便可以获得梯度上升算法中用于更新参数的迭代公式:
骤s135:直至用户向量矩阵
所述步骤s200具体包括:
步骤s210:评分预测
参考数据集中用户和项目之间的观测评分,对其进行拼接,将拼接向量当作新的推荐样本xn;
式中,
步骤s220:采用ffm模型计算评分:
式中:w0为全局偏置、wi为第i个特征的相应权重以及
步骤s230:参数学习
采用最小化均方误差学习,获取目标函数
式中:yn为第n个样本的实际评分;n为样本数量;
在目标函数中引入可以用于挑选特征的组lasso,参数p的组lasso正则化具有如下表示:
式中,pg为所有属于第g组的参数,g=1,2,...g;||·||2——l2范数;
将样本xn中由同一个元结构生成的特征归入同一个组,因此样本xn的特征将被分为2l个组,参数w以及v分别有以下正则化公式:
式中:wl为一个维度为d的向量;vl为第1个元结构的特征在所有域上的隐向量构成的矩阵;||·||f为矩阵的frobenius范数;
综合目标函数和正则化公式,优化目标可转换为:
采用非单调加速近端梯度算法nmapg进行模型的优化,输出/得到优化后的特征选择。具体为:
输入:由
d={(xn,yn)n=1,2,3,4,...n}
输出:一阶参数w,二阶参数v
步骤:
将w0和v0初始化为高斯随机矩阵;
fort=1,2,3,...,tdo:
else:
else:
qt+1=ηqt+1;
endfor
returnwt+1,vt+1。
本发明提出基于异构信息网络表示学习的推荐方法,通过设计基于元结构和动态截断随机游走的网络表示学习方法实现推荐系统中用户特征信息和项目特征信息的提取,并进一步分析用户直接近邻和间接近邻的差异,利用贝叶斯个性化排序的思想对用户特征向量进行修正。随后,为避免信息融合过程会造成的不必要推荐损失,本发明放弃将多个用户和项目特征分别整合为一个综合特征的想法,而是将用户和项目的多个特征向量直接作用于推荐过程,通过向量拼接生成推荐样本并将其作为样本特征输入同时考虑特征一阶关系和二阶关系的域感知因子分解机模型进行评分预测。并且,本发明通过在最终的目标函数中加入组lasso作为正则项实现特征的挑选。
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
- 还没有人留言评论。精彩留言会获得点赞!