面向专利咨询的多轮对话生成方法与流程
本发明属于人工智能数据
技术领域:
,具体涉及一种面向专利咨询的多轮对话生成方法。
背景技术:
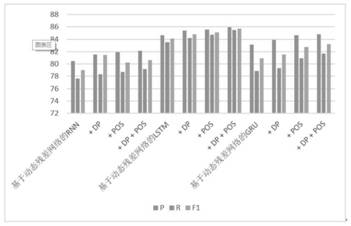
:科技服务业以技术和知识服务社会各行业,是现代服务业的重要组成部分。现有科技咨询的方式主要是先由作为咨询方的个人或企业“提问”,再由具有专业知识并熟悉咨询业务的专家,以科学为依据,以信息为基础,综合利用科学知识、技术、经验、信息筛选合适的科技资源,形成“答案”给予提供。且常常为了更精准的提供“答案”,专家会多次、反复与咨询方进行沟通。可见,“多轮对话”即是科技咨询的实现途径,其结果是否有效则依赖于专家能否准确的筛选、匹配合适的科技资源。随着我国科技服务业的发展,科技资源从数量、种类、分布量均达到了空前的壮大和发展,且分散孤立、动态异构、多样复杂。快速、准确地筛选、匹配合适的科技资源变得愈加困难。除此,由于现有方法过分依赖专家个人,其时间精力、专业知识背景和判断力等参差不齐,也是影响其是否能快速锁定合适的科技资源的关键因素,回答问题的及时性和可用性难以得到保证。为解决传统科技咨询方式存在的过分依赖专家的问题,面对日益动态多变的技术需求环境,全天候、即时可得的智能对话方案成为科技咨询的迫切需求和热点研究方向。近年来,随着大数据和人工智能的发展,机器学习和深度学习方法极大的推动了智能对话的研究进展,智能对话系统在多个领域体现出了其潜在的研究价值和应用价值。科技咨询的内容极具知识性、专业性、隐蔽性和复杂多样性,现有针对日常、商务的智能对话方案难以满足其需求。因此,面向专门领域的科技咨询智能对话方案的研究成为解决问题的关键。其中,专利咨询由于其在科技创新引导和保护,推动实体产业向高质量发展过程中具有的重要支撑作用。面向专利咨询的智能对话方案成为科技咨询研究的首要任务。由于围绕确权、管权、维权等内容,专利咨询不仅涉及技术问题,还涉及诸多经济和法律问题,呈现出多维、多粒度、多领域交叉融合的复杂网络依赖关系,这种科技服务方式不仅服务效率低,并且也造成了大量科技资源的浪费。技术实现要素:本发明所要解决的技术问题便是针对上述现有技术的不足,提供一种面向专利咨询的多轮对话生成方法,该方法能够高效、便捷地实现科技咨询服务,解决了现有专利咨询服务过程中过分依赖专家人工咨询造成的交互自主性、及时性、可用性等问题。本发明所采用的技术方案是:面向专利咨询的多轮对话生成方法,包括以下步骤:(1)专利咨询对话语料的预处理:依次对专利咨询语料进行文本去噪音、中文文本分词、去停用词、文本向量化处理;针对专利咨询语料存在噪音大、专业词汇多、序列长等特点,分别对专利咨询语料进行去停用词、去噪音、分词、文本向量化等数据预处理,为后续构建专利咨询对话模型提供数据质量保证及文本数据的标准化支持。(2)为解决现有方法难以处理对话语料中超长序列依赖以及在编码序列过程中的记忆遗忘等问题,提成了一种基于动态残差网络的自然语言生成模型:根据当前的解码环境,动态的从历史状态集中选择一个最优的状态建立与当前状态的连接,以提高lstm长序列依赖能力,由于引入动态的残差连接后会产生长距离连接依赖词,采用基于强化学习的方法模拟词与词之间的依赖关系,并把产生的长距离依赖关系引入到模型的训练过程中;(3)两阶段的自然语言理解模型:将意图识别和槽位的填充这两个任务进行分离,首先第一阶段基于依存句法分析获取对话语句的意图,然后第二阶段将槽位填充转化为自然语言处理中的序列标注任务,以第一阶段的结果为基础使用深度神经网络进行槽填充,以得到插槽序列和句子级别的意图;自然语言理解模型采用iob(in-out-begin)格式表示插槽标签,输入是对话序列,输出为插槽序列和句子级别的意图,优化的目标是在给定单词序列下,最大化插槽序列和意图的条件似然概率。(4)面向专利咨询的多轮对话模型:包括用户模拟器和端到端的神经对话系统。目前的多轮对话,在实现方法上主要有三类:检索式模型、生成式模型以及混合式模型。检索式的多轮对话生成方法是在给定对话上下文的情况下,尝试从预定义的历史对话模板中找到与当前最相关的上下文响应。可以从历史对话模板中选择适合当前对话环境的人类自然语言。生成的自然语言具有更好的流畅性和可读性。检索式的多轮对话方法也存在着一些不足:对于复杂的对话任务,在多轮迭代的过程中容易丢失某些重要的历史信息;相比生成式的多轮对话方法,基于检索的方法生成的回复往往比较单一,语句缺乏丰富性。生成式对话模型以历史对话信息和当前对话信息作为输入,在与用户不断交互的过程中自动学习对话策略,模型通过不断训练最终学会生成符合人类语言习惯的自然语言。生成的对话语句虽具有一定的多样性,但是,由于受到语言模型的影响,生成式模型易于生成与对话上文不相关的回复。混合式模型是将生成式模型和检索式模型进行了集成,使用检索式方法抽取候选对象,然后将抽取的对象和对话原文一起输入到生成式模型中生成回复内容。结合强化学习构建了多个语言生成模型和语言检索模型。由于模块化的任务型对话模型每个模块均需要单独训练,然后再将每个模块按照一定的逻辑连接起来形成整体模型。现有的方法的主要缺点是每个模块都存在一定的误差,将各个模块连接起来后,不同模块存在的误差将被再次放大。针对模块化的任务型对话存在的缺陷,本方案提出了一种端到端的多轮对话模型,并结合强化学习完成端到端的训练。从而实现咨询服务的交互自主性、及时性、可用性,解决了现有专利咨询服务过程中过分依赖专家人工咨询造成的交互自主性、及时性、可用性等问题。进一步地,文本向量化处理采用word2vec进行文本向量化处理。可以将词编码为固定维度的嵌入表示,且每个维度包含了单词内在的语义信息,可以解决one-hot编码维数灾难和编码语义信息的问题。word2vec中基于分层的softmax的cbow模型中先设置每个词的上下文长度为2n,并以2n个词作为输入;然后将2n个词相加后映射为单个向量,该向量为当前词上下文的抽象表示,映射过程如式2-1所示:cbow模型模拟完形填空的行为,预测空位的单词,首先初始化一个词向量权值矩阵wv∈rv*m,其中v为词表中单词的数量,m为词向量的维度;根据向量矩阵的索引查找输入单词的向量,词向量中的每一行对应一个当前序号的单词向量e;然后将这些上下文对应的词向量进行求和,求和过程如公式2-1所示;接着将xw与词向量权值矩阵wv做点乘,通过权值矩阵wv将xw映射为m维的向量e,计算过程如公式2-2所示;最后用softmax函数求得当前词的概率,计算过程如公式2-3所示:e=wvxw(2-2)word2vec中基于分层softmax的skip-gram模型利用词wi对该词上下文的单词的词向量进行预测,首先初始化一个词向量权值矩阵wv∈rn*d,其中n为词典中词的个数,d为词向量的维度,然后根据词wi与词向量矩阵对应的位置关系将该单词转化为对应的词向量,将词wi进行线性映射得到xw,接着将xw与词向量权值矩阵ev做点乘,通过权值矩阵ev将xw映射为d维的向量e,计算过程如公式2-4所示,最后用softmax函数求得当前词的概率,计算过程如公式2-5所示:e=evxw(2-4)由于基于word2vec的文本向量化方法相比基于one-hot编码的方法可以降低词向量的维度,从而避免在训练过程中由于向量维数过高而造成维数灾难,并且word2vec训练得到的词向量包含单词本身的语义信息,所以文本选择使用基于word2vec的文本向量化方法进行对话语料的文本向量化。由于专利对话语料包含领域知识的特点,这种领域知识大多体现在专有词汇上,而skip-gram相比cbow对专有词汇以及生僻词汇的关注度更高,训练得到的词向量质量更好,所以,本方案优先选择使用skip-gram模型对专利咨询语料进行文本向量化。由于谷歌开源的gensim库已经封装好了基于skip-gram的word2vec方法,且库调用过程简单、便捷,所以本方案采用gensim库中的skip-gram进行专利咨询对话语料的词向量训练。进一步地,用户模拟器包括自然语言生成模型和用户议程模型两个模块。自然语言生成模型是以用户产生的对话动作为输入,根据对话管理模块学习到的对话策略,映射并生成相关的回复;用户议程模型是实现当前用户产生的对话目标后,将当前的用户目标从用户议程模型中弹出。进一步地,端到端的神经对话系统包括自然语言理解模块和对话管理模块两部分。自然语言理解模块是以自然语言生成模块生成的响应为输入,将自然语言解析成其对应的结构化语义框架,以作为对话管理模块的输入;对话管理模块是将整个对话过程中对话状态的追踪以及对话策略的学习,记录、更新和维护每个时刻的对话状态并做出相应的对话响应。对话管理模块以自然语言理解模块生成的结构化语义框架为输入,通过与数据库交互生成相应的系统策略。为了提升多轮对话模型的鲁棒性,使用噪音控制器分别模拟自然语言理解模块以及用户模拟器与系统进行交互产生的噪音,本方案在多轮对话模型中分别引入意图级别的噪音和槽级别的噪音。本发明的有益效果在于:本发明是根据专利咨询语料涉及特定领域知识的特点,设计了面向专利咨询的对话生成方法,该方法能够高效、便捷地实现科技咨询服务,解决了现有专利咨询服务过程中过分依赖专家人工咨询造成的交互自主性、及时性、可用性等问题。附图说明图1为cbow模型框架图;图2为skip-gram模型框架图;图3为静态的残差连接结构示意图;图4为当前状态与选择的最优历史状态的连接过程示意图;图5为两阶段的自然语言理解模型总体框架示意图;图6为基于依存句法规则的意图识别算法总体框架图;图7为移进-归约算法的分析动作示意图;图8为基于深度语义的槽位填充算法框架示意图;图9为添加不同特征的不同类型的深度语义网络在专利对话语料上的效果柱状图;图10为模型在success_rate指标上的实验结果示意图;图11为success_rate指标上的中间实验结果示意图;图12为模型在ave_rewards指标上的实验结果示意图;图13为ave_rewards指标上的中间实验结果示意图;图14为模型在ave_turns指标上的实验结果示意图;图15为ave_turns指标上的中间实验结果示意图;图16为专利咨询对话数据示意图。具体实施方式下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。如图1至图16所示,面向专利咨询的多轮对话生成方法,需要对专利咨询对话语料的预处理,针对专利咨询语料的特点,如对话语句长、噪音大、存在许多专有名词等,对专利咨询语料的预处理方法进行研究,主要包括文本去噪音、中文文本分词、去停用词、文本向量化等,为后续的多轮对话生成方法提供标准化的数据支持。对专利语料进行去噪音处理主要是去除语料中存在的诸如中英文标点符号、表情符号、乱码符号等非法字符,避免对后续的文本向量化及模型效果造成影响。本方案使用正则化的方法对专利语料进行去噪。正则化去除文本噪音主要包含两个过程,即词形还原和词干提取,通过词形还原将词汇进行还原,即将其还原为能够表达语义的最简形式。词干提取是对一个词的主干进行提取,该词的主干并不一定表达完整的语义信息。本方案研究对象为中文专利咨询对话生成,不同于英文文本,中文句子中词与词之间没有空格分隔,因此需要对对话语料进行中文分词处理,分词过程即词义切割的过程,将具有独立含义的词与其它词分割开来。例如在对话句子“著作权的产生是自然取得,即作品完成就自然获得著作权,不需要根据法定程序获得。”中,需要将“著作权”切分为一个独立的词。目前,中文分词技术已经非常成熟,且已存在封装好的分词工具,因此,本方案使用已经封装好的分词工具对专利对话语料进行分词处理。目前主流的分词工具有jieba分词和pyltp。结巴分词主要通过切分词频概率最高的组合,确定分词结果。pyltp是基于python封装的用于分词、词性标注、依存句法分析等功能的自然语言处理工具。pyltp是基于词典和统计机器学习方法相结合的分词算法,相比基于词典的jieba分词方法可以更好的解决分词歧义的问题,因此,本方案优先选择使用基于pyltp的分词方法对专利对话语料进行分词。除了对专利语料进行分词之外,还需要对语料文本进行停用词的去除,即去除语料库中没有实际含义的词,可以将该过程看作是特征筛选,即去除无用特征的过程,除了去除这些没有实际含义的停用词外,对于出现频率非常低的词,也可以将这部分词从语料库中去除。把停用词和出现频率非常低的词从语料库中去除后,通过统计词频以及设置的词频阈值可以得到词典库,用于后续的文本生成。根据对现有成熟工具的调研筛选,本方案优先采用哈工大中英文停用词表去除专利语料中包含的中英文停用词。由于英文的大小写对对话生成过程有一定的影响,本方案将所有的英文字母在文本预处理过程中全部统一为小写。由于专利对话语料是一种离散的非结构化数据,因此,需要将专利对话文本向量化。专利咨询对话语料不同于其它普通文本,对话语料中包含了区别于生活、娱乐信息的领域知识的词汇,因此,公开的基于大量互联网百科数据训练好的词向量难以满足专利咨询文本对话生成的需求。本方案针对专利咨询对话语料包含领域知识的特点,选择合适的文本向量化方法对专利对话语料进行文本向量化表示。目前主流的文本向量化表示模型有两类,一类为传统的one-hot编码表示,第二类为基于word2vec的文本向量化方法。当采用one-hot方法对文本数据进行编码时,首先要根据所有文本数据构建一个词汇表,词汇表大小即为one-hot编码维度,单词与one-hot编码维度一一对应。基于one-hot编码的文本表示产生的词向量的维数较高,并且高度稀疏,在线性模型中极易造成维数灾难和高度的过拟合。由于使用one-hot编码的词向量之间的点乘为0,这意味着每个单词是独立,这一结果使得基于one-hot编码得到的词向量之间不存在语义上的联系。word2vec可以将词编码为固定维度的嵌入表示,且每个维度包含了单词内在的语义信息,可以解决one-hot编码维数灾难和编码语义信息的问题。word2vec包含两种模型,一种为cbow模型,第二种为skip-gram,这两种模型分别用了两种方法进行实现,一种是基于分层softmax的word2vec,另一种是基于负采样的word2vec。word2vec中基于分层的softmax的cbow模型如图1所示,先设置每个词的上下文长度为2n,并以2n个词作为输入;然后将2n个词相加后映射为单个向量,该向量为当前词上下文的抽象表示,映射过程如式2-1所示:最后以一种树形结构对结果进行输出。cbow模型模拟完形填空的行为,预测空位的单词,具体的预测流程为:首先初始化一个词向量权值矩阵wv∈rv*m,其中v为词表中单词的数量,m为词向量的维度,一般根据经验和训练集的大小确定v和m的初始值;根据向量矩阵的索引查找输入单词的向量,词向量中的每一行对应一个当前序号的单词向量e;然后将这些上下文对应的词向量进行求和,求和过程如公式2-1所示;接着将xw与词向量权值矩阵wv做点乘,通过权值矩阵wv将xw映射为m维的向量e,计算过程如公式2-2所示;最后用softmax函数求得当前词的概率,计算过程如公式2-3所示:e=wvxw(2-2)基于分层softmax的skip-gram模型的结构与基于分层softmax的cbow模型具有相同的网络结构,skip-gram模型的结构如图2所示。skip-gram模型训练词向量是基于当前的词预测该词上下文的词向量并以one-hot编码初始化。skip-gram的映射层是线性映射,输入和输出相等。输出层和cbow模型一样,是一种树形结构。利用词wi对该词上下文的单词的词向量进行预测的流程为:首先初始化一个词向量权值矩阵wv∈rn*d,其中n为词典中词的个数,d为词向量的维度,然后根据词wi与词向量矩阵对应的位置关系将该单词转化为对应的词向量,将词wi进行线性映射得到xw,接着将xw与词向量权值矩阵ev做点乘,通过权值矩阵ev将xw映射为d维的向量e,计算过程如公式2-4所示,最后用softmax函数求得当前词的概率,计算过程如公式2-5所示:e=evxw(2-4)由于上述cbow模型和skip-gram模型的输出层是一种复杂的树形结构,计算量较大且训练速度慢,对此,一种负采样技术被应用于word2vec。负采样不再使用复杂的树形结构作为神经网络的输出层,而是利用随机负采样,该方法相当于是对基于树形结构的word2vec的一种改进。基于负采样的word2vec通过对需要预测词向量的单词定义其对应的正样本和负样本,然后最大化正样本出现的概率,同时缩小负样本出现的概率,从而训练得到单词的词向量。由于基于word2vec的文本向量化方法相比基于one-hot编码的方法可以降低词向量的维度,从而避免在训练过程中由于向量维数过高而造成维数灾难,并且word2vec训练得到的词向量包含单词本身的语义信息,所以文本选择使用基于word2vec的文本向量化方法进行对话语料的文本向量化。由于专利对话语料包含领域知识的特点,这种领域知识大多体现在专有词汇上,而skip-gram相比cbow对专有词汇以及生僻词汇的关注度更高,训练得到的词向量质量更好,所以,本方案选择使用skip-gram模型对专利咨询语料进行文本向量化。由于谷歌开源的gensim库已经封装好了基于skip-gram的word2vec方法,且库调用过程简单、便捷,所以本方案采用gensim库中的skip-gram进行专利咨询对话语料的词向量训练。预处理的工作为后续的面向专利咨询的多轮对话生成模型提供数据质量保证和文本数据的标准化支持。现有的基于lstm的seq2seq自然语言生成模型难以处理对话语料中超长序列依赖以及在编码序列过程中的记忆遗忘等问题,因此,该模型在处理长序列的语言生成任务时往往会造成重要信息的丢失。为此,本方案提出了一种基于动态残差网络的自然语言生成模型,该方法根据当前的解码环境,动态的从历史状态集中选择一个最优的状态建立与当前状态的连接,以提高lstm长序列依赖能力。但由于引入动态的残差连接后会产生长距离连接依赖词,对此,提出了一种新的基于强化学习的方法模拟词与词之间的依赖关系,并把产生的这种长距离依赖关系引入到模型的训练过程中去。在基线模型结构的基础上引入了一种动态的残差网络,提出了一种基于动态残差网络的自然语言生成模型,并结合一种新的强化学习策略完成模型的训练。主要分三个部分来阐述所提出的模型:(1)基线模型;(2)基于动态残差网络的自然语言生成模型;(3)基于强化学习的训练过程。本方案基线模型采用一种pointer-generatornetworks模型。pointer-generatornetworks是一种特殊的基于注意力机制的sequence-to-sequence模型,该模型是通过从原文中复制单词或从词汇表中生成单词来生成对话句子,其中,编码器部分使用的是单层双向的lstm,编码输入的上下文信息,使用表示由n个词形成的demb维的词嵌入向量(wordembeddings)矩阵,hfwi和hbwi分别表示第i时刻编码器中单层双向的lstm输出的前向隐藏状态和后向隐藏状态,hfwi和hbwi均是dhid维的向量,henci表示第i时刻包含编码器前向信息和后向信息的隐藏状态。如下式所示:传统的encoder-decoder模型基于词汇表生成当前所需的对话语句。注意力机制能够根据当前的对话环境关注到历史对话信息,通过对不同时刻的历史对话信息进行加权获得作为对当前解码对话的特征补充。在每一个时间步t,模型根据公式3-2计算当前的注意力分布,其中以及batten是需要学习的参数。pointer-generatornetworks模型的解码器使用的是单向的lstm,负责将编码器编码的历史对话信息解码为当前对话信息,hdect表示解码器第t时间步的隐藏状态,假设输入对话序列的长度为l,则上下文向量c*t可以表示为式3-3。为了从词汇表中生成词汇,需要知道词汇表中所有词汇的分布pvocab(c*t),pwvocab(c*t)表示了在当前解码时间步解码出词w的概率,其中w、w′、b和b′都是需要学习的参数。pointer-generatornetworks模型既可以使用pointer从词汇表中生成词汇,也可以通过copymechanism从历史对话信息中复制词汇。对于解码时间步t,可以根据上下文向量c*t、解码器当前的状态st以及解码器的当前输入xt,计算一个生成概率pgen∈[0,1],pgen用来决定模型从词汇表中生成词汇而不是从历史对话信息中复制单词的概率,pgen的计算可以表示为式3-5。其中以及bgen都是需要学习的参数,σ表示sigmoid函数。然后使用pgen对词汇表中所有词汇的分布pvocab(c*t)和注意力分布αti进行加权平均,从而得到扩展词汇表的词汇分布pwexten。如果词w是未登录(oov)词,则pvocab(c*t)为零,同样,如果词w未出现在源文档中,则∑i:wiαti为零,所以,pointer-generatornetworks解码的词汇不再局限于词汇表,具有产生未登录词的能力。基线模型通过使用pointer从词汇表中生成词汇,使用copymechanism从历史对话信息中复制单词,从而解决了未登录词(oov)的问题。然而,基线模型是基于lstm的sqe2sqe框架,模型仍然存在长距离依赖方面的局限性,在处理轮数较多的多轮对话任务时会丢失很多重要的信息,为此,将一种具有动态残差连接的lstm引入到模型的解码器中,提出一种基于动态残差连接的自然语言生成模型。综上,本方案提出一种基于动态残差连接的自然语言生成模型,该模型由两部分组成:第一部分为由静态残差网络连接的并经过一维卷积融合前后向信息的编码器,第二部分是具有动态残差网络连接的解码器,下面将对这两部分进行详细的阐述。模型的编码器采用单层双向的lstm,为了避免梯度消失,提升网络的训练效果,在编码器部分加入了静态的残差连接,即将前一时刻的输入与其对应的输出叠加一次,其原理如图3所示。其中ht-1为t时刻的输入,ht为t时刻对应的输出,由式3-7得到经静态残差连接后的t+1时刻的输入ht。由于每一层参与计算的输入增加了一项前一时刻的输出状态ht-1,那么该层变量求导的时候就多了一个常数项,所以在反向传播梯度连乘的过程中就不容易造成梯度消失。由于编码器使用的是单层双向的lstm,编码器每个时刻会输出前向状态hfwt和后向状态hfwt两个状态的信息,在每个编码时刻使用一个一维卷积网络对生成的前向信息和后向信息进行融合,卷积操作。如公式3-8,假设句子长度为l,hfw1-l表示序列产生的前向信息,hbw1-l表示序列产生的后向信息,将一维卷积的卷积核大小设为1,即一层卷积窗口为一个单词的状态信息(hfw1-l,hbw1-l)的一维卷积神经网络。最后,将编码器最终的输出状态作为解码器的初始化状态。具有动态残差连接的解码器由两部分组成,即强化学习agent和动态连接。其中强化学习agent会根据当前的解码环境反复的从历史对话状态集中选择一个最优的状态作为下一时刻的输入;动态连接是指agent会跨时间的从多个历史对话状态中动态的选择最优的状态,并实现与当前状态的连接。如公式3-9,3-10所示,在观察当前的解码状态st后,然后创建存储历史状态的集合sk。agent将会执行一个action,即从k个历史隐藏状态集sk中取样一个最优的状态st-k,其中k属于1,2,...,k且k值是提前设定好的。选中的历史状态将直接与当前时刻的输入相连。为了获得与当前解码环境最相关的历史状态,使用一个前馈神经网络根据当前时刻的解码环境得到k个历史状态的概率分布p。p=softmax(ffl(st))(3-10)其中,ffl根据当前的解码状态st得到一个k维的向量,然后经过softmax函数得到k个历史状态的概率分布。得到历史隐藏状态的概率分布后,agent需要依据多项分布从集合sk中选择一个最优的状态与当前的输入进行连接,如公式3-11所示:如果k=i,则[k=i]等于1,否则[k=i]等于0,pi表示历史状态的概率分布p中的第i个元素,最后,被选中的最优历史状态st-k被转化为lstmcell参与进一步的运算。agent从历史状态集sk中动态选择的最优状态,将会作为当前解码器的状态输入,从而达到动态连接的效果,其结构如图4所示,其中λ为agent选择的历史最优状态与当前隐藏状态建立连接时所占的权重,σ和tanh分别指的是sigmoid函数和tanh函数。首先,需要获得当前隐藏状态的表示,即前一时刻隐藏层的输出状态(ct-1,st-1)与从历史状态集sk中选中的与当前解码环境最相关的历史对话状态(ct-k,st-k)进行加权,权重系数用λ表示。由式3-12和式3-13得到基于动态残差连接的解码器t-1时刻的解码状态模型的训练目标就是优化强化学习策略产生的参数σ*以及标准lstm包含的参数σα,定义pw(σα)为基线模型下生成词w的概率,则loss1σα为相应的损失函数,如式3-14:用loss2σ*表示强化学习策略下产生的损失函数,agent的目的就是最大化在这种动态连接策略下的期望激励,使用e表示交叉熵运算,如式3-15:其中,φ(a1:t)=∏tt=1φk(at|st;δ*),ψ(φ(a1:t))=-eφ(a1:t)[logφ(a1:t)]表示熵正则化,加入熵正则化项是为了防止熵在计算的过程中过早的崩塌以及促使这种强化学习策略能够探索更多的不同空间。模型的最终损失函数为基线模型下产生的损失函数loss1σα与强化学习策略下产生的损失函数loss2σ*的加和,如式3-15:loss(δa,δ*)=loss1(δa)+loss2(δ*)(3-16)为支持用户咨询问题的识别与理解,结合专利对话语料的特点,提出了一种两阶段的自然语言理解模型。自然语言理解模块的主要任务是进行意图识别,并进行槽填充以形成结构化的语义框架,以此作为对话管理模块的输入。提出的两阶段的自然语言理解模型将这两个任务进行分离。首先,第一阶段基于依存句法规则获取对话语句的意图,然后,第二阶段将槽位填充转化为自然语言处理中的序列标准任务,以第一阶段的结果为基础使用深度神经网络进行槽填充。由于专利咨询对话语料涉及到专利领域的知识,比如著作权、商标、专利、商业秘密等,经过对大量的专利对话语料研究发现,每条对话语句的意图往往位于该对话语句的主语部分且为名词,同时对话语句的意图也是整个对话语句阐述的主要对象,比如对话语句“商业秘密保护的对象是什么?”,该对话语句阐述的主要对象为“商业秘密”,“商业秘密”位于该对话语句的主语部分且为名词,根据该特性,本方案首先使用依存句法规则得到对话语句的意图,然后以获得的对话意图作为第二阶段深度语义网络的特征补充来进行槽位的填充,从而得到结构化的语义框架。两阶段的自然语言理解模型的原理如图5所示。第一阶段使用依存句法规则算法得到对话语句的依存句法成分,然后从得到的依存句法成分中提取其中的主语成分得到对话语句的意图,该过程使用的依存句法规则算法属于无监督算法,该算法准确率高且无需人工标注数据。当提取的对话意图达到一定量级时,这些被提取的对话意图将作为第二阶段算法的补充特征,从而提升第二阶段深度语义算法的准确率。第二阶段以第一阶段算法获得的句子级别的意图为补充特征使用深度语义网络对专利对话语料进行槽位填充,从而得到每条对话语句结构化的语义框架,作为对话管理模块的输入。为了进一步提升该阶段算法的性能,使用一种基于动态残差网络的lstm作为深度语义网络的基础。通过对专利对话语料的分析发现,词性特征和依存句法特征对于深度语义网络进行语义理解至关重要,因此,将词性信息和依存句法信息同时作为深度语义网络输入的一部分,进一步增强深度语义网络的自然语言理解能力。通过对专利对话语料进行分析发现,专利对话语料涉及专利领域的知识,每轮对话阐述的主要对象大多涉及到专利领域的专有名词,比如著作权、商标、专利、商业秘密等,这些被阐述的主要对象即为对话意图,根据该特性,首先使用依存句法规则算法获得每条对话语句的依存句法成分,然后从获得的依存句法成分中抽取主语部分即得到对话语句的意图。基于依存句法规则的意图识别算法框架如图6所示。该算法以词性信息作为依存句法规则的辅助特征对专利对话语料进行分析,从而得到专利对话语料的依存句法成分,然后抽取其中的主语部分作为最终的对话意图。其中token1token2...tokenk代表分词后专利对话语料词序列,pos1pos2...posk和dp1dp2...dpk分别代表词序列对应的词性序列和依存语法成分序列,s1s2...sk表示最终得到的对话意图。使用pyltp进行句法分析,pyltp进行句法分析的原理是以词性作为辅助特征对专利对话语料进行句法分析。在pyltp中,封装了词性标注方法,pyltp进行词性标注的原理是将词性标注映射为对词做词性的序列标注任务,即将分好词的文本进行词性的序列标注,输入是分好词的词序列,输出为对应词的词序列。依存句法规则是一种建立在依存语法理论上的对文本进行分析的方法,如下表所示,共有24种中文依存句法关系。依存关系符号依存关系符号定中关系att关联结构cnj数量关系qun语态结构mt并列关系coo独立结构is同位关系app状中结构adv前附加关系lad动补结构cmp后附加关系rad“的”字结构de动宾关系vob“地”字结构di介宾关系pob“得”字结构dei主谓关系sbv“把”字结构ba比拟关系sim“被”字结构bei核心hed独立分句ic连动结构vv依存分句dc移进-归约算法通过执行一系列的动作,不断对对话语句进行定点标注,从而确定标注对象的依存句法成分。该算法主要包含三个动作,分别为:shift(移进)、right-reduce(右归约)和left-reduce(左归约)。在遍历对话语句的过程中,使用该算法定义的三种动作建立句子的依存句法关系,不同的依存句法关系之间构成了依存句法子树。依照nivre,2003a对分析动作的表示方式,用图7来解释移进-归约算法是如何使用这三种分析动作。其中w表示目标词(targetnode)窗口,窗口大小为2,表示在移进过程中每次遍历相邻的两个词;a用于存储遍历的结果;i表示词在当前序列中的位置,同一个词在多次循环中所处的位置可能不同。当窗口遍历到某一目标词上时,分析并提取目标词的上下文信息,该部分信息将作为目标词的辅助特征被送入分类模型中进行分析动作的预测,最后,执行预测动作以扩充依存关系集合a和推进分析窗口。分类器训练实例的提取即在带有依存结构的训练语句上重复此分析过程,得到分析动作-特征向量对。在图7中,横线上方表示当前关注的“目标词”窗口,横线下方表示执行相应分析动作之后的结果。基于深度语义的槽位填充算法由基于动态残差的循环神经网络(包括rnn、lstm、gru)组成,基于动态残差的循环神经网络由两部分组成,即强化学习agent和动态连接,其中,强化学习agent根据当前的解码环境反复的从历史状态集中选择一个最优的状态作为下一时刻的输入;动态连接通过agent跨时间的从多个历史状态中动态的选择最优的状态,并实现与当前状态的连接。基于动态残差的循环神经网络相比标准循环神经网络具有更好的长期记忆能力,善于挖掘更深层的语义信息。本方案将自然语言理解的槽位填充看作是自然语言处理中的序列标注任务,并使用ibo的标注方法,其中b表示槽位信息的首字符,i表示槽位信息的中间字符和尾字符,o表示非算法所需的字符。基于深度语义的槽位填充算法框架如图8所示。基于深度语义的槽位填充算法的网络结构依次为对话序列层、特征输入层、特征编码层、映射层和输出层(插槽序列),其中,w1w2...wn表示对话序列,e1e2...en表示向量化表征序列,s1s2...sn∈[b,i,o]表示插槽序列,pos表示词性特征序列,dp表示依存句法特征序列,fc表示映射层,h表示特征编码层,整个过程共享特征编码层h和映射层fc的参数。特征编码层分别使用三种循环神经网络,分别为基于动态残差的lstm、基于动态残差的gru以及基于动态残差的rnn。由于标准的循环神经网络(rnn、lstm以及gru)在存在长距离依赖的局限性,在编码语义的过程中往往会丢失某些重要的信息。为了提升循环神经网络的编码记忆能力,此处使用一种基于动态残差的循环神经网络。基于动态残差的循环神经网络能够根据当前的编码环境动态的从历史状态集中选择一个最优的状态建立与当前状态的连接,以提高循环神经网络的编码记忆的能力。以基于动态残差的lstm为例,对基于深度语义的槽位填充算法进行详细阐述。基于动态残差的lstm由两部分组成,即强化学习agent和动态连接,其中强化学习agent根据当前的解码环境反复的从历史状态集中选择一个最优的状态作为下一时刻的输入;动态连接是指agent会跨时间的从多个历史状态中动态的选择最优的状态,并实现与当前状态的连接。agent将前一时刻的隐藏状态st-1和当前的输入xt进行连接作为当前解码器的状态表示st,其中表示连接操作,如式4-1所示:在观察当前的解码状态st后,会创建存储历史状态的集合sk。agent将会执行一个action,即从k个历史隐藏状态集sk中取样一个最优的状态st-k,其中k属于1,2,...,k且k值是提前设定好的。选中的历史状态将直接与当前时刻的输入相连。为了获得与当前解码环境最相关的历史状态,我们使用一个前馈神经网络根据当前时刻的解码环境得到k个历史状态的概率分布p,如式4-2所示:p=softmax(ffl(st))(4-2)其中,ffl根据当前的解码状态st得到一个k维的向量,然后经过softmax函数得到k个历史状态的概率分布。得到历史隐藏状态的概率分布后,agent需要依据多项分布从集合sk中选择一个最优的状态与当前的输入进行连接,如式4-3所示:如果k=i,则[k=i]等于1,否则[k=i]等于0,pi表示历史状态的概率分布p中的第i个元素,最后,被选中的最优历史状态st-k被转化为lstmcell参与进一步的运算。agent从历史状态集sk中动态选择的最优状态,并作为当前解码器的状态输入,从而达到动态连接的效果。首先,我们需要获得当前隐藏状态的表示,即前一时刻隐藏层的输出状态(ct-1,st-1)与从历史状态集sk中选中的与当前解码环境最相关的历史状态(ct-k,st-k)进行加权,权重系数用λ表示,如式4-4、4-5所示:面向专利咨询的多轮对话模型包含两大模块,即用户模拟器和端到端的神经对话系统。其中用户模拟器包括自然语言生成模型和用户议程模型两个模块。端到端的神经对话系统包括自然语言理解模块和对话管理模块两部分。用户首先产生用户目标,用户议程模型根据用户提供的用户目标,将当前的用户目标从用户议程模型中弹出,输出相应的对话动作。自然语言生成模块以用户模拟器输出的对话动作为输入,根据对话管理模块学习到的对话策略,映射并生成相关的回复。自然语言理解模块以自然语言生成模块生成的相关响应为输入,通过意图识别和槽位填充生成结构化的语义框架,以作为对话管理模块的输入。对话管理模块以自然语言理解模块生成的结构化语义框架为输入,通过与数据库交互生成相应的系统策略,将整个对话过程中对话状态的追踪以及对话策略的学习,记录、更新和维护每个时刻的对话状态并做出相应的对话响应。为了提升多轮对话模型的鲁棒性,使用噪音控制器分别模拟自然语言理解模块以及用户模拟器与系统进行交互产生的噪音,本方案在多轮对话模型中分别引入意图级别的噪音和槽级别的噪音。由于模块化的任务型对话模型每个模块均需要单独训练,然后再将每个模块按照一定的逻辑连接起来形成整体模型。该类方法的主要缺点是每个模块都存在一定的误差,将各个模块连接起来后,不同模块存在的误差将被再次放大。针对模块化的任务型对话存在的缺陷,本方案提出了一种端到端的多轮对话模型,并结合强化学习完成端到端的训练。为了对提出的面向专利咨询的多轮对话模型进行端到端训练,需要模拟用户行为与神经对话模型进行自动交互,因此,用户模拟器的作用是模拟人的行为在对话过程中不断与神经对话系统进行交互产生对话响应。在多轮对话模型运作过程中,用户模拟器根据用户输入生成用户目标,然后用户议程模型根据用户目标确定相应的对话动作。在对话过程中,用户目标是整个对话过程的中心,整个对话过程的目标是实现用户模拟器产生的用户目标。用户目标由通知槽和请求槽两部分组成,其中,通知槽是包含用户可查询信息的插槽,请求槽主要用于当用户没有任何信息但想要在对话期间从agent代理那里获取值的插槽,即获取插槽值的过程就是获取信息的过程。在进行专利咨询的对话过程中,用户议程模型的主要作用是存储和弹出用户产生的对话动作。由于在对话的过程中对话系统优先实现当前用户产生的对话目标,在实现当前用户目标后,将当前的用户目标从用户议程模型中弹出,因此,用户议程模型的实现形式使用的是一种类似堆栈的数据结构,从而实现用户对话动作的出栈和入栈。本方案的需求和数据来源于实际的专利咨询场景,由于面向专利咨询的对话语料并非开源的公开数据集,所以数据量级较小,为了在有限的标签数据下保证用户模拟器的质量,本方案采用基于模板和基于生成的自然语言生成模型两种方法生成对话语句。通过基于动态残差网络的自然语言生成模型在带有标签的对话语料上进行训练,得到基于生成的自然语言生成模型。基于生成的自然语言生成模型以用户议程模型产生的对话动作作为输入,通过基于动态残差的encoder-decoder结构解码生成带有插槽占位符的句子草图,然后根据用户的对话信息,将插槽占位符替换为其对应的真实值,从而生成对话语句。基于模板的自然语言生成模型首先要对专利对话语料构建对话模板,对话模板使用字典的形式进行构建,即定义对话动作和对话动作对应的响应内容。如果用户产生的对话动作在预定义的对话模板中存在,则优先使用基于模板的自然语言生成模型生成对话,否则使用基于生成的自然语言模型生成对话。端到端的神经对话系统由自然语言理解模块和对话管理模块两部分组成,对话管理模块是以自然语言理解模块输出的对话意图以及具体的插槽序列为输入,确定当前的对话状态,并根据历史对话信息,决定当前的对话响应。对话管理包含对话状态追踪和策略学习两大模块。对话状态追踪的主要功能是记录、维护和更新整个对话过程的对话状态,确定当前用户的对话目标。策略学习的主要目标是根据对话状态追踪模块提供的对话状态生成下一个对话动作,辅助对话模型学习对话策略。对话状态追踪在给定自然语言理解模块输出结果的基础上执行三个方面的功能:1)根据当前的对话信息,从数据库中检索当前所需的结果;2)根据从数据库中查询的结果以及当前的用户对话操作对当前的对话状态进行更新;3)为策略学习提供对话状态表示。对话状态的表示形式包括:当前用户的对话行为、当前系统agent操作以及从数据库中检索的结果。根据状态追踪器生成的状态表示st,对话模型将学习相应的对话策略π,并生成下一个对话动作。为了学习对话模型在对话交互过程中的对话策略,此处使用一种基于强化学习的策略学习算法对对话管理模块进行训练,以学习到对话模型与环境的交互策略。该强化学习方法为dqn网络,在策略学习过程中使用两个dqn技巧:目标dqn网络和经验回放。强化学习和深度学习相比,由于对话状态在不断变化,不同的对话状态所产生的对话行为也不同,造成在训练过程中优化目标不断变化,为此,本方案使用目标dqn网络学习对话策略。在模型训练的每个模拟时期,一次性模拟100个对话过程,在单个模拟时期,当前dqn网络的参数不断被更新,用于学习当前对话过程的对话策略。在每个模拟时期的最后,目标dqn网络被当前dqn网络的参数进行初始化,即在单个模拟时期,目标dqn网络只被更新一次,因此,在每个模拟时期,当前dqn网络的优化目标是固定的,即当前dqn网络的优化目标为当前模拟时期目标dqn网络的对话策略。由于本方案使用的是领域对话语料,数据量级较小,为了在有限的标签数据下提升模型学习对话策略的性能,此处使用一种经验回放策略来存储对话过程中积累的状态转移元组。在模型训练的过程中涉及到两个参与对话过程的agent,即基于规则的agent和基于强化学习的agent。在训练的前期,由于基于规则的agent的对话性能高于基于强化学习的agent的对话性能,因此,经验池里的状态优先存储基于规则的agent产生的状态转移元组。随着模型的训练,基于强化学习的agent的对话性能不断提升,当基于强化学习的agent的对话性能高于基于规则的agent的对话性能阈值时,基于强化学习的agent产生的对话状态开始填充经验池,该过程称为经验回放。通过经验回放策略,保证了模型在训练前期的稳定性,有利于模型收敛,从而学习到正确的对话策略。由于在多轮对话模型训练和测试的过程中会产生基于对话行为的语义框架,而该语义框架与模型最初输入的对话语句存在非线性的映射关系,在语义映射的过程中往往会引入各种噪音,对此,为了提升多轮对话模型的鲁棒性,使用噪音控制器分别模拟自然语言理解模块以及用户模拟器与系统进行交互产生的噪音,本方案在多轮对话模型中分别引入意图级别的噪音和槽级别的噪音。(1)意图级别的噪音本方案对专利对话语料涉及到的意图类别分为三类,第一类:问候、致谢以及结束语;第二类:用户可以提供给对话agent的槽值,例如,inform(object=“商业秘密”,description=“保护对象”),该插槽及插槽对应的值描述的是关于“商业秘密”的“保护对象”;第三类:用户可以在对话过程中向对话agent请求的信息,例如,request(object=“著作权”,description),该插槽表示的是用户对于“著作权”相关信息的提问。在进行专利咨询的对话过程中,会存在多个通知和请求意图,例如,请求咨询的对象、请求咨询对象的类型以及产生形式等。针对以上意图类别,使用噪音控制器引入三种类型的噪音,随机噪音:来自同一意图类别或不同意图类别之间的噪音;组内噪音:引入的噪音和真实意图属于同一类别,例如,真实意图是request(object),但是自然语言理解模块预测的意图可能是request(description);组间噪音:引入的噪音来自不同的类别,例如,对话模型可能将request(object)预测为inform(object)。(2)槽级别的噪音噪音控制器引入三种槽级别的噪音,删除槽:用于自然语言理解模块不能识别的槽;错误槽值:可以正确识别槽位,但不能识别槽值的槽;错误槽:不能正确识别槽位及其槽值的槽。上述描述从两个方面对本方案提出的面向专利咨询的多轮对话模型进行验证。首先在公开数据集上,对所提出的算法性能进行实验验证,根据实验结果及对实验结果的分析,验证了算法的性能。然后,为验证本方案提出的面向专利咨询的多轮对话生成方法的有效性,使用课题组提供的专利对话数据集对本方案所提的算法模型进行应用层面的验证,并与平台现有的专利咨询方法进行对比,验证其有效性。基于动态残差网络的自然语言生成模型对比实验,此处将提出的基于动态残差网络的自然语言生成模型应用于文本生成任务以验证所提算法的性能。由于文本摘要是经典的文本生成任务,因此,将该部分的实验应用于文本摘要任务上验证算法的性能,即输入为原始文本,输出为原始文本对应的摘要。在该实验部分,使用cnn/dailymail数据集对提出的基于动态残差网络的自然语言生成模型的性能进行评估。cnn/dailymail数据集有匿名和非匿名两种版本,匿名版本是经过预处理以替换每一个命名性实体的数据,非匿名版本的是没有经过预处理的源数据,相比之下,由于非匿名版本的cnn/dailymail数据集对于一个模型更具有挑战性,因此,使用和相同版本的非匿名cnn/dailymail数据集进行实验。数据集中包含224698对训练数据12241对验证数据以及10446对测试数据,每对数据由源文档及其对应的摘要两部分组成。该实验部分使用tensorflow搭建神经网络,并使用nvidia2070gpu配置设备进行实验,在整个实验过程中,模型隐藏状态的维度设为256维,词向量维度设为128维,词表大小为50k。模型使用adagrad作为优化器,学习率设为0.15。在整个训练和测试的过程中,输入的原始文档最大长度设为400个词。在训练的过程中,生成结果的最大长度设为100个词。在测试的过程中,生成结果的最大长度为120个词。在编码器中,加入一维卷积神经网络融合编码器每个时刻输出的前后向信息,该一维卷积神经网络的卷积核大小设为1,激活函数选用relu函数,输入和输出层的维度设为256维,一维卷积神经网络中间层维度设为1024维。在解码器中,由于引入了一种动态的残差网络来从历史状态集中选择一个与当前解码状态最相关的历史状态作为当前的输入,所以需要提前创建一个存储历史状态信息的容器。在整个实验过程中,模型通过训练学习从存储历史状态集的容器中选择的历史状态在当前输入中占的比重λ初始化为0.5。该实验使用标准的rouge指标评估本方案的模型。常用的rouge指标有rouge-1、rouge-2以及rouge-l,使用这三种指标的f1值进行评估。在cnn/dailymail数据集上的实验结果如下表所示,实验结果表明,本方案的模型相比抽取式的baselinemodel与生成式的baselinemodel得到了显著提升,其中,抽取式模型包括summarunner(nallapatietal.,2017)、summarunnerabs(summarunner-abs与summarunner相似)和lead-3(抽取每篇文章的前三句话作为输出结果),生成式模型包括point-cov(seeetal.,2017)、deeprl(paulusetal.,2017)、sumgan(liuetal.,2018)以及rsal-entrl(pasunuruandbansal,2018)。根据上表可以看出,提出的模型相比baselinemodel取得了显著提升。对比其它的抽取式和生成式模型,所提模型在rouge-1、rouge-2以及rouge-l的实验结果上也有不同程度的提升。所提出的模型相较于抽取式模型summarunner提升了+0.95rouge-1、+1.15rouge-2以及+1.97rougel,相较于抽取式模型summarunner-abs提升了+3.05rouge-1、+2.85rouge-2以及+3.87rouge-l,相较于抽取式模型lead-3提升了+0.21rouge-1、+0.7rouge-l,rouge-2的f1值有所下降。所提模型相较于ourbaselinemodel(point-cov)提升了+1.02rouge-1、+0.07rouge-2以及+0.89rouge-l,相较于其它代表性的生成式模型(deeprl、sumgan、rsal-entrl)在rouge-1、rouge-2以及rouge-l上都有不同程度的提升。从baselinemodel(point-cov)和本方案的模型的实验结果中抽出部分示例进行对比,在原始文档中,事件“hewasreleased”距离该事件发生的时间“lastweek”较远,相较于baselinemodel,我们的模型能够成功的捕捉到该时间信息,表明所提模型相比baselinemodel具有更强的捕捉长距离依赖关系的能力。原始文档中事件发生的原因“theydidn’thaveenoughevidencetoproveacaseagainsthim”应该属于比较重要的信息,但是baselinemodel生成的摘要中却丢失了该部分信息,相较于baselinemodel,我们的模型可以从原始文档中选择更多重要的信息,具有更强的自然语言生成能力。两阶段的自然语言理解模型对比实验,该实验使用专利对话数据集验证本方案提出的两阶段的自然语言理解模型的有效性。首先基于依存句法规则得到对话语料的对话意图,在此基础上,分别使用三种基于动态残差网络的循环神经网络(rnn、lstm以及gru)对对话语料进行槽位填充。此处将槽填充映射为序列标注任务,并使用bio方法对专利对话语料进行标注。分别对三种基于动态残差网络的循环神经网络进行对比实验,并对实验结果进行分析。该实验部分,使用课题组提供的483条专利咨询的对话数据集进行实验。根据专利咨询对话语料涉及专利领域知识的特点,本方案对专利对话语料定义五种对话意图,分别为:商业秘密、著作权、商标、专利、侵权,将这五种意图分为三类,第一类:问候、致谢类;第二类:用户可以提供信息的槽值;第三类:用户可以请求查询的槽信息。本方案对专利对话语料定义28种槽类型,分别是:问候、结束语、类型、发明、发明创造、保护对象、产生形式、注册形式、描述、功能、专利权、转让、合同、权力形式、出资形式、申请对象、办理手续、登记形式、行政法规、标记形式、申请程序、外观设计、实用新型、集体商标、商标形式、处置行为、许可方式、出资入股。该部分实验首先使用哈工大社会计算与信息检索研究中心的语言技术平台的python封装版本pyltp进行词性标注和依存句法分析。然后使用tensorflow搭建基于动态残差网络的深度语义网络,使用gensim导入词向量,使用nvidia2070gpu配置设备进行实验。在整个实验过程中,模型隐藏层的维度设为256维,词向量维度设为128维,词表大小为50k。模型使用adam作为优化器,学习率设为0.001。在该部分实验使用精确率p、召回率r以及f1值作为判定模型性能的评价指标。精确率、召回率和f1值的计算公式如(6-1)~(6-3)所示:其中,tp表示真正例(truepositive)、fp表示假正例(falsepositive)、tn表示真反例(truenegative)、fn表示假反例(falsenegative)。该部分实验首先使用pyltp对专利对话语料进行依存句法分析,得到专利对话语料的依存句法成分,抽取其中的主语成分得到对话语句的对话意图。然后以得到的对话意图作为辅助特征,分别使用基于动态残差网络的rnn、lstm以及gru进行槽位的填充。本方案分别将词性特征和依存句法特征分别加入到基于动态残差的深度语义网络的训练过程中,从而进一步加强神经网络的语义编码能力。实验结果如下表所示。如上表所示,使用准确率(p)、召回率(r)和f1值作为评价指标,分别选取基于动态残差网络的rnn、lstm以及gru作为基线模型,并加入依存句法信息(dp)和词性标注信息(pos)作为辅助特征进行实验并对实验结果进行统计。根据上表的实验数据绘制的柱状图如图9所示,进行分析可发现,基于动态残差网络的lstm和基于动态残差网络的gru相比基于动态残差网络的rnn在专利对话数据集上具有更高的精确率和召回率。三种深度语义网络在加入词性特征和依存句法特征后相较于基线模型在精确率和召回率指标上均有不同程度的提升,但基于动态残差网络的rnn在加入词性特征和依存句法特征后提升效果并不明显,并且在加入词性特征后,基于动态残差网络的rnn在f1值指标上反而有所下降。经分析,由于rnn本身的结构比较简单,当加入过多的辅助特征时,在模型训练的过程中,rnn难以编码复杂的语义语法信息,从而造成基于动态残差网络的rnn算法性能下降。进行多轮对话模型对比实验,前面分别对多轮对话模型中的自然语言生成模块和自然语言理解模块进行了算法性能的验证。使用公开数据集电影票预订对话数据集对本方案提出的多轮对话模型进行整体算法性能的验证,并对实验结果进行分析。该部分实验使用的电影票预订对话数据集是由amazonmechanicalturk收集,并经领域专家提供了标注。数据集中共包含270个对话,每个对话平均轮数为11。经标注的对话数据包含11种对话行为,分别为:request,inform,confirm_question,confirm_answer,greetingclosing,multiple_choice,thanks,welcome,deny,not_sure。对话数据集包含29个插槽,分别为:actor,actress,city,closing,critic_rating,date,description,distanceconstraints,genre,greeting,implicit_value,movie_series,moviename,mpaa_rating,numberofpeople,numberofkids,taskcomplete,other,price,seating,starttime,state,theater,theater_chain,video_format,zip,result,ticket,mc_list。在电影票预订对话数据集中,大多数为inform种类的插槽和request种类的插槽。inform种类的插槽是用于向用户提供用户所需的信息,限制用户进一步的搜索。request种类的插槽用于用户向对话系统发出请求,从对话代理那里获取对应插槽的值。本方案基于python编程语言,使用tensorflow深度学习框架进行多轮对话算法的开发。在数据处理方面,本文使用scikit-learn中集成的numpy、pandas等数据库进行对话语料的预处理。由于整个多轮对话模型包含多个由深度神经网络构成的模块,训练过程中对硬件配置要求较高,该部分实验使用到的硬件配置如下表所示。处理器intel(r)core(tm)i7-8700kcpu@3.70ghz显卡nvidiageforcertx20708g内存32g2133mhz硬盘250gssd+1thdd在本实验,经过对多轮对话模型反复训练和参数调整,最终确定了一组表现效果较好的超参数。多轮对话模型各模块的具体参数如下表所示。超参数自然语言生成模块自然语言理解模块对话管理模块词汇表大小50k50k50k词向量维度128128128卷积核的大小1无无卷积核的数目128无无编码器隐藏层维度256无无编码器隐藏层层数1无无解码器隐藏层维度128256无解码器隐藏层层数22无dqn网络维度无无60dqn网络层数无无2优化器adagradadamadam单次输入批量161616学习率0.150.0010.001dropout0.50.50.5上表包含的只是对话模型的部分参数,该部分参数在不同的对话场景下是不变的。在本文提出的多轮对话模型中,还存在随不同的对话场景而发生改变的参数,比如动作级别:0表示对话行为级别的动作,1表示自然语言级别的动作;对话agent:0表示输入命令行agent,1-6表示基于规则的agent。对话模型包含的三个模块均使用同样大小的词表维度和词向量维度,对于未登录词,使用“unk”符号表示。在自然语言生成模块,编码器部分使用单层双向的lstm,隐藏层大小为256维,由于编码器每个时刻会输出前向状态和后向状态两个状态的信息,在每个编码时刻使用一个一维卷积网络对生成的前向信息和后向信息进行融合,卷积核大小为1,卷积核个数为128。解码器部分使用基于动态残差网络的双层单向的lstm,维度为128维,由于每个时刻只输出一个状态信息,因此,解码器部分不使用卷积核进行卷积操作。自然语言理解模块使用的是单一的深度语义网络,并不是encoder-decoder结构,因此,可将其看作单一的解码器结构。对话管理模块主要使用dqn网络学习对话策略,使用的是双层dqn网络,即当前dqn网络和目标dqn网络,维度均设为60。在训练过程中,自然语言生成模块使用adagrad优化器优化模型,学习率设为0.15,自然语言理解模块和对话管理模块使用adam优化器优化模型,学习率设为0.001。由于整个对话模型网络层数较多,结构复杂,为避免在模型训练的过程中出现过拟合,在模型训练的过程中引入dropout技术来简化网络结构,从而有效防止过拟合。随着模型的训练,lstm易发生梯度消失和梯度爆炸的问题,为此,我们使用梯度裁剪技术来控制梯度的大小。本方案为该实验定义了三种评价指标,分别为成功率(success_rate)、平均对话奖励(ave_rewards)以及平均轮数(ave_turns)。对于每一个对话,首先定义该对话的用户目标,每个对话的用户目标可能为一个或多个,比如电影票是否被成功预定或被预定的电影是否满足用户需求。如果在该对话过程中,对话模型能够完成所有的用户目标,则标注该对话为success,否则标注为fail。被对话模型标注为success的对话个数占所有对话的比例即为success_rate。平均对话奖励是用来衡量对话策略好坏的一种指标。本方案提出的多轮对话模型的对话管理模块采用的是一种强化学习策略进行对话策略学习,对话管理模块学到的对话策略越适用当前的对话环境,模型在训练的过程中产生的对话奖励值就越大。对于每个对话,都会包含若干个对话目标,对话轮数描述的是在一次对话过程中,完成该次对话包含的对话目标所用的对话轮次。模型对话性能越好,完成每个对话包含的对话目标使用的对话轮数越少。进行三组实验,第一组实验为使用评价指标success_rate在电影订票对话数据集上验证对话模型的总体性能;第二组实验为使用ave_rewards指标验证对话模型的对话策略的好坏;由于模型的success_rate高并不能证明模型在单个对话上的性能,第三组实验使用平均对话轮数指标进一步验证模型在单个对话上的性能。(1)在success_rate指标上进行模型综合性能评估该实验使用success_rate指标进行对话模型总体性能的评估。模型在电影订票预订对话数据集上进行实验的实验结果如图10所示。从图10中可以看出,随着对话模型的训练,对话模型的success_rate在不断上升。在0-100个模拟时期,模型的success_rate上升较快,当超过100个模拟时期时,success_rate接近平稳状态,从图中可以看出,对话模型的success_rate最终大概稳定在0.9左右。图11为截取的第132个时期的实验结果,在当前时期,模拟100个对话,每个对话在训练过程中均会被标注为success或fail,比如在第132个时期,模拟的第99个对话被标注为success,模拟的第100个对话被标注为fail,当前时期的平均success_rate为0.86,从训练开始到当前状态最高success_rate为0.95。多轮对话模型在success_rate评价指标上的实验结果表明,本文所提模型在公开数据集电影票预定对话数据集上的表现结果较好,且算法性能较高。(2)在ave_rewards指标上进行对话策略性能评估该实验使用ave_rewards指标对模型的对话策略进行评估。多轮对话模型的对话管理模块采用了一种强化学习策略进行策略学习。在对话过程中,对话模型产生的reward值越大,表明当前的对话策略越好。模型在电影订票预订对话数据集上进行实验的实验结果如图12所示。从图12中可以看出,随着对话模型的训练,对话模型的产生的ave_rewards在不断上升。在前60个模拟时期,模型的ave_rewards上升较快,在第60个模拟时期以后,ave_rewards接近平稳状态,从图中可以看出,对话模型的ave_rewards最终大概稳定在64左右。图13为截取的第368个时期的实验结果,在当前时期,模拟100个对话,当前时期的100个对话产生的ave_reward为63.31,从训练开始到当前状态产生的平均reward值为46.87。多轮对话模型在ave_reward评价指标上的实验结果表明,本文所提模型中使用的对话管理模块的有效性,能够帮助多轮对话模型在对话过程中学习到适合当前对话环境的对话策略。(3)在ave_turns指标上进行模型性能评估该实验使用ave_turns指标对模型在单个对话上的性能进行评估。模型在电影订票对话数据集上进行实验的实验结果如图14所示。从图14可以看出,随着对话模型的训练,对话模型在完成单个对话包含的对话目标所使用的对话轮数在不断下降。在前40个模拟时期,模型完成单个对话所使用的对话轮数下降较快,在第40个模拟时期以后,ave_turns接近平稳状态,从图中可以看出,对话模型完成单个对话包含的对话目标所使用的对话轮数大概稳定在13轮左右。图15为截取的第398个时期的实验结果,在当前时期,模拟100个对话,完成当前时期100个对话所需的平均对话轮数为13.74轮,从训练开始到当前状态完成所有对话所需的平均对话轮数为16.93轮。通过对原始对话数据集进行统计得到平均对话轮数为12轮,本文所提模型在原始对话数据集上的实验结果为13轮左右,该实验结果表明本文所提模型在单个对话上的对话性能同样表现出良好的对话性能。前面使用公开数据集验证了本文所提算法的性能,为了进一步验证本文所提的面向专利咨询的多轮对话模型在专利咨询上的对话效果,该实验将模型应用到课题组提供的专利咨询对话数据集上进行有效性验证。关于专利对话数据集实验,该实验使用的数据集为东方灵顿、万方以及宁波信息院等课题组合作方为课题组提供的483条专利咨询领域的对话数据集。本文将原始专利咨询对话数据存储到如图16所示的sqlite数据库中。数据表documents中共包含三个字段,字段名称分别为:module、intention以及description。module字段中存储的是数据模块,intention字段存储的是各模块的对话意图,description字段中存储的是每个对话意图对应的对话数据。该部分实验通过抓取sqlite数据库中存储的数据作为原始对话数据进行模型的有效性和实用性验证。本实验仍然使用成功率、平均对话奖励以及平均对话轮数三个指标对专利对话模型在专利咨询对话数据集上的表现进行综合评价。首先采用专利咨询语料预处理中的方法对专利咨询对话语料进行分词和去停用词。由于专利咨询对话语料包含专利领域的专有名词,比如“商业秘密”、“著作权”、“商标”等,为了提高文本向量化后得到的词向量质量,本方案使用全部的专利咨询对话语料重新训练word2vec得到专属于专利咨询领域的词向量矩阵。本方案使用word2vec中的skip-gram模型进行专利咨询对话语料的文本向量化。根据专利咨询领域的对话数据集涉及到专利领域知识的特点,首先基于领域知识定义5种对话意图以及28种槽类型,然后,根据定义的对话意图和槽类型构建面向专利咨询的对话模板。面向专利咨询多轮对话模型实验验证,对专利咨询对话语料进行预处理后,我们将数据按一定比例划分为训练集、验证集以及测试集,其中,训练集、验证集以及测试集包含的数据没有交叉关系,划分比例如下表所示。训练集验证集测试集80%10%10%根据划分好的数据,使用本文提出的多轮对话模型在专利咨询对话数据集上进行训练。在专利咨询对话数据集上的模型主要参数如下表所示。超参数自然语言生成模块自然语言理解模块对话管理模块词汇表大小10k10k10k词向量维度128128128卷积核的大小1无无卷积核的数目256无无编码器隐藏层维度128无无编码器隐藏层层数1无无解码器隐藏层维度128256无解码器隐藏层层数22无dqn网络维度无无64dqn网络层数无无2优化器adagradadamadam单次输入批量888学习率0.150.0010.001dropout0.70.70.7首先使用训练集对多轮对话模型进行训练,保存训练过程中的模型参数。然后使用验证集验证模型效果并进行模型参数调整。模型训练并调参完毕后,将模型在测试集上进行模型性能测试。我们将测试结果与现有平台方法进行比较,比较结果如下表所示。模型success_rateave_rewardsave_turnsourmodel0.9164.713平台现有方法0.80无16实验对比表明,本文提出的面向专利咨询的多轮对话技术方案优于现有平台使用的方法。目前,东方灵顿、宁波信息院等专利资源机构面向用户的专利咨询大多使用的是人工+规则的方法,该方法不仅咨询效率低,而且费用较高。本文在分析了专利咨询对话语料特点的基础上,提出的面向专利咨询的多轮对话模型有效解决了目前专利资服务机构面向用户专利咨询方面存在的不足,具有实际应用价值。本文模拟真实用户与对话模型进行交互,实验结果表明,对话模型能够完成用户在对话过程中提出的所有需求,并且在与用户交互的过程中没有生成冗余信息。以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1