一种基于众包的人类行为文本数据集的构造以及处理方法
1.本发明涉及移动互联网应用技术领域,尤其涉及一种基于众包的人类行为文本数据集的构造以及处理方法。
背景技术:
2.随着人工智能的高速发展,智能看护机器人、自动驾驶汽车等形式多样的智能体在人类生活中也扮演着越来越重要的角色。但是,随着智能化的普及,对于人类行为的分析和判断决策过程也越发重要。但是现有的伦理智能体的设计,基于专家示例,逆强化学习等通过人类示范学习人类价值观,但所需数据集的收集具有以下缺点:代价昂贵、周期长,存在偏见等问题,导致数据集不够全面,因此,对于人类行为的分析不是很准确。
技术实现要素:
3.本发明的目的在于提供一种基于众包的人类行为文本数据集的构造以及处理方法,提高对人类行为的分析的准确性。
4.为实现上述目的,本发明提供了一种基于众包的人类行为文本数据集的构造以及处理方法,包括以下步骤:
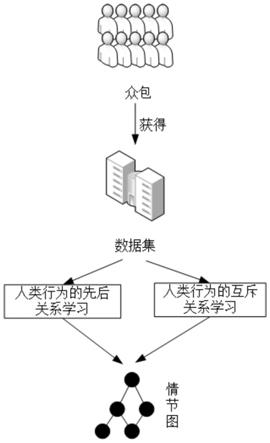
5.根据对应的主题对象和要求生成任务并发布于众包平台,同时获取设定主题下所有的文本数据集;
6.采用聚类的方式对所述文本数据集中的同一行为的不同文本表现进行聚类;
7.采用关联分析技术对不同行为之间进行分析,生成对应的先后关系结构图;
8.采用互信息技术获取行为之间的互斥关系结构,并将人类行为存在的各种关系构造成一个情节图。
9.其中,采用聚类的方式对所述文本数据集中的同一行为的不同文本表现进行聚类,包括:
10.利用python对所述文本数据集进行数据预处理,并对得到的各单词向量进行拼接,得到句子向量;
11.使用sklearn工具的封装的接口对所述句子向量进行相似度计算以及k
‑
means算法聚类。
12.其中,采用关联分析技术对不同行为之间进行分析,生成对应的先后关系结构图,包括:
13.句子蔟id对聚类后的所述文本数据集进行序列化,并遍历得到的文本序列数据集;
14.根据得到的后继关系集中的任意两节点同时出现的数据信息,计算出对应的置信度,并删除置信度小于阈值的对应的先后关系,生成对应的先后关系结构图。
15.其中,采用关联分析技术对不同行为之间进行分析,生成对应的先后关系结构图之后,所述方法还包括:
16.将所述先后关系结构图中多路径中直连的先后关系删除。
17.其中,采用互信息技术获取行为之间的互斥关系结构,并将人类行为存在的各种关系构造成一个情节图,包括:
18.基于文本序列事件是否发生的标记值获取对应的标记矩阵,同时计算出互斥关系得分;
19.根据所学习到的行为间的关系,构造情节图。
20.其中,基于文本序列事件是否发生的标记值获取对应的标记矩阵,同时计算出互斥关系得分,包括:
21.判断所述文本序列事件是否发生,并用0或1进行标记区分,直至文本序列数据集中的所有事件标记完成,得到对应的标记矩阵;
22.计算单事件和双事件同时发生的概率,并基于所述概率,计算出事件间的互斥关系得分。
23.本发明的一种基于众包的人类行为文本数据集的构造以及处理方法,首先,确定需要收集的主题对象,依据具体的要求生成任务并发布于众包平台,获得设定主题下所有可能发生的人类示例的文本数据集;对于同一个行为或事件的文本经过不同人的撰写会表现在多个句子,因此需要把描述同一事件的不同句子聚类在一起,对于获取的数据集采用聚类的方式将本属于同一行为的不同文本表现聚为一类;采用关联分析技术挖掘出行为之间存在的先后关系结构;采用互信息技术学习出行为之间存在的互斥关系结构,并将人类行为存在的各种关系构造成一个情节图,即表明在某种情况下会发生什么事件,并限制其发生的方式,提高对人类行为的分析的准确性。
附图说明
24.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
25.图1是本发明提供的一种基于众包的人类行为文本数据集的构造以及处理方法的步骤示意图。
26.图2是本发明提供的一种基于众包的人类行为文本数据集的构造以及处理方法的流程示意图。
27.图3是本发明提供的环状结构图。
28.图4是本发明提供的先后关系结构图。
29.图5是本发明提供的基于众包获取数据集的示意图。
30.图6是本发明提供的人类行为聚类的示意图。
31.图7是本发明提供的人类行为的先后关系的学习示意图。
32.图8是本发明提供的人类行为的互斥关系的学习示意图。
具体实施方式
33.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终
相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
34.在本发明的描述中,需要理解的是,术语“长度”、“宽度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
35.请参阅图1和图2,本发明提供一种基于众包的人类行为文本数据集的构造以及处理方法,包括以下步骤:
36.s101、根据对应的主题对象和要求生成任务并发布于众包平台,同时获取设定主题下所有的文本数据集。
37.具体的,如图5所示,确定一个需要收集的主题,并明确提出该任务的具体要求,并在任务设计中设置陷阱问题保证一定程度上的数据质量,将该任务发布在众包平台;
38.筛选众包平台上的工作者提交的数据,并接受符合本任务要求的数据,如有需要,可支付一定酬金。
39.s102、采用聚类的方式对所述文本数据集中的同一行为的不同文本表现进行聚类。
40.具体的,如图6所示,具体包括:
41.由于收集原始的数据集可能存在缺失、重复等质量问题,需要对数据集进行数据预处理,包括分词,去停用词,词性还原等,使用python在文本数据处理经常用到的一个库natural language toolkit(nltk)进行数据预处理。
42.使用google基于googlenews超大语料库利用word2vec预先训练好的公开单词向量模型,每个词向量300维。利用python中的gensim工具库加载词向量模型,然后对句子中的各单词向量进行拼接得到句子向量。
43.使用sklearn工具的封装的接口对上一步得到的文本向量进行相似度计算以及k
‑
means算法聚类;
44.利用轮廓系数来确定聚类类别的数量;
[0045][0046]
其中,a表示样本点与同一簇中所有其他点的平均距离,b表示样本点与下一个最近簇中所有点的平均距离。
[0047]
依据人工聚类评估并进行人工二次聚类,从中挑出与本类别内与其他句子最不相似的句子,从本类别内拿出。并对每一个类别总结一句话作为本类别的原始事件即情节点(人类行为)。
[0048]
s103、采用关联分析技术对不同行为之间进行分析,生成对应的先后关系结构图。
[0049]
具体的,如图7所示,具体包括:
[0050]
根据句子蔟id对文本集进行序列化。根据聚类结果可以得到n个蔟{c1,c2,
…
,c
n
},而每个簇内包含多个句子c={s1,s2,
…
,s
m
},从中选取某一个句子作为簇头s
m
,并对簇头进行唯一标识e
i
作为情节点。即簇{c1,c2,
…
,c
n
}中每一元素对应情节点{e1,e2,
…
,e
n
}中相应
的元素。接着将文本数据集中的句子按照聚类后的蔟id进行编码,得到text={[e1,e2,
…
,e
i
],[e1,e2,
…
,e
j
],
…
,[e1,e2,
…
,e
t
]}的文本序列数据集。
[0051]
遍历文本序列数据集,获得后继关系集。对文本序列数据集进行遍历,并根据情节点的先后关系生成后继关系集。例如文本序列[e1,e3,e6,e8]和[e1,e4,e6,e7,e9],可以得到e1:[e3,e4]、e3:[e6]、e4:[e6]、e6:[e7,e8]、e7:[e9]等后继关系集合。
[0052]
遍历后继关系集,获得任意两节点同时出现的数据信息,并计算置信度。如求取e
i
与e
j
两个节点的数据信息,包括有:num(e
i
→
e
j
),e
i
发生在e
j
之前的次数;num(e
j
→
e
i
),e
j
发生在e
i
之前的次数。通过此信息根据以下公式求取置信度,并构造置信度矩阵。
[0053][0054][0055][0056]
这里的e
i
→
e
j
指在同一个文本中e
i
先发生而e
j
后发生,|sample|为所有文本数量。
[0057]
遍历所有环状结构,并删除置信度最小的先后关系。在构造情节图的过程中,出现了很多环状结构。如图3所示:情节点a、b、c、d构成了一个环,然而情节图本质是种有向无环图,按照情节发展向后推进。在生成过程中需要禁止自循环,通过设置置信度大于0.5消除before(e
i
,e
j
)与before(e
j
,e
i
)同时存在的可能性,进而消除了两个节点间的循环,对于三个节点或者更多节点间的循环,本文通过消除关系中置信度最低的那个达到无环图的目的。分以下两步解决:
①
遍历情节图,利用深度优先的递归方式遍历出图中所有环状结构;
②
删除环状结构中的置信度最小的边。
[0058]
删除多路径中的先后关系,在众包文本数据时,并不是每个工作者撰写的文本的情节点都很丰富,有的文本中会省略部分情节点。故存在如下图所示的情况。图4中的a到b,即存在直接路径[a,b],又存在另一条多节点路径[a,c,d,b],故将直连的先后关系before(a,b)删除。
[0059]
s104、采用互信息技术获取行为之间的互斥关系结构,并将人类行为存在的各种关系构造成一个情节图。
[0060]
具体的,如图8所示,具体包括:
[0061]
标注各文本序列事件e
i
是否发生,其中发生的事件标记1,否则标记为0。例如:文本序列[e1,e3,e6,e8],由此得到标记后的列表[0,1,0,1,0,0,1,0,1]。遍历所有文本序列并获取各事件是否发生的标记矩阵。
[0062]
计算单事件与双事件同时发生的概率。假如总共有n条文本,其中事件e
i
发生的次数为k,则p(e
i
=1)的概率为k/n。
[0063]
计算互斥关系得分。根据如下公式计算,如果求得事件间的互信息值大于0,则事件间具有互斥关系。
[0064]
[0065][0066]
e
i
∈{0,1}表明事件e
i
是否出现在一个文本中,如果出现在该文本中,e
i
取值为1,反之取值为0。若a取值为0,则取值为1。
[0067]
根据所学习到的行为间的关系,构造情节图。
[0068]
本发明的有益效果:
[0069]
1、本发明利用众包技术收集了借助自然语言表述的人类行为数据,解决了专家示例、模仿学习等所需数据集构建时普遍存在的费用高昂、耗时、存在偏见等缺点。
[0070]
2、且鉴于众包在数据收集方面的强大优势,随着越来越多的人类行为数据被收集,涉及伦理问题的决策会更加清晰和一致。
[0071]
本发明的一种基于众包的人类行为文本数据集的构造以及处理方法,确定需要收集的主题对象,依据具体的要求设计任务并发布于众包平台,获得某一特定主题下所有可能发生的人类示例的文本数据集;对于同一个行为或事件的文本经过不同人的撰写会表现在多个句子,因此需要把描述同一事件的不同句子聚类在一起,对于获取的数据集采用聚类的方式将本属于同一行为的不同文本表现聚为一类;采用关联分析技术挖掘出行为之间存在的先后关系结构;采用互信息技术学习出行为之间存在的互斥关系结构,并将人类行为存在的各种关系构造成一个情节图,即表明在某种情况下会发生什么事件,并限制其发生的方式。本发明利用众包技术收集了借助自然语言表述的人类行为数据,能够利用众包的优势构建体现人类共同价值观的行为数据集,用以训练智能体获得人类价值观,使之遵守人类伦理道德规范。利用众包技术收集了借助自然语言表述的人类行为数据,解决了专家示例、模仿学习等所需数据集构建时普遍存在的费用高昂、耗时、存在偏见等缺点;进一步通过文本聚类、关联分析等技术生成情节图,用以定义智能体训练时的基本行为空间,约束行为的发生顺序。
[0072]
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1