一种基于假位置和偏移位置的LBS隐私保护策略
技术领域:
本发明属于信息安全技术领域,涉及位置隐私保护技术。
背景技术:
:
lbs环境下的隐私保护问题是当前的热点问题,针对该问题,国内外的学者们提出了大量的位置隐私保护方案,其中模糊方法当前位置隐私保护的首要选择,主要通过空间匿名或假位置的技术手段实现。空间匿名方法通常依靠可信第三方服务器(trustedthirdparty,ttp)将用户的准确位置泛化为一个包含k个用户(包含目标用户)的区域。这样不受信任的lbs服务器很难从此区域中区分出目标用户的真实位置。但是该种方法存在一定的局限性。为了解决空间匿名技术中的不足,有研究者提出了同样能实现k-匿名的假位置技术。
当前的基于假位置的lbs隐私保护策略虽然有效地解决了空间匿名技术中的不足,但是没有充分考虑攻击者拥有边信息或者背景知识等问题。本文通过同时考虑位置查询概率、位置语义信息以及位置物理距离这三方面的因素,设计一种基于假位置和偏移位置的lbs隐私保护策略,可以有效地抵抗攻击者的单点攻击。
技术实现要素:
:
本发明的目的是提供一种基于假位置和偏移位置的lbs隐私保护策略,包含选择偏移位置、选择满足语义差异性的位置、选择最大化语义差异性和物理分散性的位置等步骤,其具体过程如下:
首先介绍单点攻击模型,攻击者的单点攻击方式包括边信息攻击、位置同质攻击、位置相似性攻击。
边信息是指攻击者用来过滤假位置、辅助缩小匿名度的信息。例如,对于随机生成的假位置匿名集,某些位置可能处于河中或者无人区中,攻击者根据地图信息很容易将这些位置过滤掉。假设位置匿名度要求为k,当选择的k-1个假位置中有k′个假位置被攻击者根据边信息过滤掉,则不满足k匿名要求,导致隐私保护水平下降。
位置同质攻击是指攻击者分析匿名集中的多个位置,如果位置距离非常接近(如位于同一个广场内等),虽然达到k匿名的要求,但由于隐匿空间太小,用户的位置隐私仍然无法得到很好的保护。
位置相似性攻击是指攻击者分析隐匿区域内的语义信息,若该区域仅包含一种语义信息,比如医院或学校等,则攻击者可推断出用户的行为。以下介绍本发明的具体过程:
1)将当前地图划分为一定大小的样本空间,并且选择一个偏移位置;
2)选择满足语义差异性的位置加入到假位置集中,然后进行下一步的操作;
3)在步骤2)的基础上,选择同时满足物理分散性和语义差异性最大的假位置,将其作为最终候选位置加入到假位置集dls中;
4)循环执行步骤2)和步骤3),直至假位置集dls中的假位置个数为k,输出假位置集dls={l1,l2,…,lk-1,ld}。
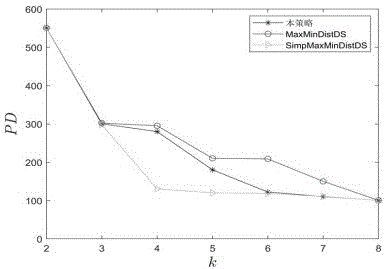
为了证明该发明的有效性,本策略和maxmindistds算法、maxmindistds算法以及dls算法在物理分散度pd、语义差异性、perl等不同的衡量指标之间进行了对比。实验结果表明,本策略具有更低的perl,更大的pd和语义差异性。
附图说明
图1为本策略的摘要图。
图2详细描述了本策略的物理分散度pd。
图3详细描述了本策略的语义差异性。
图4详细描述了本策略的perl。
具体实施方式:
(1)样本空间划分及选择偏移位置:
(1.1)将当前位置地图信息划分为m×m的网格,在用户真实位置l周围选择出距离最近的n-1个pi>0的位置,与l一起组成偏移位置集合mset={l1,l2,…,ln-1,l};
(1.2)从mset中随机选择一个偏移位置ld作为l的替代位置;
(2)设u=4为预先设定的语义差异度,对于任意两个位置li,lj,dsem(li,lj)表示这两个位置之间的语义距离。将整个网格空间中所有pi>0的位置组成假位置候选集合dlcs(dummylocationcandidateset)。将偏移位置ld加入假位置集dls中,并将其从dlcs中移除,将dlcs中与dls中新加入的假位置(dls.last)语义距离小于u的假位置过滤掉;
(3)在步骤(2)的基础上,从dlcs剩余位置中选择与dls.last满足
(4)循环执行步骤(2)和(3),直到dls中的假位置个数等于k,最后返回假位置集dls={l1,l2,…,lk-1,ld}。
位置的物理分散度pd(location’sphysicaldispersion),本文通过计算匿名集中任意两位置间的最小距离来度量匿名集中假位置的分散程度,具体过程如下式所示:
匿名集中任意两位置间的最小距离越大,位置分散度越高,匿名集的覆盖范围越大,因此会有更好的匿名效果。
θ-安全值,本文采用θ-安全值来度量假位置集的语义差异性。θ-安全值的计算公式如下式所示:
其中,sem=|dsem|dsem(li,lj)≤u|,k=|dls|,dls是包含偏移位置在内的假位置集,
位置暴露概率perl(probabilityofexposingreallocation),本文使用用户真实位置的暴露概率来衡量算法抵抗边信息攻击的有效性,其计算方式如下式所示:
其中,k为匿名度,k′表示攻击者通过边信息攻击过滤掉的假位置数。攻击者过滤掉的假位置数越多,perl越大,则算法抵抗边信息攻击的效果越差;perl越小,则算法抵抗边信息攻击的效果越好。
- 还没有人留言评论。精彩留言会获得点赞!