一种基于强化学习的个性化短视频推荐方法以及系统
本发明涉及人工智能领域,主要关于人工智能在短视频推荐过程中的应用,特别是一种基于强化学习的个性化短视频推荐方法以及系统。
背景技术:
近几年来,短视频平台的蓬勃发展,背后需要一种能有效、高效推荐用户其感兴趣的视频的方法。推荐领域也在飞速发展,如基于协同过滤、基于内容的推荐、机器学习以及深度学习等各类技术都被应用于推荐方法当中。
在国内,大数据个性化推荐算法自2012年提出之后,经过两年的发展期和一年的成熟期,到2016年进入了广泛的应用期,同时在技术方面也从最初hadhoop技术应用到大数据的快速处理、推荐算法及框架的研究,进而转向在电子商务、新闻和社交网络等领域的个性化推荐应用研究。国外的研究早于国内,自2015年开始国外已从理论研究转向教育、医疗及用户行为等多方面的应用研究。在当今大数据的背景下,推荐算法主要有基于内容的推荐、协同过滤推荐、基于社交网络的推荐、基于规则的推荐、混合推荐等等。除了上述算法,现在机器学习和深度学习也开始引入推荐系统,并取得不错的效果。
虽然现今推荐算法的种类丰富,但是最常用且有效的还是基于协同过滤的方法,主要有两种类型一种是基于用户的协同过滤,另一种则是基于项目的协同过滤。基于用户的协调过滤是将与目标用户有相似兴趣爱好的用户所喜欢的物品推荐给目标用户,基于项目的协同过滤则是通过目标项目的相似项目集合预测用户对相似项目的喜欢程度。协调过滤算法虽然是应用最广泛的一种推荐技术,但受限于其自身的稀疏性,仍然存在一定的问题。新兴的基于深度学习的推荐算法则是静态模型,无法响应用户的动作,因此只会追求短暂的最优推荐结果而忽略用户可能喜欢的、更感兴趣的方向。即追求局部最优解而非全局最优解。常用的强化学习模型比如model-free的基于价值的强化学习方法和model-free的基于策略的强化学习方法,虽然会追求全局最优解,但是采样效率低下、需要大量的样本支撑起学习,学习时间成本高。同时,上述算法难以实现用户定制化,是由一个推荐引擎适用于所有用户,而定制化的推荐系统更能捕获用户的兴趣。
现有的强化推荐算法研究中,一种基于元学习与强化学习的推荐系统(专利申请号:201911393658)和一种带负反馈的基于深度强化学习的推荐方法及系统(专利申请号:202010328640)均为基于强化学习的推荐系统,均为model-free的强化学习算法而非model-base的强化学习算法。前者利用元学习和强化学习解决冷启动问题,后者使用model-free的dqn实现,并使用gru单元降维,从而提升训练速度;但是两者都没有使用model-base的强化学习,且从定制化的角度来看前者更注重初期的用户定制化,而后者没有实现用户定制化。
技术实现要素:
为了解决现有技术中强化推荐算法多采用model-free的强化学习算法,无法实现用户定制化的技术问题,本发明提出一种基于强化学习的个性化短视频推荐方法以及系统。
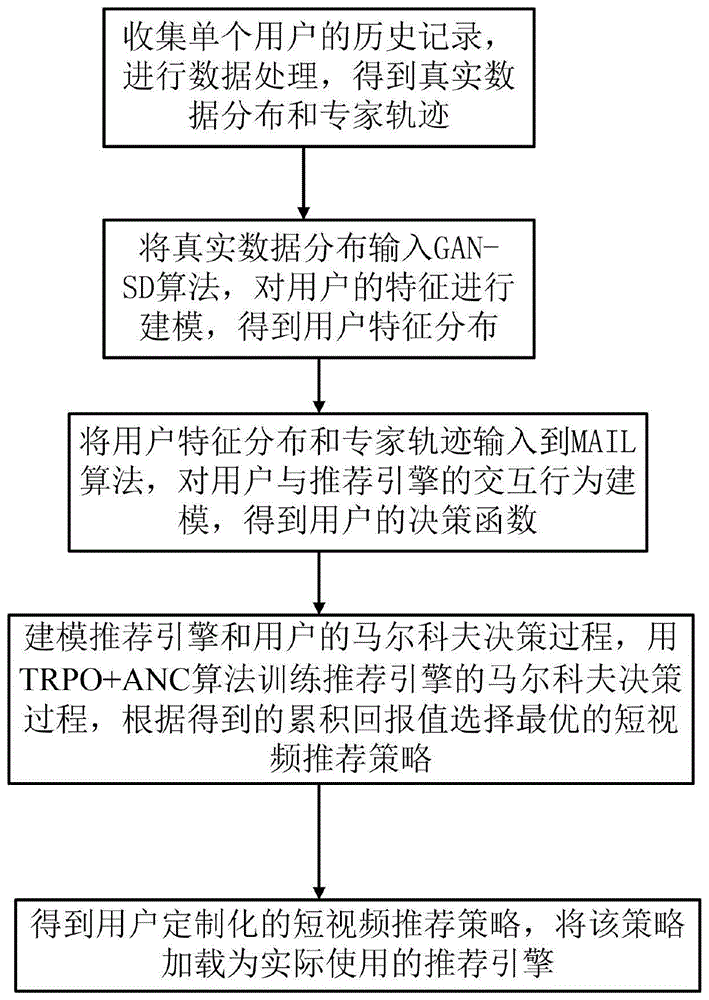
为此,本发明提出的一种基于强化学习的个性化短视频推荐方法具体包括如下步骤:
s1、收集单个用户的历史记录,进行数据处理,得到真实数据分布和专家轨迹;
s2、将真实数据分布输入gan-sd算法,对用户的特征进行建模,得到用户特征分布;
s3.将用户特征分布和专家轨迹输入到mail算法,对用户与推荐引擎的交互行为建模,得到用户的决策函数;
s4、建模推荐引擎和用户的马尔科夫决策过程,用trpo+anc算法训练推荐引擎的马尔科夫决策过程,根据得到的累积回报值确定不同动作下的短视频推荐策略,从短视频推荐策略中选择最优的短视频推荐策略;
s5、得到用户定制化的短视频推荐策略,将该策略加载为实际使用的推荐引擎。
进一步地,所述真实数据分布具体表示为:
其中xi表示第i个用户感兴趣的视频。
进一步地,所述专家轨迹具体表示为:
其中的si表示推荐引擎推荐的第i个视频,
进一步地,所述步骤s2具体包括:
s21、将判别模型d和生成模型g分别用参数θd,θg表示,使用随机初始化;
s22、从正态分布中生成一个批次的噪声z,从真实数据分布中取出一个批次的样本数据x,通过梯度下降更新参数θg;
s23、重复步骤s22多次;
s24、从正态分布中生成一个批次的噪声z,从真实数据分布中取出一个批次的样本数据x,通过梯度下降更新参数θd;
s25、重复步骤s22-s24,直至判别模型d和生成模型g收敛;
s26、得到收敛的生成模型g,作为用户特征分布。
进一步地,所述步骤s3中mail算法将推荐引擎的策略函数πσ与用户的策略函数
进一步地,所述步骤s3中,根据用户特征分布,推荐引擎与用户进行互动,生成一系列轨迹,从生成的轨迹中采样一条轨迹,通过最小化表达式,更新用户的奖励函数,在用户的马尔科夫决策过程中使用rl优化
进一步地,在所述步骤s4中,推荐引擎的马尔科夫决策过程表示为
其中ac为用户采取的动作,
进一步地,在所述步骤s4中,用户的马尔科夫决策过程表示为
其中ac为用户采取的动作,
为此,本发明提出的基于强化学习的个性化短视频推荐系统包括中央处理器和存储器,所述存储器中存储有可以被所述中央处理器运行的程序,所述中央处理器通过运行所述程序可以实现上述基于强化学习的个性化短视频推荐方法。
为此,本发明提出的计算机存储介质存储有可以被中央处理器运行的程序,所述程序在被所述中央处理器运行的过程中可以实现上述基于强化学习的个性化短视频推荐方法。
相比于现有技术,本发明具有如下有益效果:
1)将强化学习应用到短视频推荐;
2)根据单个用户的历史记录对用户的特征进行建模,由于不同的用户会生成不同的数据集,从而能够实现不同用户的定制化;
3)建模推荐引擎和用户的马尔科夫决策过程,使用model-base的方法进行推荐,而不是更常用的model-free。
附图说明
图1是个性化短视频推荐方法的流程图;
图2是个性化短视频推荐的运行示意图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图说明本发明的具体实施方式。
本发明实施例提出的基于强化学习的个性化短视频推荐方法的整体流程图如图1所示,具体包括如下步骤:
s1、收集单个用户的历史记录,进行数据处理,得到真实数据分布
s2、将
s21、d和g分别用参数θd,θg表示,使用随机初始化;
s22、从正态分布中生成一个批次的噪声z,从
s23、重复步骤s22k次;
s24、从正态分布中生成一个批次的噪声z,从
s25、重复s22-s24若干次,直至模型d和g收敛;
s26、得到收敛的生成模型g,g(z)模拟用户喜好的视频,记为
s3.将
s31、随机初始化参数κ,σ,θ;
s32、初始化变量
s33、采样ac~π(sc,·),添加(sc,ac)到
s34、重复步骤s33直至进入终止状态;
s35、重复步骤s32~s34j次,生成j条模仿轨迹;
s36、从
s37、沿最小化的方向更新参数θ:
s38、在
s39、重复步骤s32~s38i次,得到训练完成的用户策略函数πc。
s4、建模推荐引擎的mdp以及用户的mdp,具体地,短视频推荐过程中,假设用户只记得最后一个短视频的内容并且行为只受该短视频影响,则推荐引擎给用户推荐短视频这个过程符合标准马尔科夫决策过程,因此,建模推荐引擎的马尔科夫决策过程
其中aπ(s,c)=qπ(s,a)-vπ(s)=es′p(s′|s,a)[r(s)+γvπ(s′)-vπ(s)];
使用anc策略防止过拟合,将原始的奖励函数r(s,a)用下式替代:
根据得到的累积回报值确定不同动作下的短视频推荐策略,从短视频推荐策略中选择最优的短视频推荐策略。
关于推荐引擎的mdp建模,记为
其中ac为用户采取的动作,奖励函数
关于用户的mdp建模,记为
其中ac为用户采取的动作,奖励函数
s5、得到用户定制化的短视频推荐策略,将该策略加载为实际使用的推荐引擎,当用户打开软件,推荐引擎将状态设为从上一次离开时的状态,即上一次推荐的视频,用户做出相应的动作(切换、点赞或退出),推荐引擎接接受到相应的奖励,通过状态转移函数转移为下一个状态并进行推荐等行为。
本发明实施例提出的基于强化学习的个性化短视频推荐系统包括中央处理器和存储器,存储器中存储有可以被中央处理器运行的程序,中央处理器通过运行程序可以实现上述基于强化学习的个性化短视频推荐方法。
本发明采用gan-sd和mail算法对用户进行建模,模拟用户的行为,利用马尔科夫决策过程mdp对单个用户和推荐引擎建模,通过trpo+anc算法训练推荐引擎,最终实现用户定制化的推荐引擎,在动态响应用户的同时,还做到了尽可能贴近用户进行推荐。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!