一种相似演化模式聚类及动态时区划分的交通流分区模型
一种相似演化模式聚类及动态时区划分的交通流分区模型
一、技术领域
1.本发明涉及智能交通领域,尤其涉及短时交通流预测,具体是一种以相似演化模式为标准,对路网各路段交通流数据进行聚类,进而对具有相似演化模式各路段的单日内交通流数据进行动态时区划分的交通流分区模型。
二、
背景技术:
2.准确实时的短时交通流预测能够有效缓解城市交通拥堵、降低城市空气污染,具有重要社会意义。交通流数据具有趋势性,周期性和动态随机性等特性。其中趋势性和周期性属于交通流规律特性,主要表现为根据时间规律变化的趋势或波动,是交通流可以被预测的前提。动态随机性由区域路网交通影响因素事件(如信号灯、行人穿行、道路事故、交通管制等)产生的,会使交通流时间序列数据产生波动的特征。动态随机性是导致交通流难以被准确预测的根本原因。
三、
技术实现要素:
3.本发明的目的是进一步挖掘区域路网交通流的时空信息,建立能更加适应路网交通流动态随机性的自适应短时交通流预测模型,以进一步提升模型预测精度。
4.在时间维度上,路段不同时段内交通流的时空分布具有明显的差异(如高峰时段和非高峰时段),一个路段的交通流演化模式会随着时间的推移而发生改变,即交通流在单日内会呈现出显著的时间非平稳性。因此,有必要对路段单日内不同时段的交通流进行研究。
5.以往交通流预测模型往往采取全时间序列建模或对时间序列的静态时间分区建模。其中,对时间序列的静态时间分区建模往往基于日常生活经验,手动地对路段单日内的交通流量时间序列数据进行时区划分,例如将数据分为5段:0:00
‑
6:00、6:00
‑
9:00、9:00
‑
17:00、17:00
‑
20:00、20:00
‑
23:59,其中6:00
‑
9:00和17:00
‑
20:00为当天的早高峰和晚高峰。但是,这种分区策略往往只根据日常经验手动划分,没有适应交通流真实的数据特点。因此,需要一种动态时间分区策略,以适应路网交通流的时间非平稳性,更细粒度地表征交通流的时空状态特征,以提高短时交通流模型的预测精度。
6.基于以上分析,本发明提出了基于相似演化模式聚类及动态时区划分的交通流时间序列分区模型(similarpatternclusteranddynamictimeseriespartition,spc
‑
dtsp),首次尝试挖掘交通流随时间变化的动态时空特征,解决交通流时间非平稳性在短时交通流预测中带来的挑战。具体地,本章所做工作的贡献如下:
7.(1)使用亲和力传播聚类算法(affinitypropagationcluster,apc),自动识别出路网内具有相似交通流演化模式的路段。
8.(2)针对交通流的日内演化差异,使用曲度k
‑
means算法(warpedk
‑
means,wkms),对相似演化模式中的交通流进行动态时区划分,更深层次地挖掘路网交通流的时空状态特征。
9.(3)在相似模式识别和自动时区划分后,对不同模式下的不同时区内的交 通流分别建模,更细粒度地对交通流的状态信息进行量化,使模型的预测精度更 加准确。
10.(4)使用真实数据集对所提模型的有效性进行验证,并与现有优秀预测模 型进行效果对比,展示所提模型的先进性。
11.本发明的目的是这样达到的:
12.针对现有研究没有充分利用路网各路段交通流单日内的动态随机性,并使用 静态全局固定的模型结构进行预测的问题,本发明建立了一个基于相似演化模式 聚类及动态时区划分的交通流时间序列分区模型。首先使用亲和力传播聚类,对 路网内各路段的交通流进行分类,将具有相似演化模式的路段交通流归为一类; 然后使用曲度k
‑
means算法,对具有相似交通流演化模式的路段进行单日时区划 分,在时间维度上进一步细粒度地标准路段的交通流状态。在此基础上再进行对 交通流的建模预测,预测精度会得到进一步提升。
13.具体做法是:
14.首先对采集到的美国加州公路管理系统pems的交通流数据进行预处理工作, 包括数据聚合、缺失数据填充、异常值处理、数据筛选。以提高数据可用性,提 升模型的预测精度。
15.(1)数据聚合:pems系统原始的数据采样间隔为30s,但过短的采样间隔会 导致收集到的数据呈现出较大程度的分散性和随机性,不利于对交通时间序列数 据的分析研究。pems自身提供了多种数据聚合的方法,将采样间隔30s的数据 重新聚合到一个更大的时间间隔内,包括5分钟、15分钟、60分钟,以满足研 究者不同的数据需求。本文聚焦于短时交通流预测,因此选用时间间隔为5分钟 的交通流时间序列数据。
16.(2)缺失数据填充:由于道路环形探测器长期暴露于室外环境,会受到天气、 地磁、物理撞击等各种因素的影响,从而导致传感器发生故障乃至损害,采集到 的交通流时间序列数据可能出现局部缺失和大片缺失的状况。针对局部缺失数 据,本文采用相邻时间的数据进行线性插值计算。针对大片缺失数据,本文采用 多个相同星期编号的平均时间序列数据进行填补。
17.(3)异常值处理:异常值体现在交通流时间序列数据中存在数据突变。比如 在早高峰时段中,某路段8:10、8:15、8:20三个采样时间点的车流量数据为520、 20、540,很明显8:15分的数据为异常数据。针对采样数据,本文使用异常点前 后相邻采样时间点的线性均值进行替换。
18.(4)数据筛选:路段工作日和周末的交通流时间序列数据呈现不同的演化趋 势,工作日的时间序列数据具有较为明显的早高峰和晚高峰,而周末的单高峰时 段也一般出现在中午,这是城市居民在不同时间不同的出行习惯导致的。为了实 验数据的一致性,只选用工作日的交通流时间序列数据作为研究对象。
19.在进行完对交通流数据的预处理后,得到可用性更高的数据。之后,需要首 先对各路段所有时间的交通流数据进行特征表示;其次,需要对各路段的交通流 特征数据进行相似演化模式聚类;最后,对具有相似交通流演化模式的数据进行 动态时区划分,得到最后对交通流数据的时间分区结果。
20.1.交通流时间序列数据特征表示
21.各路段单日内的交通流时间序列数据呈现出一条时变曲线,以5分钟的数据 采样频率为例,该交通流时变曲线以288个交通流数据为组成元素,构成了一条 路段一天的交通流时间序列,曲线的走势反映出来路段单日内的交通流演化模 式。理论上应当对所有采集时间(d天)的交通流时间序列数据进行聚类,然后 再使用某种算法将出现的重叠簇进行过滤和组合,但这种方法加大了预测模型的 复杂度,会带来巨大的计算负载,不利于对及交通流的实时预测。为了简化计算, 对各路段所有采集时间的交通流数据以天为单位进行均值计算,获取交通流平均 时间序列,表示该路段在统计时间内的日内平均演化交模式,作为亲和力传播聚 类算法的交通流数据特征。
22.现假设某个路网有m条路段,该路网所有路段的的交通流量数据表示为现假设某个路网有m条路段,该路网所有路段的的交通流量数据表示为其中路段p的所有交通数据定义为公式(4
‑
1):
[0023][0024]
其中n表示单日以5分钟为采样频率的交通流量采集数,n=288;d表示采 集天数;x
p,i
表示路段p第i天的交通流量时间序列数据。
[0025]
将路段p的交通流数据特征设定为代表了所有采集时间内的交通流平 均变化趋势。由于工作日和非工作日的交通流数据存在明显差别,本文的研究对 象仅限于路网工作日的交通流数据。的定义如公式(4
‑
2)所示:
[0026][0027]
2.亲和力传播聚类算法apc算法对路网所有特征序列进行聚类
[0028]
使用apc算法识别交通流相似演化模式包括如下5个步骤:
[0029]
(1)将每个路段的交通流量时间序列数据进行特征表示。
[0030]
(2)将路段交通特征映射为数据点(data point)。
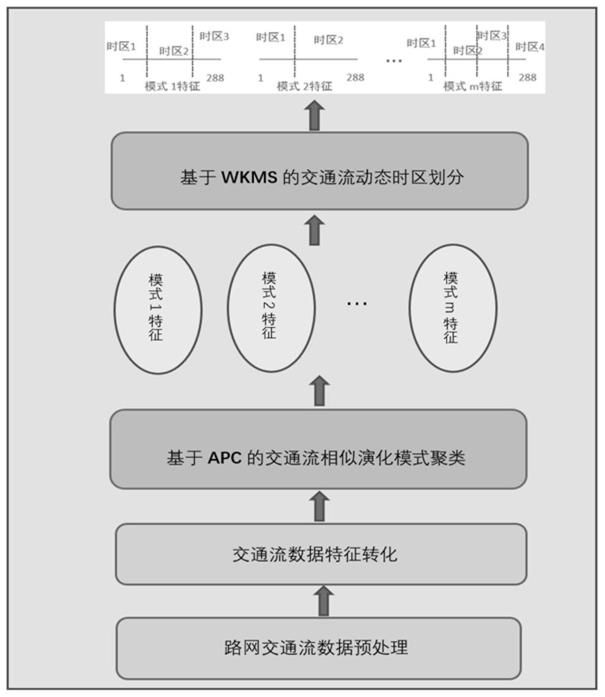
[0031]
(3)迭代计算责任性信息(responsibility message)r
i,j
和可用性信息 (availability message)a
i,j
。
[0032]
(4)通过全局函数判断信息传递网络是否收敛。
[0033]
(5)信息传递网络收敛,得到各聚类中心及各交通流演化模式序列。
[0034]
apc聚类算法的第一步是将路段i的交通流平均时间序列数据映射为n维空 间的1个数据点,路网内所有路段的交通流平均时间序列数据的数据点表示为 {1,2,
…
,m},所有数据点组成了一个信息传递网络,每一个数据点都是这个信息 传递网络中的一个节点。apc聚类算法将这些数据点都视为潜在的聚类中心, 并沿着信息传递网络边缘,递归地计算并传递两种类型的实值消息:r
i,j
和a
i,j
, 直至信息传递网络收敛,全局函数取得最大值,得到最佳的聚类中心点集
[67]
。 网络全局函数定义为公式(4
‑
3)和公式(4
‑
4):
[0035][0036][0037]
其中f是路网所有数据点的聚类中心集,c
i
∈f是数据点i的聚类中心,是 数据点i和c
i
的相似度,相似度通过计算二者的欧氏距离得出。任意两点i和j的相 似度计算公式定义为公式(4
‑
5):
[0038][0039]
相似度值越大,表明点j作为点i的能力越大。h
j
是点j作为潜在聚类中心点c
j
的惩罚函数。如果c
i
选择点j作为他的聚类中心点,则点j也必须作为自己的聚类 中心,否则点j不能称为一个聚类中心点,即公式(4
‑
6):
[0040]
c
i
=j,only if c
j
=j
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4
‑
6)
[0041]
两种类型信息:责任性信息r
u,l
和可用性信息a
u,l
在apc算法的迭代计算中 传递
[68]
,r
i,j
包含点i到候选聚类中心点j的信息,表征了点j作为点i聚类中心的适 合程度(suitability)。a
i,j
包含候选聚类中心点j到点i的信息,表明点f选择点j作 为聚类中心的合适程度。通过绘制与聚类准则函数相对应的因子图,利用置信传 播更新两种信息,使因子图的全局函数最大化,从而完成聚类
[69]
。使用如下公 式(4
‑
7)至公式(4
‑
9)进行消息更新:
[0042]
r
i,j
←
s
i,j
‑
∑
j
′
s.t.j
′
≠{i,j}
(a
i,j
′
+s
i,j
′
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(4
‑
7)
[0043]
a
i,j
←
min{0,r
j,j
+∑
i
′
s.t.i
′
≠{i,j}
max(0,r
i
′
,j
)}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4
‑
8)
[0044]
r
j,j
←
∑
i
′
s.t.i
′
≠j
max(0,r
i
′
,j
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4
‑
9)
[0045]
当信息传递网络收敛后,对于每个数据点i的聚类中心c
i
,c
i
满足公式(4
‑
10):
[0046][0047]
当完成了对所有数据点的聚类后,便可以得出如公式(4
‑
11)所示的聚类中 心点集:
[0048]
c={c
i
,i∈[1,w],1<w<m}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4
‑
11)
[0049]
其中w是中心个数,m是路网路段总数。
[0050]
对聚类中心点集进行去重后,便可以得到公式(4
‑
12)所示的路网交通流演 化模式点集:
[0051]
p=unique(c)={p1,p2,...,p
r
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4
‑
12)
[0052]
其中r即为聚类得到的交通流演化模式数目,r=len(p)。
[0053]
任意一种交通模式i所包含的路段点集为s
i
,则模式i所包含的路段个数为 n
i
=|s
i
|,s
i
如公式(4
‑
13)所示:
[0054]
s
i
={j|p
i
=c
j
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4
‑
13)
[0055]
假设所有交通流演化模式时间序列特征集为l,则l的表示如公式(4
‑
14)所 示:
[0056][0057]
其中n为单日内的交通流数据采集数目。
[0058]
在得到聚类结果后,为更直观地展示各路段特征时间序列与聚类中心时间序 列的数据分布情况,本节将所有路段的特征时间序列数据集x
p
进行标准分数转 换。标准分数的定义如公式(4
‑
15)所示:
[0059][0060]
其中,e[x
p
]是x
p
的期望,是x
p
的标准差。
[0061]
3.曲度k
‑
means时区划分算法
[0062]
曲度k
‑
means算法的输入是通过apc聚类算法得到的交通流演化模式时间 序列集
合p,对p中每个交通流演化模式序列分别进行时区划分。通过迭代计算, wkms算法得到离散分布的同质类。
[0063]
在算法初始阶段,设置聚类边界点b
i
(黑色点)。由于引入了强制序列限制, 在每一个迭代计算过程,时间序列的前一半元素只能向左移动到边界前面数据点 (橘色点);时间序列的后一半元素只能向右移动到边界的后面。通过这种限制, 对整个交通流时间序列数据进行时区划分。
[0064]
现假设经过apc聚类,任意第p种交通流演化模式的时间序列特征数据为 wkms的目标在于将划分为k
p
个不同的数据类1<k
p
<<288,每一个数据类代表着一个时间分区的交通流数 据,k
p
是wkms对第m种演化模式交通流的时间分区数目。在每一次迭代计算 中,每一种演化模式中的每一个聚类数目的轮廓系数都会被计算,当轮廓系数值 取得最大值时,该时刻的聚类数目即为最佳时区划分数目,即此时第m种交通流 演化模式的分区数目k
p
。
[0065]
至此,便完成了对相似交通流演化模式的动态时区划分。经过时区划分后, 假设第q个时区内的交通流数据总数为则时区交通数据 和第p种演化模式的交通流时间序列数据的映射关系如公式(4
‑
16)和公式(4
‑
17) 所示:
[0066]
{1,2,
…
,k
p
}
→
{1,2,
…
,288}
ꢀꢀꢀꢀꢀꢀꢀꢀ
(4
‑
16)
[0067][0068]
其中k
p
是时间分区数目,表示第p种交通流演化模式中第p个时间分区的 交通流数据。
四、附图说明
[0069]
图1是相似演化模式聚类及动态时区划分的交通流时间序列分区模型结构图。
[0070]
图2是亲和力传播聚类模型示意图。
[0071]
图3是apc聚类算法流程。
[0072]
图4是曲度k
‑
mens进行交通流动态时区划分示意图。
五、具体实施方式
[0073]
本发明分3部分实施:
[0074]
(1)交通流数据特征表示:为了简化计算,对各路段所有采集时间的交通流 数据以天为单位进行均值计算,获取交通流平均时间序列,表示该路段在统计时 间内的日内平均演化交模式,作为亲和力传播聚类算法的交通流数据特征。
[0075]
(2)对交通流特征数据进行相似演化模式聚类:由于路网内各路段间存在物 理上直接或间接的连接,某个路段的交通状态在一定程度上会受其周围路段交通 状态的影响,这就形成了路段间的空间相关性和交通流协同演化模式。在进行完 交通流数据的特征表示后,本发明使用亲和力聚类传播算法对路网内具有相似演 化模式的路段交通流进行分类,使得预测模型的构建范围缩小在一个更加精确的 数据范围。
[0076]
(3)动态时区划分:对聚类后的具有相似演化模式的交通流数据进行动态 时区划
分。城市交通流在一天中不同时段呈现不同演化模式,各时段的交通流数 据分布呈现出明显差别。一天中非高峰时段的数据趋势平缓,高峰时段的数据呈 上升和下降趋势,且不同工作日之间、工作日和周末的单日内各时段的交通流数 据分布又各不相同。因此,准确识别出各时段交通流的数据分布特征,更加细粒 度地刻画单日交通流的演化模式对于预测模型的性能提高起着重要作用。因此使 用改进的k
‑
means算法曲度k
‑
means对聚类后的具有相似演化模式的交通流数据 进行动态时区划分。
[0077]
本发明的用户使用场景举例:
[0078]
一个有效的交通流预测模型对于路线规划、交通控制和智能驾驶等方面十分 重要。出行者可以利用流量预测信息判断道路未来拥堵情况,制定更加高效的出 行计划。实时的路况预测分析也有助于出行者及时调整前进路线,减少交通拥堵 的发生。交通管理者可以利用预测模型监控交通状态,提前对可能发生拥堵的区 域采取交通信号控制等措施。在车祸等紧急事件发生时,周边路段的未来交通流 变化趋势有助于交通管理者合理分配资源,从而提升疏散和救援的速度。对于智 能驾驶和车联网等应用而言,精准的速度预测信息是智能车辆协同系统的基础, 也是提升道路通行能力和安全性的重要保障。
[0079]
综上所述,交通流预测研究对改善交通问题和提升出行效率等方面有着不可 替代的意义。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1