一种基于辅助表示融合的非自回归神经机器翻译方法与流程
1.本发明涉及一种神经机器翻译推断加速方法,具体为基于辅助表示融合的非自回归神经机器翻译方法。
背景技术:
2.机器翻译是将一种自然语言翻译为另一种自然语言的技术。机器翻译是自然语言处理的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。同时,随着互联网技术的飞速发展,机器翻译技术在人们日常的生活工作中起到了越来越重要的作用。
3.机器翻译技术从上世纪70年代基于规则的方法,到80年代基于实例的方法,90年代基于统计的方法,到如今基于神经网络的方法,历经多年的发展,终于达到了良好的效果,在人们的日常生活中得到了更广泛的使用。
4.目前最被广为应用的神经机器翻译系统通常采用基于神经网络的端到端的编码器
‑
解码器框架,其中性能最强大的则是基于自注意力机制的transformer模型结构,在多个语种的上取得了最佳的翻译性能。transformer由基于自注意力机制的编码器和解码器组成。标准的transformer编码器如图3所示由六层堆叠的编码层组成,解码器同样包括六层解码层。整个模型中抛弃了传统的rnn和cnn,完全由注意力机制组成。更准确的说transformer由且仅由注意力机制和前馈神经网络组成。相比于rnn由于transformer抛弃了只能顺序计算的限制,提高了系统的并行能力。同时由于并行计算的处理方式,也缓解了顺序计算中的长期依赖难以处理的现象。transformer的编码层包括自注意力层和前馈神经网络组成。自注意力编码端输出的用稠密向量表示的句子进行特征提取后送入前馈神经网络。解码器相对于解码器来说在自注意力层和前馈神经网络层之间增加了一个编码
‑
解码注意力层,来对源语和目标语之间的映射关系进行建模。
5.基于神经网络的机器翻译系统在性能上相较之前备受瞩目的基于统计的翻译系统而言,在性能上已经得到了十足的进步。但由于神经网络涉及大量的矩阵运算,因此在训练以及解码上相对之前的方法会更加耗时。对于这两方面的耗时,在实际中往往对于解码的时间消耗更为看重。为使得神经机器翻译系统能够在实际中被应用起来,必须要求系统在解码的过程中具有较高的响应速度,否则面对难以接受的延迟,即使翻译系统具有更为优秀的性能,在很多场景下用户也很难接受。
6.目前大多数机器翻译模型都使用了编码器
‑
解码器框架来实现,编码器将源语句的表示送入到解码器来生成目标句子;解码器通常以自回归的方式来工作,从左到右逐字地生成目标句子,第t个目标词的生成依赖于先前生成的t
‑
1个目标词。这种自回归的解码方式符合阅读和生成句子时的习惯,能有效地捕捉到真实翻译的分布情况。但是解码器的每个步骤必须顺序地而不是并行地运行,因此自回归解码会阻止像transformer这样的体系结构在推理过程中充分体现其训练时的性能优势。
7.为了减轻推理延迟,非自回归翻译模型被提出,该模型以从左到右的方式使用复制的源输入初始化解码器输入,并独立地同时生成所有目标词。但是,nat模型在实现加速
的同时,其解码器必须在薄弱的目标端信息的条件下来处理翻译任务,从而降低了翻译的准确性。
技术实现要素:
8.针对非自回归机器翻译模型中由于薄弱的目标端信息造成翻译质量下降的问题,本发明提供了一种基于辅助表示融合的非自回归神经机器翻译方法,能够使得非自回归机器翻译取得与自回归机器翻译相当的性能且具有较高的响应速度以及更好实际应用。
9.为解决上述技术问题,本发明采用的技术方案是:
10.本发明提供一种基于辅助表示融合的非自回归神经机器翻译方法,包括以下步骤:
11.1)采用基于自注意力机制的transformer模型,构造一个包含编码器和解码器的自回归神经机器翻译模型;
12.2)构建训练平行语料,进行分词和字词切分预处理,得到源语序列和目标语序列,生成机器翻译词表后,训练一个只有一层解码器的模型直到模型收敛;
13.3)移除transformer模型中原有解码器对未来信息屏蔽的矩阵,同时在自注意力和编码解码注意力之间加入多头位置注意力,构造非自回归神经机器翻译模型;
14.4)使用浅层的自回归模型解码出源语的按规定比例设置的前一部分词,将自回归神经机器翻译模型解码器最顶层的前馈神经网络后的输出与非自回归神经机器翻译模型编码器的顶层表示进行加权融合,作为非自回归神经机器翻译模型解码器的输入;
15.5)使用平行语料训练通过融合表示作为输入的非自回归神经机器翻译模型,编码器对源语句子进行编码,提取源语句子信息,解码器根据该源语句子信息来预测对应的目标语句子;然后计算预测出的数据分布与真实数据分布的差异,通过反向传播的方式不断减少该差异,直到模型收敛完成非自回归神经机器翻译模型的训练过程;
16.6)将用户输入的源语句子送入非自回归神经机器翻译模型中,解码出不同长度的翻译结果,并通过自回归神经机器翻译模型的评价选取最优的翻译结果。
17.步骤3)中构造非自回归神经机器翻译模型,具体为:
18.301)移除解码端对未来信息屏蔽的矩阵后对翻译问题进行建模:
[0019][0020]
其中,x为源语序列,y为目标语序列,t为目标语序列长度,t
′
为源语序列长度,t为目标语的位置,x
1...t
′
为源语句子,y
t
为第t个位置的目标语词;
[0021]
302)在每个解码器层中添加额外的多头位置注意力模块,该模块为:
[0022][0023]
其中,q为查询矩阵,k为键矩阵,v为值矩阵,softmax(.)为归一化函数,attention(.)为注意力计算函数,d
k
为键矩阵的维度;
[0024]
303)在解码开始之前,使用源语长度对目标语长度进行预估并将预估的目标语长度数据送至非自回归神经机器翻译模型,以便并行生成所有单词。
[0025]
步骤4)中使用自回归模型的翻译结果来改进非自回归神经机器翻译模型的输入,具体为:
[0026]
401)非自回归机器翻译模型解码端的输入,如下所示:
[0027][0028]
其中,θ
at
和θ
nat
分别是自回归神经机器翻译模型和非自回归神经机器翻译模型的参数,t为目标语序列长度,t
′
为源语序列长度,y
t
为第t个位置的目标语词,x
1...t
′
为源语句子,y
<t
为第1到t
‑
1个目标词,z
nat
是非自回归神经机器翻译模型解码端的输入;
[0029]
402)构造表示融合函数,采用加权和的方式,具体为:
[0030]
fusion=λdecoder
at
(y
1...k
)+μencoder
nat
(x
1...t
′
)
[0031]
其中,λ和μ是控制不同表示项权重的超参数,decoder
at
(.)是自回归神经机器翻译模型解码器的输出,encoder
nat
(.)是非自回归神经机器翻译模型解码器的输出,y
1...k
为第1到k个词,x
1...t
′
为源语句子;
[0032]
403)将上述计算得到的融合表示送入解码器之前,通过应用层归一化操作来归一化前向层输入和后向层梯度。
[0033]
步骤401)中z
nat
的计算公式如下:
[0034]
z
nat
=fusion(decoder
at
(y
1...k
),encoder
nat
(x
1...t
′
))
[0035]
其中,decoder
at
(.)是自回归模型解码端的输出,encoder
nat
(.)是非自回归模型解码端的输出,fusion(.)为辅助表示融合函数,y
1...k
为第1到k个词,x
1...t
′
为源语句子。
[0036]
步骤5)非自回归神经机器翻译模型的训练过程中将平行语料送入模型计算交叉熵损失,然后再计算相应的梯度进行参数更新来完成训练过程。
[0037]
步骤6)中,将用户输入的源语句子送入到非自回归神经机器翻译模型中,通过指定不同的目标语长度来获得多个翻译结果;然后,使用自回归神经机器翻译模型作为这些解码翻译结果的打分函数,进而选择最佳的整体翻译。
[0038]
本发明具有以下有益效果及优点:
[0039]
1.本发明提出了基于辅助表示融合的非自回归神经机器翻译方法,通过
[0040]
将编码在自回归模型中的高级表示引入到非自回归模型中,来提高非自回归模型的翻译质量。结合自回归模型和非自回归模型的优点,能够实现快速且准确的翻译。
[0041]
2.本发明方法使用源语和部分目标语的融合表示作为输入,极大的缓解了非自回归模型薄弱的目标端信息的问题,有效的提升了非自回归模型的性能。
[0042]
3.本发明方法具有很强的扩展性,通过调整使用自回归神经机器翻译模型所解码的前一部分词的比例,其可以包括自回归神经机器翻译模型和非自回归神经机器翻译模型。
附图说明
[0043]
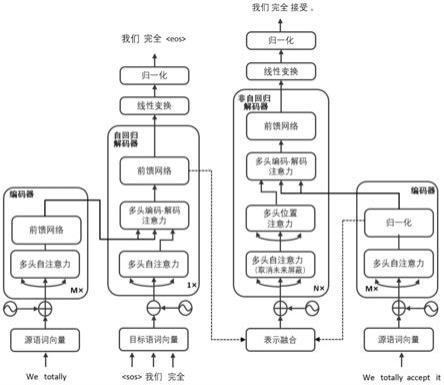
图1为本发明中基于融合表示的非自回归神经机器翻译模型图示;
[0044]
图2为本发明中传统transformer中编码层和解码层的结构示意图。
具体实施方式
[0045]
下面结合说明书附图对本发明作进一步阐述。
[0046]
本发明将从表示融合角度对非自回归神经机器翻译系统的翻译性能进行优化,旨在实现准确且快速的翻译。
[0047]
本发明提出了一种基于辅助表示融合的非自回归神经机器翻译方法,包括以下步骤:
[0048]
1)采用基于自注意力机制的transformer模型,构造一个包含编码器解码器的自回归神经机器翻译模型;
[0049]
2)构建训练平行语料,进行分词和字词切分预处理流程,得到源语序列和目标语序列,生成机器翻译词表后训练一个只有一层解码端的模型直到收敛;
[0050]
3)移除transformer中解码端对未来信息屏蔽的矩阵,同时在自注意力和编码解码注意力之间加入多头位置注意力,构造非自回归机器翻译模型;
[0051]
4)使用浅层的自回归模型解码出前一部分词,将自回归机器翻译模型解码端最顶层的前馈神经网络后的输出与非自回归机器翻译模型编码端的顶层表示进行加权融合,作为非自回归机器翻译模型解码端的输入;
[0052]
5)使用平行语料训练使用融合表示作为输入的非自回归机器翻译模型,编码器对源语句子进行编码,提取源语句子信息,解码器根据该信息来预测对应的目标语句子。然后计算预测出的分布与真实数据分布的损失,通过反向传播不断减少该损失,完成模型的训练过程;
[0053]
6)将用户输入的源语句子送入机器翻译模型中,解码出不同长度的翻译结果,并通过自回归模型的评价来得到最优的翻译结果。
[0054]
步骤1)中,transformer仅由注意力机制和前馈神经网络组成,如图2所示。transformer仍是基于编码器
‑
解码器框架,通过堆叠多个相同的栈,分别组成了编码器和解码器,编码器和解码器的子层结构略有不同。transformer在机器翻译任务的多个数据集上均实现了显著的性能提高,并达到了当时的最好性能,而且具备更快的训练速度。注意力机制是神经机器翻译模型中重要的组成部分。在最初的编码器
‑
解码器框架中,由于上述原因导致神经网络难以学习到源端和目标端的对应信息,翻译系统对输入较长的句子的翻译效果较差。在自注意力机制中,查询(query,q),键(key,k)和值(value,v)来自相同的内容,首先对三个矩阵分别进行线性变换,然后进行缩放点积操作,即计算query与key进行点积计算,为了防止计算结果过大,会除以key的维度来达到调节作用,如下述公式所示:
[0055][0056]
其中,q为查询矩阵,k为键矩阵,v为值矩阵,softmax(.)为归一化函数,attention(.)为注意力计算函数,d
k
为键矩阵的维度。
[0057]
步骤2)中,在解码时,自回归模型最耗时的操作在解码器。由于在解码阶段没有参考译文,自回归神经机器翻译模型利用已生成的序列来预测当前的目标词,这导致了严重的解码延迟。使用轻量级的自回归神经机器翻译模型能够极大的提升解码速度。
[0058]
步骤3)中构造非自回归神经机器翻译模型,具体为:
[0059]
301)移除解码端对未来信息屏蔽的矩阵后对翻译问题进行建模:
[0060][0061]
其中,x为源语序列,y为目标语序列,t为目标语序列长度,t
′
为源语序列长度,t为目标语的位置,x
1...t
′
为源语句子,y
t
为第t个位置的目标语词;
[0062]
302)在每个解码器层中添加额外的多头位置注意力模块,该模块为:
[0063][0064]
其中,q为查询矩阵,k为键矩阵,v为值矩阵,softmax(.)为归一化函数,attention(.)为注意力计算函数,d
k
为模型隐藏层的维度;
[0065]
303)在解码开始之前,使用源语长度对目标语长度进行预估并将预估的目标语长度数据送至非自回归神经机器翻译模型,以便并行生成所有单词。
[0066]
步骤4)中使用自回归神经机器翻译模型的翻译结果来改造非自回归神经机器翻译模型的输入,具体为:
[0067]
401)使用浅层的自回归模型解码出前一部分词,将自回归机器翻译模型解码端最顶层的前馈神经网络后的输出与非自回归机器翻译模型编码端的顶层表示进行加权融合,作为非自回归机器翻译模型解码端的输入,如下所示:
[0068]
401)非自回归机器翻译模型解码端的输入,如下所示:
[0069][0070]
其中,θ
at
和θ
nat
分别是自回归神经机器翻译模型和非自回归神经机器翻译模型的参数,t为目标语序列长度,t
′
为源语序列长度,y
t
为第t个位置的目标语词,x
1...t
′
为源语句子,y
<t
为第1到t
‑
1个目标词,z
nat
是非自回归神经机器翻译模型解码端的输入;z
nat
的计算公式如下:
[0071]
z
nat
=fusion(decoder
at
(y
1...k
),encoder
nat
(x
1...t
′
))
[0072]
其中,decoder
at
(.)是自回归模型解码端的输出,encoder
nat
(.)是非自回归模型解码端的输出,fusion(.)为辅助表示融合函数,y
1...k
为第1到k个词,x
1...t
′
为源语句子。
[0073]
402)构造表示融合函数,采用加权和的方式,具体为:
[0074]
fusion=λdecoder
at
(y
1...k
)+μencoder
nat
(x
1...t
′
)
[0075]
其中,λ和μ是控制不同表示项权重的超参数,decoder
at
(.)是自回归神经机器翻译模型解码器的输出,encoder
nat
(.)是非自回归神经机器翻译模型解码器的输出,y
1...k
为第1到k个词,x
1...t
′
为源语句子;
[0076]
403)将上述计算得到的融合表示送入解码器之前,通过应用层归一化操作来归一化前向层输入和后向层梯度。
[0077]
步骤5)中非自回归神经机器翻译的训练过程中将平行语料送入模型计算交叉熵损失,然后再计算相应的梯度进行参数更新来完成训练过程。
[0078]
步骤6)中,将用户输入的源语句子送入到模型中,通过指定不同的目标语长度来
获得多个翻译结果;然后,使用自回归模型作为这些解码翻译结果的打分函数,进而选择最佳的整体翻译;由于所有翻译样本都可以完全独立地计算和打分,因此与计算单个翻译相比,如果有足够的并行性,则该过程只会增加一倍的时间。
[0079]
本发明使用目前比较常用的数据集iwslt14德英口语数据集和wmt14德英数据集来验证所提出方法的有效性,其训练集分别包含16万和450万平行句对。通过byte pair encoder字词切分方式,得到处理后的双语语料训练数据。但由于非自回归模型很难拟合真实数据中的多峰分布,因此本实施例采用句子级知识精炼的方式解决*该问题。也即,把同样参数配置的自回归神经机器翻译生成的句子作为训练样本,提供给非自回归神经机器翻译进行学习。
[0080]
如图1所示,本实施例中,先将源语句子的前两个词“we totally”送入到自回归神经机器翻译模型的编码器中,编码器的多头注意力通过获取各个词之间的相关性系数之后送入前馈神经网络来提取源语言句子信息。接着,自回归神经机器翻译模型的解码器接受该信息然后依次经过多头自注意力层、多头编码解码注意力层、前馈神经网络层之后再进行一次线性变换后得到翻译结果“我们完全”。然后,非自回归神经机器翻译模型使用该翻译结果与非自回归神经机器翻译模型的编码器信息进行表示融合后作为其解码器的输入,最后与上面流程相同,解码器使用提取到的源语言句子信息和该解码器输入依次经过多头自注意力层、多头位置注意力、多头编码解码注意力层、前馈神经网络层再经过一次线性变化后得到整个目标语句子“我们完全接受”。
[0081]
本发明使用机器翻译任务中常用的双语评价指标bleu作为评价标准。实验结果表明,使用辅助表示融合方法作为非自回归模型的输入并同时解码9个不同长度的候选翻译,之后再使用自回归模型评价的方法在iwslt14德英数据集上损失了百分之14的性能的情况下,获得了9.4倍的速度提升;在wmt14德英数据集上,获得了7.9倍的速度提升却只损失了百分之8.5的性能。
[0082]
本发明将从表示融合角度对非自回归神经机器翻译系统的翻译性能进行优化,旨在实现准确且快速的翻译。通过将编码在浅层自回归模型中的高级表示引入到非自回归模型中,来提高非自回归模型的翻译质量且保证高效的推理速度。使用源语和部分目标语的融合表示作为输入,极大的缓解了非自回归模型薄弱的目标端信息的问题,有效的增强了模型的性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1