一种网络舆情监测方法与流程
本发明涉及一种网络舆情监测方法,属于大规模网络图文的分析与挖掘,包括网络图文分类,检索,推荐,tag修正与推荐,图文话题发现,以及图文地理定位等技术领域。
背景技术:
互联网的高速发展催生网络社会,网络舆情是网络社会中的一个焦点。面对海量的舆情信息,需要使网络舆情信息更好的完成网络舆情科学汇集、信息决策保障、研判依据、网络舆情检测,从而增强决策的科学性,有效引导网络舆情,确保决策的正确方向。但是现有技术对于网络舆情,主要还是停留在海量数据的海量比对上,即在此海量的比对动作中发现网络舆情信息,但是这种方式存在着数据量巨大,直接带来比对时间过长,这期间很有可能出现未在第一时间发现侦测相关重要信息的情况。
技术实现要素:
本发明所要解决的技术问题是提供一种网络舆情监测方法,采用全新比对逻辑思想,应用多数据库比对,结合监控对象与全网对象之间的关联对比,高效实现网络舆情的侦测。
本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种网络舆情监测方法,用于针对目标监控集中的各个网络账号实现监控,包括分别针对目标监控集中的各个网络账号,按网络账号所对应的监测周期时长,周期执行如下步骤:
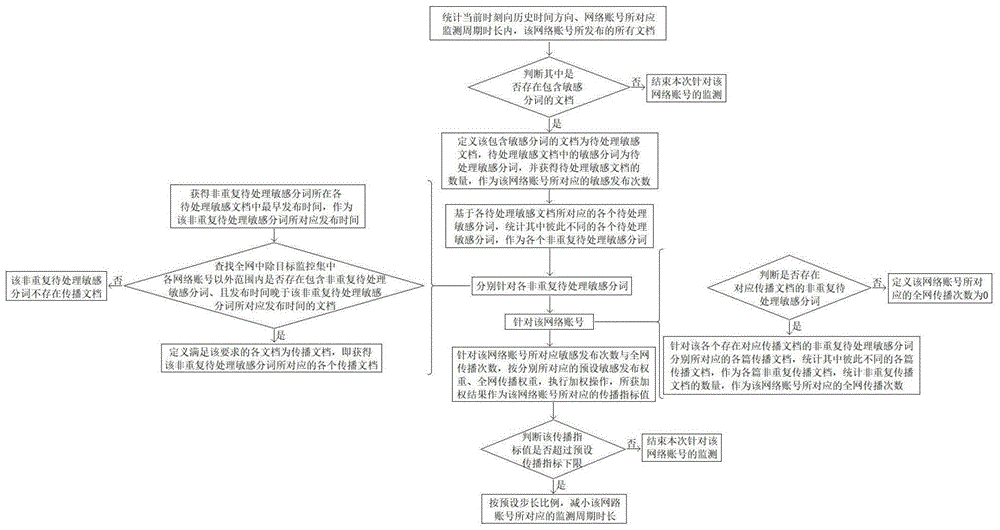
步骤a.统计当前时刻向历史时间方向、网络账号所对应监测周期时长内,该网络账号所发布的所有文档,并判断其中是否存在包含敏感分词的文档,是则定义该包含敏感分词的文档为待处理敏感文档,待处理敏感文档中的敏感分词为待处理敏感分词,即获得各待处理敏感文档分别所对应的各个待处理敏感分词,并获得待处理敏感文档的数量,作为该网络账号所对应的敏感发布次数,然后进入步骤b;否则结束本次针对该网络账号的监测;
步骤b.基于各待处理敏感文档所对应的各个待处理敏感分词,统计其中彼此不同的各个待处理敏感分词,作为各个非重复待处理敏感分词,然后进入步骤c;
步骤c.分别针对各非重复待处理敏感分词,首先获得非重复待处理敏感分词所在各待处理敏感文档中最早发布时间,作为该非重复待处理敏感分词所对应发布时间,然后查找全网中除目标监控集中各网络账号以外范围内是否存在包含非重复待处理敏感分词、且发布时间晚于该非重复待处理敏感分词所对应发布时间的文档,是则定义满足该要求的各文档为传播文档,即获得该非重复待处理敏感分词所对应的各个传播文档;否则该非重复待处理敏感分词不存在传播文档;待完成此步骤关于各非重复待处理敏感分词的操作后,然后进入步骤d;
步骤d.判断是否存在对应传播文档的非重复待处理敏感分词,是则针对该各个存在对应传播文档的非重复待处理敏感分词分别所对应的各篇传播文档,统计其中彼此不同的各篇传播文档,作为各篇非重复传播文档,统计非重复传播文档的数量,作为该网络账号所对应的全网传播次数;否则定义该网络账号所对应的全网传播次数为0;待完成此步骤的判断后,进入步骤e;
步骤e.针对该网络账号所对应敏感发布次数与全网传播次数,按分别所对应的预设敏感发布权重、全网传播权重,执行加权操作,所获加权结果作为该网络账号所对应的传播指标值,并判断该传播指标值是否超过预设传播指标下限,是则按预设步长比例,减小该网路账号所对应的监测周期时长;否则结束本次针对该网络账号的监测。
作为本发明的一种优选技术方案:所述步骤a包括如下步骤a1至步骤a7;
步骤a1.统计当前时刻向历史时间方向、网络账号所对应监测周期时长内,该网络账号所发布的所有文档,作为各篇待处理文档,并分别针对各篇待处理文档进行分词处理,获得各篇待处理文档分别所对应的各个分词,然后进入步骤a2;
步骤a2.分别针对各篇待处理文档,统计待处理文档中彼此不同的各个分词,作为该待处理文档所对应的各个非重复分词,进而获得各篇待处理文档分别所对应的各个非重复分词,然后进入步骤a3;
步骤a3.判断各篇待处理文档分别所对应各个非重复分词中是否存在通用敏感分词,是则将该各个非重复分词作为各个待处理通用敏感分词,并进入步骤a4;否则进入步骤a5;
步骤a4.分别针对各个待处理通用敏感分词,将待处理通用敏感分词所在的各篇待处理文档作为各篇待处理敏感文档,并进一步分别针对该各篇待处理敏感文档,计算获得该待处理通用敏感分词分别与待处理敏感文档中其他各个非重复分词之间的相似度,并选择其中相似度大于预设相似度阈值的各个非重复分词,同样作为待处理通用敏感分词,即更新该篇待处理敏感文档所对应的各个待处理通用敏感分词,并将新增待处理通用敏感分词加入预设通用敏感词汇集,更新预设通用敏感词汇集;进而获得各篇待处理敏感文档、以及待处理敏感文档所对应的各待处理通用敏感分词,然后进入步骤a5;
步骤a5.判断各篇待处理文档分别所对应各个非重复分词中是否存在领域敏感分词,是则将该各个非重复分词作为各个待处理领域敏感分词,并进入步骤a6;否则进入步骤a7;
步骤a6.分别针对各个待处理领域敏感分词,将待处理领域敏感分词所在的各篇待处理文档作为各篇待处理敏感文档,并进一步分别针对该各篇待处理敏感文档,计算获得该待处理领域敏感分词分别与待处理敏感文档中其他各个非重复分词之间的相似度,并选择其中相似度大于预设相似度阈值的各个非重复分词,同样作为待处理领域敏感分词,即更新该篇待处理敏感文档所对应的各个待处理领域敏感分词,并将新增待处理领域敏感分词加入预设领域敏感词汇集,更新预设领域敏感词汇集;进而获得各篇待处理敏感文档、以及待处理敏感文档所对应的各待处理领域敏感分词,然后进入步骤a7;
步骤a7.判断是否存在待处理敏感文档,是则分别针对各待处理敏感文档,将待处理敏感文档所对应的各个待处理领域敏感分词、各待处理领域敏感分词,构成该待处理敏感文档所对应的各个待处理敏感分词,进而获得各待处理敏感文档分别所对应的各个待处理敏感分词,并获得待处理敏感文档的数量,作为该网络账号所对应的敏感发布次数,然后进入步骤b;否则结束本次针对该网络账号的监测。
作为本发明的一种优选技术方案:所述步骤a2中,在获得各篇待处理文档分别所对应的各个非重复分词后,获得各个非重复分词分别所对应的分词向量,然后进入步骤a3;
所述步骤a4中,分别针对各篇待处理敏感文档,根据待处理通用敏感分词所对应分词向量分别与待处理敏感文档中其他各非重复分词所对应分词向量之间的正弦距离,构成待处理通用敏感分词分别与待处理敏感文档中其他各个非重复分词之间的相似度;
所述步骤a6中,分别针对各篇待处理敏感文档,根据待处理领域敏感分词所对应分词向量分别与待处理敏感文档中其他各非重复分词所对应分词向量之间的正弦距离,计算获得待处理领域敏感分词分别与待处理敏感文档中其他各个非重复分词之间的相似度。
作为本发明的一种优选技术方案:所述步骤a3中,分别针对各篇待处理文档所对应的各个非重复分词,应用以分词向量为输入、分词向量分别对应通用敏感类与非通用敏感类的概率为输出的通用敏感分类模型,针对非重复分词所对应的分词向量进行处理,判断非重复分词是否为通用敏感分词;进而实现判断各篇待处理文档分别所对应各个非重复分词中是否存在通用敏感分词,是则将该各个非重复分词作为各个待处理通用敏感分词,并进入步骤a4;否则进入步骤a5;
所述步骤a5中,分别针对各篇待处理文档所对应的各个非重复分词,应用以分词向量为输入、分词向量分别对应领域敏感类与非领域敏感类的概率为输出的领域敏感分类模型,针对非重复分词所对应的分词向量进行处理,判断非重复分词是否为领域敏感分词;进而实现判断各篇待处理文档分别所对应各个非重复分词中是否存在领域敏感分词,是则将该各个非重复分词作为各个待处理领域敏感分词,并进入步骤a6;否则进入步骤a7。
作为本发明的一种优选技术方案:基于预设通用敏感词汇集中各通用敏感词分别所对应的分词向量,以及预设数量个预设非通用敏感词分别所对应的分词向量,针对第一目标分类网络进行训练,获得以分词向量为输入、分词向量分别对应通用敏感类与非通用敏感类的概率为输出的通用敏感分类模型;
基于预设领域敏感词汇集中各领域敏感词分别所对应的分词向量,以及预设数量个预设非领域敏感词分别所对应的分词向量,针对第二目标分类网络进行训练,获得以分词向量为输入、分词向量分别对应领域敏感类与非领域敏感类的概率为输出的领域敏感分类模型。
作为本发明的一种优选技术方案:所述通用敏感分类模型、领域敏感分类模型的训练获得过程中,采用如下交叉熵作为损失函数;
其中,yi表示第i个分词向量的真实分类,f(·)是目标分类网络的映射函数,vi表示第i个分词向量,n表示训练阶段的分词向量的数量。
作为本发明的一种优选技术方案:所述步骤a3中,将各篇待处理文档分别所对应的各个非重复分词、与预设通用敏感词汇集中的各个敏感词进行匹配,判断是否存在匹配成功的非重复分词,是则将该各匹配成功的非重复分词作为各个待处理通用敏感分词,并进入步骤a4;否则进入步骤a5;
所述步骤a5中,将各篇待处理文档分别所对应的各个非重复分词、与该网路账号所对应技术领域下的预设领域敏感词汇集中的各个敏感词进行匹配,判断是否存在匹配成功的非重复分词,是则将该各匹配成功的非重复分词作为各个待处理领域敏感分词,并进入步骤a6;否则进入步骤a7。
作为本发明的一种优选技术方案:所述步骤d中,判断是否存在对应传播文档的非重复待处理敏感分词,是则在获得该网络账号所对应的全网传播次数后,进入步骤de-1;否则定义该网络账号所对应的全网传播次数为0,并进入步骤e;
步骤de-1.将各篇非重复传播文档与各篇待处理敏感文档进行匹配,判断是否存在匹配成功的非重复传播文档,是则进入步骤de-2;否则进入步骤e;
步骤de-2.判断各匹配成功的非重复传播文档中是否存在互为引用关系,是则获得其中各被引用非重复传播文档的引用次数,分别作为各被引用非重复传播文档所对应网络账号的敏感传播次数,并选择其中敏感传播次数大于预设传播次数阈值的网络账号加入目标监控集中,更新目标监控集,然后进入步骤e;否则直接进入步骤e。
作为本发明的一种优选技术方案:还包括目标监控集删减更新方法,按预设周期执行如下步骤i至步骤iii;
步骤i.分别针对目标监控集中的各个网路账号,判断网络账号距当前时刻最近的一次监测中,该网络账号所对应传播次数是否为0,是则将该网络账号作为待处理网络账号;否则不做任何处理;待完成此步骤针对目标监控集中各网路账号的判断操作后,进入步骤ii;
步骤ii.判断是否存在待处理网络账号,是则分别针对各待处理网络账号,针对自待处理网络账号距当前时刻最近的一次监测起、向历史方向的各次监测,统计该待处理网络账号连续对应传播次数为0的监测的数目,作为待处理网络账号所对应的衡量次数,进而获得各待处理网络账号分别所对应的衡量次数,然后进入步骤iii;否则不做任何处理;
步骤iii.根据各待处理网络账号分别所对应的衡量次数,将衡量次数高于预设衡量次数阈值的各个待处理网络账号,由目标监控集中删除,更新目标监控集。
作为本发明的一种优选技术方案:分别针对目标监控集中的各个网络账号,按网络账号所对应的监测周期时长,周期所执行步骤中,步骤a中,统计当前时刻向历史时间方向、网络账号所对应监测周期时长内,该网络账号所发布的所有文档、并获得各篇文档截图;
在执行步骤a至步骤e的同时,若出现所获文档截图被删除的情况,且各篇被删除文档截图分别所对应的文档中、存在非待处理敏感文档的文档,则据此文档的数量,针对该网络账号所对应的敏感发布次数执行增加更新。
本发明所述一种网络舆情监测方法,采用以上技术方案与现有技术相比,具有以下技术效果:
本发明所设计一种网络舆情监测方法,采用全新设计网络舆情比对方式,根据通用敏感词汇集、领域敏感词汇集,针对目标监控集中各网络账号所发表文档进行一次比对,并结合目标监控集到全网的延伸,实现舆情的二次比对,并且在比对过程中,实现了对通用敏感词汇集、领域敏感词汇集、以及目标监控集的更新,智能调整舆情比对范围、以及比对依据,使得比对过程能够随网络信息发展而智能调节;整个设计方案运用大数据与人工智能技术,能实现公众账号审核、政务新媒体传播考核与评估、互联网争议信息识别与溯源等功能。
附图说明
图1是本发明所设计网络舆情监测方法的流程示意图。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。
本发明设计了一种网络舆情监测方法,用于针对目标监控集中的各个网络账号实现监控,包括分别针对目标监控集中的各个网络账号,按网络账号所对应的监测周期时长,周期执行如下步骤a至步骤e。
步骤a.统计当前时刻向历史时间方向、网络账号所对应监测周期时长内,该网络账号所发布的所有文档,并判断其中是否存在包含敏感分词的文档,是则定义该包含敏感分词的文档为待处理敏感文档,待处理敏感文档中的敏感分词为待处理敏感分词,即获得各待处理敏感文档分别所对应的各个待处理敏感分词,并获得待处理敏感文档的数量,作为该网络账号所对应的敏感发布次数,然后进入步骤b;否则结束本次针对该网络账号的监测。
实际应用当中,上述步骤a具体执行如下步骤a1至步骤a7。
步骤a1.统计当前时刻向历史时间方向、网络账号所对应监测周期时长内,该网络账号所发布的所有文档,作为各篇待处理文档,并分别针对各篇待处理文档进行分词处理,获得各篇待处理文档分别所对应的各个分词,然后进入步骤a2。
步骤a2.分别针对各篇待处理文档,统计待处理文档中彼此不同的各个分词,作为该待处理文档所对应的各个非重复分词,进而获得各篇待处理文档分别所对应的各个非重复分词,并应用word2vec词向量模型,获得各个非重复分词分别所对应的分词向量,然后进入步骤a3。
步骤a3.判断各篇待处理文档分别所对应各个非重复分词中是否存在通用敏感分词,是则将该各个非重复分词作为各个待处理通用敏感分词,并进入步骤a4;否则进入步骤a5。
关于上述步骤a3的操作,在实际应用当中,具体可以设计采用两种实施方式,第一种实施方式是:将各篇待处理文档分别所对应的各个非重复分词、与预设通用敏感词汇集中的各个敏感词进行匹配,判断是否存在匹配成功的非重复分词,是则将该各匹配成功的非重复分词作为各个待处理通用敏感分词,并进入步骤a4;否则进入步骤a5;
第二种实施方式是:分别针对各篇待处理文档所对应的各个非重复分词,应用以分词向量为输入、分词向量分别对应通用敏感类与非通用敏感类的概率为输出的通用敏感分类模型,针对非重复分词所对应的分词向量进行处理,判断非重复分词是否为通用敏感分词;进而实现判断各篇待处理文档分别所对应各个非重复分词中是否存在通用敏感分词,是则将该各个非重复分词作为各个待处理通用敏感分词,并进入步骤a4;否则进入步骤a5。
对于通用敏感分类模型来说,是预先基于预设通用敏感词汇集中各通用敏感词分别所对应的分词向量,以及预设数量个预设非通用敏感词分别所对应的分词向量,针对采用多层全连接层作为的第一目标分类网络进行训练,获得以分词向量为输入、分词向量分别对应通用敏感类与非通用敏感类的概率为输出的通用敏感分类模型,并且其中采用如下交叉熵作为损失函数;
其中,yi表示第i个分词向量的真实分类,f(·)是目标分类网络的映射函数,vi表示第i个分词向量,n表示训练阶段的分词向量的数量。
步骤a4.分别针对各个待处理通用敏感分词,将待处理通用敏感分词所在的各篇待处理文档作为各篇待处理敏感文档,并进一步分别针对该各篇待处理敏感文档,根据该待处理通用敏感分词所对应分词向量分别与待处理敏感文档中其他各非重复分词所对应分词向量之间的正弦距离,构成该待处理通用敏感分词分别与待处理敏感文档中其他各个非重复分词之间的相似度,并选择其中相似度大于预设相似度阈值的各个非重复分词,同样作为待处理通用敏感分词,即更新该篇待处理敏感文档所对应的各个待处理通用敏感分词,并将新增待处理通用敏感分词加入预设通用敏感词汇集,更新预设通用敏感词汇集;进而获得各篇待处理敏感文档、以及待处理敏感文档所对应的各待处理通用敏感分词,然后进入步骤a5。
步骤a5.判断各篇待处理文档分别所对应各个非重复分词中是否存在领域敏感分词,是则将该各个非重复分词作为各个待处理领域敏感分词,并进入步骤a6;否则进入步骤a7。
与上述步骤a3所具体设计的两种实施方式相对应,这里步骤a5在实际应用当中,同样具体可以设计采用两种实施方式,第一种实施方式是:将各篇待处理文档分别所对应的各个非重复分词、与该网路账号所对应技术领域下的预设领域敏感词汇集中的各个敏感词进行匹配,判断是否存在匹配成功的非重复分词,是则将该各匹配成功的非重复分词作为各个待处理领域敏感分词,并进入步骤a6;否则进入步骤a7。
第二种实施方式是:分别针对各篇待处理文档所对应的各个非重复分词,应用以分词向量为输入、分词向量分别对应领域敏感类与非领域敏感类的概率为输出的领域敏感分类模型,针对非重复分词所对应的分词向量进行处理,判断非重复分词是否为领域敏感分词;进而实现判断各篇待处理文档分别所对应各个非重复分词中是否存在领域敏感分词,是则将该各个非重复分词作为各个待处理领域敏感分词,并进入步骤a6;否则进入步骤a7。
对于领域敏感分类模型来说,是预先基于预设领域敏感词汇集中各领域敏感词分别所对应的分词向量,以及预设数量个预设非领域敏感词分别所对应的分词向量,针对采用多层全连接层作为的第二目标分类网络进行训练,获得以分词向量为输入、分词向量分别对应领域敏感类与非领域敏感类的概率为输出的领域敏感分类模型,并且其中采用如下交叉熵作为损失函数;
其中,yi表示第i个分词向量的真实分类,f(·)是目标分类网络的映射函数,vi表示第i个分词向量,n表示训练阶段的分词向量的数量。
步骤a6.分别针对各个待处理领域敏感分词,将待处理领域敏感分词所在的各篇待处理文档作为各篇待处理敏感文档,并进一步分别针对该各篇待处理敏感文档,根据该待处理领域敏感分词所对应分词向量分别与待处理敏感文档中其他各非重复分词所对应分词向量之间的正弦距离,计算获得该待处理领域敏感分词分别与待处理敏感文档中其他各个非重复分词之间的相似度,并选择其中相似度大于预设相似度阈值的各个非重复分词,同样作为待处理领域敏感分词,即更新该篇待处理敏感文档所对应的各个待处理领域敏感分词,并将新增待处理领域敏感分词加入预设领域敏感词汇集,更新预设领域敏感词汇集;进而获得各篇待处理敏感文档、以及待处理敏感文档所对应的各待处理领域敏感分词,然后进入步骤a7。
步骤a7.判断是否存在待处理敏感文档,是则分别针对各待处理敏感文档,将待处理敏感文档所对应的各个待处理领域敏感分词、各待处理领域敏感分词,构成该待处理敏感文档所对应的各个待处理敏感分词,进而获得各待处理敏感文档分别所对应的各个待处理敏感分词,并获得待处理敏感文档的数量,作为该网络账号所对应的敏感发布次数,然后进入步骤b;否则结束本次针对该网络账号的监测。
步骤b.基于各待处理敏感文档所对应的各个待处理敏感分词,统计其中彼此不同的各个待处理敏感分词,作为各个非重复待处理敏感分词,然后进入步骤c。
步骤c.分别针对各非重复待处理敏感分词,首先获得非重复待处理敏感分词所在各待处理敏感文档中最早发布时间,作为该非重复待处理敏感分词所对应发布时间,然后查找全网中除目标监控集中各网络账号以外范围内是否存在包含非重复待处理敏感分词、且发布时间晚于该非重复待处理敏感分词所对应发布时间的文档,是则定义满足该要求的各文档为传播文档,即获得该非重复待处理敏感分词所对应的各个传播文档;否则该非重复待处理敏感分词不存在传播文档;待完成此步骤关于各非重复待处理敏感分词的操作后,然后进入步骤d。
步骤d.判断是否存在对应传播文档的非重复待处理敏感分词,是则针对该各个存在对应传播文档的非重复待处理敏感分词分别所对应的各篇传播文档,统计其中彼此不同的各篇传播文档,作为各篇非重复传播文档,统计非重复传播文档的数量,作为该网络账号所对应的全网传播次数;否则定义该网络账号所对应的全网传播次数为0;待完成此步骤的判断后,进入步骤e。
实际应用当中,上述步骤d具体判断是否存在对应传播文档的非重复待处理敏感分词,是则在获得该网络账号所对应的全网传播次数后,进入步骤de-1;否则定义该网络账号所对应的全网传播次数为0,并进入步骤e;
步骤de-1.将各篇非重复传播文档与各篇待处理敏感文档进行匹配,判断是否存在匹配成功的非重复传播文档,是则进入步骤de-2;否则进入步骤e;
步骤de-2.判断各匹配成功的非重复传播文档中是否存在互为引用关系,是则获得其中各被引用非重复传播文档的引用次数,分别作为各被引用非重复传播文档所对应网络账号的敏感传播次数,并选择其中敏感传播次数大于预设传播次数阈值的网络账号加入目标监控集中,更新目标监控集,然后进入步骤e;否则直接进入步骤e。
步骤e.针对该网络账号所对应敏感发布次数与全网传播次数,按分别所对应的预设敏感发布权重、全网传播权重,执行加权操作,所获加权结果作为该网络账号所对应的传播指标值,并判断该传播指标值是否超过预设传播指标下限,是则按预设步长比例,减小该网路账号所对应的监测周期时长;否则结束本次针对该网络账号的监测。
在通过上述步骤a至步骤e,周期实现上述分别针对目标监控集中的各个网络账号的监测的同时,还包括周期所执行针对目标监控集的删减更新方法,具体设计按预设周期执行如下步骤i至步骤iii。
步骤i.分别针对目标监控集中的各个网路账号,判断网络账号距当前时刻最近的一次监测中,该网络账号所对应传播次数是否为0,是则将该网络账号作为待处理网络账号;否则不做任何处理;待完成此步骤针对目标监控集中各网路账号的判断操作后,进入步骤ii。
步骤ii.判断是否存在待处理网络账号,是则分别针对各待处理网络账号,针对自待处理网络账号距当前时刻最近的一次监测起、向历史方向的各次监测,统计该待处理网络账号连续对应传播次数为0的监测的数目,作为待处理网络账号所对应的衡量次数,进而获得各待处理网络账号分别所对应的衡量次数,然后进入步骤iii;否则不做任何处理。
步骤iii.根据各待处理网络账号分别所对应的衡量次数,将衡量次数高于预设衡量次数阈值的各个待处理网络账号,由目标监控集中删除,更新目标监控集。
将本发明所设计网络舆情监测方法,应用于实际当中时,分别针对目标监控集中的各个网络账号,按网络账号所对应的监测周期时长,周期所执行的步骤a至步骤e中,步骤a中,统计当前时刻向历史时间方向、网络账号所对应监测周期时长内,该网络账号所发布的所有文档、并获得各篇文档截图。
并且在执行步骤a至步骤e的同时,若出现所获文档截图被删除的情况,且各篇被删除文档截图分别所对应的文档中、存在非待处理敏感文档的文档,则据此文档的数量,针对该网络账号所对应的敏感发布次数执行增加更新。
上述技术方案所设计一种网络舆情监测方法应用于实际当中,采用全新设计网络舆情比对方式,根据通用敏感词汇集、领域敏感词汇集,针对目标监控集中各网络账号所发表文档进行一次比对,并结合目标监控集到全网的延伸,实现舆情的二次比对,并且在比对过程中,实现了对通用敏感词汇集、领域敏感词汇集、以及目标监控集的更新,智能调整舆情比对范围、以及比对依据,使得比对过程能够随网络信息发展而智能调节;整个设计方案运用大数据与人工智能技术,能实现公众账号审核、政务新媒体传播考核与评估、互联网争议信息识别与溯源等功能。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!